Đăng bởi Dan Holmes, người viết blog tại sql.dnhlms.com.
SQL Server Books Online (BOL), sách trắng và nhiều nguồn khác sẽ chỉ cho bạn cách thức và lý do bạn có thể muốn cập nhật thống kê trên bảng hoặc chỉ mục. Tuy nhiên, bạn chỉ có một cách để định hình các giá trị đó. Tôi sẽ chỉ cho bạn cách bạn có thể tạo thống kê chính xác theo cách bạn muốn trong giới hạn 200 bước có sẵn.
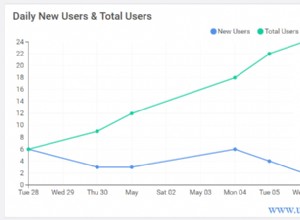
Tuyên bố từ chối trách nhiệm :Điều này phù hợp với tôi vì tôi biết ứng dụng, cơ sở dữ liệu của mình cũng như quy trình làm việc thường xuyên của người dùng và các kiểu sử dụng ứng dụng. Tuy nhiên, nó sử dụng các lệnh không có tài liệu và nếu sử dụng không đúng cách, ứng dụng của bạn có thể hoạt động kém hơn đáng kể.Trong ứng dụng của chúng tôi, người dùng Lập lịch thường xuyên đọc và ghi dữ liệu đại diện cho các sự kiện cho ngày mai và vài ngày tới. Dữ liệu cho ngày hôm nay và trước đó không được Người lập lịch sử dụng. Điều đầu tiên vào buổi sáng, tập dữ liệu cho ngày mai bắt đầu ở vài trăm hàng và đến giữa trưa có thể là 1400 hàng trở lên. Biểu đồ sau đây sẽ minh họa số lượng hàng. Dữ liệu này được thu thập vào sáng Thứ Tư, ngày 18 tháng 11 năm 2015. Về mặt lịch sử, bạn có thể thấy rằng số lượng hàng thông thường là khoảng 1.400, ngoại trừ những ngày cuối tuần và ngày hôm sau.
Đối với Người lập lịch, dữ liệu thích hợp duy nhất là trong vài ngày tới. Những gì đang xảy ra hôm nay và xảy ra ngày hôm qua không liên quan đến hoạt động của anh ấy. Vì vậy, làm thế nào điều này gây ra một vấn đề? Bảng này có 2.259.205 hàng có nghĩa là sự thay đổi về số lượng hàng từ sáng đến trưa sẽ không đủ để kích hoạt cập nhật thống kê do SQL Server khởi xướng. Hơn nữa, một công việc được lên lịch theo cách thủ công tạo thống kê bằng cách sử dụng UPDATE STATISTICS điền vào biểu đồ với một mẫu của tất cả dữ liệu trong bảng nhưng có thể không bao gồm thông tin liên quan. Số hàng delta này đủ để thay đổi kế hoạch. Tuy nhiên, nếu không có bản cập nhật thống kê và biểu đồ chính xác, kế hoạch sẽ không thay đổi theo hướng tốt hơn khi dữ liệu thay đổi.
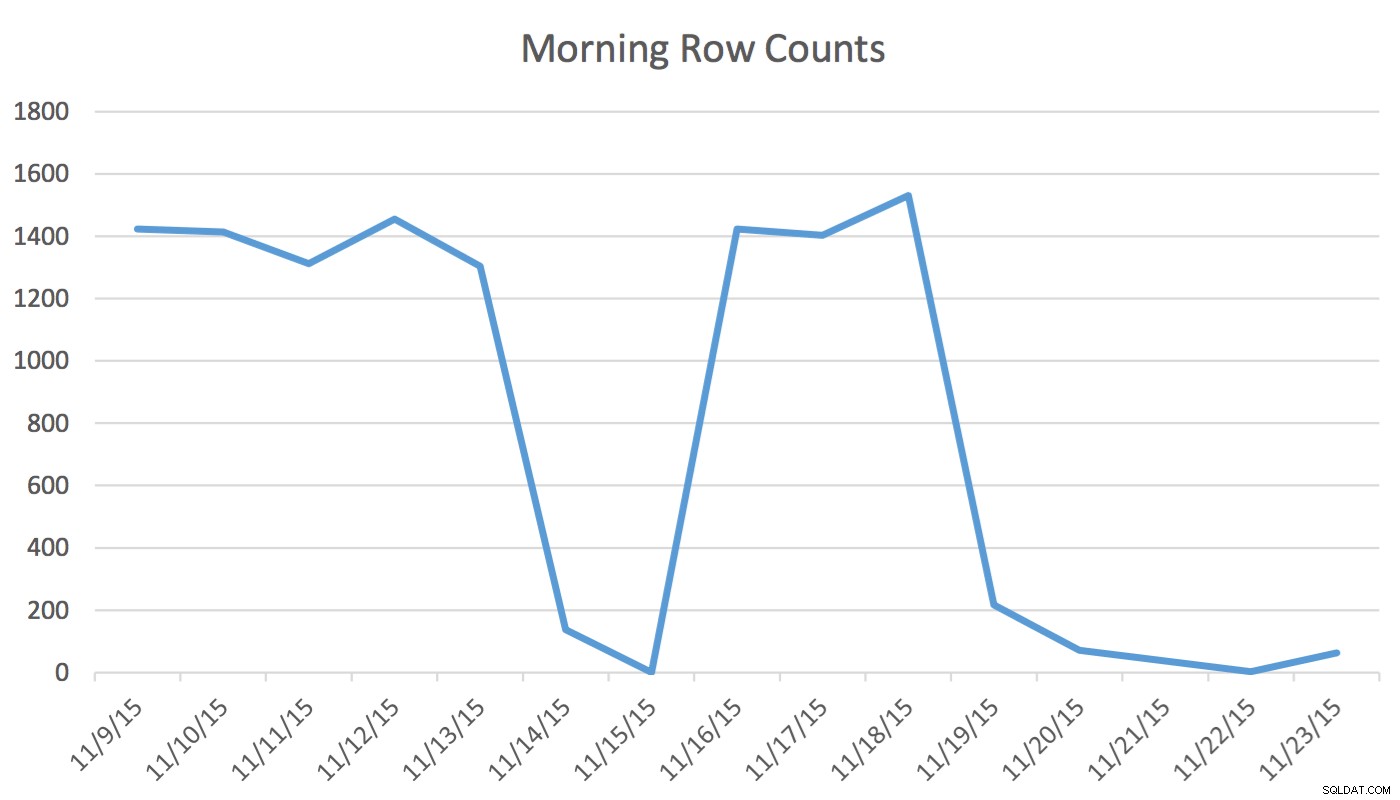
Lựa chọn biểu đồ có liên quan cho bảng này từ bản sao lưu ngày 11/4/2015 có thể trông giống như sau:
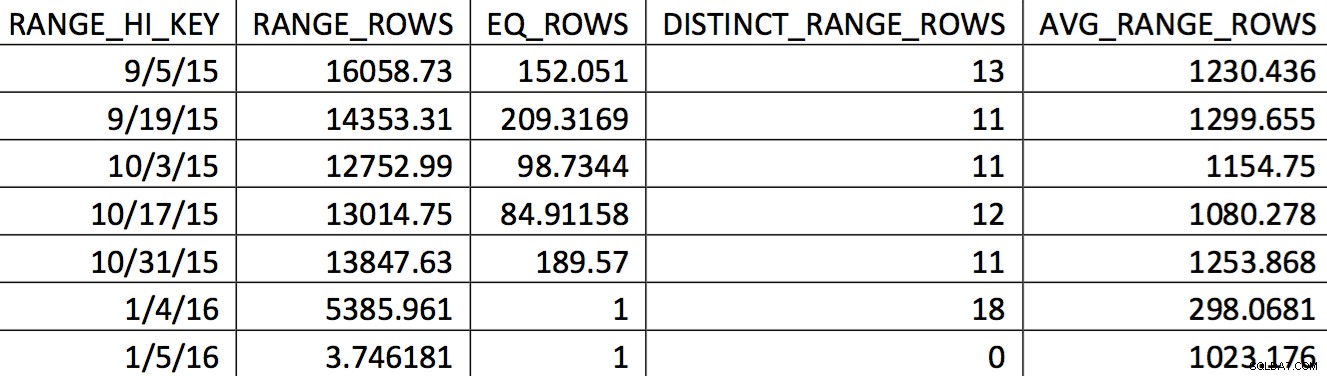
Các giá trị quan tâm không được phản ánh chính xác trong biểu đồ. Những gì sẽ được sử dụng cho ngày 11/5/2015 sẽ là giá trị cao 1/4/2016. Dựa trên biểu đồ, biểu đồ này rõ ràng không phải là nguồn thông tin tốt cho trình tối ưu hóa cho ngày quan tâm. Việc buộc các giá trị sử dụng vào biểu đồ là không đáng tin cậy, vậy bạn có thể làm điều đó bằng cách nào? Nỗ lực đầu tiên của tôi là sử dụng liên tục WITH SAMPLE tùy chọn của UPDATE STATISTICS và truy vấn biểu đồ cho đến khi các giá trị tôi cần có trong biểu đồ (nỗ lực chi tiết tại đây). Cuối cùng, cách tiếp cận đó được chứng minh là không đáng tin cậy.
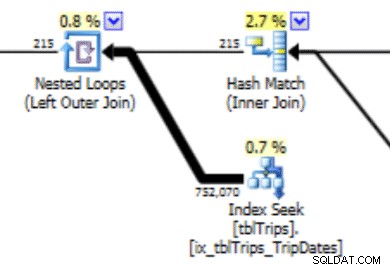
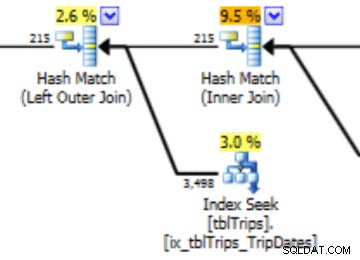
Biểu đồ này có thể dẫn đến một kế hoạch với loại hành vi này. Việc đánh giá thấp các hàng tạo ra tham gia Vòng lặp lồng nhau và tìm kiếm chỉ mục. Số lần đọc sau đó cao hơn mức đáng lẽ do lựa chọn kế hoạch này. Điều này cũng sẽ ảnh hưởng đến thời lượng sao kê.
Điều sẽ hoạt động tốt hơn nhiều là tạo dữ liệu chính xác theo cách bạn muốn và đây là cách thực hiện điều đó.
Có một tùy chọn không được hỗ trợ là UPDATE STATISTICS :STATS_STREAM . Điều này được bộ phận Hỗ trợ khách hàng của Microsoft sử dụng để xuất và nhập thống kê để họ có thể tạo lại trình tối ưu hóa mà không cần có tất cả dữ liệu trong bảng. Chúng tôi có thể sử dụng tính năng đó. Ý tưởng là tạo một bảng mô phỏng DDL của thống kê mà chúng tôi muốn tùy chỉnh. Dữ liệu có liên quan được thêm vào bảng. Các số liệu thống kê được xuất và nhập vào bảng gốc.
Trong trường hợp này, đó là một bảng có 200 hàng không phải ngày NULL và 1 hàng bao gồm các giá trị NULL. Ngoài ra, có một chỉ mục trên bảng đó khớp với chỉ mục có giá trị biểu đồ xấu.
Tên của bảng là tblTripsScheduled . Nó có một chỉ mục không phân cụm trên (id, TheTripDate) và một chỉ mục được phân nhóm trên TheTripDate . Có một số cột khác, nhưng chỉ những cột liên quan đến chỉ mục là quan trọng.
Tạo một bảng (bảng tạm thời nếu bạn muốn) bắt chước bảng và chỉ mục. Bảng và chỉ mục trông như thế này:
TẠO BẢNG #tbltripsschedised_cix_tripsschedised (id INT NOT NULL, tripdate DATETIME NOT NULL, PRIMARY KEY NONCLUSTERED (id, tripdate)); TẠO CHỈ SỐ ĐƯỢC CẬP NHẬT VÀO #tbltripsschedised_cix_tripsschedised (tripdate);
Tiếp theo, bảng cần được điền 200 hàng dữ liệu mà thống kê sẽ dựa trên đó. Đối với tình huống của tôi, đó là ngày của đến sáu mươi ngày tới. Quá khứ và hơn 60 ngày được điền với lựa chọn "ngẫu nhiên" cứ 10 ngày một lần. (cnt giá trị trong CTE là một giá trị gỡ lỗi. Nó không đóng vai trò trong kết quả cuối cùng.) Thứ tự giảm dần cho rn đảm bảo rằng 60 ngày được bao gồm và sau đó là càng nhiều càng tốt.
DECLARE @date DATETIME ='20151104'; VỚI tripdateAS (CHỌN ngày tháng, COUNT (*) cnt TỪ dbo.tbltrip được lên lịch TẠI ĐÂU KHÔNG PHẢI ngày tháng GIỮA @date VÀ @date AND thetripdateBảng của chúng tôi hiện được điền với mọi hàng có giá trị đối với người dùng ngày nay và lựa chọn các hàng lịch sử. Nếu cột
TheTripdatelà nullable, phần chèn cũng sẽ bao gồm những điều sau:UNION ALLSELECT id, thetripdateFROM dbo.tbltripsschedisedW đâu thetripdate IS NULL;Tiếp theo, chúng tôi cập nhật thống kê về chỉ mục của bảng tạm thời của chúng tôi.
CẬP NHẬT THỐNG KÊ #tbltrips_IX_tbltrips_tripdates (giá ba lần) VỚI FULLSCAN;Bây giờ, hãy xuất những số liệu thống kê đó sang một bảng tạm thời. Bảng đó trông như thế này. Nó khớp với kết quả đầu ra của
DBCC SHOW_STATISTICS WITH HISTOGRAM.TẠO BẢNG #stats_with_stream (luồng VARBINARY (MAX) KHÔNG ĐẦY ĐỦ, hàng KHÔNG PHẢI KHÔNG ĐỦ, các trang KHÔNG ĐỦ);
DBCC SHOW_STATISTICScó một tùy chọn để xuất các thống kê dưới dạng một luồng. Đó là dòng mà chúng tôi muốn. Luồng đó cũng chính là luồng màUPDATE STATISTICStùy chọn luồng sử dụng. Để làm điều đó:CHÈN VÀO #stats_with_stream --SELECT * FROM #stats_with_streamEXEC ('DBCC SHOW_STATISTICS (Không có' 'Bước cuối cùng là tạo SQL cập nhật số liệu thống kê của bảng mục tiêu của chúng tôi và sau đó thực thi nó.
DECLARE @sql NVARCHAR (MAX); SET @sql =(CHỌN 'THỐNG KÊ CẬP NHẬT tbltripsschedised (cix_tbltripsschedised) WITHSTATS_STREAM =0x' + CAST ('' AS XML) .value ('xs:hexBinary (sql:column ("stream ")) ',' NVARCHAR (MAX) ') FROM #stats_with_stream); EXEC (@sql);Tại thời điểm này, chúng tôi đã thay thế biểu đồ bằng biểu đồ được tạo tùy chỉnh của chúng tôi. Bạn có thể xác minh bằng cách kiểm tra biểu đồ:
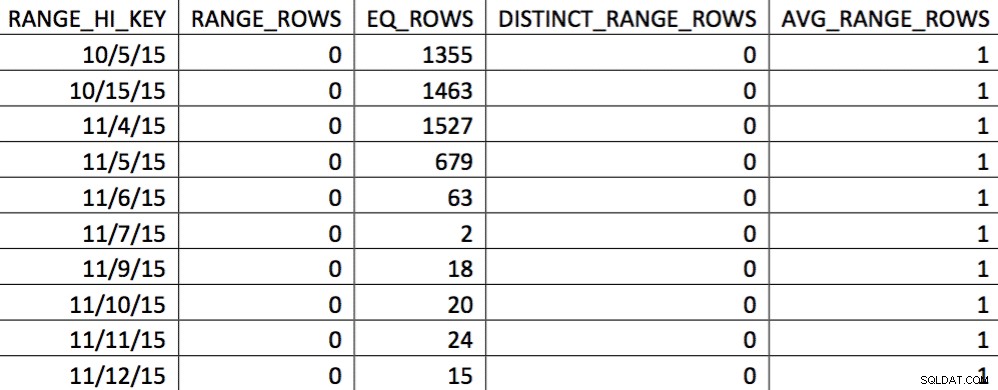
Trong lựa chọn dữ liệu vào ngày 11/4 này, tất cả các ngày từ 11/4 trở đi đều được thể hiện và dữ liệu lịch sử được thể hiện chính xác và chính xác. Xem lại phần kế hoạch truy vấn được hiển thị trước đó, bạn có thể thấy trình tối ưu hóa đã đưa ra lựa chọn tốt hơn dựa trên các thống kê đã sửa:
Có một lợi ích về hiệu suất đối với số liệu thống kê đã nhập. Chi phí để tính toán thống kê nằm trên bảng "ngoại tuyến". Thời gian ngừng hoạt động duy nhất cho bảng sản xuất là thời gian nhập luồng.
Quá trình này sử dụng các tính năng không có giấy tờ và có vẻ như nó có thể nguy hiểm, nhưng hãy nhớ rằng có một cách hoàn tác dễ dàng:tuyên bố thống kê cập nhật. Nếu có sự cố, thống kê luôn có thể được cập nhật bằng T-SQL chuẩn.
Lập lịch để mã này chạy thường xuyên có thể giúp trình tối ưu hóa tạo ra các kế hoạch tốt hơn khi cung cấp một tập dữ liệu thay đổi theo thời điểm nhưng không đủ để kích hoạt cập nhật thống kê.
Khi tôi hoàn thành bản nháp đầu tiên của bài viết này, số hàng trên bảng trong biểu đồ đầu tiên đã thay đổi từ 217 thành 717. Đó là mức thay đổi 300%. Điều đó đủ để thay đổi hành vi của trình tối ưu hóa nhưng không đủ để kích hoạt cập nhật thống kê. Sự thay đổi dữ liệu này sẽ để lại một kế hoạch tồi. Với quy trình được mô tả ở đây, vấn đề này đã được giải quyết.
Tài liệu tham khảo:
- CẬP NHẬT THỐNG KÊ (Sách Trực tuyến)
- Báo cáo chính thức về thống kê SQL 2008
- Tìm kiếm điểm tới hạn