Tôi đã viết trước đây về thuộc tính Đọc hàng thực tế. Nó cho bạn biết có bao nhiêu hàng thực sự được đọc bởi một Index Seek, để bạn có thể thấy mức độ chọn lọc của Vị từ tìm kiếm, so với mức độ chọn lọc của Vị từ tìm kiếm cộng với Vị từ dư được kết hợp.
Nhưng chúng ta hãy xem điều gì đang thực sự diễn ra bên trong toán tử Seek. Bởi vì tôi không tin rằng “Đọc hàng thực tế” nhất thiết phải là mô tả chính xác về những gì đang diễn ra.
Tôi muốn xem xét một ví dụ truy vấn địa chỉ của các loại địa chỉ cụ thể cho khách hàng, nhưng nguyên tắc ở đây sẽ dễ dàng áp dụng cho nhiều trường hợp khác nếu hình dạng truy vấn của bạn phù hợp, chẳng hạn như tìm kiếm các thuộc tính trong bảng Cặp khóa-giá trị, chẳng hạn.
SELECT AddressTypeID, FullAddress FROM dbo.Addresses WHERE CustomerID = 783 AND AddressTypeID IN (2,4,5);
Tôi biết tôi chưa cho bạn thấy bất cứ điều gì về siêu dữ liệu - Tôi sẽ quay lại điều đó sau một phút. Hãy cùng suy nghĩ về truy vấn này và loại chỉ mục nào chúng tôi muốn có cho nó.
Thứ nhất, chúng tôi biết chính xác ID khách hàng. Một đối sánh bình đẳng như thế này thường làm cho nó trở thành một ứng cử viên xuất sắc cho cột đầu tiên trong một chỉ mục. Nếu chúng tôi có một chỉ mục trên cột này, chúng tôi có thể đi thẳng vào địa chỉ của khách hàng đó - vì vậy tôi muốn nói rằng đó là một giả định an toàn.
Điều tiếp theo cần xem xét là bộ lọc trên AddressTypeID. Thêm cột thứ hai vào các khóa của chỉ mục của chúng tôi là hoàn toàn hợp lý, vì vậy hãy làm điều đó. Chỉ mục của chúng tôi hiện đang ở trên (CustomerID, AddressTypeID). Và hãy BAO GỒM cả FullAddress để chúng tôi không cần thực hiện bất kỳ thao tác tra cứu nào để hoàn thành bức tranh.
Và tôi nghĩ rằng chúng tôi đã hoàn thành. Chúng ta có thể giả định một cách an toàn rằng chỉ mục lý tưởng cho truy vấn này là:
CREATE INDEX ixIdealIndex ON dbo.Addresses (CustomerID, AddressTypeID) INCLUDE (FullAddress);
Chúng tôi có thể tuyên bố nó là một chỉ mục duy nhất - chúng tôi sẽ xem xét tác động của điều đó sau.
Vì vậy, chúng ta hãy tạo một bảng (tôi đang sử dụng tempdb, vì tôi không cần nó tồn tại sau bài đăng blog này) và kiểm tra điều này.
CREATE TABLE dbo.Addresses ( AddressID INT IDENTITY(1,1) PRIMARY KEY, CustomerID INT NOT NULL, AddressTypeID INT NOT NULL, FullAddress NVARCHAR(MAX) NOT NULL, SomeOtherColumn DATE NULL );
Tôi không quan tâm đến các ràng buộc khóa ngoại hoặc các cột khác có thể có. Tôi chỉ quan tâm đến Chỉ số lý tưởng của mình. Vì vậy, hãy tạo quá trình đó, nếu bạn chưa làm.
Kế hoạch của tôi có vẻ khá hoàn hảo.
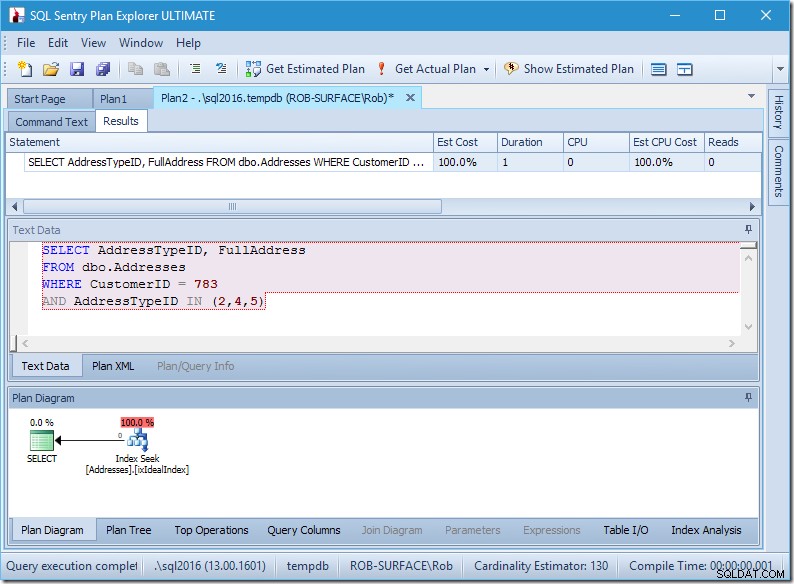
Tôi có một cuộc tìm kiếm chỉ mục, và thế là xong.
Đúng là không có dữ liệu nên không có lần đọc, không có CPU và nó cũng chạy khá nhanh. Nếu chỉ có thể điều chỉnh tất cả các truy vấn như thế này.
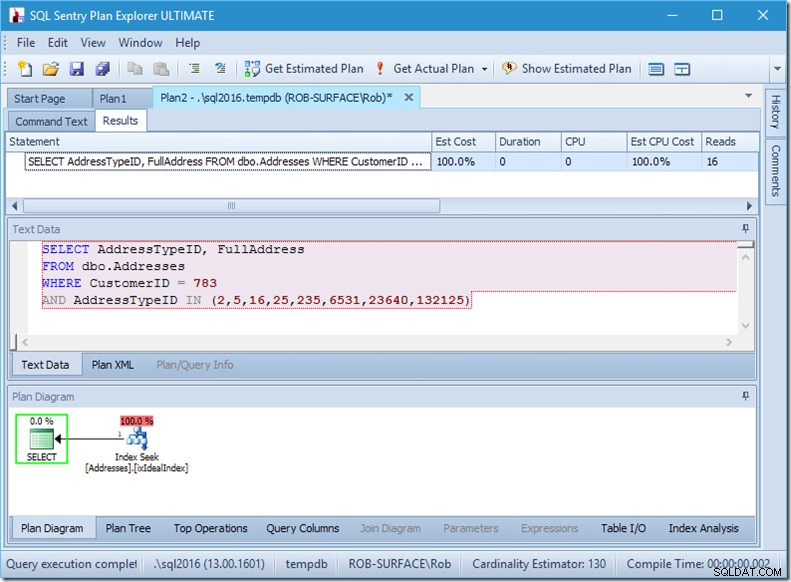
Hãy xem điều gì đang xảy ra gần hơn một chút, bằng cách xem xét các thuộc tính của Seek.
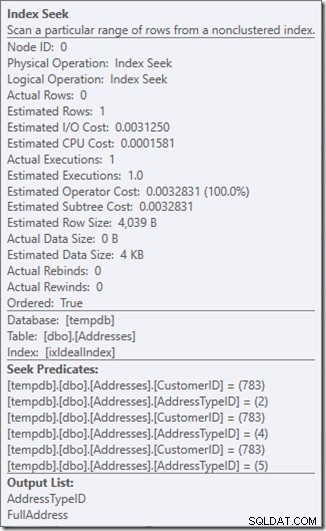
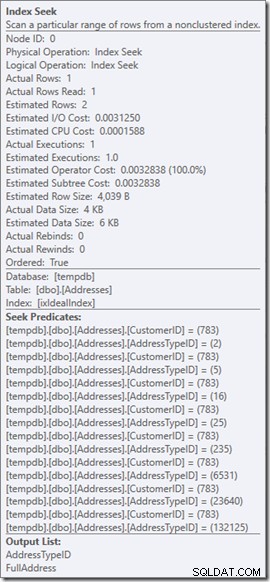
Chúng ta có thể thấy các Dự đoán Tìm kiếm. Có sáu. Ba về CustomerID và ba về AddressTypeID. Những gì chúng ta thực sự có ở đây là ba tập hợp các vị từ tìm kiếm, chỉ ra ba hoạt động tìm kiếm trong toán tử Tìm kiếm duy nhất. Lần tìm kiếm đầu tiên là tìm kiếm Khách hàng 783 và AddressType 2. Lần tìm kiếm thứ hai là tìm 783 và 4, và 783 và 5. Toán tử Tìm kiếm của chúng tôi đã xuất hiện một lần, nhưng có ba lần tìm kiếm đang diễn ra bên trong đó.
Chúng tôi thậm chí không có dữ liệu, nhưng chúng tôi có thể biết chỉ mục của chúng tôi sẽ được sử dụng như thế nào.
Hãy đưa một số dữ liệu giả vào để chúng ta có thể xem xét một số tác động của việc này. Tôi sẽ đặt địa chỉ cho các loại từ 1 đến 6. Mọi khách hàng (trên 2000, dựa trên kích thước của master..spt_values ) sẽ có địa chỉ thuộc loại 1. Có thể đó là Địa chỉ chính. Tôi đang để 80% có địa chỉ loại 2, 60% là loại 3, v.v., lên đến 20% cho loại 5. Hàng 783 sẽ nhận được địa chỉ loại 1, 2, 3 và 4, nhưng không phải là 5. Tôi thà chọn các giá trị ngẫu nhiên, nhưng tôi muốn đảm bảo rằng chúng ta đang ở trên cùng một trang để lấy các ví dụ.
WITH nums AS (
SELECT row_number() OVER (ORDER BY (SELECT 1)) AS num
FROM master..spt_values
)
INSERT dbo.Addresses (CustomerID, AddressTypeID, FullAddress)
SELECT num AS CustomerID, 1 AS AddressTypeID, N'Some sample text for the address' AS FullAddress
FROM nums
UNION ALL
SELECT num AS CustomerID, 2 AS AddressTypeID, N'Some sample text for the address' AS FullAddress
FROM nums
WHERE num % 10 < 8
UNION ALL
SELECT num AS CustomerID, 3 AS AddressTypeID, N'Some sample text for the address' AS FullAddress
FROM nums
WHERE num % 10 < 6
UNION ALL
SELECT num AS CustomerID, 4 AS AddressTypeID, N'Some sample text for the address' AS FullAddress
FROM nums
WHERE num % 10 < 4
UNION ALL
SELECT num AS CustomerID, 5 AS AddressTypeID, N'Some sample text for the address' AS FullAddress
FROM nums
WHERE num % 10 < 2
; Bây giờ chúng ta hãy xem xét truy vấn của chúng tôi với dữ liệu. Hai hàng sắp ra. Nó giống như trước đây, nhưng bây giờ chúng tôi thấy hai hàng xuất phát từ toán tử Seek và chúng tôi thấy sáu lần đọc (ở trên cùng bên phải).
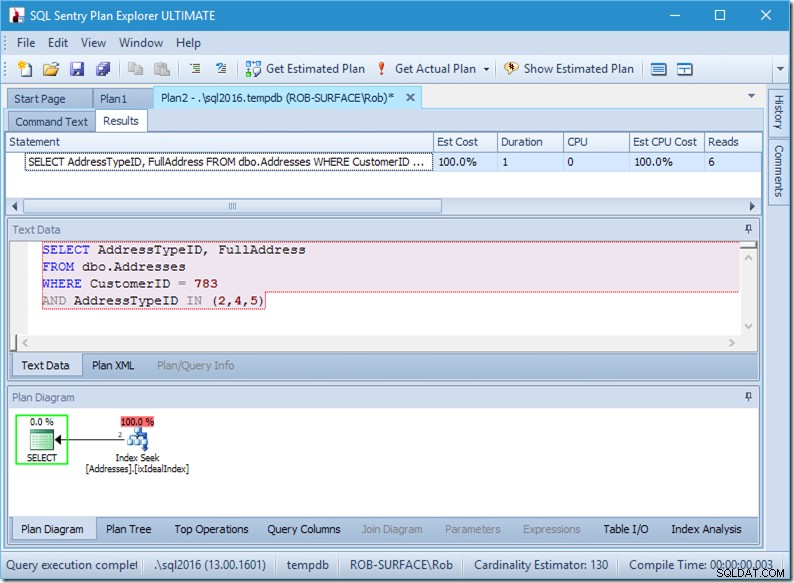
Sáu lần đọc có ý nghĩa đối với tôi. Chúng tôi có một bảng nhỏ và chỉ số vừa với hai cấp độ. Chúng tôi đang thực hiện ba lần tìm kiếm (trong một nhà điều hành của chúng tôi), vì vậy công cụ đang đọc trang gốc, tìm ra trang nào cần truy cập và đọc trang đó và thực hiện ba lần.
Nếu chúng tôi chỉ tìm kiếm hai AddressTypeID, chúng tôi sẽ chỉ thấy 4 lần đọc (và trong trường hợp này, một hàng duy nhất đang được xuất ra). Tuyệt vời.
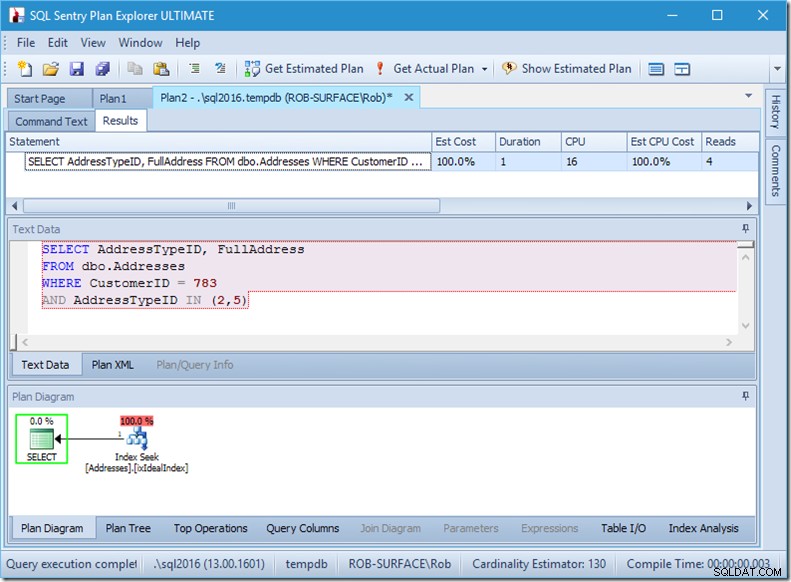
Và nếu chúng tôi đang tìm kiếm 8 loại địa chỉ, thì chúng tôi sẽ thấy 16.
Tuy nhiên, mỗi điều trong số này cho thấy rằng Số hàng thực tế đã đọc khớp chính xác với Hàng thực tế. Không hề kém hiệu quả!
Hãy quay lại truy vấn ban đầu của chúng ta, tìm kiếm các loại địa chỉ 2, 4 và 5, (trả về 2 hàng) và suy nghĩ về những gì đang diễn ra bên trong tìm kiếm.
Tôi sẽ giả sử rằng Công cụ truy vấn đã hoàn thành công việc để tìm ra rằng Tìm kiếm chỉ mục là hoạt động phù hợp và nó có số trang của gốc chỉ mục có ích.
Tại thời điểm này, nó tải trang đó vào bộ nhớ, nếu nó chưa ở đó. Đó là lần đọc đầu tiên được tính trong quá trình thực hiện tìm kiếm. Sau đó, nó xác định số trang cho hàng mà nó đang tìm kiếm và đọc trang đó. Đó là lần đọc thứ hai.
Nhưng chúng tôi thường đánh giá cao bit "định vị số trang" đó.
Bằng cách sử dụng DBCC IND(2, N'dbo.Address', 2); (2 đầu tiên là id cơ sở dữ liệu vì tôi đang sử dụng tempdb; 2 thứ hai là id chỉ mục của ixIdealIndex ), Tôi có thể phát hiện ra rằng 712 trong tệp 1 là trang có IndexLevel cao nhất. Trong ảnh chụp màn hình bên dưới, tôi có thể thấy trang 668 là IndexLevel 0, là trang gốc.

Vì vậy, bây giờ tôi có thể sử dụng DBCC TRACEON(3604); DBCC PAGE (2,1,712,3); để xem nội dung của trang 712. Trên máy tính của tôi, tôi nhận được 84 hàng trở lại và tôi có thể nói rằng CustomerID 783 sẽ ở trang 1004 của tệp 5.
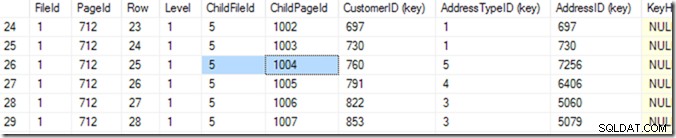
Nhưng tôi biết điều này bằng cách cuộn qua danh sách của mình cho đến khi tôi thấy danh sách mình muốn. Tôi bắt đầu bằng cách cuộn xuống một chút, và sau đó quay lại, cho đến khi tôi tìm thấy hàng mình muốn. Máy tính gọi đây là tìm kiếm nhị phân và nó chính xác hơn tôi một chút. Nó đang tìm kiếm hàng trong đó kết hợp (CustomerID, AddressTypeID) nhỏ hơn kết hợp mà tôi đang tìm kiếm, với trang tiếp theo lớn hơn hoặc giống với nó. Tôi nói "giống nhau" bởi vì có thể có hai kết quả trùng khớp, trải dài trên hai trang. Nó biết có 84 hàng (0 đến 83) dữ liệu trong trang đó (nó đọc nó trong tiêu đề trang), vì vậy nó sẽ bắt đầu bằng cách kiểm tra hàng 41. Từ đó, nó biết nửa nào để tìm kiếm và (trong ví dụ này), nó sẽ đọc hàng 20. Một vài lần đọc nữa (tổng cộng là 6 hoặc 7) * và nó biết rằng hàng 25 (vui lòng nhìn vào cột có tên 'Hàng' cho giá trị này, không phải số hàng được cung cấp bởi SSMS ) quá nhỏ, nhưng hàng 26 quá lớn - vì vậy câu trả lời là 25!
* Trong tìm kiếm nhị phân, việc tìm kiếm có thể nhanh hơn một chút nếu may mắn khi nó chia khối thành hai nếu không có vị trí ở giữa và tùy thuộc vào việc có thể loại bỏ vị trí ở giữa hay không.
Bây giờ nó có thể chuyển sang trang 1004 trong tệp 5. Hãy sử dụng DBCC PAGE trên trang đó.
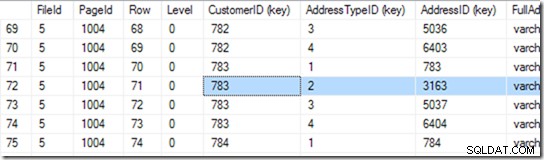
Cái này cho tôi 94 hàng. Nó thực hiện một tìm kiếm nhị phân khác để tìm điểm bắt đầu của phạm vi mà nó đang tìm kiếm. Nó phải xem qua 6 hoặc 7 hàng để tìm ra điều đó.
"Bắt đầu phạm vi?" Tôi có thể nghe bạn hỏi. Nhưng chúng tôi đang tìm kiếm địa chỉ loại 2 của khách hàng 783.
Đúng, nhưng chúng tôi không tuyên bố chỉ mục này là duy nhất. Vì vậy, có thể có hai. Nếu nó là duy nhất, tìm kiếm có thể thực hiện tìm kiếm đơn lẻ và có thể tình cờ tìm thấy nó trong quá trình tìm kiếm nhị phân, nhưng trong trường hợp này, nó phải hoàn thành tìm kiếm nhị phân, để tìm hàng đầu tiên trong phạm vi. Trong trường hợp này, đó là hàng 71.
Nhưng chúng tôi không dừng lại ở đây. Bây giờ chúng ta cần xem nếu thực sự có một cái thứ hai! Vì vậy, nó cũng đọc hàng 72 và nhận thấy rằng cặp CustomerID + AddressTypeiD thực sự quá lớn và việc tìm kiếm của nó đã được thực hiện.
Và điều này xảy ra ba lần. Lần thứ ba, nó không tìm thấy hàng cho khách hàng 783 và địa chỉ loại 5, nhưng nó không biết điều này trước thời hạn và vẫn cần hoàn thành tìm kiếm.
Vì vậy, các hàng thực sự được đọc trên ba tìm kiếm này (để tìm hai hàng để xuất ra) nhiều hơn rất nhiều so với số được trả về. Có khoảng 7 ở cấp chỉ mục 1 và khoảng 7 nữa ở cấp lá chỉ để tìm điểm bắt đầu của phạm vi. Sau đó, nó đọc hàng mà chúng ta quan tâm, rồi đến hàng sau đó. Tôi nghe có vẻ giống 16 hơn, và nó thực hiện điều này ba lần, tạo thành khoảng 48 hàng.
Nhưng Số hàng thực tế Đọc không phải là số hàng thực sự được đọc, mà là số hàng được trả về bởi Vị từ tìm kiếm, được kiểm tra so với Vị từ dư. Và trong đó, chỉ có 2 hàng được tìm thấy bởi 3 lần tìm kiếm.
Tại thời điểm này, bạn có thể nghĩ rằng có một số điểm không hiệu quả nhất định ở đây. Lần tìm kiếm thứ hai cũng sẽ đọc trang 712, kiểm tra 6 hoặc 7 hàng giống nhau ở đó, sau đó đọc trang 1004 và tìm kiếm qua nó… như lần tìm kiếm thứ ba.
Vì vậy, có lẽ sẽ tốt hơn nếu bạn có được điều này trong một lần tìm kiếm, chỉ đọc trang 712 và trang 1004 một lần. Rốt cuộc, nếu tôi đang làm điều này với một hệ thống dựa trên giấy tờ, tôi sẽ thực hiện tìm kiếm khách hàng 783, và sau đó quét qua tất cả các loại địa chỉ của họ. Bởi vì tôi biết rằng một khách hàng không có xu hướng có nhiều địa chỉ. Đó là một lợi thế của tôi so với công cụ cơ sở dữ liệu. Công cụ cơ sở dữ liệu biết thông qua số liệu thống kê của nó rằng một tìm kiếm sẽ là tốt nhất, nhưng nó không biết rằng tìm kiếm chỉ nên đi xuống một cấp, khi nó có thể cho biết rằng nó có giống như Chỉ số lý tưởng.
Nếu tôi thay đổi truy vấn của mình để lấy một loạt các loại địa chỉ, từ 2 đến 5, thì hầu như tôi sẽ có được hành vi mà tôi muốn:
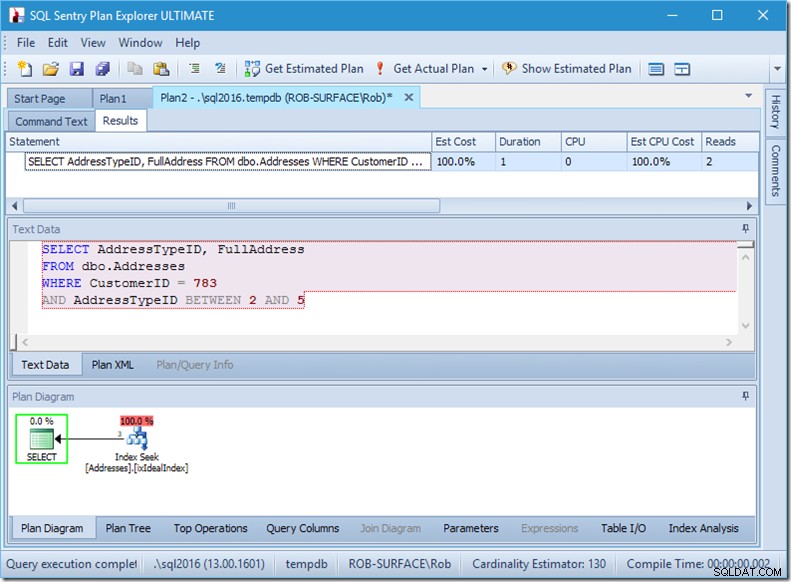
Hãy nhìn xem - số lần đọc giảm xuống còn 2, và tôi biết đó là những trang nào…
… Nhưng kết quả của tôi là sai. Bởi vì tôi chỉ muốn các loại địa chỉ 2, 4 và 5, không phải 3. Tôi cần phải nói với nó là không có 3, nhưng tôi phải cẩn thận cách tôi thực hiện việc này. Hãy xem hai ví dụ tiếp theo.
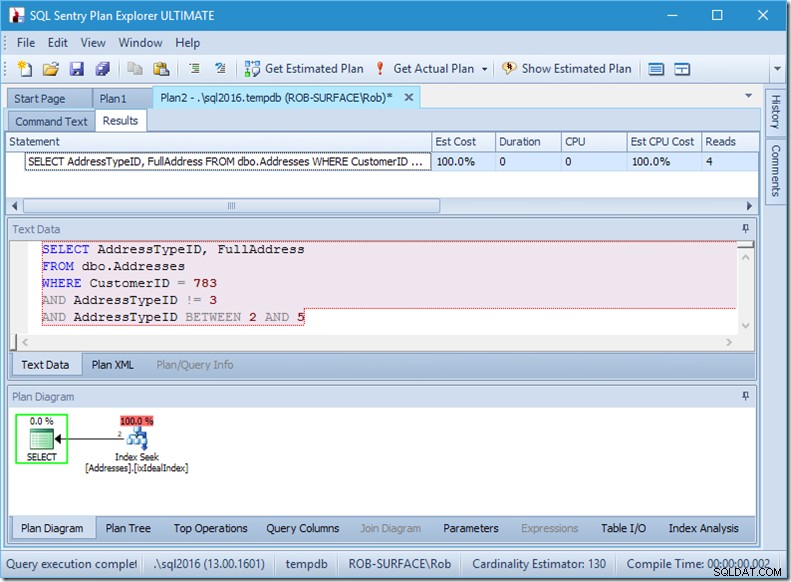
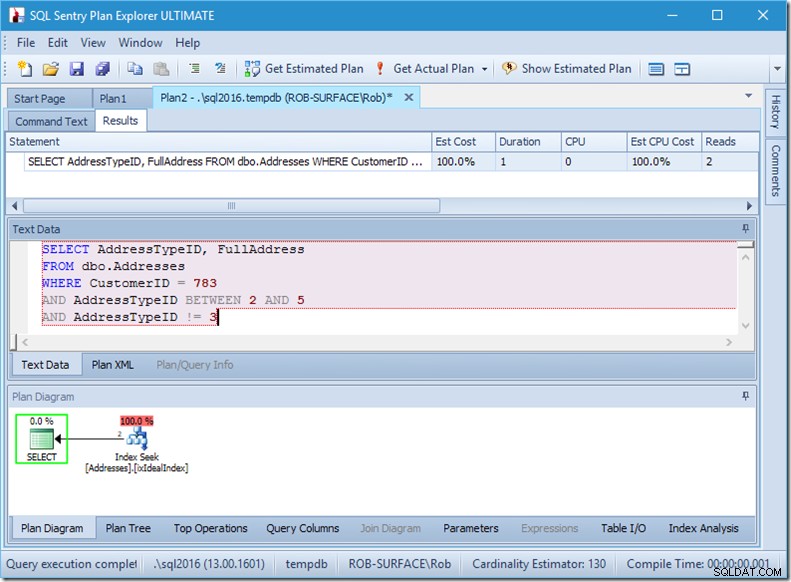
Tôi có thể đảm bảo với bạn rằng thứ tự vị ngữ không quan trọng, nhưng ở đây rõ ràng là có. Nếu chúng ta đặt "không phải 3" trước, nó thực hiện hai lần tìm kiếm (4 lần đọc), nhưng nếu chúng ta đặt "không phải 3" thứ hai, nó thực hiện một lần tìm kiếm (2 lần đọc).
Vấn đề là AddressTypeID! =3 được chuyển đổi thành (AddressTypeID> 3 HOẶC AddressTypeID <3), sau đó được coi là hai vị từ tìm kiếm rất hữu ích.
Và vì vậy sở thích của tôi là sử dụng một vị từ không thể phân loại để cho nó biết rằng tôi chỉ muốn các loại địa chỉ 2, 4 và 5. Và tôi có thể làm điều đó bằng cách sửa đổi AddressTypeID theo một cách nào đó, chẳng hạn như thêm số không vào nó.
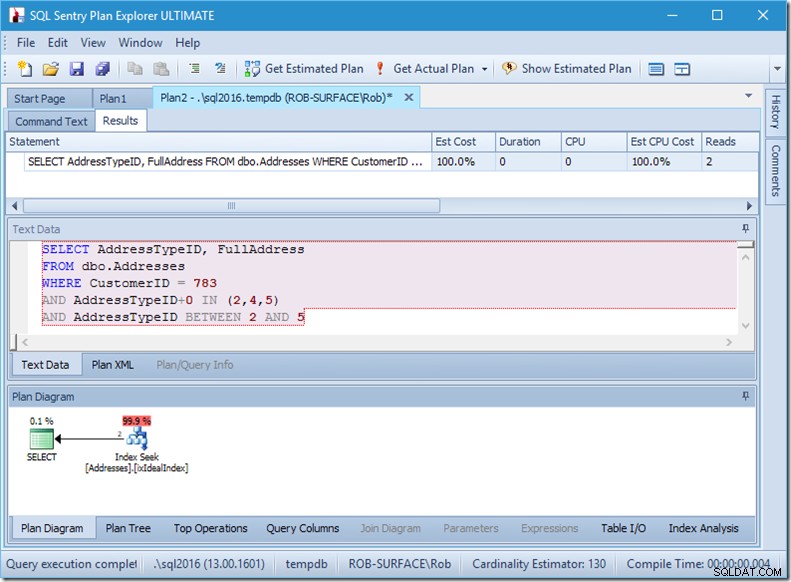
Bây giờ tôi có một bản quét phạm vi chặt chẽ và đẹp mắt trong một lần tìm kiếm duy nhất và tôi vẫn đảm bảo rằng truy vấn của tôi chỉ trả về những hàng mà tôi muốn.
Ồ, nhưng đó là thuộc tính Đọc hàng thực tế? Giá đó hiện cao hơn thuộc tính Hàng thực, bởi vì Vị trí tìm kiếm tìm thấy loại địa chỉ 3, mà Vị trí còn lại từ chối.
Tôi đã đánh đổi ba lần tìm kiếm hoàn hảo để lấy một lần tìm kiếm không hoàn hảo duy nhất, tôi đang sửa chữa bằng một vị từ còn lại.
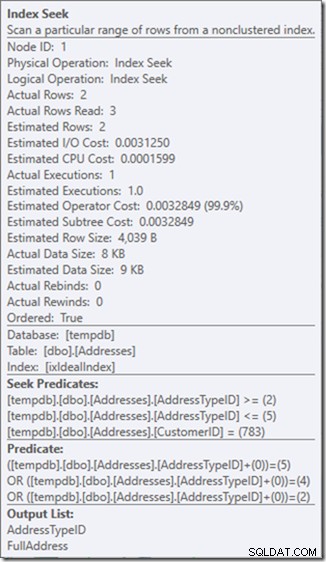
Và đối với tôi, đó đôi khi là một cái giá đáng phải trả, giúp tôi có được một kế hoạch truy vấn mà tôi hạnh phúc hơn nhiều. Nó không rẻ hơn đáng kể, mặc dù nó chỉ có một phần ba số lần đọc (vì sẽ chỉ có hai lần đọc thực tế), nhưng khi tôi nghĩ về công việc nó đang làm, tôi cảm thấy thoải mái hơn nhiều với những gì tôi đang yêu cầu. để làm theo cách này.



