Bài viết này khám phá một số tính năng và hạn chế của trình tối ưu hóa truy vấn ít nổi tiếng hơn, đồng thời giải thích lý do cho hiệu suất kết hợp băm cực kỳ kém trong một trường hợp cụ thể.
Dữ liệu mẫu
Tập lệnh tạo dữ liệu mẫu tiếp theo dựa trên một bảng số hiện có. Nếu bạn chưa có một trong những tập lệnh này, bạn có thể sử dụng tập lệnh dưới đây để tạo một tập lệnh hiệu quả. Bảng kết quả sẽ chứa một cột số nguyên duy nhất với các số từ một đến một triệu:
WITH Ten(N) AS
(
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1
)
SELECT TOP (1000000)
n = IDENTITY(int, 1, 1)
INTO dbo.Numbers
FROM Ten T10,
Ten T100,
Ten T1000,
Ten T10000,
Ten T100000,
Ten T1000000;
ALTER TABLE dbo.Numbers
ADD CONSTRAINT PK_dbo_Numbers_n
PRIMARY KEY CLUSTERED (n)
WITH (SORT_IN_TEMPDB = ON, MAXDOP = 1, FILLFACTOR = 100); Dữ liệu mẫu bao gồm hai bảng, T1 và T2. Cả hai đều có một cột khóa chính số nguyên tuần tự có tên là pk và một cột không thể trống thứ hai có tên là c1. Bảng T1 có 600.000 hàng trong đó các hàng được đánh số chẵn có cùng giá trị đối với c1 như cột pk và các hàng được đánh số lẻ là rỗng. Bảng c2 có 32.000 hàng trong đó cột c1 là NULL trong mỗi hàng. Tập lệnh sau tạo và điền các bảng này:
CREATE TABLE dbo.T1
(
pk integer NOT NULL,
c1 integer NULL,
CONSTRAINT PK_dbo_T1
PRIMARY KEY CLUSTERED (pk)
);
CREATE TABLE dbo.T2
(
pk integer NOT NULL,
c1 integer NULL,
CONSTRAINT PK_dbo_T2
PRIMARY KEY CLUSTERED (pk)
);
INSERT dbo.T1 WITH (TABLOCKX)
(pk, c1)
SELECT
N.n,
CASE
WHEN N.n % 2 = 1 THEN NULL
ELSE N.n
END
FROM dbo.Numbers AS N
WHERE
N.n BETWEEN 1 AND 600000;
INSERT dbo.T2 WITH (TABLOCKX)
(pk, c1)
SELECT
N.n,
NULL
FROM dbo.Numbers AS N
WHERE
N.n BETWEEN 1 AND 32000;
UPDATE STATISTICS dbo.T1 WITH FULLSCAN;
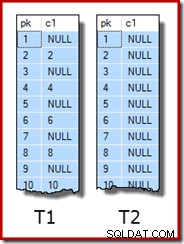
UPDATE STATISTICS dbo.T2 WITH FULLSCAN; Mười hàng dữ liệu mẫu đầu tiên trong mỗi bảng trông giống như sau:
Nối hai bảng
Thử nghiệm đầu tiên này liên quan đến việc kết hợp hai bảng trên cột c1 (không phải cột pk) và trả về giá trị pk từ bảng T1 cho các hàng tham gia:
SELECT T1.pk FROM dbo.T1 AS T1 JOIN dbo.T2 AS T2 ON T2.c1 = T1.c1;
Thực sự truy vấn sẽ không trả về hàng nào vì cột c1 là NULL trong tất cả các hàng của bảng T2, vì vậy không hàng nào có thể khớp với vị từ nối bình đẳng. Điều này nghe có vẻ như là một điều kỳ quặc để làm, nhưng tôi đảm bảo rằng nó dựa trên một truy vấn sản xuất thực (được đơn giản hóa rất nhiều để dễ thảo luận).
Lưu ý rằng kết quả trống này không phụ thuộc vào cài đặt của ANSI_NULLS, vì điều đó chỉ kiểm soát cách xử lý các phép so sánh với một ký tự hoặc biến null. Đối với so sánh cột, một vị từ bình đẳng luôn từ chối giá trị rỗng.
Kế hoạch thực thi cho truy vấn nối đơn giản này có một số tính năng thú vị. Đầu tiên chúng ta sẽ xem xét kế hoạch trước khi thực thi ('ước tính') trong SQL Sentry Plan Explorer:
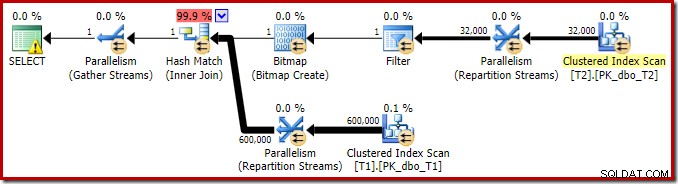
Cảnh báo trên biểu tượng CHỌN chỉ là phàn nàn về việc thiếu chỉ mục trên bảng T1 cho cột c1 (với pk là cột được bao gồm). Đề xuất chỉ mục không liên quan ở đây.
Mục thực sự quan tâm đầu tiên trong kế hoạch này là Bộ lọc:
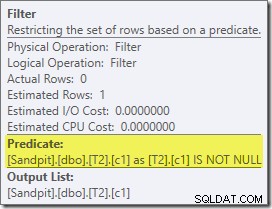
Vị từ KHÔNG ĐẦY ĐỦ này không xuất hiện trong truy vấn nguồn, mặc dù nó được ngụ ý trong vị từ nối như đã đề cập trước đó. Điều thú vị là nó đã được chia ra như một toán tử phụ rõ ràng và được đặt trước hoạt động nối. Lưu ý rằng ngay cả khi không có Bộ lọc, truy vấn vẫn tạo ra kết quả chính xác - bản thân phép nối sẽ vẫn từ chối các giá trị rỗng.
Bộ lọc cũng gây tò mò vì những lý do khác. Nó có chi phí ước tính chính xác bằng 0 (mặc dù nó dự kiến sẽ hoạt động trên 32.000 hàng) và nó chưa bị đẩy xuống Clustered Index Scan như một vị từ còn lại. Trình tối ưu hóa thường rất muốn làm điều này.
Cả hai điều này đều được giải thích bởi thực tế là Bộ lọc này được giới thiệu trong quá trình viết lại sau tối ưu hóa. Sau khi trình tối ưu hóa truy vấn hoàn tất quá trình xử lý dựa trên chi phí, có một số lượng tương đối nhỏ các bản ghi lại kế hoạch cố định được xem xét. Một trong những người này chịu trách nhiệm giới thiệu Bộ lọc.
Chúng ta có thể thấy đầu ra của lựa chọn gói dựa trên chi phí (trước khi viết lại) bằng cách sử dụng cờ theo dõi không có tài liệu 8607 và 3604 quen thuộc để hướng đầu ra văn bản đến bảng điều khiển (tab thông báo trong SSMS):
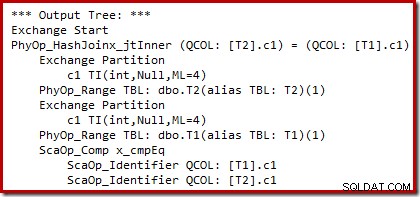
Cây đầu ra hiển thị một phép nối băm, hai lần quét và một số toán tử song song (trao đổi). Không có Bộ lọc từ chối rỗng trên cột c1 của bảng T2.
Việc viết lại sau tối ưu hóa cụ thể chỉ xem xét đầu vào xây dựng của phép nối băm. Tùy thuộc vào đánh giá của nó về tình huống, nó có thể thêm một Bộ lọc rõ ràng để từ chối các hàng trống trong khóa tham gia. Ảnh hưởng của Bộ lọc đối với số lượng hàng ước tính cũng được ghi vào kế hoạch thực thi, nhưng vì tối ưu hóa dựa trên chi phí đã hoàn thành nên chi phí cho Bộ lọc không được tính. Trong trường hợp không rõ ràng, việc tính toán chi phí sẽ rất lãng phí nếu tất cả các quyết định dựa trên chi phí đã được đưa ra.
Bộ lọc vẫn nằm trực tiếp trên đầu vào bản dựng thay vì bị đẩy xuống Quét chỉ mục theo cụm vì hoạt động tối ưu hóa chính đã hoàn thành. Các bản viết lại sau tối ưu hóa là những chỉnh sửa hiệu quả vào phút cuối đối với một kế hoạch thực thi đã hoàn thành.
Việc viết lại sau tối ưu hóa thứ hai, và khá riêng biệt, do toán tử Bitmap chịu trách nhiệm trong kế hoạch cuối cùng (bạn có thể nhận thấy nó cũng bị thiếu trong đầu ra 8607):
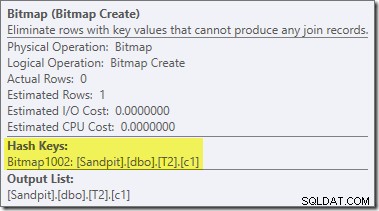
Nhà điều hành này cũng có chi phí ước tính bằng không cho cả I / O và CPU. Điều khác xác định nó là một toán tử được giới thiệu bởi một lần chỉnh sửa muộn (chứ không phải trong quá trình tối ưu hóa dựa trên chi phí) là tên của nó là Bitmap, theo sau là một số. Có các loại bitmap khác được giới thiệu trong quá trình tối ưu hóa dựa trên chi phí mà chúng ta sẽ thấy ở phần sau.
Hiện tại, điều quan trọng về bitmap này là nó ghi lại các giá trị c1 được thấy trong giai đoạn xây dựng của phép nối băm. Bitmap đã hoàn thành được đẩy sang phía thăm dò của phép nối khi hàm băm chuyển từ giai đoạn xây dựng sang giai đoạn thăm dò. Bitmap được sử dụng để thực hiện việc giảm bán nối sớm, loại bỏ các hàng từ phía đầu dò không thể tham gia. nếu bạn cần thêm chi tiết về vấn đề này, vui lòng xem bài viết trước của tôi về chủ đề này.
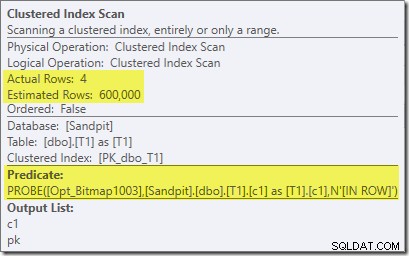
Hiệu ứng thứ hai của bitmap có thể được nhìn thấy trên Quét chỉ mục theo cụm phía đầu dò:
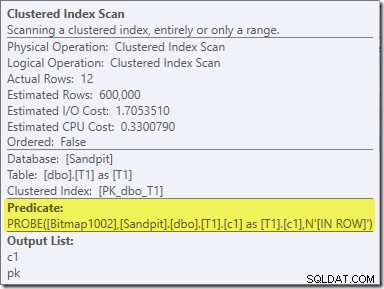
Ảnh chụp màn hình ở trên cho thấy bitmap đã hoàn thành đang được kiểm tra như một phần của Quét chỉ mục theo cụm trên bảng T1. Vì cột nguồn là một số nguyên (bigint cũng sẽ hoạt động) nên việc kiểm tra bitmap được đẩy vào bộ lưu trữ (như được chỉ ra bởi bộ định lượng 'INROW') thay vì được bộ xử lý truy vấn kiểm tra. Nói chung hơn, bitmap có thể được áp dụng cho bất kỳ toán tử nào ở phía thăm dò, từ sàn giao dịch trở xuống. Bộ xử lý truy vấn có thể đẩy bitmap đi bao xa tùy thuộc vào loại cột và phiên bản của SQL Server.
Để hoàn thành việc phân tích các đặc điểm chính của kế hoạch thực thi này, chúng ta cần xem xét kế hoạch sau thực hiện ('thực tế'):
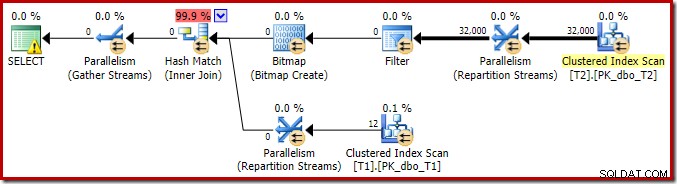
Điều đầu tiên cần chú ý là sự phân bố các hàng trên các luồng giữa quá trình quét T2 và trao đổi Luồng phân vùng lại ngay phía trên nó. Trong một lần chạy thử nghiệm, tôi thấy bản phân phối sau trên hệ thống có bốn bộ xử lý logic:
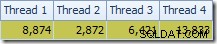
Phân phối không đặc biệt đồng đều, như thường xảy ra đối với việc quét song song trên một số lượng hàng tương đối nhỏ, nhưng ít nhất tất cả các luồng đều nhận được một số công việc. Sự phân phối luồng giữa cùng một trao đổi Luồng phân vùng và Bộ lọc rất khác nhau:
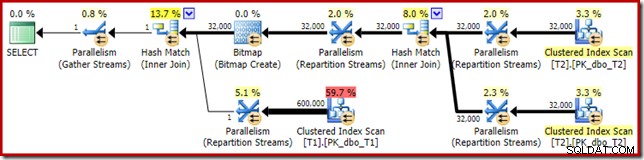
Điều này cho thấy rằng tất cả 32.000 hàng từ bảng T2 đã được xử lý bởi một luồng duy nhất. Để biết lý do tại sao, chúng ta cần xem xét các thuộc tính trao đổi:

Trao đổi này, giống như trao đổi ở phía thăm dò của tham gia băm, cần đảm bảo rằng các hàng có cùng giá trị khóa tham gia kết thúc tại cùng một phiên bản của tham gia băm. Tại DOP 4, có bốn phép tham gia băm, mỗi liên kết có bảng băm riêng. Để có kết quả chính xác, các hàng bên xây dựng và hàng bên thăm dò có cùng khóa nối phải đến cùng một phép nối băm; nếu không, chúng tôi có thể kiểm tra một hàng phía thăm dò so với bảng băm sai.
Trong kế hoạch song song chế độ hàng, SQL Server đạt được điều này bằng cách phân vùng lại cả hai đầu vào bằng cách sử dụng cùng một hàm băm trên các cột nối. Trong trường hợp hiện tại, phép nối nằm trên cột c1, vì vậy các đầu vào được phân phối trên các luồng bằng cách áp dụng một hàm băm (kiểu phân vùng:băm) cho cột khóa tham gia (c1). Vấn đề ở đây là cột c1 chỉ chứa một giá trị duy nhất - null - trong bảng T2, vì vậy tất cả 32.000 hàng được cung cấp cùng một giá trị băm, vì vậy tất cả đều kết thúc trên cùng một chuỗi.
Tin tốt là không có điều nào thực sự quan trọng đối với truy vấn này. Bộ lọc viết lại sau tối ưu hóa loại bỏ tất cả các hàng trước khi hoàn thành rất nhiều công việc. Trên máy tính xách tay của tôi, truy vấn ở trên thực thi (không tạo ra kết quả như mong đợi) trong khoảng 70 mili giây .
Nối ba bảng
Đối với thử nghiệm thứ hai, chúng tôi thêm một phép nối bổ sung từ bảng T2 vào chính nó trên khóa chính của nó:
SELECT T1.pk FROM dbo.T1 AS T1 JOIN dbo.T2 AS T2 ON T2.c1 = T1.c1 JOIN dbo.T2 AS T3 -- New! ON T3.pk = T2.pk;
Điều này không thay đổi kết quả logic của truy vấn, nhưng nó thay đổi kế hoạch thực thi:
Như mong đợi, việc tự nối bảng T2 trên khóa chính của nó không ảnh hưởng đến số hàng đủ điều kiện từ bảng đó:
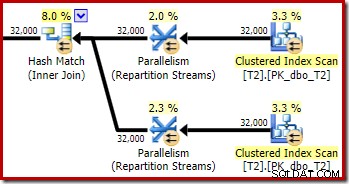
Việc phân phối các hàng trên các chủ đề cũng tốt trong phần kế hoạch này. Đối với quá trình quét, nó tương tự như trước đây vì quá trình quét song song phân phối các hàng thành các luồng theo yêu cầu. Các trao đổi phân vùng lại dựa trên một băm của khóa tham gia, đó là cột pk lần này. Với phạm vi giá trị pk khác nhau, phân phối luồng kết quả cũng rất đồng đều:
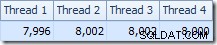
Chuyển sang phần thú vị hơn của kế hoạch ước tính, có một số khác biệt so với thử nghiệm hai bảng:

Một lần nữa, trao đổi phía xây dựng kết thúc định tuyến tất cả các hàng đến cùng một luồng vì c1 là khóa tham gia và do đó cột phân vùng cho các trao đổi Luồng phân vùng lại (hãy nhớ, c1 là null cho tất cả các hàng trong bảng T2).
Có hai điểm khác biệt quan trọng khác trong phần này của kế hoạch so với phần kiểm tra trước. Đầu tiên, không có Bộ lọc nào để loại bỏ các hàng null-c1 từ phía bản dựng của phép nối băm. Lời giải thích cho điều đó gắn liền với sự khác biệt thứ hai - Bitmap đã thay đổi, mặc dù nó không rõ ràng từ hình trên:
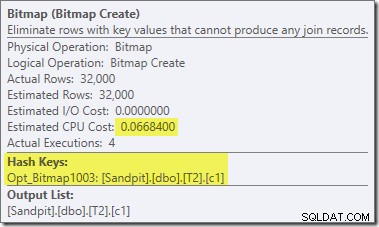
Đây là Opt_Bitmap, không phải Bitmap. Sự khác biệt là bitmap này được giới thiệu trong quá trình tối ưu hóa dựa trên chi phí, không phải bằng cách viết lại vào phút cuối. Cơ chế coi bitmap được tối ưu hóa được liên kết với việc xử lý các truy vấn nối sao. Logic kết hợp theo dấu sao yêu cầu ít nhất ba bảng được kết hợp, vì vậy điều này giải thích lý do tại sao được tối ưu hóa bitmap không được xem xét trong ví dụ về nối hai bảng.
Bitmap được tối ưu hóa này có chi phí CPU ước tính khác 0 và ảnh hưởng trực tiếp đến kế hoạch tổng thể do trình tối ưu hóa chọn. Tác động của nó đối với ước tính số lượng phía đầu dò có thể được nhìn thấy tại toán tử Luồng phân vùng:
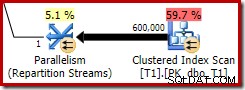
Lưu ý rằng hiệu ứng cardinality được nhìn thấy tại trao đổi, mặc dù bitmap cuối cùng đã được đẩy xuống toàn bộ công cụ lưu trữ ('INROW') giống như chúng ta đã thấy trong thử nghiệm đầu tiên (nhưng hãy lưu ý tham chiếu Opt_Bitmap ngay bây giờ):
Kế hoạch sau khi thực hiện ('thực tế') như sau:
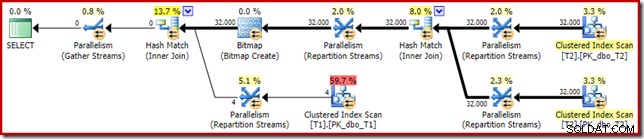
Hiệu quả dự đoán của bitmap được tối ưu hóa có nghĩa là việc viết lại sau tối ưu hóa riêng biệt cho Bộ lọc rỗng không được áp dụng. Cá nhân tôi nghĩ rằng điều này là không may vì việc loại bỏ các null sớm bằng Bộ lọc sẽ phủ nhận nhu cầu xây dựng bitmap, điền các bảng băm và thực hiện quét bảng T1 nâng cao bitmap. Tuy nhiên, trình tối ưu hóa quyết định khác và không có gì phải tranh cãi với nó trong trường hợp này.
Mặc dù có thêm tự tham gia của bảng T2 và công việc bổ sung liên quan đến Bộ lọc bị thiếu, kế hoạch thực thi này vẫn tạo ra kết quả như mong đợi (không có hàng) trong thời gian nhanh chóng. Một quá trình thực thi điển hình trên máy tính xách tay của tôi mất khoảng 200ms .
Thay đổi kiểu dữ liệu
Đối với thử nghiệm thứ ba này, chúng tôi sẽ thay đổi kiểu dữ liệu của cột c1 trong cả hai bảng từ số nguyên sang số thập phân. Không có gì đặc biệt về sự lựa chọn này; hiệu ứng tương tự có thể được nhìn thấy với bất kỳ kiểu số nào không phải là số nguyên hoặc bigint.
ALTER TABLE dbo.T1 ALTER COLUMN c1 decimal(9,0) NULL; ALTER TABLE dbo.T2 ALTER COLUMN c1 decimal(9,0) NULL; ALTER INDEX PK_dbo_T1 ON dbo.T1 REBUILD WITH (MAXDOP = 1); ALTER INDEX PK_dbo_T2 ON dbo.T2 REBUILD WITH (MAXDOP = 1); UPDATE STATISTICS dbo.T1 WITH FULLSCAN; UPDATE STATISTICS dbo.T2 WITH FULLSCAN;
Sử dụng lại truy vấn nối ba phép:
SELECT T1.pk FROM dbo.T1 AS T1 JOIN dbo.T2 AS T2 ON T2.c1 = T1.c1 JOIN dbo.T2 AS T3 ON T3.pk = T2.pk;
Kế hoạch thực hiện ước tính trông rất quen thuộc:
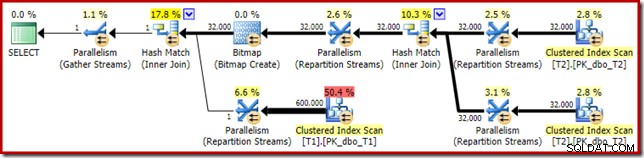
Ngoài thực tế là bitmap được tối ưu hóa không còn có thể được áp dụng 'INROW' bởi công cụ lưu trữ do sự thay đổi của kiểu dữ liệu, kế hoạch thực thi về cơ bản giống hệt nhau. Hình chụp bên dưới cho thấy sự thay đổi trong các thuộc tính quét:
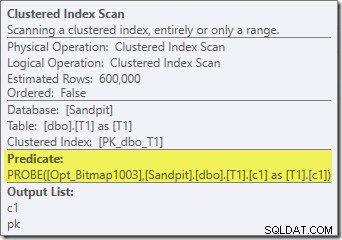
Thật không may, hiệu suất bị ảnh hưởng khá nhiều. Truy vấn này thực thi không phải trong 70 mili giây hoặc 200 mili giây mà trong khoảng 20 phút . Trong thử nghiệm đưa ra kế hoạch hậu thực thi sau đây, thời gian chạy thực tế là 22 phút 29 giây:

Sự khác biệt rõ ràng nhất là Quét chỉ mục theo cụm trên bảng T1 trả về 300.000 hàng ngay cả sau khi bộ lọc bitmap được tối ưu hóa được áp dụng. Điều này có ý nghĩa, vì bitmap được xây dựng trên các hàng chỉ chứa rỗng trong cột c1. Bitmap loại bỏ các hàng không null khỏi quá trình quét T1, chỉ để lại 300.000 hàng có giá trị null cho c1. Hãy nhớ rằng, một nửa số hàng trong T1 là rỗng.
Mặc dù vậy, có vẻ kỳ lạ là việc kết hợp 32.000 hàng với 300.000 hàng sẽ mất hơn 20 phút. Trong trường hợp bạn đang thắc mắc, một lõi CPU đã được chốt ở mức 100% cho toàn bộ quá trình thực thi. Lời giải thích cho hiệu suất kém và việc sử dụng tài nguyên quá mức này dựa trên một số ý tưởng mà chúng tôi đã khám phá trước đó:
Ví dụ, chúng ta đã biết rằng mặc dù có các biểu tượng thực thi song song, tất cả các hàng từ T2 đều kết thúc trên cùng một luồng. Xin nhắc lại, phép nối băm song song chế độ hàng yêu cầu phân vùng lại trên các cột nối (c1). Tất cả các hàng từ T2 có cùng giá trị - null - trong cột c1, vì vậy tất cả các hàng kết thúc trên cùng một chủ đề. Tương tự, tất cả các hàng từ T1 vượt qua bộ lọc bitmap cũng có giá trị rỗng trong cột c1, vì vậy chúng cũng phân vùng lại cho cùng một chủ đề. Điều này giải thích tại sao một lõi duy nhất thực hiện tất cả công việc.
Vẫn có vẻ không hợp lý khi băm kết hợp 32.000 hàng với 300.000 hàng sẽ mất 20 phút, đặc biệt là vì các cột tham gia ở cả hai bên đều rỗng và sẽ không tham gia. Để hiểu điều này, chúng ta cần suy nghĩ về cách hoạt động của phép nối băm này.
Đầu vào xây dựng (32.000 hàng) tạo một bảng băm bằng cách sử dụng cột nối, c1. Vì mọi hàng phía bản dựng đều chứa cùng một giá trị (null) cho cột tham gia c1, điều này có nghĩa là tất cả 32.000 hàng kết thúc trong cùng một nhóm băm. Khi tham gia băm chuyển sang dò tìm các trận đấu, mỗi hàng bên thăm dò có cột c1 rỗng cũng băm vào cùng một nhóm. Sau đó, tham gia băm phải kiểm tra tất cả 32.000 mục nhập trong nhóm đó xem có khớp không.
Kiểm tra 300.000 hàng thăm dò dẫn đến 32.000 lần so sánh được thực hiện 300.000 lần. Đây là trường hợp xấu nhất đối với một phép nối băm:Tất cả các hàng bên xây dựng đều băm vào cùng một nhóm, dẫn đến về cơ bản là một sản phẩm Descartes. Điều này giải thích thời gian thực thi dài và việc sử dụng bộ xử lý 100% không đổi vì hàm băm tuân theo chuỗi thùng băm dài.
Hiệu suất kém này giúp giải thích lý do tại sao việc viết lại sau tối ưu hóa để loại bỏ các giá trị rỗng trên đầu vào bản dựng thành một phép nối băm tồn tại. Rất tiếc là Bộ lọc không được áp dụng trong trường hợp này.
Giải pháp thay thế
Trình tối ưu hóa chọn hình dạng kế hoạch này vì nó ước tính không chính xác rằng bitmap được tối ưu hóa sẽ lọc ra tất cả các hàng từ bảng T1. Mặc dù ước tính này được hiển thị tại Luồng phân vùng thay vì Quét chỉ mục theo cụm, nhưng đây vẫn là cơ sở để đưa ra quyết định. Xin nhắc lại ở đây là phần có liên quan của kế hoạch trước khi thực hiện:
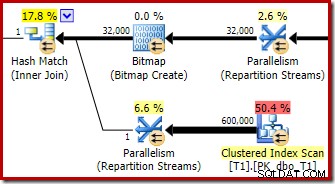
Nếu đây là một ước tính chính xác, sẽ không mất chút thời gian nào để xử lý phép nối băm. Thật không may là ước tính chọn lọc cho bitmap được tối ưu hóa rất sai khi kiểu dữ liệu không phải là một số nguyên đơn giản hoặc bigint. Có vẻ như một bitmap được xây dựng trên một số nguyên hoặc khóa bigint cũng có thể lọc ra các hàng rỗng không thể tham gia. Nếu thực sự đúng như vậy, thì đây là lý do chính để thích các cột nối số nguyên hoặc bigint.
Các giải pháp tiếp theo phần lớn dựa trên ý tưởng loại bỏ các bitmap được tối ưu hóa có vấn đề.
Thực thi nối tiếp
Một cách để ngăn chặn các ảnh bitmap được tối ưu hóa đang được xem xét là yêu cầu một kế hoạch không song song. Các toán tử Bitmap ở chế độ hàng (được tối ưu hóa hoặc cách khác) chỉ được nhìn thấy trong các kế hoạch song song:
SELECT T1.pk
FROM
(
dbo.T2 AS T2
JOIN dbo.T2 AS T3
ON T3.pk = T2.pk
)
JOIN dbo.T1 AS T1
ON T1.c1 = T2.c1
OPTION (MAXDOP 1, FORCE ORDER); Truy vấn đó được thể hiện bằng cú pháp hơi khác với gợi ý LỆNH LỆNH để tạo ra một hình dạng kế hoạch dễ dàng so sánh hơn với các kế hoạch song song trước đó. Tính năng cần thiết là gợi ý MAXDOP 1.
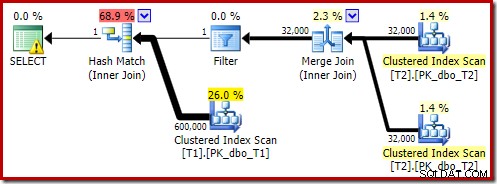
Kế hoạch ước tính đó cho thấy Bộ lọc ghi lại sau tối ưu hóa đang được khôi phục:
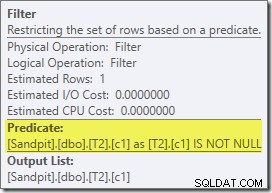
Phiên bản sau khi thực hiện của kế hoạch cho thấy rằng nó lọc ra tất cả các hàng từ đầu vào bản dựng, có nghĩa là có thể bỏ qua hoàn toàn quá trình quét phía đầu dò:
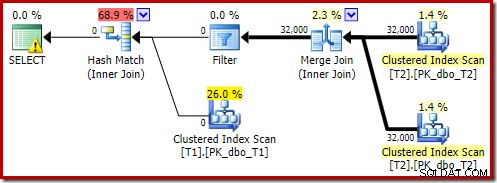
Như bạn mong đợi, phiên bản này của truy vấn thực thi rất nhanh - trung bình khoảng 20ms đối với tôi. Chúng tôi có thể đạt được hiệu quả tương tự mà không cần gợi ý LỆNH LỆNH và ghi lại truy vấn:
SELECT T1.pk FROM dbo.T1 AS T1 JOIN dbo.T2 AS T2 ON T2.c1 = T1.c1 JOIN dbo.T2 AS T3 ON T3.pk = T2.pk OPTION (MAXDOP 1);
Trình tối ưu hóa chọn một hình dạng kế hoạch khác trong trường hợp này, với Bộ lọc được đặt ngay phía trên bản quét của T2:
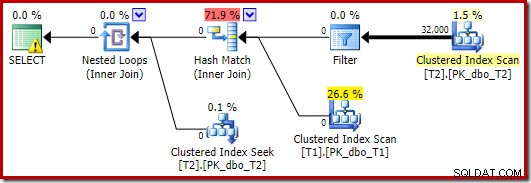
Quá trình này thậm chí còn nhanh hơn - trong khoảng 10ms - như người ta mong đợi. Đương nhiên, đây sẽ không phải là một lựa chọn tốt nếu số lượng hàng hiện tại (và có thể ghép nối) lớn hơn nhiều.
Tắt Bitmap được Tối ưu hóa
Không có gợi ý truy vấn nào để tắt bitmap được tối ưu hóa, nhưng chúng ta có thể đạt được hiệu quả tương tự bằng cách sử dụng một vài cờ theo dõi không có tài liệu. Như mọi khi, điều này chỉ dành cho giá trị lãi suất; bạn sẽ không muốn sử dụng chúng trong một hệ thống hoặc ứng dụng thực:
SELECT T1.pk FROM dbo.T1 AS T1 JOIN dbo.T2 AS T2 ON T2.c1 = T1.c1 JOIN dbo.T2 AS T3 ON T3.pk = T2.pk OPTION (QUERYTRACEON 7497, QUERYTRACEON 7498);
Kế hoạch thực hiện kết quả là:
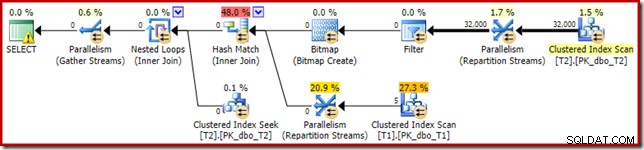
Bitmap có một bitmap viết lại sau tối ưu hóa, không phải là một bitmap được tối ưu hóa:
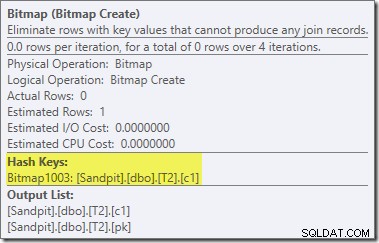
Lưu ý ước tính chi phí bằng 0 và tên Bitmap (thay vì Opt_Bitmap). mà không có một bitmap được tối ưu hóa để làm sai lệch ước tính chi phí, việc ghi lại sau tối ưu hóa để bao gồm Bộ lọc từ chối rỗng sẽ được kích hoạt. Kế hoạch thực thi này chạy trong khoảng 70 mili giây .
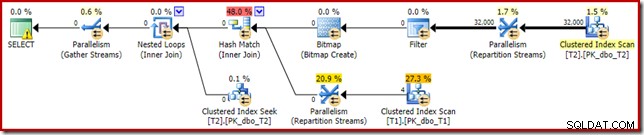
Kế hoạch thực thi tương tự (với Bộ lọc và Bitmap không được tối ưu hóa) cũng có thể được tạo ra bằng cách tắt quy tắc trình tối ưu hóa chịu trách nhiệm tạo các kế hoạch bitmap nối sao (một lần nữa, hoàn toàn không có tài liệu và không sử dụng trong thế giới thực):
SELECT T1.pk FROM dbo.T1 AS T1 JOIN dbo.T2 AS T2 ON T2.c1 = T1.c1 JOIN dbo.T2 AS T3 ON T3.pk = T2.pk OPTION (QUERYRULEOFF StarJoinToHashJoinsWithBitmap);
Bao gồm một bộ lọc rõ ràng
Đây là lựa chọn đơn giản nhất, nhưng người ta chỉ nghĩ là làm được nếu nhận thức được các vấn đề được thảo luận cho đến nay. Bây giờ chúng ta biết rằng chúng ta cần loại bỏ null khỏi T2.c1, chúng ta có thể thêm nó vào truy vấn trực tiếp:
SELECT T1.pk
FROM dbo.T1 AS T1
JOIN dbo.T2 AS T2
ON T2.c1 = T1.c1
JOIN dbo.T2 AS T3
ON T3.pk = T2.pk
WHERE
T2.c1 IS NOT NULL; -- New! Kế hoạch thực hiện ước tính kết quả có lẽ không hoàn toàn như những gì bạn có thể mong đợi:
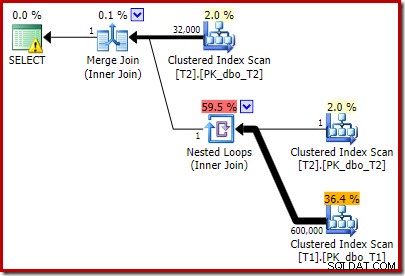
Vị từ bổ sung mà chúng tôi thêm vào đã được đẩy vào Quét chỉ mục được phân cụm ở giữa của T2:
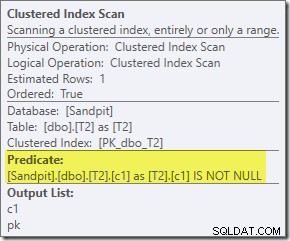
Kế hoạch sau khi thực hiện là:
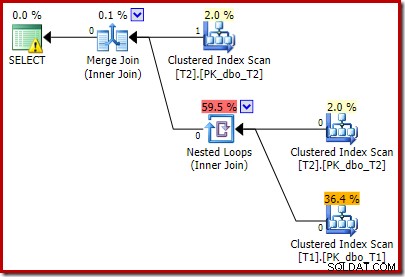
Lưu ý rằng Kết hợp hợp nhất sẽ tắt sau khi đọc một hàng từ đầu vào trên cùng của nó, sau đó không tìm thấy hàng ở đầu vào thấp hơn của nó, do ảnh hưởng của vị từ mà chúng tôi đã thêm. Quá trình quét chỉ mục theo cụm của bảng T1 hoàn toàn không được thực thi, vì phép nối Vòng lặp lồng nhau không bao giờ có một hàng trên đầu vào dẫn động của nó. Biểu mẫu truy vấn cuối cùng này thực thi trong một hoặc hai mili giây.
Suy nghĩ cuối cùng
Bài viết này đã trình bày một lượng cơ sở hợp lý để khám phá một số hành vi của trình tối ưu hóa truy vấn ít nổi tiếng hơn và giải thích lý do cho hiệu suất kết hợp băm cực kỳ kém trong một trường hợp cụ thể.
Có thể bạn muốn hỏi tại sao trình tối ưu hóa không thường xuyên thêm bộ lọc từ chối rỗng trước khi nối bình đẳng. Người ta chỉ có thể cho rằng điều này sẽ không có lợi trong những trường hợp phổ biến. Hầu hết các phép nối sẽ không gặp phải nhiều từ chối null =null và việc thêm các vị từ thường xuyên có thể nhanh chóng trở nên phản tác dụng, đặc biệt nếu có nhiều cột nối. Đối với hầu hết các phép nối, việc từ chối các giá trị null bên trong toán tử phép nối có lẽ là một lựa chọn tốt hơn (từ góc độ mô hình chi phí) so với việc giới thiệu một Bộ lọc rõ ràng.
Có vẻ như có một nỗ lực để ngăn những trường hợp xấu nhất biểu hiện thông qua việc viết lại sau tối ưu hóa được thiết kế để từ chối các hàng nối rỗng trước khi chúng tiếp cận đầu vào xây dựng của phép nối băm. Có vẻ như tồn tại một sự tương tác đáng tiếc giữa tác động của các bộ lọc bitmap được tối ưu hóa và ứng dụng của việc viết lại này. Cũng không may là khi sự cố hiệu suất này xảy ra, rất khó để chẩn đoán chỉ từ kế hoạch thực thi.
Hiện tại, lựa chọn tốt nhất dường như đã biết về vấn đề hiệu suất tiềm ẩn này với các phép nối băm trên các cột có thể làm trống và thêm các vị từ từ chối null rõ ràng (kèm theo nhận xét!) Để đảm bảo tạo ra một kế hoạch thực thi hiệu quả, nếu cần. Sử dụng gợi ý MAXDOP 1 cũng có thể tiết lộ một kế hoạch thay thế với Bộ lọc kể chuyện hiện có.
Theo quy tắc chung, các truy vấn kết hợp trên các cột kiểu số nguyên và tìm kiếm dữ liệu tồn tại có xu hướng phù hợp với mô hình trình tối ưu hóa và khả năng của công cụ thực thi hơn là tốt hơn các lựa chọn thay thế.
Lời cảm ơn
Tôi muốn cảm ơn SQL_Sasquatch (@sqL_handLe) vì anh ấy đã cho phép phản hồi bài viết gốc của anh ấy với một phân tích kỹ thuật. Dữ liệu mẫu được sử dụng ở đây chủ yếu dựa trên bài báo đó.
Tôi cũng muốn cảm ơn Rob Farley (blog | twitter) vì các cuộc thảo luận kỹ thuật của chúng tôi trong những năm qua, và đặc biệt là một cuộc thảo luận vào tháng 1 năm 2015, nơi chúng tôi đã thảo luận về tác động của các vị từ từ chối bổ sung đối với các phép nối tương đương. Rob đã viết về các chủ đề liên quan nhiều lần, bao gồm cả trong Dự đoán nghịch đảo - hãy xem xét cả hai cách trước khi bạn vượt qua.