Thứ ba T-SQL của tháng này đang được tổ chức bởi Mike Donnelly (@SQLMD) và anh ấy đã tóm tắt chủ đề như sau:
Chủ đề tháng này là thẳng về phía trước, nhưng kết thúc rất mở. Bạn phải học một cái gì đó mới và sau đó viết một bài đăng trên blog giải thích về nó.Chà, từ thời điểm Mike công bố chủ đề, tôi đã không thực sự bắt đầu tìm hiểu bất cứ điều gì mới, và khi cuối tuần đến gần và tôi biết thứ Hai sẽ tấn công tôi với nhiệm vụ bồi thẩm đoàn, tôi nghĩ tôi sẽ phải ngồi đây. hết tháng.
Sau đó, Martin Smith đã dạy cho tôi điều gì đó mà tôi chưa bao giờ biết, hoặc biết từ lâu nhưng đã quên (đôi khi bạn không biết những gì bạn không biết, và đôi khi bạn không thể nhớ những gì bạn chưa từng biết và những gì bạn không thể nhớ). Hồi ức của tôi là việc thay đổi một cột từ NOT NULL thành NULL nên là một hoạt động chỉ siêu dữ liệu, với việc ghi vào bất kỳ trang nào được trì hoãn cho đến khi trang đó được cập nhật vì các lý do khác, kể từ NULL bitmap sẽ không thực sự cần tồn tại cho đến khi ít nhất một hàng có thể trở thành NULL .
Trên cùng bài đăng đó, @ypercube cũng nhắc tôi về câu trích dẫn thích hợp này từ Books Online (lỗi đánh máy và tất cả):
Việc thay đổi một cột từ NOT NULL thành NULL không được hỗ trợ như một hoạt động trực tuyến khi cột đã thay đổi được tham chiếu bởi các chỉ mục không hợp nhất."Không phải hoạt động trực tuyến" có thể được hiểu là "không phải là hoạt động chỉ dành cho siêu dữ liệu" - có nghĩa là nó thực sự sẽ là một hoạt động ở quy mô dữ liệu (chỉ mục của bạn càng lớn thì càng mất nhiều thời gian).
Tôi bắt đầu chứng minh điều này bằng một thử nghiệm khá đơn giản (nhưng dài dòng) đối với một cột mục tiêu cụ thể để chuyển đổi từ NOT NULL thành NULL . Tôi sẽ tạo 3 bảng, tất cả đều có khóa chính được phân cụm, nhưng mỗi bảng có một chỉ mục không được phân cụm khác nhau. Một sẽ có cột đích làm cột khóa, cột thứ hai là INCLUDE và cột thứ ba hoàn toàn không tham chiếu đến cột mục tiêu.
Đây là các bảng của tôi và cách tôi điền chúng:
CREATE TABLE dbo.test1
(
a INT NOT NULL, b INT NOT NULL, c BIGINT NOT NULL,
CONSTRAINT pk_t1 PRIMARY KEY (a,b)
);
GO
CREATE NONCLUSTERED INDEX ix1 ON dbo.test1(b,c);
GO
CREATE TABLE dbo.test2
(
a INT NOT NULL, b INT NOT NULL, c BIGINT NOT NULL,
CONSTRAINT pk_t2 PRIMARY KEY (a,b)
);
GO
CREATE NONCLUSTERED INDEX ix2 ON dbo.test2(b) INCLUDE(c);
GO
CREATE TABLE dbo.test3
(
a INT NOT NULL, b INT NOT NULL, c BIGINT NOT NULL,
CONSTRAINT pk_t3 PRIMARY KEY (a,b)
);
GO
CREATE NONCLUSTERED INDEX ix3 ON dbo.test3(b);
GO
INSERT dbo.test1(a,b,c) -- repeat for test2 / test3
SELECT n1, n2, ABS(n2)-ABS(n1)
FROM
(
SELECT TOP (100000) s1.[object_id], s2.[object_id]
FROM master.sys.all_objects AS s1
CROSS JOIN master.sys.all_objects AS s2
GROUP BY s1.[object_id], s2.[object_id]
) AS n(n1, n2);
Mỗi bảng có 100.000 hàng, các chỉ mục theo nhóm có 310 trang và các chỉ mục không theo nhóm có 272 trang (test1 và test2 ) hoặc 174 trang (test3 ). (Các giá trị này rất dễ lấy từ sys.dm_db_index_physical_stats .)
Tiếp theo, tôi cần một cách đơn giản để nắm bắt các hoạt động đã được ghi ở cấp trang - tôi chọn sys.fn_dblog() , mặc dù tôi có thể đào sâu hơn và xem các trang trực tiếp. Tôi không bận tâm với các giá trị LSN để chuyển đến hàm, vì tôi không chạy nó trong sản xuất và không quan tâm nhiều đến hiệu suất, vì vậy sau khi kiểm tra, tôi chỉ kết xuất kết quả của hàm, loại trừ bất kỳ dữ liệu nào đã được ghi trước ALTER TABLE hoạt động.
-- establish an exclusion set SELECT * INTO #x FROM sys.fn_dblog(NULL, NULL);
Bây giờ tôi có thể chạy các thử nghiệm của mình, đơn giản hơn rất nhiều so với thiết lập.
ALTER TABLE dbo.test1 ALTER COLUMN c BIGINT NULL; ALTER TABLE dbo.test2 ALTER COLUMN c BIGINT NULL; ALTER TABLE dbo.test3 ALTER COLUMN c BIGINT NULL;
Bây giờ tôi có thể kiểm tra các thao tác đã được ghi trong từng trường hợp:
SELECT AllocUnitName, [Operation], Context, c = COUNT(*)
FROM
(
SELECT * FROM sys.fn_dblog(NULL, NULL)
WHERE [Operation] = N'LOP_FORMAT_PAGE'
AND AllocUnitName LIKE N'dbo.test%'
EXCEPT
SELECT * FROM #x
) AS x
GROUP BY AllocUnitName, [Operation], Context
ORDER BY AllocUnitName, [Operation], Context; Các kết quả dường như gợi ý rằng mọi trang lá của chỉ mục không phân cụm đều được chạm vào các trường hợp cột mục tiêu được đề cập trong chỉ mục theo bất kỳ cách nào, nhưng không có hoạt động nào như vậy xảy ra đối với trường hợp cột mục tiêu không được đề cập trong bất kỳ chỉ mục không phân cụm:
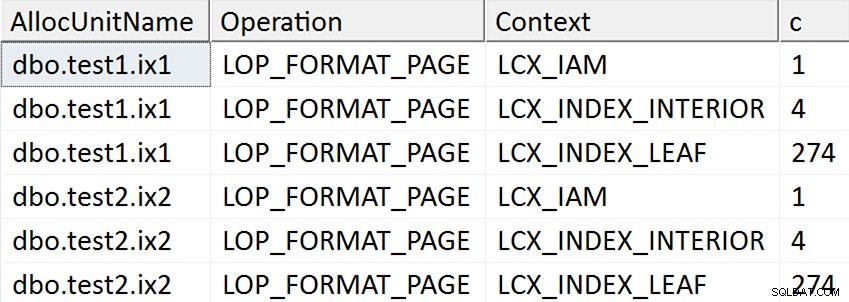
Trên thực tế, trong hai trường hợp đầu tiên, các trang mới được cấp phát (bạn có thể xác thực điều đó bằng DBCC IND , như Spörri đã làm trong câu trả lời của mình), vì vậy thao tác có thể diễn ra trực tuyến, nhưng điều đó không có nghĩa là nó nhanh (vì nó vẫn phải viết ra một bản sao của tất cả dữ liệu đó và tạo NULL bitmap thay đổi như một phần của việc viết ra mỗi trang mới và ghi lại tất cả hoạt động đó).
Tôi nghĩ rằng hầu hết mọi người sẽ nghi ngờ rằng việc thay đổi một cột từ NOT NULL thành NULL sẽ chỉ là siêu dữ liệu trong tất cả các trường hợp, nhưng tôi đã chỉ ra ở đây rằng điều này không đúng nếu cột được tham chiếu bởi chỉ mục không phân cụm (và những điều tương tự xảy ra cho dù đó là khóa hay INCLUDE cột). Có lẽ thao tác này cũng có thể bị buộc phải là ONLINE trong Cơ sở dữ liệu Azure SQL ngày hôm nay, hoặc nó sẽ có thể trong phiên bản chính tiếp theo? Điều này sẽ không nhất thiết làm cho các hoạt động vật lý thực tế diễn ra nhanh hơn, nhưng nó sẽ ngăn chặn việc chặn.
Tôi đã không kiểm tra kịch bản đó (và việc phân tích xem liệu nó có thực sự trực tuyến hay không vẫn khó khăn hơn trong Azure), cũng như tôi đã không kiểm tra nó trên một đống. Một cái gì đó tôi có thể xem lại trong một bài viết trong tương lai. Trong thời gian chờ đợi, hãy cẩn thận về bất kỳ giả định nào bạn có thể đặt ra đối với các hoạt động chỉ siêu dữ liệu.