Đây là phần thứ mười ba và cuối cùng trong loạt bài về các biểu thức bảng. Tháng này, tôi tiếp tục cuộc thảo luận mà tôi đã bắt đầu từ tháng trước về các hàm giá trị bảng nội tuyến (iTVFs).
Tháng trước, tôi đã giải thích rằng khi SQL Server nội tuyến các iTVF được truy vấn với các hằng số làm đầu vào, nó sẽ áp dụng tối ưu hóa nhúng tham số theo mặc định. Nhúng tham số có nghĩa là SQL Server thay thế các tham chiếu tham số trong truy vấn bằng các giá trị hằng số theo nghĩa đen từ việc thực thi hiện tại và sau đó mã có hằng số được tối ưu hóa. Quá trình này cho phép đơn giản hóa có thể dẫn đến các kế hoạch truy vấn tối ưu hơn. Trong tháng này, tôi sẽ trình bày chi tiết về chủ đề này, bao gồm các trường hợp cụ thể để đơn giản hóa như gấp liên tục và lọc động và sắp xếp. Nếu bạn cần cập nhật về tối ưu hóa nhúng thông số, hãy xem qua bài viết của tháng trước cũng như bài viết xuất sắc của Paul White về Hít thông số, Nhúng và Tùy chọn RECOMPILE.
Trong các ví dụ của mình, tôi sẽ sử dụng cơ sở dữ liệu mẫu có tên là TSQLV5. Bạn có thể tìm thấy tập lệnh tạo và điền nó tại đây và sơ đồ ER của nó tại đây.
Gấp liên tục
Trong giai đoạn đầu của quá trình xử lý truy vấn, SQL Server đánh giá một số biểu thức liên quan đến hằng số, gấp chúng thành hằng số kết quả. Ví dụ:biểu thức 40 + 2 có thể được gấp lại thành hằng số 42. Bạn có thể tìm thấy các quy tắc cho các biểu thức có thể gấp lại và không thể gấp lại ở đây trong “Đánh giá biểu thức và gấp không đổi.”
Điều thú vị liên quan đến iTVF là nhờ tối ưu hóa nhúng tham số, các truy vấn liên quan đến iTVF trong đó bạn chuyển các hằng số làm đầu vào, trong những trường hợp phù hợp, được hưởng lợi từ việc gấp liên tục. Biết các quy tắc cho các biểu thức có thể gập lại và không thể gập lại có thể ảnh hưởng đến cách bạn triển khai iTVF của mình. Trong một số trường hợp, bằng cách áp dụng những thay đổi rất nhỏ cho các biểu thức của mình, bạn có thể kích hoạt các kế hoạch tối ưu hơn với việc sử dụng lập chỉ mục tốt hơn.
Ví dụ:hãy xem xét việc triển khai iTVF được gọi là Sales.MyOrders sau:
USE TSQLV5;
GO
CREATE OR ALTER FUNCTION Sales.MyOrders
( @add AS INT, @subtract AS INT )
RETURNS TABLE
AS
RETURN
SELECT orderid + @add - @subtract AS myorderid,
orderdate, custid, empid
FROM Sales.Orders;
GO Đưa ra truy vấn sau liên quan đến iTVF (tôi sẽ gọi đây là Truy vấn 1):
SELECT myorderid, orderdate, custid, empid FROM Sales.MyOrders(1, 10248) ORDER BY myorderid;
Kế hoạch cho Truy vấn 1 được thể hiện trong Hình 1.
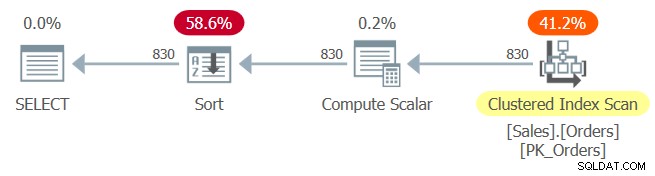 Hình 1:Kế hoạch cho Truy vấn 1
Hình 1:Kế hoạch cho Truy vấn 1
Chỉ mục được phân cụm PK_Orders được xác định với orderid làm khóa. Nếu việc gấp liên tục diễn ra ở đây sau khi nhúng tham số, biểu thức sắp xếp orderid + 1 - 10248 sẽ được gấp lại thành orderid - 10247. Biểu thức này sẽ được coi là một biểu thức bảo toàn thứ tự đối với orderid, và như vậy sẽ cho phép trình tối ưu hóa để dựa vào thứ tự chỉ mục. Than ôi, đó không phải là trường hợp, như được hiển nhiên bởi toán tử Sắp xếp rõ ràng trong kế hoạch. Vậy chuyện gì đã xảy ra?
Các quy tắc gấp liên tục rất phức tạp. Biểu thức cột1 + hằng số1 - hằng số2 được đánh giá từ trái sang phải cho các mục đích gấp không đổi. Phần đầu tiên, cột1 + hằng số1 không được gấp lại. Hãy gọi đây là biểu thức1. Phần tiếp theo được đánh giá được coi là biểu thức1 - hằng số2, phần này cũng không được gấp lại. Nếu không gấp, một biểu thức ở dạng cột1 + hằng số1 - hằng số2 không được coi là bảo toàn thứ tự đối với cột1 và do đó không thể dựa vào thứ tự chỉ mục ngay cả khi bạn có chỉ mục hỗ trợ trên cột1. Tương tự, biểu thức hằng1 + cột1 - hằng2 không phải là hằng số có thể gấp lại được. Tuy nhiên, biểu thức hằng1 - hằng2 + cột1 có thể gấp lại được. Cụ thể hơn, phần đầu tiên hằng số1 - hằng số2 được gấp lại thành một hằng số duy nhất (hãy gọi nó là hằng số3), dẫn đến biểu thức hằng số3 + column1. Biểu thức này được coi là một biểu thức bảo toàn thứ tự đối với cột1. Vì vậy, miễn là bạn đảm bảo viết biểu thức của mình bằng biểu mẫu cuối cùng, bạn có thể kích hoạt trình tối ưu hóa dựa vào thứ tự chỉ mục.
Hãy xem xét các truy vấn sau (tôi sẽ gọi chúng là Truy vấn 2, Truy vấn 3 và Truy vấn 4) và trước khi xem xét các kế hoạch truy vấn, hãy xem liệu bạn có thể biết cái nào sẽ liên quan đến sắp xếp rõ ràng trong kế hoạch và cái nào sẽ không:
-- Query 2 SELECT orderid + 1 - 10248 AS myorderid, orderdate, custid, empid FROM Sales.Orders ORDER BY myorderid; -- Query 3 SELECT 1 + orderid - 10248 AS myorderid, orderdate, custid, empid FROM Sales.Orders ORDER BY myorderid; -- Query 4 SELECT 1 - 10248 + orderid AS myorderid, orderdate, custid, empid FROM Sales.Orders ORDER BY myorderid;
Bây giờ hãy kiểm tra các kế hoạch cho các truy vấn này như trong Hình 2.
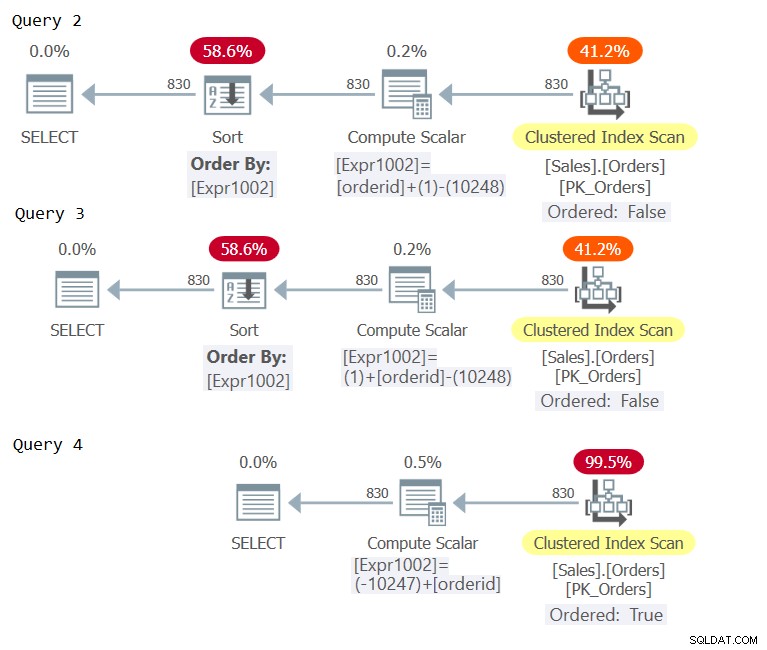 Hình 2:Kế hoạch cho Truy vấn 2, Truy vấn 3 và Truy vấn 4
Hình 2:Kế hoạch cho Truy vấn 2, Truy vấn 3 và Truy vấn 4
Kiểm tra các toán tử tính toán vô hướng trong ba kế hoạch. Chỉ kế hoạch cho Truy vấn 4 phát sinh tình trạng gấp liên tục, dẫn đến biểu thức sắp xếp được coi là duy trì thứ tự đối với hệ thống xếp hạng, tránh sắp xếp rõ ràng.
Hiểu được khía cạnh này của việc gấp liên tục, bạn có thể dễ dàng sửa iTVF bằng cách thay đổi biểu thức orderid + @add - @subtract thành @add - @subtract + orderid, như sau:
CREATE OR ALTER FUNCTION Sales.MyOrders
( @add AS INT, @subtract AS INT )
RETURNS TABLE
AS
RETURN
SELECT @add - @subtract + orderid AS myorderid,
orderdate, custid, empid
FROM Sales.Orders;
GO Truy vấn lại hàm (tôi sẽ gọi đây là Truy vấn 5):
SELECT myorderid, orderdate, custid, empid FROM Sales.MyOrders(1, 10248) ORDER BY myorderid;
Kế hoạch cho truy vấn này được thể hiện trong Hình 3.
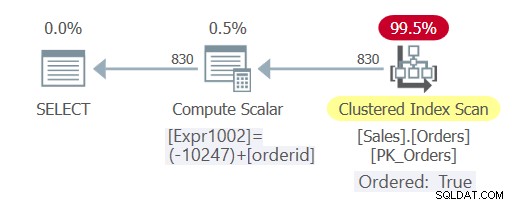 Hình 3:Kế hoạch cho Truy vấn 5
Hình 3:Kế hoạch cho Truy vấn 5
Như bạn có thể thấy, lần này truy vấn bị gấp liên tục và trình tối ưu hóa có thể dựa vào thứ tự chỉ mục, tránh sắp xếp rõ ràng.
Tôi đã sử dụng một ví dụ đơn giản để chứng minh kỹ thuật tối ưu hóa này và như vậy, nó có vẻ hơi phức tạp. Bạn có thể tìm thấy một ứng dụng thực tế của kỹ thuật này trong bài viết Các giải pháp thử thách trình tạo chuỗi số - Phần 1.
Lọc / Sắp xếp động
Tháng trước, tôi đã đề cập đến sự khác biệt giữa cách SQL Server tối ưu hóa một truy vấn trong iTVF so với cùng một truy vấn trong một thủ tục được lưu trữ. SQL Server thường sẽ áp dụng tối ưu hóa nhúng tham số theo mặc định cho truy vấn liên quan đến iTVF với các hằng số làm đầu vào, nhưng tối ưu hóa dạng tham số hóa của truy vấn trong một thủ tục được lưu trữ. Tuy nhiên, nếu bạn thêm TÙY CHỌN (RECOMPILE) vào truy vấn trong thủ tục được lưu trữ, SQL Server thường cũng sẽ áp dụng tối ưu hóa nhúng tham số trong trường hợp này. Các lợi ích trong trường hợp iTVF bao gồm thực tế là bạn có thể đưa nó vào một truy vấn và miễn là bạn chuyển các đầu vào liên tục lặp lại, thì sẽ có khả năng sử dụng lại kế hoạch đã lưu trong bộ nhớ cache trước đó. Với một thủ tục được lưu trữ, bạn không thể đưa nó vào một truy vấn và nếu bạn thêm TÙY CHỌN (RECOMPILE) để có được tối ưu hóa nhúng tham số, thì không có khả năng tái sử dụng kế hoạch. Thủ tục được lưu trữ cho phép linh hoạt hơn nhiều về các phần tử mã mà bạn có thể sử dụng.
Hãy xem tất cả điều này diễn ra như thế nào trong tác vụ sắp xếp và nhúng thông số cổ điển. Sau đây là một quy trình được lưu trữ được đơn giản hóa áp dụng lọc và sắp xếp động tương tự như quy trình mà Paul đã sử dụng trong bài viết của mình:
CREATE OR ALTER PROCEDURE HR.GetEmpsP @lastnamepattern AS NVARCHAR(50), @sort AS TINYINT AS SET NOCOUNT ON; SELECT empid, firstname, lastname FROM HR.Employees WHERE lastname LIKE @lastnamepattern OR @lastnamepattern IS NULL ORDER BY CASE WHEN @sort = 1 THEN empid END, CASE WHEN @sort = 2 THEN firstname END, CASE WHEN @sort = 3 THEN lastname END; GO
Lưu ý rằng việc triển khai hiện tại của thủ tục được lưu trữ không bao gồm TÙY CHỌN (RECOMPILE) trong truy vấn.
Xem xét việc thực thi quy trình được lưu trữ sau:
EXEC HR.GetEmpsP @lastnamepattern = N'D%', @sort = 3;
Kế hoạch cho việc thực hiện này được thể hiện trong Hình 4.
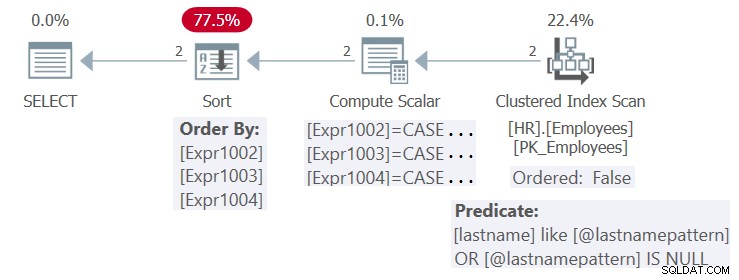 Hình 4:Kế hoạch cho Quy trình HR.GetEmpsP
Hình 4:Kế hoạch cho Quy trình HR.GetEmpsP
Có một chỉ mục được xác định trên cột họ. Về mặt lý thuyết, với các đầu vào hiện tại, chỉ mục có thể có lợi cho cả nhu cầu lọc (với một tìm kiếm) và sắp xếp (với một tìm kiếm có thứ tự:quét phạm vi thực) của truy vấn. Tuy nhiên, vì theo mặc định, SQL Server tối ưu hóa hình thức được tham số hóa của truy vấn và không áp dụng nhúng tham số, nên nó không áp dụng các đơn giản hóa cần thiết để có thể hưởng lợi từ chỉ mục cho cả mục đích lọc và sắp xếp. Vì vậy, kế hoạch có thể tái sử dụng, nhưng không phải là tối ưu.
Để xem mọi thứ thay đổi như thế nào với tối ưu hóa nhúng tham số, hãy thay đổi truy vấn thủ tục được lưu trữ bằng cách thêm TÙY CHỌN (RECOMPILE), như sau:
CREATE OR ALTER PROCEDURE HR.GetEmpsP @lastnamepattern AS NVARCHAR(50), @sort AS TINYINT AS SET NOCOUNT ON; SELECT empid, firstname, lastname FROM HR.Employees WHERE lastname LIKE @lastnamepattern OR @lastnamepattern IS NULL ORDER BY CASE WHEN @sort = 1 THEN empid END, CASE WHEN @sort = 2 THEN firstname END, CASE WHEN @sort = 3 THEN lastname END OPTION(RECOMPILE); GO
Thực thi lại quy trình đã lưu trữ với cùng các đầu vào mà bạn đã sử dụng trước đây:
EXEC HR.GetEmpsP @lastnamepattern = N'D%', @sort = 3;
Kế hoạch cho việc thực hiện này được thể hiện trong Hình 5.
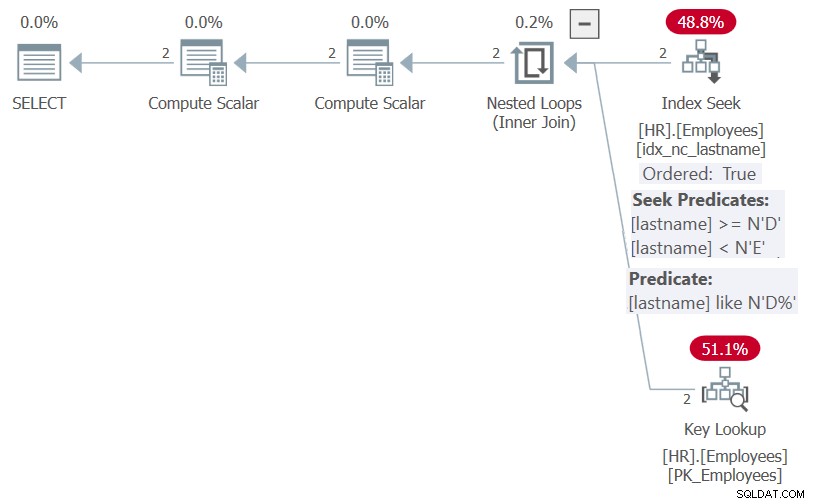 Hình 5:Kế hoạch cho Quy trình HR.GetEmpsP With OPTION (RECOMPILE)
Hình 5:Kế hoạch cho Quy trình HR.GetEmpsP With OPTION (RECOMPILE)
Như bạn có thể thấy, nhờ tối ưu hóa nhúng tham số, SQL Server đã có thể đơn giản hóa vị từ bộ lọc thành vị từ sargable họ LIKE N'D% 'và danh sách sắp xếp thành NULL, NULL, lastname. Cả hai yếu tố có thể được hưởng lợi từ chỉ mục trên họ và do đó, kế hoạch cho thấy một tìm kiếm trong chỉ mục và không có sự phân loại rõ ràng.
Về mặt lý thuyết, bạn mong đợi có thể có được sự đơn giản hóa tương tự nếu bạn triển khai truy vấn trong iTVF và do đó lợi ích tối ưu hóa tương tự, nhưng với khả năng sử dụng lại các kế hoạch đã lưu trong bộ nhớ cache khi các giá trị đầu vào giống nhau được sử dụng lại. Vì vậy, hãy thử…
Đây là nỗ lực triển khai cùng một truy vấn trong iTVF (chưa chạy mã này):
CREATE OR ALTER FUNCTION HR.GetEmpsF
(
@lastnamepattern AS NVARCHAR(50),
@sort AS TINYINT
)
RETURNS TABLE
AS
RETURN
SELECT empid, firstname, lastname
FROM HR.Employees
WHERE lastname LIKE @lastnamepattern OR @lastnamepattern IS NULL
ORDER BY
CASE WHEN @sort = 1 THEN empid END,
CASE WHEN @sort = 2 THEN firstname END,
CASE WHEN @sort = 3 THEN lastname END;
GO Trước khi cố gắng thực thi mã này, bạn có thể thấy sự cố với việc triển khai này không? Hãy nhớ rằng ngay từ đầu trong loạt bài này, tôi đã giải thích một biểu thức bảng là một bảng. Nội dung bảng là một tập hợp (hoặc nhiều tập hợp) các hàng và như vậy không có thứ tự. Do đó, thông thường, một truy vấn được sử dụng như một biểu thức bảng không thể có mệnh đề ORDER BY. Thật vậy, nếu bạn thử chạy mã này, bạn sẽ gặp lỗi sau:
Msg 1033, Mức 15, Trạng thái 1, Thủ tục GetEmps, Dòng 16 [Dòng Bắt đầu Hàng loạt 128]Mệnh đề ORDER BY không hợp lệ trong các dạng xem, hàm nội tuyến, bảng dẫn xuất, truy vấn con và biểu thức bảng thông thường, trừ khi TOP, OFFSET hoặc FOR XML cũng được chỉ định.
Chắc chắn, giống như lỗi đã nói, SQL Server sẽ tạo ngoại lệ nếu bạn sử dụng phần tử lọc như TOP hoặc OFFSET-FETCH, phần tử này dựa vào mệnh đề ORDER BY để xác định khía cạnh thứ tự của bộ lọc. Nhưng ngay cả khi bạn bao gồm mệnh đề ORDER BY trong truy vấn bên trong nhờ ngoại lệ này, bạn vẫn không nhận được đảm bảo cho thứ tự của kết quả trong truy vấn bên ngoài so với biểu thức bảng, trừ khi nó có mệnh đề ORDER BY riêng. .
Nếu bạn vẫn muốn triển khai truy vấn trong iTVF, bạn có thể yêu cầu truy vấn bên trong xử lý phần lọc động, nhưng không phải thứ tự động, như sau:
CREATE OR ALTER FUNCTION HR.GetEmpsF ( @lastnamepattern AS NVARCHAR(50) ) RETURNS TABLE AS RETURN SELECT empid, firstname, lastname FROM HR.Employees WHERE lastname LIKE @lastnamepattern OR @lastnamepattern IS NULL; GO
Tất nhiên, bạn có thể có truy vấn bên ngoài xử lý bất kỳ nhu cầu đặt hàng cụ thể nào, như trong đoạn mã sau (tôi sẽ gọi đây là Truy vấn 6):
SELECT empid, firstname, lastname FROM HR.GetEmpsF(N'D%') ORDER BY lastname;
Kế hoạch cho truy vấn này được thể hiện trong Hình 6.
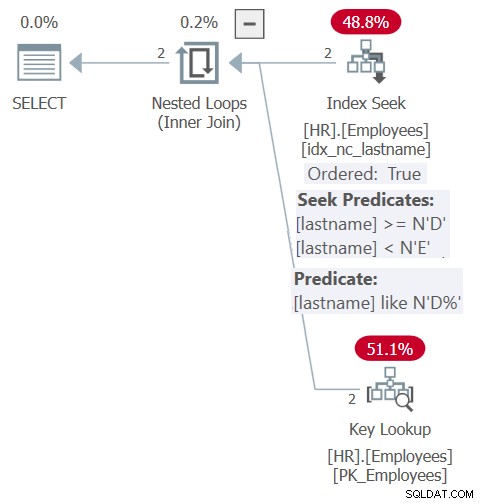 Hình 6:Kế hoạch cho Truy vấn 6
Hình 6:Kế hoạch cho Truy vấn 6
Nhờ vào nội tuyến và nhúng tham số, kế hoạch tương tự như kế hoạch được hiển thị trước đó cho truy vấn thủ tục được lưu trữ trong Hình 5. Kế hoạch dựa vào chỉ mục một cách hiệu quả cho cả mục đích lọc và sắp xếp. Tuy nhiên, bạn không nhận được sự linh hoạt của đầu vào đặt hàng động như bạn đã làm với quy trình được lưu trữ. Bạn phải rõ ràng với thứ tự trong mệnh đề ORDER BY trong truy vấn đối với hàm.
Ví dụ sau có một truy vấn đối với hàm không có yêu cầu lọc và không có thứ tự (tôi sẽ gọi đây là Truy vấn 7):
SELECT empid, firstname, lastname FROM HR.GetEmpsF(NULL);
Kế hoạch cho truy vấn này được thể hiện trong Hình 7.
 Hình 7:Kế hoạch cho Truy vấn 7
Hình 7:Kế hoạch cho Truy vấn 7
Sau khi nhúng nội tuyến và tham số, truy vấn được đơn giản hóa để không có vị từ bộ lọc và không có thứ tự, đồng thời được tối ưu hóa bằng cách quét toàn bộ không có thứ tự của chỉ mục nhóm.
Cuối cùng, truy vấn hàm với N'D% 'làm mẫu lọc họ đầu vào và sắp xếp kết quả theo cột tên (tôi sẽ gọi đây là Truy vấn 8):
SELECT empid, firstname, lastname FROM HR.GetEmpsF(N'D%') ORDER BY firstname;
Kế hoạch cho truy vấn này được thể hiện trong Hình 8.
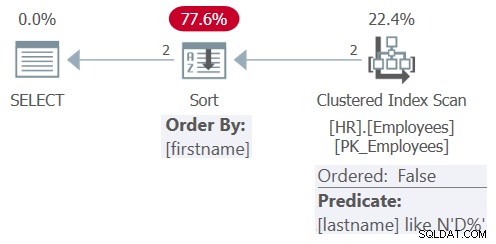 Hình 8:Kế hoạch cho Truy vấn 8
Hình 8:Kế hoạch cho Truy vấn 8
Sau khi đơn giản hóa, truy vấn chỉ liên quan đến họ của vị từ lọc LIKE N'D% 'và tên phần tử sắp xếp thứ tự. Lần này trình tối ưu hóa chọn áp dụng quét không theo thứ tự chỉ mục được phân nhóm, với họ của vị từ còn lại LIKE N'D% ', theo sau là sắp xếp rõ ràng. Nó đã chọn không áp dụng tìm kiếm trong chỉ mục trên họ bởi vì chỉ mục không phải là chỉ mục bao trùm, bảng quá nhỏ và việc sắp xếp chỉ mục không có lợi cho nhu cầu sắp xếp truy vấn hiện tại. Ngoài ra, không có chỉ mục nào được xác định trên cột tên, vì vậy, vẫn phải áp dụng một sắp xếp rõ ràng.
Kết luận
Việc tối ưu hóa nhúng tham số mặc định của iTVF cũng có thể dẫn đến việc gấp liên tục, cho phép các kế hoạch tối ưu hơn. Tuy nhiên, bạn cần phải lưu ý đến các quy tắc gấp không đổi để xác định cách hình thành biểu thức của bạn tốt nhất.
Việc triển khai logic trong iTVF có những ưu điểm và nhược điểm so với việc triển khai logic trong một thủ tục được lưu trữ. Nếu bạn không quan tâm đến việc tối ưu hóa nhúng tham số, thì việc tối ưu hóa truy vấn được tham số hóa mặc định của các thủ tục được lưu trữ có thể dẫn đến hành vi sử dụng và lưu vào bộ nhớ đệm của kế hoạch tối ưu hơn. Trong trường hợp bạn quan tâm đến việc tối ưu hóa nhúng tham số, bạn thường lấy nó theo mặc định với iTVF. Để có được sự tối ưu hóa này với các thủ tục được lưu trữ, bạn cần thêm tùy chọn truy vấn RECOMPILE, nhưng sau đó bạn sẽ không nhận được kế hoạch sử dụng lại. Ít nhất với iTVF, bạn có thể sử dụng lại kế hoạch với điều kiện các giá trị tham số giống nhau được lặp lại. Sau đó, một lần nữa, bạn có ít tính linh hoạt hơn với các phần tử truy vấn mà bạn có thể sử dụng trong iTVF; ví dụ:bạn không được phép có điều khoản ORDER BY trong bản trình bày.
Quay lại toàn bộ loạt bài về biểu thức bảng, tôi thấy chủ đề này cực kỳ quan trọng đối với những người thực hành cơ sở dữ liệu. Chuỗi hoàn chỉnh hơn bao gồm các phân nhánh trên trình tạo chuỗi số, được triển khai dưới dạng iTVF. Tổng cộng bộ truyện bao gồm 19 phần sau:
- Các nguyên tắc cơ bản về biểu thức bảng, Phần 1
- Các nguyên tắc cơ bản về biểu thức bảng, Phần 2 - Các bảng có nguồn gốc, các cân nhắc logic
- Các nguyên tắc cơ bản về biểu thức bảng, Phần 3 - Các bảng có nguồn gốc, cân nhắc tối ưu hóa
- Các nguyên tắc cơ bản về biểu thức bảng, Phần 4 - Các bảng có nguồn gốc, cân nhắc tối ưu hóa, tiếp theo
- Các nguyên tắc cơ bản về biểu thức bảng, Phần 5 - CTE, các cân nhắc logic
- Các nguyên tắc cơ bản về biểu thức bảng, Phần 6 - CTE đệ quy
- Các nguyên tắc cơ bản về biểu thức bảng, Phần 7 - CTE, các cân nhắc tối ưu hóa
- Các nguyên tắc cơ bản về biểu thức bảng, Phần 8 - CTE, tiếp tục xem xét tối ưu hóa
- Các nguyên tắc cơ bản về biểu thức bảng, Phần 9 - Chế độ xem, được so sánh với các bảng dẫn xuất và CTE
- Các nguyên tắc cơ bản về biểu thức bảng, Phần 10 - Các thay đổi về chế độ xem, SELECT * và DDL
- Các nguyên tắc cơ bản về biểu thức bảng, Phần 11 - Chế độ xem, Cân nhắc sửa đổi
- Các nguyên tắc cơ bản về biểu thức bảng, Phần 12 - Hàm nội tuyến được định giá trong bảng
- Các nguyên tắc cơ bản về biểu thức bảng, Phần 13 - Các hàm được định giá trong bảng nội tuyến, tiếp theo
- Thử thách đang diễn ra! Kêu gọi cộng đồng tạo ra trình tạo chuỗi số nhanh nhất
- Các giải pháp thách thức trình tạo chuỗi số - Phần 1
- Các giải pháp thách thức trình tạo chuỗi số - Phần 2
- Các giải pháp thách thức trình tạo chuỗi số - Phần 3
- Các giải pháp thách thức trình tạo chuỗi số - Phần 4
- Các giải pháp thách thức trình tạo chuỗi số - Phần 5