Đây là phần thứ hai trong loạt bài về các giải pháp cho thử thách máy phát chuỗi số. Tháng trước, tôi đã đề cập đến các giải pháp tạo các hàng một cách nhanh chóng bằng cách sử dụng hàm tạo giá trị bảng với các hàng dựa trên hằng số. Không có hoạt động I / O nào liên quan đến các giải pháp đó. Tháng này, tôi tập trung vào các giải pháp truy vấn bảng cơ sở vật lý mà bạn điền trước các hàng. Vì lý do này, ngoài việc báo cáo hồ sơ thời gian của các giải pháp như tôi đã làm vào tháng trước, tôi cũng sẽ báo cáo hồ sơ I / O của các giải pháp mới. Một lần nữa xin cảm ơn Alan Burstein, Joe Obbish, Adam Machanic, Christopher Ford, Jeff Moden, Charlie, NoamGr, Kamil Kosno, Dave Mason, John Nelson # 2 và Ed Wagner đã chia sẻ ý kiến và nhận xét của bạn.
Giải pháp nhanh nhất cho đến nay
Đầu tiên, xin nhắc lại nhanh chóng, hãy cùng xem lại giải pháp nhanh nhất từ bài viết tháng trước, được triển khai dưới dạng TVF nội tuyến có tên là dbo.GetNumsAlanCharlieItzikBatch.
Tôi sẽ thực hiện thử nghiệm của mình trong tempdb, bật thống kê IO và TIME:
SET NOCOUNT ON; USE tempdb; SET STATISTICS IO, TIME ON;
Giải pháp nhanh nhất từ tháng trước là áp dụng phép nối với một bảng giả có chỉ mục cột lưu trữ để xử lý hàng loạt. Đây là mã để tạo bảng giả:
DROP TABLE IF EXISTS dbo.BatchMe; GO CREATE TABLE dbo.BatchMe(col1 INT NOT NULL, INDEX idx_cs CLUSTERED COLUMNSTORE);
Và đây là mã với định nghĩa của hàm dbo.GetNumsAlanCharlieItzikBatch:
CREATE OR ALTER FUNCTION dbo.GetNumsAlanCharlieItzikBatch(@low AS BIGINT = 1, @high AS BIGINT)
RETURNS TABLE
AS
RETURN
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT TOP(@high - @low + 1)
rownum AS rn,
@high + 1 - rownum AS op,
@low - 1 + rownum AS n
FROM Nums LEFT OUTER JOIN dbo.BatchMe ON 1 = 0
ORDER BY rownum;
GO Tháng trước, tôi đã sử dụng mã sau để kiểm tra hiệu suất của hàm với 100 triệu hàng, sau khi bật kết quả Loại bỏ sau khi thực thi trong SSMS để ngăn trả lại các hàng đầu ra:
SELECT n FROM dbo.GetNumsAlanCharlieItzikBatch(1, 100000000) OPTION(MAXDOP 1);
Đây là thống kê thời gian mà tôi nhận được cho việc thực hiện này:
Thời gian CPU =16031 ms, thời gian đã trôi qua =17172 ms.Joe Obbish đã lưu ý một cách chính xác rằng thử nghiệm này có thể thiếu sự phản ánh của nó đối với một số tình huống trong cuộc sống thực theo nghĩa là một phần lớn thời gian chạy là do chờ đợi I / O của mạng không đồng bộ (kiểu chờ ASYNC_NETWORK_IO). Bạn có thể quan sát thời gian chờ cao nhất bằng cách xem trang thuộc tính của nút gốc của kế hoạch truy vấn thực tế hoặc chạy phiên sự kiện mở rộng với thông tin chờ. Việc bạn bật Loại bỏ kết quả sau khi thực thi trong SSMS không ngăn SQL Server gửi các hàng kết quả tới SSMS; nó chỉ ngăn SSMS in chúng. Câu hỏi đặt ra là, khả năng bạn sẽ trả về các tập kết quả lớn cho máy khách trong các tình huống thực tế ngay cả khi bạn sử dụng hàm để tạo ra một chuỗi số lớn là bao nhiêu? Có lẽ bạn thường ghi kết quả truy vấn vào bảng hoặc sử dụng kết quả của hàm như một phần của truy vấn mà cuối cùng tạo ra một tập kết quả nhỏ. Bạn cần phải tìm ra điều này. Bạn có thể viết tập hợp kết quả vào một bảng tạm thời bằng cách sử dụng câu lệnh SELECT INTO hoặc bạn có thể sử dụng mẹo của Alan Burstein với câu lệnh SELECT gán, câu lệnh này sẽ gán giá trị cột kết quả cho một biến.
Dưới đây là cách bạn sẽ thay đổi thử nghiệm cuối cùng để sử dụng tùy chọn gán có thể thay đổi:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsAlanCharlieItzikBatch(1, 100000000) OPTION(MAXDOP 1);
Đây là thống kê thời gian mà tôi nhận được cho bài kiểm tra này:
Thời gian CPU =8641 ms, thời gian đã trôi qua =8645 ms.Lần này, thông tin chờ không có I / O mạng không đồng bộ chờ và bạn có thể thấy thời gian chạy giảm đáng kể.
Kiểm tra lại chức năng, lần này thêm thứ tự:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsAlanCharlieItzikBatch(1, 100000000) ORDER BY n OPTION(MAXDOP 1);
Tôi nhận được số liệu thống kê về hiệu suất sau cho quá trình thực thi này:
Thời gian CPU =9360 ms, thời gian trôi qua =9551 ms.Nhớ lại rằng không cần toán tử Sắp xếp trong kế hoạch cho truy vấn này vì cột n dựa trên một biểu thức bảo toàn thứ tự đối với cột rownum. Đó là nhờ mẹo gấp liên tục của Charli mà tôi đã trình bày vào tháng trước. Các kế hoạch cho cả hai truy vấn — một truy vấn không đặt hàng và một truy vấn có đặt hàng giống nhau, do đó, hiệu suất có xu hướng giống nhau.
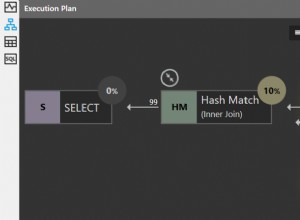
Hình 1 tóm tắt các con số hiệu suất mà tôi nhận được cho các giải pháp của tháng trước, chỉ lần này bằng cách sử dụng phép gán có thể thay đổi trong các bài kiểm tra thay vì loại bỏ kết quả sau khi thực hiện.
 Hình 1:Tóm tắt hiệu suất cho đến nay với phép gán biến
Hình 1:Tóm tắt hiệu suất cho đến nay với phép gán biến
Tôi sẽ sử dụng kỹ thuật gán biến để kiểm tra phần còn lại của các giải pháp mà tôi sẽ trình bày trong bài viết này. Đảm bảo rằng bạn điều chỉnh các bài kiểm tra của mình để phản ánh tốt nhất tình huống thực tế của bạn, sử dụng phép gán có thể thay đổi, CHỌN VÀO, Loại bỏ kết quả sau khi thực hiện hoặc bất kỳ kỹ thuật nào khác.
Mẹo để buộc các kế hoạch nối tiếp không có MAXDOP 1
Trước khi trình bày các giải pháp mới, tôi chỉ muốn trình bày một mẹo nhỏ. Nhớ lại rằng một số giải pháp hoạt động tốt nhất khi sử dụng kế hoạch nối tiếp. Cách rõ ràng để buộc điều này là với gợi ý truy vấn MAXDOP 1. Và đó là cách phù hợp để thực hiện nếu đôi khi bạn muốn bật chế độ song song và đôi khi không. Tuy nhiên, điều gì sẽ xảy ra nếu bạn luôn muốn bắt buộc một kế hoạch nối tiếp khi sử dụng hàm, mặc dù một trường hợp ít khả năng xảy ra hơn?
Có một mẹo để đạt được điều này. Sử dụng UDF vô hướng không tuyến tính trong truy vấn là một chất ức chế song song. Một trong những chất ức chế nội tuyến UDF vô hướng đang gọi một hàm nội tại phụ thuộc vào thời gian, chẳng hạn như SYSDATETIME. Vì vậy, đây là một ví dụ cho UDF vô hướng không thể nội tuyến:
CREATE OR ALTER FUNCTION dbo.MySYSDATETIME() RETURNS DATETIME2 AS BEGIN RETURN SYSDATETIME(); END; GO
Một tùy chọn khác là xác định một UDF chỉ với một số hằng số làm giá trị trả về và sử dụng tùy chọn INLINE =OFF trong tiêu đề của nó. Nhưng tùy chọn này chỉ khả dụng bắt đầu với SQL Server 2019, đã giới thiệu nội tuyến UDF vô hướng. Với chức năng được đề xuất ở trên, bạn có thể tạo nó như với các phiên bản SQL Server cũ hơn.
Tiếp theo, thay đổi định nghĩa của hàm dbo.GetNumsAlanCharlieItzikBatch để có một lệnh gọi giả đến dbo.MySYSDATETIME (xác định một cột dựa trên nó nhưng không tham chiếu đến cột trong truy vấn được trả về), như sau:
CREATE OR ALTER FUNCTION dbo.GetNumsAlanCharlieItzikBatch(@low AS BIGINT = 1, @high AS BIGINT)
RETURNS TABLE
AS
RETURN
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT
ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum,
dbo.MySYSDATETIME() AS dontinline
FROM L3 )
SELECT TOP(@high - @low + 1)
rownum AS rn,
@high + 1 - rownum AS op,
@low - 1 + rownum AS n
FROM Nums LEFT OUTER JOIN dbo.BatchMe ON 1 = 0
ORDER BY rownum;
GO Giờ đây, bạn có thể chạy lại kiểm tra hiệu suất mà không cần chỉ định MAXDOP 1 và vẫn nhận được gói nối tiếp:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsAlanCharlieItzikBatch(1, 100000000) ORDER BY n;
Điều quan trọng cần nhấn mạnh là mặc dù bất kỳ truy vấn nào sử dụng chức năng này bây giờ sẽ nhận được một kế hoạch nối tiếp. Nếu có bất kỳ cơ hội nào mà hàm sẽ được sử dụng trong các truy vấn sẽ được hưởng lợi từ các kế hoạch song song, tốt hơn là không sử dụng thủ thuật này và khi bạn cần một kế hoạch nối tiếp, chỉ cần sử dụng MAXDOP 1.
Giải pháp của Joe Obbish
Giải pháp của Joe khá sáng tạo. Đây là mô tả của riêng anh ấy về giải pháp:
“ Tôi đã chọn tạo chỉ mục cột lưu trữ theo nhóm (CCI) với 134.217.728 hàng số nguyên tuần tự. Hàm tham chiếu đến bảng tối đa 32 lần để lấy tất cả các hàng cần thiết cho tập kết quả. Tôi chọn CCI vì dữ liệu sẽ nén tốt (ít hơn 3 byte mỗi hàng), bạn nhận được chế độ hàng loạt "miễn phí" và kinh nghiệm trước đây cho thấy rằng việc đọc các số tuần tự từ CCI sẽ nhanh hơn so với việc tạo chúng thông qua một số phương pháp khác. ”Như đã đề cập trước đó, Joe cũng lưu ý rằng thử nghiệm hiệu suất ban đầu của tôi đã bị sai lệch đáng kể do các đợi I / O của mạng không đồng bộ được tạo ra bằng cách truyền các hàng tới SSMS. Vì vậy, tất cả các bài kiểm tra mà tôi sẽ thực hiện ở đây sẽ sử dụng ý tưởng của Alan với nhiệm vụ có thể thay đổi. Đảm bảo điều chỉnh các bài kiểm tra của bạn dựa trên những gì phản ánh gần nhất tình hình thực tế của bạn.
Đây là mã Joe đã sử dụng để tạo bảng dbo.GetNumsObbishTable và điền nó với 134,217,728 hàng:
DROP TABLE IF EXISTS dbo.GetNumsObbishTable; CREATE TABLE dbo.GetNumsObbishTable (ID BIGINT NOT NULL, INDEX CCI CLUSTERED COLUMNSTORE); GO SET NOCOUNT ON; DECLARE @c INT = 0; WHILE @c < 128 BEGIN INSERT INTO dbo.GetNumsObbishTable SELECT TOP (1048576) @c * 1048576 - 1 + ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) FROM master..spt_values t1 CROSS JOIN master..spt_values t2 OPTION (MAXDOP 1); SET @c = @c + 1; END; GO
Phải mất 1:04 phút để hoàn thành mã này trên máy của tôi.
Bạn có thể kiểm tra việc sử dụng không gian của bảng này bằng cách chạy mã sau:
EXEC sys.sp_spaceused @objname = N'dbo.GetNumsObbishTable';
Tôi đã sử dụng khoảng 350 MB dung lượng. So với các giải pháp khác mà tôi sẽ trình bày trong bài viết này, giải pháp này sử dụng nhiều không gian hơn đáng kể.
Trong kiến trúc cột cửa hàng của SQL Server, một nhóm hàng được giới hạn ở 2 ^ 20 =1.048.576 hàng. Bạn có thể kiểm tra xem có bao nhiêu nhóm hàng đã được tạo cho bảng này bằng cách sử dụng mã sau:
SELECT COUNT(*) AS numrowgroups
FROM sys.column_store_row_groups
WHERE object_id = OBJECT_ID('dbo.GetNumsObbishTable'); Tôi có 128 nhóm hàng.
Đây là mã với định nghĩa của hàm dbo.GetNumsObbish:
CREATE OR ALTER FUNCTION dbo.GetNumsObbish(@low AS BIGINT, @high AS BIGINT) RETURNS TABLE AS RETURN SELECT @low + ID AS n FROM dbo.GetNumsObbishTable WHERE ID <= @high - @low UNION ALL SELECT @low + ID + CAST(134217728 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(134217728 AS BIGINT) AND ID <= @high - @low - CAST(134217728 AS BIGINT) UNION ALL SELECT @low + ID + CAST(268435456 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(268435456 AS BIGINT) AND ID <= @high - @low - CAST(268435456 AS BIGINT) UNION ALL SELECT @low + ID + CAST(402653184 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(402653184 AS BIGINT) AND ID <= @high - @low - CAST(402653184 AS BIGINT) UNION ALL SELECT @low + ID + CAST(536870912 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(536870912 AS BIGINT) AND ID <= @high - @low - CAST(536870912 AS BIGINT) UNION ALL SELECT @low + ID + CAST(671088640 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(671088640 AS BIGINT) AND ID <= @high - @low - CAST(671088640 AS BIGINT) UNION ALL SELECT @low + ID + CAST(805306368 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(805306368 AS BIGINT) AND ID <= @high - @low - CAST(805306368 AS BIGINT) UNION ALL SELECT @low + ID + CAST(939524096 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(939524096 AS BIGINT) AND ID <= @high - @low - CAST(939524096 AS BIGINT) UNION ALL SELECT @low + ID + CAST(1073741824 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(1073741824 AS BIGINT) AND ID <= @high - @low - CAST(1073741824 AS BIGINT) UNION ALL SELECT @low + ID + CAST(1207959552 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(1207959552 AS BIGINT) AND ID <= @high - @low - CAST(1207959552 AS BIGINT) UNION ALL SELECT @low + ID + CAST(1342177280 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(1342177280 AS BIGINT) AND ID <= @high - @low - CAST(1342177280 AS BIGINT) UNION ALL SELECT @low + ID + CAST(1476395008 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(1476395008 AS BIGINT) AND ID <= @high - @low - CAST(1476395008 AS BIGINT) UNION ALL SELECT @low + ID + CAST(1610612736 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(1610612736 AS BIGINT) AND ID <= @high - @low - CAST(1610612736 AS BIGINT) UNION ALL SELECT @low + ID + CAST(1744830464 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(1744830464 AS BIGINT) AND ID <= @high - @low - CAST(1744830464 AS BIGINT) UNION ALL SELECT @low + ID + CAST(1879048192 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(1879048192 AS BIGINT) AND ID <= @high - @low - CAST(1879048192 AS BIGINT) UNION ALL SELECT @low + ID + CAST(2013265920 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(2013265920 AS BIGINT) AND ID <= @high - @low - CAST(2013265920 AS BIGINT) UNION ALL SELECT @low + ID + CAST(2147483648 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(2147483648 AS BIGINT) AND ID <= @high - @low - CAST(2147483648 AS BIGINT) UNION ALL SELECT @low + ID + CAST(2281701376 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(2281701376 AS BIGINT) AND ID <= @high - @low - CAST(2281701376 AS BIGINT) UNION ALL SELECT @low + ID + CAST(2415919104 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(2415919104 AS BIGINT) AND ID <= @high - @low - CAST(2415919104 AS BIGINT) UNION ALL SELECT @low + ID + CAST(2550136832 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(2550136832 AS BIGINT) AND ID <= @high - @low - CAST(2550136832 AS BIGINT) UNION ALL SELECT @low + ID + CAST(2684354560 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(2684354560 AS BIGINT) AND ID <= @high - @low - CAST(2684354560 AS BIGINT) UNION ALL SELECT @low + ID + CAST(2818572288 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(2818572288 AS BIGINT) AND ID <= @high - @low - CAST(2818572288 AS BIGINT) UNION ALL SELECT @low + ID + CAST(2952790016 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(2952790016 AS BIGINT) AND ID <= @high - @low - CAST(2952790016 AS BIGINT) UNION ALL SELECT @low + ID + CAST(3087007744 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(3087007744 AS BIGINT) AND ID <= @high - @low - CAST(3087007744 AS BIGINT) UNION ALL SELECT @low + ID + CAST(3221225472 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(3221225472 AS BIGINT) AND ID <= @high - @low - CAST(3221225472 AS BIGINT) UNION ALL SELECT @low + ID + CAST(3355443200 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(3355443200 AS BIGINT) AND ID <= @high - @low - CAST(3355443200 AS BIGINT) UNION ALL SELECT @low + ID + CAST(3489660928 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(3489660928 AS BIGINT) AND ID <= @high - @low - CAST(3489660928 AS BIGINT) UNION ALL SELECT @low + ID + CAST(3623878656 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(3623878656 AS BIGINT) AND ID <= @high - @low - CAST(3623878656 AS BIGINT) UNION ALL SELECT @low + ID + CAST(3758096384 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(3758096384 AS BIGINT) AND ID <= @high - @low - CAST(3758096384 AS BIGINT) UNION ALL SELECT @low + ID + CAST(3892314112 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(3892314112 AS BIGINT) AND ID <= @high - @low - CAST(3892314112 AS BIGINT) UNION ALL SELECT @low + ID + CAST(4026531840 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(4026531840 AS BIGINT) AND ID <= @high - @low - CAST(4026531840 AS BIGINT) UNION ALL SELECT @low + ID + CAST(4160749568 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(4160749568 AS BIGINT) AND ID <= @high - @low - CAST(4160749568 AS BIGINT); GO
32 truy vấn riêng lẻ tạo ra các giao thức con 134,217,728 số nguyên rời rạc, khi hợp nhất, tạo ra phạm vi hoàn chỉnh không bị gián đoạn từ 1 đến 4,294,967,296. Điều thực sự thông minh về giải pháp này là bộ lọc WHERE dự đoán các truy vấn riêng lẻ sử dụng. Nhớ lại rằng khi SQL Server xử lý một TVF nội tuyến, trước tiên nó áp dụng nhúng tham số, thay thế các tham số bằng các hằng số đầu vào. Sau đó, SQL Server có thể tối ưu hóa các truy vấn tạo ra các giao thức con không giao nhau với phạm vi đầu vào. Ví dụ:khi bạn yêu cầu phạm vi đầu vào từ 1 đến 100.000.000, chỉ truy vấn đầu tiên có liên quan và tất cả các phần còn lại sẽ được tối ưu hóa. Sau đó, kế hoạch trong trường hợp này sẽ liên quan đến một tham chiếu đến chỉ một phiên bản của bảng. Điều đó khá tuyệt vời!
Hãy kiểm tra hiệu suất của chức năng với phạm vi từ 1 đến 100.000.000:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsObbish(1, 100000000);
Kế hoạch cho truy vấn này được thể hiện trong Hình 2.
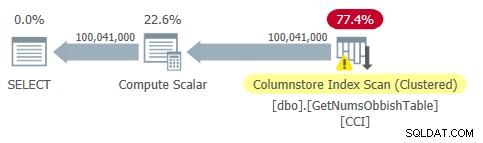 Hình 2:Kế hoạch cho dbo.GetNumsObbish, 100 triệu hàng, không có thứ tự
Hình 2:Kế hoạch cho dbo.GetNumsObbish, 100 triệu hàng, không có thứ tự
Hãy quan sát rằng thực sự chỉ cần một tham chiếu đến CCI của bảng trong kế hoạch này.
Tôi nhận được thống kê thời gian sau cho việc thực hiện này:
Điều đó khá ấn tượng và nhanh hơn nhiều so với bất kỳ thứ gì khác mà tôi đã thử nghiệm.
Đây là số liệu thống kê I / O mà tôi nhận được cho việc thực thi này:
Bảng 'GetNumsObbishTable'. Quét đếm 1, đọc logic 0, đọc vật lý 0, máy chủ trang đọc 0, đọc trước đọc 0, đọc trước máy chủ trang đọc 0, lob logic đọc 32928 , máy chủ trang lob đọc 0, máy chủ trang lob đọc 0, máy chủ trang lob đọc trước 0, máy chủ trang lob đọc trước đọc 0.Bảng 'GetNumsObbishTable'. Phân đoạn đọc 96 , phân đoạn bị bỏ qua 32.
Cấu hình I / O của giải pháp này là một trong những nhược điểm của nó so với các giải pháp khác, phải chịu hơn 30 nghìn lượt đọc logic lob cho việc thực thi này.
Để thấy rằng khi bạn vượt qua nhiều sắp xếp con 134,217,728 số nguyên, kế hoạch sẽ liên quan đến nhiều tham chiếu đến bảng, hãy truy vấn hàm với phạm vi từ 1 đến 400.000.000, ví dụ:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsObbish(1, 400000000);
Kế hoạch cho việc thực hiện này được thể hiện trong Hình 3.
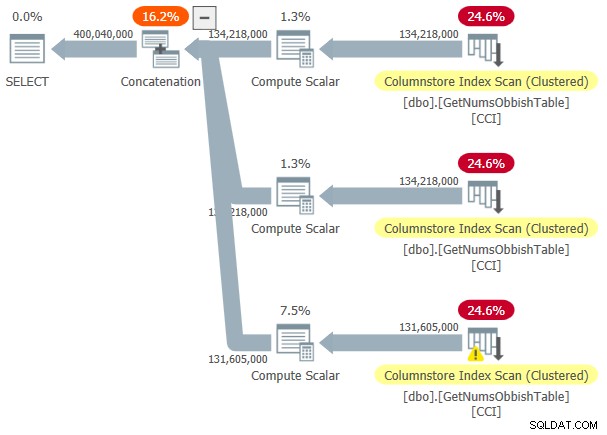 Hình 3:Kế hoạch cho dbo.GetNumsObbish, 400 triệu hàng, không có thứ tự
Hình 3:Kế hoạch cho dbo.GetNumsObbish, 400 triệu hàng, không có thứ tự
Phạm vi được yêu cầu vượt qua ba giao thức con 134.217.728 số nguyên, do đó, kế hoạch hiển thị ba tham chiếu đến CCI của bảng.
Đây là thống kê thời gian mà tôi nhận được cho việc thực hiện này:
Thời gian CPU =20610 ms, thời gian đã trôi qua =20628 ms.Và đây là số liệu thống kê I / O của nó:
Bảng 'GetNumsObbishTable'. Quét đếm 3, đọc logic 0, đọc vật lý 0, máy chủ trang đọc 0, đọc trước đọc 0, đọc trước máy chủ trang đọc 0, lob logic đọc 131026 , máy chủ trang lob đọc 0, máy chủ trang lob đọc 0, máy chủ trang lob đọc trước 0, máy chủ trang lob đọc trước đọc 0.Bảng 'GetNumsObbishTable'. Phân đoạn đọc 382 , phân đoạn bị bỏ qua 2.
Lần này việc thực thi truy vấn dẫn đến hơn 130 nghìn lần đọc logic lob.
Nếu bạn có thể tính toán chi phí I / O và không cần xử lý chuỗi số theo thứ tự, thì đây là một giải pháp tuyệt vời. Tuy nhiên, nếu bạn cần xử lý chuỗi theo thứ tự, giải pháp này sẽ dẫn đến toán tử Sắp xếp trong kế hoạch. Đây là bài kiểm tra yêu cầu kết quả được sắp xếp theo thứ tự:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsObbish(1, 100000000) ORDER BY n;
Kế hoạch cho việc thực hiện này được thể hiện trong Hình 4.
 Hình 4:Kế hoạch cho dbo.GetNumsObbish, 100 triệu hàng, theo thứ tự
Hình 4:Kế hoạch cho dbo.GetNumsObbish, 100 triệu hàng, theo thứ tự
Đây là thống kê thời gian mà tôi nhận được cho việc thực hiện này:
Thời gian CPU =44516 ms, thời gian đã trôi qua =34836 ms.Như bạn có thể thấy, hiệu suất bị giảm đáng kể với thời gian chạy tăng theo thứ tự cường độ do phân loại rõ ràng.
Dưới đây là thống kê I / O mà tôi nhận được cho việc thực hiện này:
Bảng 'GetNumsObbishTable'. Quét đếm 4, đọc logic 0, đọc vật lý 0, máy chủ trang đọc 0, đọc trước đọc 0, đọc trước máy chủ trang đọc 0, lob logic đọc 32928 , máy chủ trang lob đọc 0, máy chủ trang lob đọc 0, máy chủ trang lob đọc trước 0, máy chủ trang lob đọc trước đọc 0.Bảng 'GetNumsObbishTable'. Phân đoạn đọc 96 , phân đoạn bị bỏ qua 32.
Bảng 'Bàn làm việc'. Quét đếm 0, đọc lôgic 0, đọc vật lý 0, máy chủ trang đọc 0, đọc trước đọc 0, máy chủ trang đọc trước đọc 0, lôgic đọc 0, đọc lôgic vật lý 0, máy chủ trang lob đọc 0, đọc lob- lượt đọc trước 0, máy chủ trang lob đọc trước lượt đọc 0.
Quan sát thấy Bảng làm việc xuất hiện trong đầu ra của IO THỐNG KÊ. Đó là bởi vì một loại có thể có khả năng tràn sang tempdb, trong trường hợp đó, nó sẽ sử dụng một bảng làm việc. Việc thực thi này không tràn, do đó tất cả các số đều là số không trong mục nhập này.
Giải pháp của John Nelson # 2, Dave, Joe, Alan, Charlie, Itzik
John Nelson # 2 đã đăng một giải pháp đẹp ở sự đơn giản của nó. Thêm vào đó, nó bao gồm các ý tưởng và đề xuất từ các giải pháp khác của Dave, Joe, Alan, Charlie và tôi.
Giống như giải pháp của Joe, John quyết định sử dụng CCI để có được mức độ nén cao và xử lý hàng loạt "miễn phí". Chỉ có John quyết định điền vào bảng 4B hàng bằng một số điểm đánh dấu NULL giả trong một cột bit và yêu cầu hàm ROW_NUMBER tạo ra các số. Vì các giá trị được lưu trữ đều giống nhau, với việc nén các giá trị lặp lại, bạn cần ít dung lượng hơn đáng kể, dẫn đến I / Os ít hơn đáng kể so với giải pháp của Joe. Tính năng nén Columnstore xử lý các giá trị lặp lại rất tốt vì nó có thể đại diện cho từng phần liên tiếp như vậy trong phân đoạn cột của nhóm hàng chỉ một lần cùng với số lần xuất hiện lặp lại liên tiếp. Vì tất cả các hàng có cùng một giá trị (điểm đánh dấu NULL), về mặt lý thuyết, bạn chỉ cần một lần xuất hiện cho mỗi nhóm hàng. Với 4B hàng, bạn sẽ có 4.096 nhóm hàng. Mỗi phân đoạn phải có một phân đoạn cột duy nhất, với yêu cầu sử dụng không gian rất ít.
Đây là mã để tạo và điền bảng, được triển khai dưới dạng CCI với tính năng nén lưu trữ:
DROP TABLE IF EXISTS dbo.NullBits4B;
CREATE TABLE dbo.NullBits4B
(
b BIT NULL,
INDEX cc_NullBits4B CLUSTERED COLUMNSTORE
WITH (DATA_COMPRESSION = COLUMNSTORE_ARCHIVE)
);
GO
WITH
L0 AS (SELECT CAST(NULL AS BIT) AS b
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1)) AS D(b)),
L1 AS (SELECT A.b FROM L0 AS A CROSS JOIN L0 AS B),
L2 AS (SELECT A.b FROM L1 AS A CROSS JOIN L1 AS B),
nulls(b) AS (SELECT A.b FROM L2 AS A CROSS JOIN L2 AS B)
INSERT INTO dbo.NullBits4B WITH (TABLOCK) (b)
SELECT b FROM nulls;
GO Nhược điểm chính của giải pháp này là mất thời gian để điền vào bảng này. Phải mất 12:32 phút để hoàn thành mã này trên máy tính của tôi khi cho phép song song và 15:17 phút khi buộc một kế hoạch nối tiếp.
Lưu ý rằng bạn có thể làm việc để tối ưu hóa tải dữ liệu. Ví dụ:John đã thử nghiệm một giải pháp tải các hàng bằng cách sử dụng 32 kết nối đồng thời với OSTRESS.EXE, mỗi kết nối chạy 128 vòng chèn của 2 ^ 20 hàng (kích thước nhóm hàng tối đa). Giải pháp này đã giảm thời gian tải của John xuống một phần ba. Đây là mã John đã sử dụng:
ostress -S (local) \ YourSQLInstance -E -dtempdb -n32 -r128 -Q "VỚI L0 AS (SELECT CAST (NULL AS BIT) AS b FROM (VALUES (1), (1), (1), (1)) , (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1)) AS D (b)), L1 AS (CHỌN A.b TỪ L0 AS A CROSS JOIN L0 AS B), L2 AS (CHỌN A.b TỪ L1 AS A CROSS JOIN L1 AS B), nulls (b) AS (CHỌN A.b TỪ L2 AS A CROSS JOIN L2 AS B) CHÈN VÀO dbo.NullBits4B (b) CHỌN ĐẦU (1048576) b TỪ TÙY CHỌN nulls (MAXDOP 1); "Tuy nhiên, thời gian tải tính bằng phút. Tin tốt là bạn chỉ cần thực hiện tải dữ liệu này một lần.
Tin tốt là số lượng không gian cần thiết của bàn. Sử dụng mã sau để kiểm tra việc sử dụng dung lượng:
EXEC sys.sp_spaceused @objname = N'dbo.NullBits4B';
Tôi có 1,64 MB. Điều đó thật tuyệt vời khi xem xét thực tế là bảng có 4B hàng!
Sử dụng đoạn mã sau để kiểm tra xem có bao nhiêu nhóm hàng đã được tạo:
SELECT COUNT(*) AS numrowgroups
FROM sys.column_store_row_groups
WHERE object_id = OBJECT_ID('dbo.NullBits4B'); Theo dự kiến, số lượng nhóm hàng là 4.096.
Định nghĩa hàm dbo.GetNumsJohn2DaveObbishAlanCharlieItzik sau đó trở nên khá đơn giản:
CREATE OR ALTER FUNCTION dbo.GetNumsJohn2DaveObbishAlanCharlieItzik
(@low AS BIGINT = 1, @high AS BIGINT) RETURNS TABLE
AS
RETURN
WITH
Nums AS (SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM dbo.NullBits4B)
SELECT TOP(@high - @low + 1)
rownum AS rn,
@high + 1 - rownum AS op,
@low - 1 + rownum AS n
FROM Nums
ORDER BY rownum;
GO
Như bạn có thể thấy, một truy vấn đơn giản đối với bảng sử dụng hàm ROW_NUMBER để tính số hàng cơ sở (cột rownum), sau đó truy vấn bên ngoài sử dụng các biểu thức tương tự như trong dbo.GetNumsAlanCharlieItzikBatch để tính rn, op và n. Cũng ở đây, cả rn và n đều đang bảo toàn trật tự đối với rownum.
Hãy kiểm tra hiệu suất của hàm:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsJohn2DaveObbishAlanCharlieItzik(1, 100000000);
Tôi nhận được kế hoạch được hiển thị trong Hình 5 cho việc thực thi này.
 Hình 5:Kế hoạch cho dbo.GetNumsJohn2DaveObbishAlanCharlieItzik
Hình 5:Kế hoạch cho dbo.GetNumsJohn2DaveObbishAlanCharlieItzik
Đây là thống kê thời gian mà tôi nhận được cho bài kiểm tra này:
Thời gian CPU =7593 ms, thời gian đã trôi qua =7590 ms.
Như bạn có thể thấy, thời gian thực hiện không nhanh bằng giải pháp của Joe nhưng vẫn nhanh hơn tất cả các giải pháp khác mà tôi đã thử nghiệm.
Dưới đây là số liệu thống kê I / O mà tôi nhận được cho thử nghiệm này:
Bảng 'NullBits4B'. Phân đoạn đọc 96 , phân đoạn bị bỏ qua 0
Lưu ý rằng các yêu cầu I / O thấp hơn đáng kể so với giải pháp của Joe.
Điều tuyệt vời khác về giải pháp này là khi bạn cần xử lý chuỗi số được đặt hàng, bạn không phải trả thêm bất kỳ khoản nào. Đó là vì nó sẽ không dẫn đến một hoạt động sắp xếp rõ ràng trong kế hoạch, bất kể bạn sắp xếp kết quả theo rn hay n.
Dưới đây là một bài kiểm tra để chứng minh điều này:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsJohn2DaveObbishAlanCharlieItzik(1, 100000000) ORDER BY n;
Bạn nhận được cùng một kế hoạch như được hiển thị trước đó trong Hình 5.
Đây là thống kê thời gian mà tôi nhận được cho bài kiểm tra này;
Thời gian CPU =7578 ms, thời gian đã trôi qua =7582 ms.Và đây là số liệu thống kê I / O:
Bảng 'NullBits4B'. Quét đếm 1, đọc logic 0, đọc vật lý 0, máy chủ trang đọc 0, đọc trước đọc 0, đọc trước máy chủ trang đọc 0, lần đọc logic lob 194 , máy chủ trang lob đọc 0, máy chủ trang lob đọc 0, máy chủ trang lob đọc trước 0, máy chủ trang lob đọc trước đọc 0.Bảng 'NullBits4B'. Phân đoạn đọc 96 , phân đoạn bị bỏ qua 0.
Về cơ bản chúng giống như trong thử nghiệm mà không cần đặt hàng.
Giải pháp 2 của John Nelson # 2, Dave Mason, Joe Obbish, Alan, Charlie, Itzik
Giải pháp của John nhanh chóng và đơn giản. Điều đó thật tuyệt. Một nhược điểm là thời gian tải. Đôi khi điều này sẽ không thành vấn đề vì quá trình tải chỉ diễn ra một lần. Nhưng nếu đó là sự cố, bạn có thể điền vào bảng 102.400 hàng thay vì 4B hàng và sử dụng kết hợp chéo giữa hai phiên bản của bảng và bộ lọc TOP để tạo ra tối đa 4B hàng mong muốn. Lưu ý rằng để có được 4B hàng, chỉ cần điền vào bảng 65.536 hàng và sau đó áp dụng một phép nối chéo; tuy nhiên, để dữ liệu được nén ngay lập tức — thay vì được tải vào kho lưu trữ delta dựa trên rowstore — bạn cần tải bảng với tối thiểu 102.400 hàng.
Đây là mã để tạo và điền bảng:
DROP TABLE IF EXISTS dbo.NullBits102400;
GO
CREATE TABLE dbo.NullBits102400
(
b BIT NULL,
INDEX cc_NullBits102400 CLUSTERED COLUMNSTORE
WITH (DATA_COMPRESSION = COLUMNSTORE_ARCHIVE)
);
GO
WITH
L0 AS (SELECT CAST(NULL AS BIT) AS b
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1)) AS D(b)),
L1 AS (SELECT A.b FROM L0 AS A CROSS JOIN L0 AS B),
nulls(b) AS (SELECT A.b FROM L1 AS A CROSS JOIN L1 AS B CROSS JOIN L1 AS C)
INSERT INTO dbo.NullBits102400 WITH (TABLOCK) (b)
SELECT TOP(102400) b FROM nulls;
GO Thời gian tải không đáng kể - 43 ms trên máy của tôi.
Kiểm tra kích thước của bảng trên đĩa:
EXEC sys.sp_spaceused @objname = N'dbo.NullBits102400';
Tôi cần 56 KB dung lượng cho dữ liệu.
Kiểm tra số lượng nhóm hàng, trạng thái của chúng (nén hoặc mở) và kích thước của chúng:
SELECT state_description, total_rows, size_in_bytes
FROM sys.column_store_row_groups
WHERE object_id = OBJECT_ID('dbo.NullBits102400'); Tôi nhận được kết quả sau:
state_description total_rows size_in_bytes ------------------ ----------- -------------- COMPRESSED 102400 293
Ở đây chỉ cần một nhóm hàng; nó được nén và kích thước là 293 byte không đáng kể.
Nếu bạn điền vào bảng ít hơn một hàng (102.399), bạn sẽ có một cửa hàng delta mở không nén dựa trên rowstore. Trong trường hợp này, sp_spaceused báo cáo kích thước dữ liệu trên đĩa trên 1MB và sys.column_store_row_groups báo cáo thông tin sau:
state_description total_rows size_in_bytes ------------------ ----------- -------------- OPEN 102399 1499136
Vì vậy, hãy đảm bảo bạn điền vào bảng 102.400 hàng!
Đây là định nghĩa của hàm dbo.GetNumsJohn2DaveObbishAlanCharlieItzik2:
CREATE OR ALTER FUNCTION dbo.GetNumsJohn2DaveObbishAlanCharlieItzik2
(@low AS BIGINT = 1, @high AS BIGINT) RETURNS TABLE
AS
RETURN
WITH
Nums AS (SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM dbo.NullBits102400 AS A
CROSS JOIN dbo.NullBits102400 AS B)
SELECT TOP(@high - @low + 1)
rownum AS rn,
@high + 1 - rownum AS op,
@low - 1 + rownum AS n
FROM Nums
ORDER BY rownum;
GO Let’s test the function's performance:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsJohn2DaveObbishAlanCharlieItzik2(1, 100000000) OPTION(MAXDOP 1);
I got the plan shown in Figure 6 for this execution.
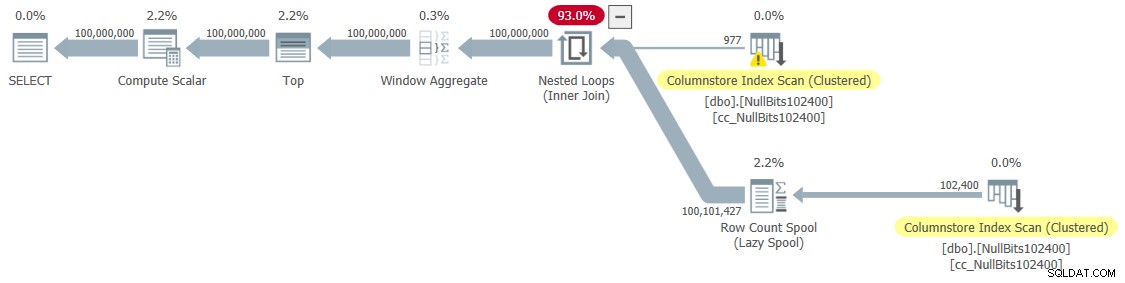 Figure 6:Plan for dbo.GetNumsJohn2DaveObbishAlanCharlieItzik2
Figure 6:Plan for dbo.GetNumsJohn2DaveObbishAlanCharlieItzik2
I got the following time statistics for this test:
CPU time =9188 ms, elapsed time =9188 ms.As you can see, the execution time increased by ~ 26%. It’s still pretty fast, but not as fast as the single-table solution. So that’s a tradeoff that you’ll need to evaluate.
I got the following I/O stats for this test:
Table 'NullBits102400'. Scan count 2, logical reads 0, physical reads 0, page server reads 0, read-ahead reads 0, page server read-ahead reads 0, lob logical reads 8 , lob physical reads 0, lob page server reads 0, lob read-ahead reads 0, lob page server read-ahead reads 0.Table 'NullBits102400'. Segment reads 2, segment skipped 0.
The I/O profile of this solution is excellent.
Let’s add order to the test:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsJohn2DaveObbishAlanCharlieItzik2(1, 100000000) ORDER BY n OPTION(MAXDOP 1);
You get the same plan as shown earlier in Figure 6 since there’s no explicit sorting needed.
I got the following time statistics for this test:
CPU time =9140 ms, elapsed time =9237 ms.And the following I/O stats:
Table 'NullBits102400'. Scan count 2, logical reads 0, physical reads 0, page server reads 0, read-ahead reads 0, page server read-ahead reads 0, lob logical reads 8 , lob physical reads 0, lob page server reads 0, lob read-ahead reads 0, lob page server read-ahead reads 0.Table 'NullBits102400'. Segment reads 2, segment skipped 0.
Again, the numbers are very similar to the test without the ordering.
Performance summary
Figure 7 has a summary of the time statistics for the different solutions.
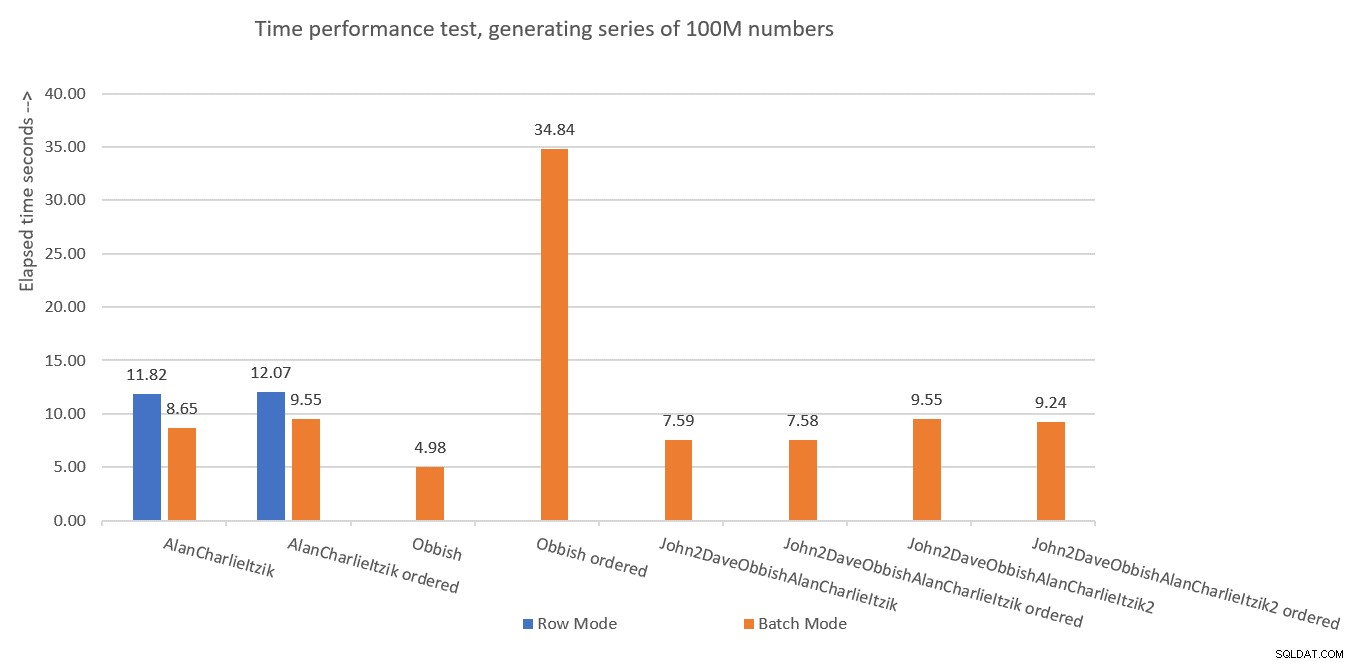 Figure 7:Time performance summary of solutions
Figure 7:Time performance summary of solutions
Figure 8 has a summary of the I/O statistics.
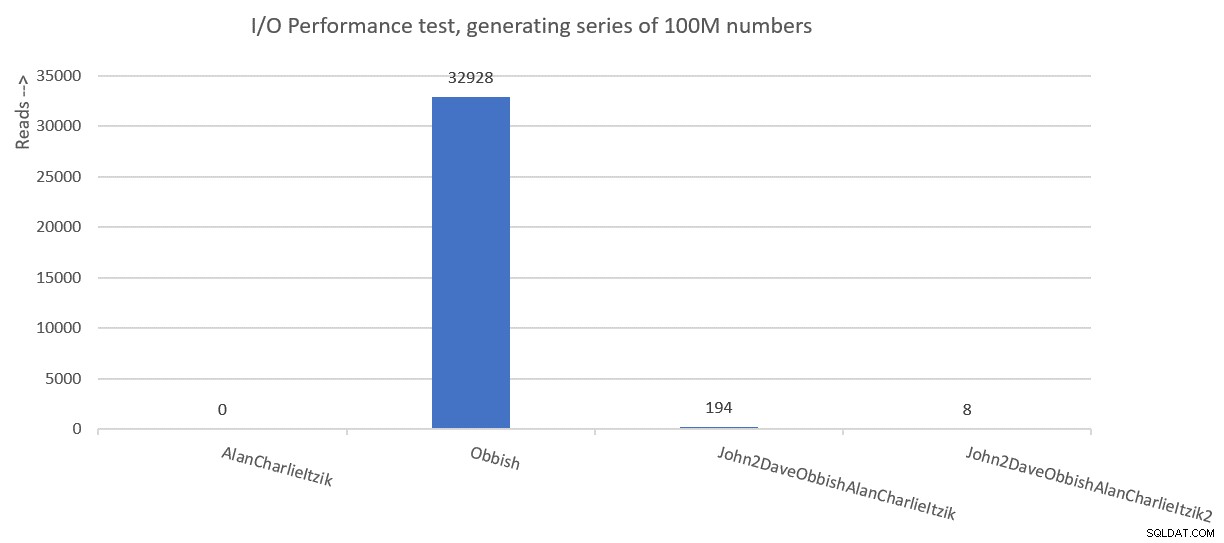 Figure 8:I/O performance summary of solutions
Figure 8:I/O performance summary of solutions
Thanks to all of you who posted ideas and suggestions in effort to create a fast number series generator. It’s a great learning experience!
We’re not done yet. Next month I’ll continue exploring additional solutions.