Cách nhanh nhất để tính giá trị trung bình là sử dụng SQL Server 2012 OFFSET phần mở rộng cho ORDER BY mệnh đề. Chạy một giây gần hết, giải pháp nhanh nhất tiếp theo sử dụng con trỏ động (có thể lồng vào nhau) hoạt động trên tất cả các phiên bản. Bài viết này xem xét một ROW_NUMBER phổ biến trước năm 2012 giải pháp cho vấn đề tính toán trung bình để xem tại sao nó hoạt động kém hơn và có thể làm gì để làm cho nó diễn ra nhanh hơn.
Kiểm tra trung bình đơn
Dữ liệu mẫu cho thử nghiệm này bao gồm một bảng mười triệu hàng (được sao chép từ bài báo gốc của Aaron Bertrand):
CREATE TABLE dbo.obj
(
id integer NOT NULL IDENTITY(1,1),
val integer NOT NULL
);
INSERT dbo.obj WITH (TABLOCKX)
(val)
SELECT TOP (10000000)
AO.[object_id]
FROM sys.all_columns AS AC
CROSS JOIN sys.all_objects AS AO
CROSS JOIN sys.all_objects AS AO2
WHERE AO.[object_id] > 0
ORDER BY
AC.[object_id];
CREATE UNIQUE CLUSTERED INDEX cx
ON dbo.obj(val, id); Giải pháp OFFSET
Để đặt điểm chuẩn, đây là giải pháp OFFSET của SQL Server 2012 (hoặc mới hơn) được tạo bởi Peter Larsson:
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT
Median = AVG(1.0 * SQ1.val)
FROM
(
SELECT O.val
FROM dbo.obj AS O
ORDER BY O.val
OFFSET (@Count - 1) / 2 ROWS
FETCH NEXT 1 + (1 - (@Count % 2)) ROWS ONLY
) AS SQ1;
SELECT Peso = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME()); Truy vấn đếm các hàng trong bảng được nhận xét và thay thế bằng một giá trị được mã hóa cứng để tập trung vào hiệu suất của mã lõi. Khi bộ sưu tập kế hoạch thực thi và bộ nhớ cache ấm bị tắt, truy vấn này chạy trong 910 mili giây trung bình trên máy thử nghiệm của tôi. Kế hoạch thực hiện được hiển thị bên dưới:

Cũng cần lưu ý thêm, điều thú vị là truy vấn phức tạp vừa phải này đủ điều kiện cho một kế hoạch tầm thường:
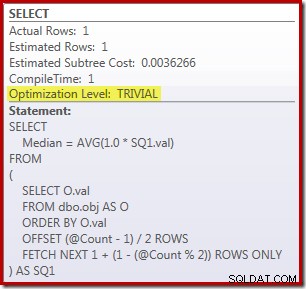
Giải pháp ROW_NUMBER
Đối với các hệ thống chạy SQL Server 2008 R2 hoặc phiên bản cũ hơn, giải pháp thay đổi hoạt động tốt nhất sử dụng con trỏ động như đã đề cập trước đây. Nếu bạn không thể (hoặc không muốn) coi đó là một tùy chọn, điều tự nhiên là bạn nên nghĩ đến việc mô phỏng OFFSET 2012 kế hoạch thực thi sử dụng ROW_NUMBER .
Ý tưởng cơ bản là đánh số các hàng theo thứ tự thích hợp, sau đó chỉ lọc một hoặc hai hàng cần thiết để tính giá trị trung bình. Có một số cách để viết điều này trong Transact SQL; một phiên bản nhỏ gọn nắm bắt tất cả các yếu tố chính như sau:
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT AVG(1.0 * SQ1.val) FROM
(
SELECT
O.val,
rn = ROW_NUMBER() OVER (
ORDER BY O.val)
FROM dbo.obj AS O
) AS SQ1
WHERE
SQ1.rn BETWEEN (@Count + 1)/2 AND (@Count + 2)/2;
SELECT Pre2012 = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME());
Kế hoạch thực thi kết quả khá giống với OFFSET phiên bản:

Cần xem xét lần lượt từng nhà khai thác kế hoạch để hiểu đầy đủ về chúng:
- Toán tử Phân đoạn là thừa trong kế hoạch này. Nó sẽ được yêu cầu nếu
ROW_NUMBERchức năng xếp hạng cóPARTITION BY, nhưng nó không. Mặc dù vậy, nó vẫn nằm trong kế hoạch cuối cùng. - Dự án Trình tự thêm một số hàng được tính toán vào luồng hàng.
- Phạm vi tính toán xác định một biểu thức liên quan đến nhu cầu chuyển đổi ngầm định
valcột thành số để nó có thể được nhân với hằng số1.0trong truy vấn. Việc tính toán này được trì hoãn cho đến khi cần đến bởi nhà điều hành sau này (điều này xảy ra là Tổng hợp Luồng). Tối ưu hóa thời gian chạy này có nghĩa là chuyển đổi ngầm chỉ được thực hiện cho hai hàng được xử lý bởi Tổng hợp luồng, không phải 5.000.001 hàng được chỉ định cho Vô hướng tính toán. - Toán tử hàng đầu được giới thiệu bởi trình tối ưu hóa truy vấn. Nó nhận ra rằng tối đa, chỉ
(@Count + 2) / 2đầu tiên các hàng được truy vấn cần thiết. Chúng tôi có thể đã thêm mộtTOP ... ORDER BYtrong truy vấn con để làm cho điều này rõ ràng, nhưng tối ưu hóa này làm cho điều đó phần lớn không cần thiết. - Bộ lọc triển khai điều kiện trong
WHEREmệnh đề, lọc ra tất cả trừ hai hàng 'giữa' cần thiết để tính giá trị trung bình (Top được giới thiệu cũng dựa trên điều kiện này). - Tổng hợp Luồng tính toán
SUMvàCOUNTcủa hai hàng trung tuyến. - Tính toán vô hướng cuối cùng tính giá trị trung bình từ tổng và đếm.
Hiệu suất thô
So với OFFSET kế hoạch, chúng tôi có thể mong đợi rằng các toán tử Phân đoạn, Dự án trình tự và Bộ lọc bổ sung sẽ có một số ảnh hưởng bất lợi đến hiệu suất. Bạn nên dành một chút thời gian để so sánh ước tính chi phí của hai kế hoạch:
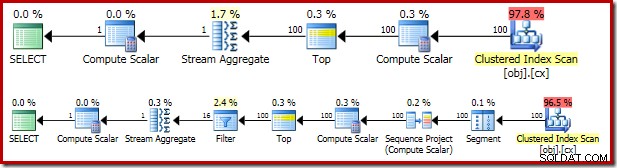
OFFSET kế hoạch có chi phí ước tính là 0,0036266 đơn vị, trong khi ROW_NUMBER kế hoạch được ước tính là 0,0036744 các đơn vị. Đây là những con số rất nhỏ và có rất ít sự khác biệt giữa hai con số này.
Vì vậy, có lẽ đáng ngạc nhiên là ROW_NUMBER truy vấn thực sự chạy trong 4000 mili giây trung bình, so với 910 mili giây trung bình cho OFFSET sự hòa tan. Một số sự gia tăng này chắc chắn có thể được giải thích là do chi phí của các nhà khai thác kế hoạch bổ sung, nhưng hệ số bốn có vẻ quá mức. Phải có nhiều thứ hơn nữa.
Bạn cũng có thể nhận thấy rằng ước tính bản số cho cả hai kế hoạch ước tính ở trên đều sai một cách vô vọng. Điều này là do tác động của các toán tử Hàng đầu, có một biểu thức tham chiếu đến một biến làm giới hạn số hàng của chúng. Trình tối ưu hóa truy vấn không thể nhìn thấy nội dung của các biến tại thời điểm biên dịch, vì vậy nó sử dụng dự đoán mặc định là 100 hàng. Cả hai kế hoạch thực sự gặp phải 5.000.001 hàng trong thời gian chạy.
Tất cả điều này đều rất thú vị, nhưng nó không trực tiếp giải thích tại sao ROW_NUMBER truy vấn chậm hơn bốn lần so với OFFSET phiên bản. Rốt cuộc, ước tính số lượng hàng 100 cũng sai trong cả hai trường hợp.
Cải thiện hiệu suất của giải pháp ROW_NUMBER
Trong bài viết trước của tôi, chúng ta đã biết hiệu suất của OFFSET giá trị trung bình được nhóm như thế nào kiểm tra có thể được tăng gần gấp đôi bằng cách chỉ cần thêm một PAGLOCK gợi ý. Gợi ý này ghi đè quyết định thông thường của công cụ lưu trữ để thu thập và giải phóng các khóa được chia sẻ ở mức độ chi tiết của hàng (do số lượng bản gốc dự kiến thấp).
Xin nhắc thêm, PAGLOCK gợi ý là không cần thiết trong OFFSET trung bình duy nhất kiểm tra do tối ưu hóa nội bộ riêng biệt có thể bỏ qua các khóa được chia sẻ ở cấp độ hàng, dẫn đến chỉ một số lượng nhỏ các khóa được chia sẻ ý định được thực hiện ở cấp độ trang.
Chúng tôi có thể mong đợi ROW_NUMBER giải pháp trung bình duy nhất để được hưởng lợi từ cùng một tối ưu hóa nội bộ, nhưng không. Giám sát hoạt động khóa trong khi ROW_NUMBER thực thi truy vấn, chúng tôi thấy hơn nửa triệu ổ khóa được chia sẻ ở cấp độ hàng riêng lẻ được lấy và phát hành.
Vì vậy, bây giờ chúng tôi biết vấn đề là gì, chúng tôi có thể cải thiện hiệu suất khóa giống như cách chúng tôi đã làm trước đây:với PAGLOCK khóa gợi ý về mức độ chi tiết hoặc bằng cách tăng ước tính số lượng bằng cách sử dụng cờ theo dõi được lập thành văn bản 4138.
Vô hiệu hóa "mục tiêu hàng" bằng cách sử dụng cờ theo dõi là giải pháp kém khả quan hơn vì một số lý do. Đầu tiên, nó chỉ có hiệu quả trong SQL Server 2008 R2 trở lên. Chúng tôi rất có thể thích OFFSET giải pháp trong SQL Server 2012, vì vậy điều này chỉ giới hạn hiệu quả việc sửa cờ theo dõi đối với SQL Server 2008 R2. Thứ hai, việc áp dụng cờ theo dõi yêu cầu quyền cấp quản trị viên, trừ khi được áp dụng thông qua hướng dẫn kế hoạch. Lý do thứ ba là việc vô hiệu hóa các mục tiêu hàng cho toàn bộ truy vấn có thể gây ra các tác dụng không mong muốn khác, đặc biệt là trong các kế hoạch phức tạp hơn.
Ngược lại, PAGLOCK gợi ý là hiệu quả, có sẵn trong tất cả các phiên bản của SQL Server mà không cần bất kỳ quyền đặc biệt nào và không có bất kỳ tác dụng phụ lớn nào ngoài việc khóa mức độ chi tiết.
Áp dụng PAGLOCK gợi ý cho ROW_NUMBER truy vấn tăng hiệu suất đáng kể:từ 4000 mili giây đến 1500 mili giây:
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT AVG(1.0 * SQ1.val) FROM
(
SELECT
O.val,
rn = ROW_NUMBER() OVER (
ORDER BY O.val)
FROM dbo.obj AS O WITH (PAGLOCK) -- New!
) AS SQ1
WHERE
SQ1.rn BETWEEN (@Count + 1)/2 AND (@Count + 2)/2;
SELECT Pre2012 = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME());
1500 mili giây kết quả vẫn chậm hơn đáng kể so với 910 mili giây cho OFFSET giải pháp, nhưng ít nhất bây giờ nó đang ở trong cùng một sân bóng. Sự khác biệt về hiệu suất còn lại chỉ đơn giản là do công việc bổ sung trong kế hoạch thực thi:

Trong OFFSET kế hoạch, năm triệu hàng được xử lý ở phía trên cùng (với các biểu thức được xác định tại Tính vô hướng được trì hoãn như đã thảo luận trước đó). Trong ROW_NUMBER kế hoạch, cùng một số hàng phải được xử lý bởi Phân đoạn, Dự án trình tự, Trên cùng và Bộ lọc.



