[Phần 1 | Phần 2 | Phần 3]
Trong phần 1, tôi đã chỉ ra cách nén cả trang và cột trong kho lưu trữ có thể giảm kích thước của bảng 1TB xuống 80% hoặc hơn. Mặc dù tôi rất ấn tượng khi có thể thu nhỏ bảng từ 1TB xuống 50GB, nhưng tôi không hài lòng lắm với lượng thời gian nó mất (từ 2 đến 14 giờ). Với một số mẹo được mượn từ những người như Joe Obbish, Lonny Niederstadt, Niko Neugebauer và những người khác, trong bài đăng này, tôi sẽ cố gắng thực hiện một số thay đổi đối với nỗ lực ban đầu của mình để có được hiệu suất tải tốt hơn. Vì chỉ mục columnstore thông thường không nén tốt hơn nén trang trên tập dữ liệu này và mất thêm 13 giờ để đến đó, tôi sẽ chỉ tập trung vào giải pháp nâng cao hơn bằng cách sử dụng COLUMNSTORE_ARCHIVE nén.
Một số vấn đề mà tôi nghĩ rằng hiệu suất bị ảnh hưởng bao gồm:
- Lựa chọn bố cục tệp không hợp lệ - Tôi đặt 8 tệp trong một nhóm tệp, với tính năng song song nhưng không có phân vùng (hoặc dưới mức tối ưu), rải I / O qua nhiều tệp với sự bỏ qua một cách thiếu thận trọng. Để giải quyết vấn đề này, tôi sẽ:
- phân vùng bảng thành 8 phân vùng (một phân vùng trên mỗi lõi)
- đặt tệp dữ liệu của từng phân vùng vào nhóm tệp của riêng nó
- sử dụng 8 quy trình riêng biệt để liên kết với từng phân vùng
- sử dụng tính năng nén lưu trữ trên tất cả trừ phân vùng "đang hoạt động"
- quá nhiều lô nhỏ và dân số nhóm hàng dưới mức tối ưu - bằng cách xử lý 10 triệu hàng cùng một lúc, tôi đã điền chín nhóm hàng với 1.048.576 hàng đẹp, và sau đó 562.816 hàng còn lại sẽ kết thúc trong một nhóm hàng khác nhỏ hơn. Và bất kỳ sự phân phối không đồng đều nào để lại phần còn lại <102.400 hàng sẽ chèn nhỏ giọt vào cấu trúc cửa hàng delta kém hiệu quả hơn. Để phân phối các hàng đồng đều hơn và tránh lưu trữ đồng bằng, tôi sẽ:
- xử lý càng nhiều dữ liệu càng tốt theo bội số chính xác của 1.048.576 hàng
- trải đều các phân vùng đó trên 8 phân vùng càng đồng đều càng tốt
- sử dụng kích thước hàng loạt gần 10x -> 100 triệu hàng
- xếp chồng lên lịch - trong khi tôi không kiểm tra điều này, có thể một số sự chậm trễ là do một người lập lịch thực hiện quá nhiều công việc và một người lập lịch khác không đủ, do kết hợp vòng vo của người lập lịch. Bây giờ tôi sẽ cố ý tải dữ liệu với 8 quy trình maxdop 1 thay vì một quy trình maxdop 8, để giữ cho tất cả các bộ lập lịch bận rộn như nhau, tôi sẽ:
- sử dụng một quy trình được lưu trữ để cố gắng cân bằng đồng đều giữa các bộ lập lịch (xem các trang 189-191 trong Hướng dẫn của SQLCAT về:Công cụ quan hệ để có nguồn cảm hứng đằng sau ý tưởng này)
- bật cờ theo dõi toàn cầu 2467 và 2469, như được cảnh báo trong tài liệu
- tác vụ nén cột lưu trữ trong nền - thật lãng phí nếu để điều này diễn ra trong thời gian có dân số, vì dù sao thì cuối cùng tôi cũng đã lên kế hoạch xây dựng lại. Lần này tôi sẽ:
- tắt tác vụ này bằng cách sử dụng cờ theo dõi toàn cục 634
Tôi đã loại bỏ chức năng và lược đồ phân vùng ban đầu, đồng thời xây dựng một lược đồ mới dựa trên sự phân phối dữ liệu đồng đều hơn. Tôi muốn 8 phân vùng phù hợp với số lõi và số tệp dữ liệu, để tối đa hóa "tính song song của người nghèo" mà tôi định sử dụng.
Đầu tiên, chúng ta cần tạo một tập hợp nhóm tệp mới, mỗi nhóm có tệp riêng:
ALTER DATABASE OCopy ADD FILEGROUP FG_CCI_Part1; ALTER DATABASE OCopy ADD FILE (name = N'CCI_Part_1', size = 250000, filename = 'K:\Data\o_cci_p_1.mdf') TO FILEGROUP FG_CCI_Part1; -- ... 6 more ... ALTER DATABASE OCopy ADD FILEGROUP FG_CCI_Part8; ALTER DATABASE OCopy ADD FILE (name = N'CCI_Part_8', size = 250000, filename = 'K:\Data\o_cci_p_8.mdf') TO FILEGROUP FG_CCI_Part8;
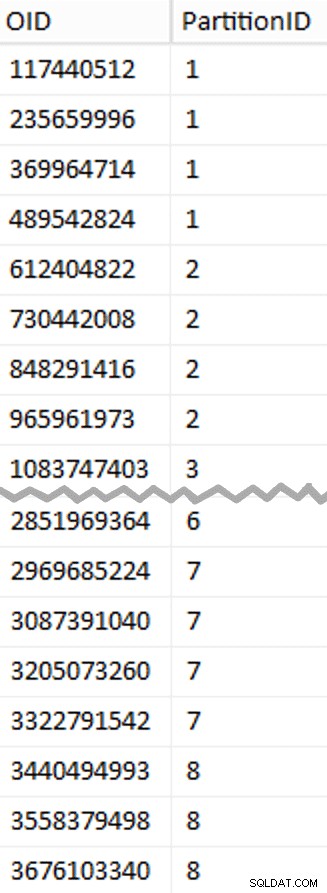
Tiếp theo, tôi nhìn vào số hàng trong bảng:3,754,965,954. Để phân phối những chính xác đồng đều trên 8 phân vùng, đó sẽ là 469.370.744,25 hàng trên mỗi phân vùng. Để làm cho nó hoạt động tốt, hãy làm cho các ranh giới phân vùng phù hợp với tiếp theo bội số của 1.048.576 hàng. Đây là 1,048,576 x 448 = 469,762,048 - đó sẽ là số hàng mà chúng tôi chụp trong 7 phân vùng đầu tiên, để lại 466.631.618 hàng trong phân vùng cuối cùng. Để xem OID thực tế các giá trị sẽ đóng vai trò là ranh giới để chứa số lượng hàng tối ưu trong mỗi phân vùng, tôi đã chạy truy vấn này so với bảng gốc (vì mất 25 phút để chạy, tôi nhanh chóng học cách chuyển các kết quả này vào một bảng riêng biệt):
;WITH x AS
(
SELECT OID, rn = ROW_NUMBER() OVER (ORDER BY OID)
FROM dbo.tblOriginal WITH (NOLOCK)
)
SELECT OID, PartitionID = 1+(rn/((1048576*448)+1))
INTO dbo.stage
FROM x
WHERE rn % (1048576*112) = 0;
 Nhiều thứ để giải nén ở đây hơn bạn có thể mong đợi. CTE thực hiện tất cả các công việc nặng nhọc, vì nó phải quét toàn bộ bảng 1,14TB và chỉ định số hàng cho mọi hàng . Tôi chỉ muốn trả lại mỗi
Nhiều thứ để giải nén ở đây hơn bạn có thể mong đợi. CTE thực hiện tất cả các công việc nặng nhọc, vì nó phải quét toàn bộ bảng 1,14TB và chỉ định số hàng cho mọi hàng . Tôi chỉ muốn trả lại mỗi (1048576*112)th mặc dù vậy, vì đây là các hàng ranh giới lô của tôi, vì vậy đây là những gì WHERE mệnh đề không. Hãy nhớ rằng tôi muốn chia công việc thành nhiều đợt gần 100 triệu hàng cùng một lúc, nhưng tôi cũng không thực sự muốn xử lý 469 triệu hàng trong một lần. Vì vậy, ngoài việc chia dữ liệu thành 8 phân vùng, tôi muốn chia từng phân vùng đó thành bốn lô 117.440.512 (1,048,576*112) hàng. Mỗi nhóm bốn lô liền kề thuộc về một phân vùng, vì vậy PartitionID Tôi dẫn xuất chỉ thêm một vào kết quả của số hàng hiện tại là số nguyên chia cho (1,048,576*448) , điều này đảm bảo rằng ranh giới luôn nằm trong tập hợp "bên trái". Sau đó, chúng tôi thêm một phân vùng vào kết quả vì nếu không, chúng tôi sẽ đề cập đến tập hợp các phân vùng dựa trên 0 và không ai muốn điều đó.
Ok, đó là rất nhiều từ. Ở bên phải là hình ảnh hiển thị nội dung (viết tắt) của stage bảng (nhấp để hiển thị toàn bộ kết quả, đánh dấu các giá trị ranh giới phân vùng).
Sau đó, chúng tôi có thể lấy một truy vấn khác từ bảng dàn dựng đó hiển thị cho chúng tôi các giá trị tối thiểu và tối đa cho mỗi lô bên trong mỗi phân vùng, cũng như lô bổ sung không được tính đến (các hàng trong bảng gốc có OID lớn hơn giá trị ranh giới cao nhất):
;WITH x AS
(
SELECT OID, PartitionID FROM dbo.stage
),
y AS
(
SELECT PartitionID,
MinID = COALESCE(LAG(OID,1) OVER (ORDER BY OID),-1)+1,
MaxID = OID
FROM x
UNION ALL
SELECT PartitionID = 8,
MinID = MAX(OID)+1,
MaxID = 4000000000 -- easier than remembering the real max
FROM x
)
SELECT PartitionID,
BatchID = ROW_NUMBER() OVER (PARTITION BY PartitionID ORDER BY MinID),
MinID,
MaxID,
RowsInRange = CONVERT(int, NULL)
INTO dbo.BatchQueue
FROM y;
-- let's not leave this as a heap:
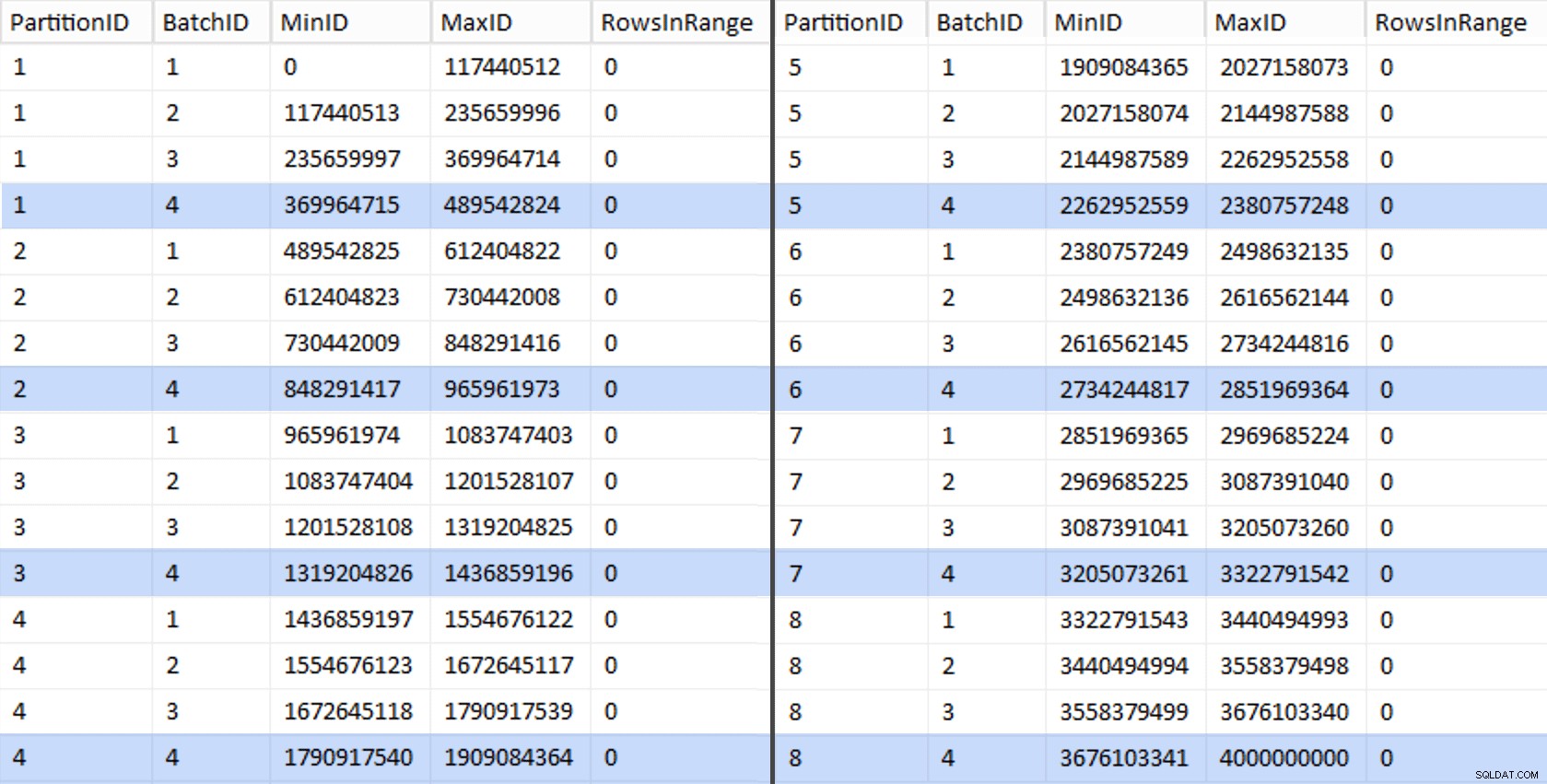
CREATE UNIQUE CLUSTERED INDEX PK_bq ON dbo.BatchQueue(PartitionID, BatchID); Các giá trị đó trông như thế này:
Để kiểm tra công việc của mình, chúng ta có thể lấy từ đó một tập hợp các truy vấn sẽ cập nhật BatchQueue với số lượng hàng thực tế từ bảng.
DECLARE @sql nvarchar(max) = N'';
SELECT @sql += 'UPDATE dbo.BatchQueue SET RowsInRange = (
SELECT COUNT(*)
FROM dbo.tblOriginal WITH (NOLOCK)
WHERE CostID BETWEEN ' + RTRIM(MinID) + ' AND ' + RTRIM(MaxID) + '
) WHERE MinID = ' + RTRIM(MinID) + ' AND MaxID = ' + RTRIM(MaxID) + ';'
FROM dbo.BatchQueue;
EXEC sys.sp_executesql @sql; Quá trình này mất khoảng 6 phút trên hệ thống của tôi. Sau đó, bạn có thể chạy truy vấn sau để cho thấy rằng mọi lô ngoại trừ lô cuối cùng có khả năng điền đầy đủ các nhóm hàng và không để lại phần còn lại cho việc sử dụng cửa hàng delta tiềm năng:
ALTER TABLE dbo.BatchQueue ADD DeltaStore AS (RowsInRange % 1048576);
Bây giờ bảng trông như thế này:
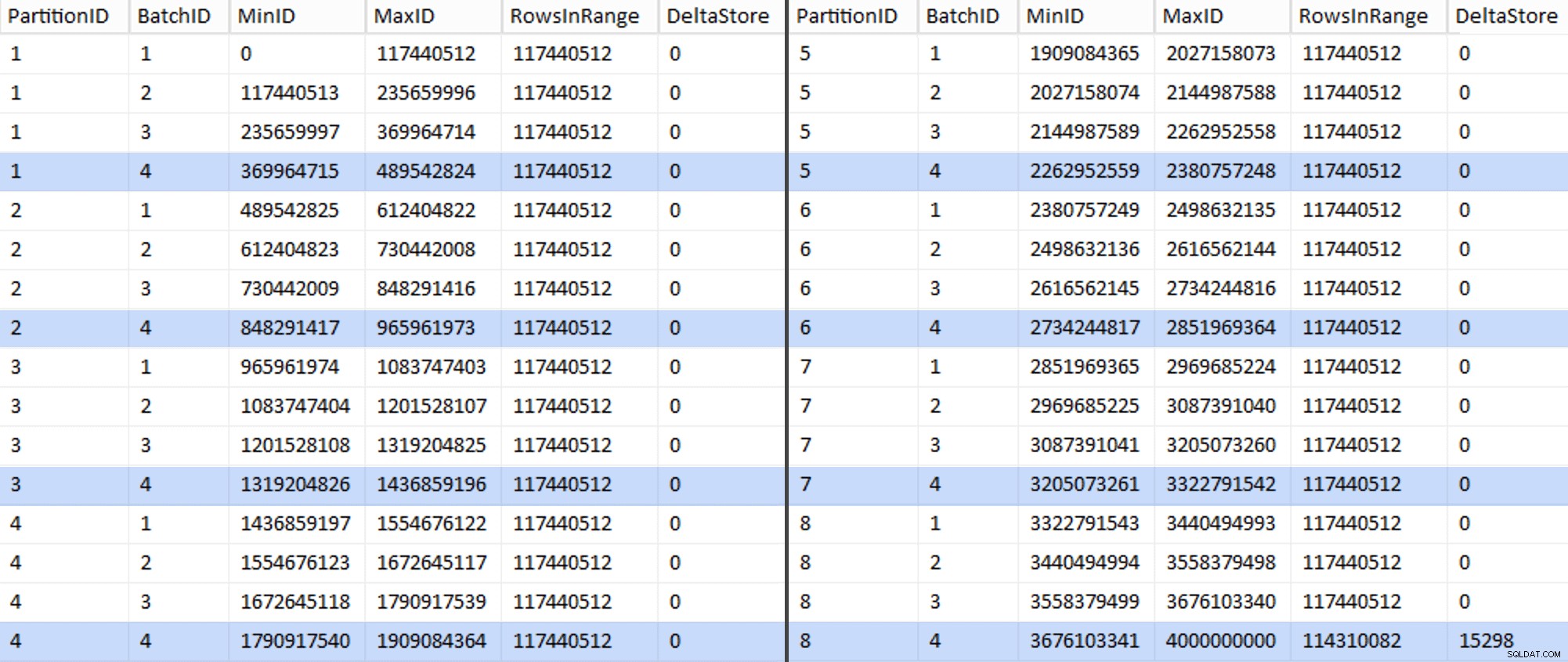
Chắc chắn, mọi lô đều có 117.440.512 triệu hàng được tính toán, ngoại trừ lô cuối cùng, ít nhất là lý tưởng, chứa kho lưu trữ delta không nén duy nhất của chúng tôi. Chúng tôi có thể cũng có thể ngăn chặn điều này, bằng cách thay đổi kích thước lô chỉ một chút cho phân vùng này để tất cả bốn lô được chạy với cùng kích thước hoặc bằng cách thay đổi số lô để phù hợp với một số bội số khác là 102.400 hoặc 1.048.576. Vì điều đó sẽ yêu cầu nhận OID mới từ bảng cơ sở, thêm 25 phút nữa cộng với nỗ lực di chuyển của chúng tôi, tôi sẽ để một phân vùng không hoàn hảo này trượt - đặc biệt là vì dù sao chúng tôi cũng không nhận được đầy đủ lợi ích nén lưu trữ từ nó.
BatchQueue bảng đang bắt đầu có dấu hiệu hữu ích cho việc xử lý các lô của chúng tôi để di chuyển dữ liệu sang bảng cột lưu trữ mới, được phân vùng, phân cụm của chúng tôi. Cái mà chúng ta cần tạo, bây giờ chúng ta đã biết ranh giới. Chỉ có 7 ranh giới, vì vậy bạn chắc chắn có thể làm điều này theo cách thủ công, nhưng tôi muốn để SQL động thực hiện công việc của tôi:
DECLARE @sql nvarchar(max) = N'';
SELECT @sql = N'CREATE PARTITION FUNCTION PF_OID([bigint])
AS RANGE LEFT FOR VALUES
(
' + STRING_AGG(MaxID, ',
') + '
);' FROM dbo.BatchQueue
WHERE PartitionID < 8
AND BatchID = 4;
PRINT @sql;
-- EXEC sys.sp_executesql @sql; Kết quả:
CREATE PARTITION FUNCTION PF_OID([bigint]) AS RANGE LEFT FOR VALUES ( 489542824, 965961973, 1436859196, 1909084364, 2380757248, 2851969364, 3322791542 );
Khi đã tạo xong, chúng ta có thể tạo lược đồ phân vùng và gán từng phân vùng kế tiếp cho tệp chuyên dụng của nó:
CREATE PARTITION SCHEME PS_OID AS PARTITION PF_OID TO ( CCI_Part1, CCI_Part2, CCI_Part3, CCI_Part4, CCI_Part5, CCI_Part6, CCI_Part7, CCI_Part8 );
Bây giờ chúng ta có thể tạo bảng và chuẩn bị sẵn sàng để di chuyển:
CREATE TABLE dbo.tblPartitionedCCI ( OID bigint NOT NULL, IN1 int NOT NULL, IN2 int NOT NULL, VC1 varchar(3) NULL, BI1 bigint NULL, IN3 int NULL, VC2 varchar(128) NOT NULL, VC3 varchar(128) NOT NULL, VC4 varchar(128) NULL, NM1 numeric(24,12) NULL, NM2 numeric(24,12) NULL, NM3 numeric(24,12) NULL, BI2 bigint NULL, IN4 int NULL, BI3 bigint NULL, NM4 numeric(24,12) NULL, IN5 int NULL, NM5 numeric(24,12) NULL, DT1 date NULL, VC5 varchar(128) NULL, BI4 bigint NULL, BI5 bigint NULL, BI6 bigint NULL, BT1 bit NOT NULL, NV1 nvarchar(512) NULL, VB1 varbinary(8000) NULL, IN6 int NULL, IN7 int NULL, IN8 int NULL, -- need to create a PK constraint on the partition scheme... CONSTRAINT PK_CCI_Part PRIMARY KEY CLUSTERED (OID) ON PS_OID(OID) ); -- ... only to drop it immediately... ALTER TABLE dbo.tblPartitionedCCI DROP CONSTRAINT PK_CCI_Part; GO -- ... so we can replace it with the CCI: CREATE CLUSTERED COLUMNSTORE INDEX CCI_Part ON dbo.tblPartitionedCCI ON PS_OID(OID); GO -- now rebuild with the compression we want: ALTER TABLE dbo.tblPartitionedCCI REBUILD PARTITION = ALL WITH ( DATA_COMPRESSION = COLUMNSTORE_ARCHIVE ON PARTITIONS (1 TO 7), DATA_COMPRESSION = COLUMNSTORE ON PARTITIONS (8) );
Trong Phần 3, tôi sẽ định cấu hình thêm cho BatchQueue lập bảng, xây dựng một thủ tục cho các quy trình để đẩy dữ liệu sang cấu trúc mới và phân tích kết quả.
[Phần 1 | Phần 2 | Phần 3]