Thông thường, khi chúng ta viết một thủ tục được lưu trữ, chúng ta muốn nó hoạt động theo những cách khác nhau dựa trên đầu vào của người dùng. Hãy xem ví dụ sau:
CREATE PROCEDURE Sales.GetOrders ( @CustomerID AS INT = NULL , @SortOrder AS SYSNAME = N'OrderDate' ) AS SELECT TOP (10) SalesOrderID = SalesOrders.SalesOrderID , OrderDate = CAST (SalesOrders.OrderDate AS DATE) , OrderStatus = SalesOrders.[Status] , CustomerID = SalesOrders.CustomerID , OrderTotal = SUM (SalesOrderDetails.LineTotal) FROM Sales.SalesOrderHeader AS SalesOrders INNER JOIN Sales.SalesOrderDetail AS SalesOrderDetails ON SalesOrders.SalesOrderID = SalesOrderDetails.SalesOrderID WHERE SalesOrders.CustomerID = @CustomerID OR @CustomerID IS NULL GROUP BY SalesOrders.SalesOrderID , SalesOrders.OrderDate , SalesOrders.DueDate , SalesOrders.[Status] , SalesOrders.CustomerID ORDER BY CASE @SortOrder WHEN N'OrderDate' THEN SalesOrders.OrderDate WHEN N'SalesOrderID' THEN SalesOrders.SalesOrderID END ASC; GO
Thủ tục được lưu trữ này, mà tôi đã tạo trong cơ sở dữ liệu AdventureWorks2017, có hai tham số:@CustomerID và @SortOrder. Tham số đầu tiên, @CustomerID, ảnh hưởng đến các hàng được trả về. Nếu một ID khách hàng cụ thể được chuyển đến quy trình đã lưu trữ, thì nó sẽ trả về tất cả các đơn đặt hàng (top 10) cho khách hàng này. Ngược lại, nếu nó là NULL, thì thủ tục được lưu trữ sẽ trả về tất cả các đơn đặt hàng (top 10), bất kể khách hàng là gì. Tham số thứ hai, @SortOrder, xác định cách dữ liệu sẽ được sắp xếp — theo OrderDate hoặc SalesOrderID. Lưu ý rằng chỉ 10 hàng đầu tiên sẽ được trả lại theo thứ tự sắp xếp.
Vì vậy, người dùng có thể ảnh hưởng đến hành vi của truy vấn theo hai cách — trả về những hàng nào và cách sắp xếp chúng. Nói chính xác hơn, có 4 hành vi khác nhau cho truy vấn này:
- Trả lại 10 hàng hàng đầu cho tất cả khách hàng được sắp xếp theo Ngày đặt hàng (hành vi mặc định)
- Trả lại 10 hàng hàng đầu cho một khách hàng cụ thể được sắp xếp theo Ngày đặt hàng
- Trả lại 10 hàng hàng đầu cho tất cả khách hàng được phân loại theo SalesOrderID
- Trả lại 10 hàng hàng đầu cho một khách hàng cụ thể được sắp xếp theo SalesOrderID
Hãy kiểm tra thủ tục được lưu trữ với tất cả 4 tùy chọn và kiểm tra kế hoạch thực thi và IO thống kê.
Trả lại 10 hàng hàng đầu cho tất cả khách hàng được sắp xếp theo ngày đặt hàng
Sau đây là mã để thực hiện quy trình được lưu trữ:
EXECUTE Sales.GetOrders; GO
Đây là kế hoạch thực hiện:
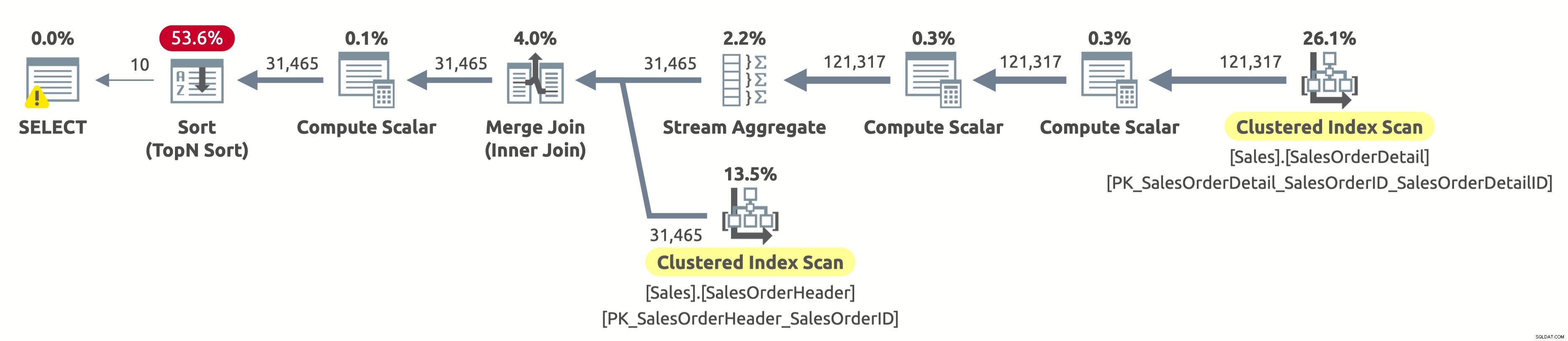
Vì chúng tôi chưa lọc theo khách hàng, chúng tôi cần quét toàn bộ bảng. Trình tối ưu hóa đã chọn quét cả hai bảng bằng cách sử dụng các chỉ mục trên SalesOrderID, điều này cho phép Tổng hợp luồng hiệu quả cũng như Kết hợp hợp nhất hiệu quả.
Nếu bạn kiểm tra các thuộc tính của toán tử Clustered Index Scan trên bảng Sales.SalesOrderHeader, bạn sẽ tìm thấy vị từ sau:[AdventureWorks2017]. [Sales]. [SalesOrderHeader]. [CustomerID] as [SalesOrders]. [CustomerID] =[ @CustomerID] HOẶC [@CustomerID] LÀ KHÔNG ĐỦ. Bộ xử lý truy vấn phải đánh giá vị từ này cho mỗi hàng trong bảng, điều này không hiệu quả lắm vì nó sẽ luôn đánh giá thành true.
Chúng ta vẫn cần sắp xếp tất cả dữ liệu theo OrderDate để trả về 10 hàng đầu tiên. Nếu có một chỉ mục trên OrderDate, thì trình tối ưu hóa có thể đã sử dụng nó để chỉ quét 10 hàng đầu tiên từ Sales.SalesOrderHeader, nhưng không có chỉ mục này, vì vậy kế hoạch có vẻ ổn khi xem xét các chỉ mục có sẵn.
Đây là kết quả của thống kê IO:
- Bảng 'SalesOrderHeader'. Quét đếm 1, đọc logic 689
- Bảng 'SalesOrderDetail'. Quét đếm 1, đọc logic 1248
Nếu bạn đang hỏi tại sao lại có cảnh báo trên toán tử CHỌN, thì đó là cảnh báo cấp quá nhiều. Trong trường hợp này, không phải do có sự cố trong kế hoạch thực thi mà là do bộ xử lý truy vấn yêu cầu 1.024KB (là mức tối thiểu theo mặc định) và chỉ sử dụng 16KB.
Đôi khi Kế hoạch Caching không phải là một ý tưởng hay
Tiếp theo, chúng tôi muốn kiểm tra kịch bản trả lại 10 hàng hàng đầu cho một khách hàng cụ thể được sắp xếp theo OrderDate. Dưới đây là mã:
EXECUTE Sales.GetOrders @CustomerID = 11006; GO
Kế hoạch thực hiện giống hệt như trước đây. Lần này, kế hoạch này rất kém hiệu quả vì nó quét cả hai bảng chỉ để trả về 3 đơn đặt hàng. Có nhiều cách tốt hơn để thực hiện truy vấn này.
Lý do, trong trường hợp này, là bộ nhớ đệm kế hoạch. Kế hoạch thực thi được tạo trong lần thực thi đầu tiên dựa trên các giá trị tham số trong lần thực thi cụ thể đó — một phương thức được gọi là đánh giá tham số. Gói đó đã được lưu trữ trong bộ nhớ cache của gói để sử dụng lại và kể từ bây giờ, mọi lệnh gọi đến thủ tục được lưu trữ này sẽ sử dụng lại cùng một gói.
Đây là một ví dụ mà bộ nhớ đệm kế hoạch không phải là một ý tưởng hay. Do bản chất của thủ tục được lưu trữ này, có 4 hành vi khác nhau, chúng tôi mong đợi có được một kế hoạch khác nhau cho mỗi hành vi. Nhưng chúng tôi bị mắc kẹt với một kế hoạch duy nhất, chỉ phù hợp với một trong 4 tùy chọn, dựa trên tùy chọn được sử dụng trong lần thực thi đầu tiên.
Hãy vô hiệu hóa bộ nhớ đệm kế hoạch cho quy trình được lưu trữ này, để chúng tôi có thể thấy kế hoạch tốt nhất mà trình tối ưu hóa có thể đưa ra cho mỗi một trong 3 hành vi còn lại. Chúng tôi sẽ thực hiện việc này bằng cách thêm WITH RECOMPILE vào lệnh EXECUTE.
Trả lại 10 hàng hàng đầu cho một khách hàng cụ thể được sắp xếp theo ngày đặt hàng
Sau đây là mã để trả về 10 hàng hàng đầu cho một khách hàng cụ thể được sắp xếp theo Ngày đặt hàng:
EXECUTE Sales.GetOrders @CustomerID = 11006 WITH RECOMPILE; GO
Sau đây là kế hoạch thực hiện:
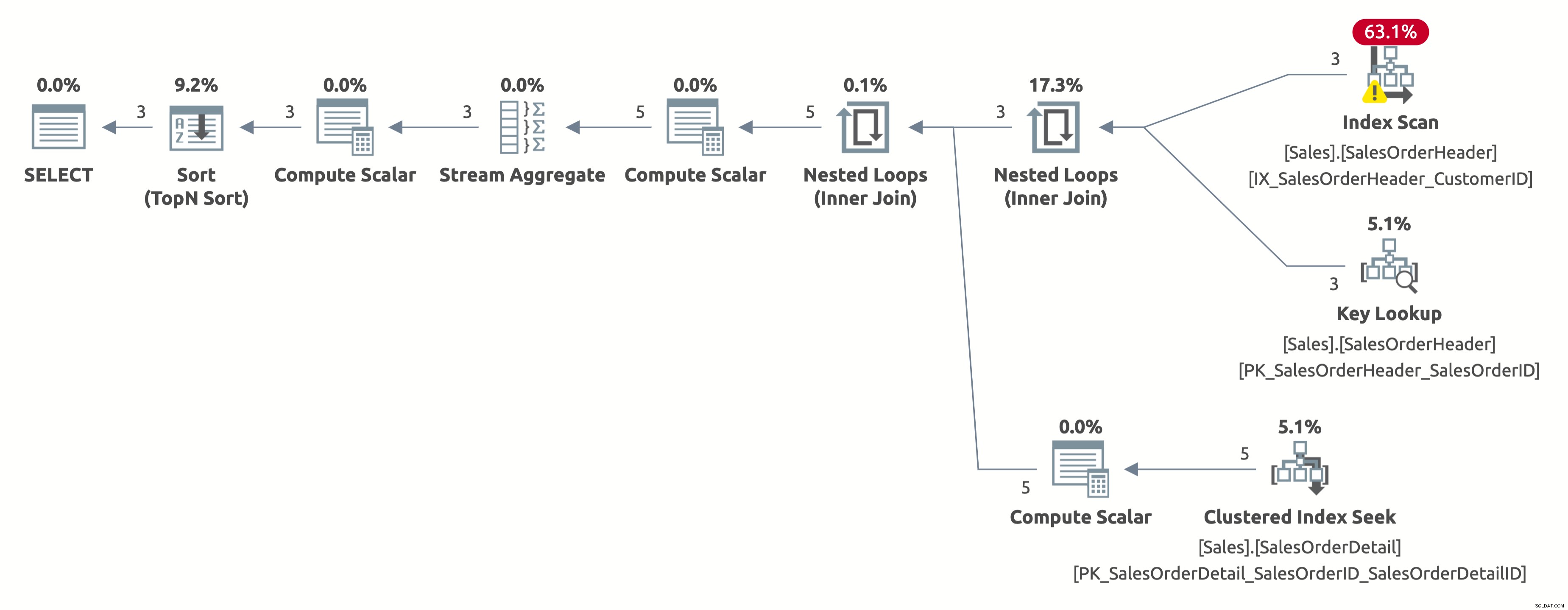
Lần này, chúng tôi nhận được một kế hoạch tốt hơn, sử dụng một chỉ mục trên CustomerID. Trình tối ưu hóa ước tính chính xác 2,6 hàng cho CustomerID =11006 (số lượng thực tế là 3). Nhưng lưu ý rằng nó thực hiện quét chỉ mục thay vì tìm kiếm chỉ mục. Nó không thể thực hiện tìm kiếm chỉ mục vì nó phải đánh giá vị từ sau cho mỗi hàng trong bảng:[AdventureWorks2017]. [Sales]. [SalesOrderHeader]. [CustomerID] as [SalesOrders]. [CustomerID] =[@ CustomerID ] HOẶC [@CustomerID] LÀ KHÔNG ĐỦ.
Đây là kết quả của thống kê IO:
- Bảng 'SalesOrderDetail'. Quét đếm 3, đọc logic 9
- Bảng 'SalesOrderHeader'. Quét đếm 1, đọc logic 66
Trả lại 10 hàng hàng đầu cho tất cả khách hàng được sắp xếp theo SalesOrderID
Sau đây là mã để trả về 10 hàng hàng đầu cho tất cả khách hàng được sắp xếp theo SalesOrderID:
EXECUTE Sales.GetOrders @SortOrder = N'SalesOrderID' WITH RECOMPILE; GO
Sau đây là kế hoạch thực hiện:
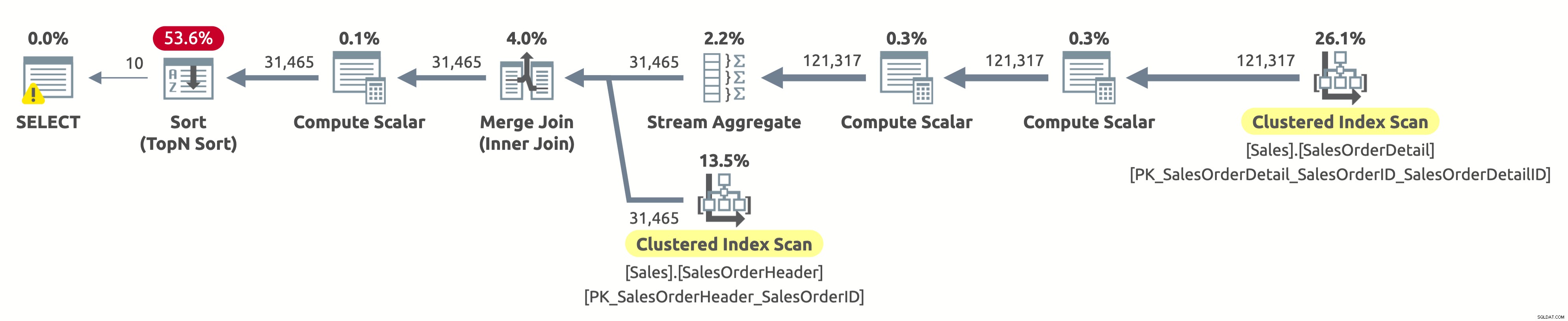
Này, đây là kế hoạch thực hiện giống như trong tùy chọn đầu tiên. Nhưng lần này, có điều gì đó không ổn. Chúng ta đã biết rằng các chỉ mục nhóm trên cả hai bảng được sắp xếp theo SalesOrderID. Chúng ta cũng biết rằng kế hoạch quét cả hai theo thứ tự logic để giữ lại thứ tự sắp xếp (thuộc tính Order được đặt thành True). Toán tử Kết hợp Kết hợp cũng giữ lại thứ tự sắp xếp. Bởi vì chúng tôi hiện đang yêu cầu sắp xếp kết quả theo SalesOrderID và nó đã được sắp xếp theo cách đó, vậy tại sao chúng tôi phải trả tiền cho một toán tử Sắp xếp đắt tiền?
Vâng, nếu bạn kiểm tra toán tử Sắp xếp, bạn sẽ nhận thấy rằng nó sắp xếp dữ liệu theo Expr1004. Và, nếu bạn kiểm tra toán tử Tính vô hướng ở bên phải của toán tử Sắp xếp, thì bạn sẽ phát hiện ra rằng Expr1004 như sau:

Đó không phải là một cảnh đẹp, tôi biết. Đây là biểu thức mà chúng ta có trong mệnh đề ORDER BY của truy vấn của chúng ta. Vấn đề là trình tối ưu hóa không thể đánh giá biểu thức này tại thời điểm biên dịch, vì vậy nó phải tính toán biểu thức này cho từng hàng trong thời gian chạy và sau đó sắp xếp toàn bộ tập hợp bản ghi dựa trên đó.
Đầu ra của thống kê IO giống như trong lần thực thi đầu tiên:
- Bảng 'SalesOrderHeader'. Quét đếm 1, đọc logic 689
- Bảng 'SalesOrderDetail'. Quét đếm 1, đọc logic 1248
Trả lại 10 hàng hàng đầu cho một khách hàng cụ thể được sắp xếp theo SalesOrderID
Sau đây là mã để trả về 10 hàng hàng đầu cho một khách hàng cụ thể được sắp xếp theo SalesOrderID:
EXECUTE Sales.GetOrders @CustomerID = 11006 , @SortOrder = N'SalesOrderID' WITH RECOMPILE; GO
Kế hoạch thực hiện giống như trong tùy chọn thứ hai (trả lại 10 hàng hàng đầu cho một khách hàng cụ thể được sắp xếp theo OrderDate). Kế hoạch có hai vấn đề giống nhau, mà chúng tôi đã đề cập đến. Vấn đề đầu tiên là thực hiện quét chỉ mục chứ không phải tìm kiếm chỉ mục do biểu thức trong mệnh đề WHERE. Vấn đề thứ hai là thực hiện một sắp xếp đắt tiền do biểu thức trong mệnh đề ORDER BY.
Vậy, chúng ta nên làm gì?
Trước tiên, chúng ta hãy nhắc nhở bản thân về những gì chúng ta đang đối phó. Chúng tôi có các tham số, xác định cấu trúc của truy vấn. Đối với mỗi sự kết hợp của các giá trị tham số, chúng tôi nhận được một cấu trúc truy vấn khác nhau. Trong trường hợp của tham số @CustomerID, hai hành vi khác nhau là NULL hoặc NOT NULL và chúng ảnh hưởng đến mệnh đề WHERE. Trong trường hợp của tham số @SortOrder, có thể có hai giá trị và chúng ảnh hưởng đến mệnh đề ORDER BY. Kết quả là có thể có 4 cấu trúc truy vấn và chúng tôi muốn có một kế hoạch khác nhau cho từng cấu trúc.
Sau đó, chúng tôi có hai vấn đề riêng biệt. Đầu tiên là kế hoạch caching. Chỉ có một kế hoạch duy nhất cho thủ tục được lưu trữ và nó sẽ được tạo dựa trên các giá trị tham số trong lần thực thi đầu tiên. Vấn đề thứ hai là ngay cả khi một kế hoạch mới được tạo, nó không hiệu quả vì trình tối ưu hóa không thể đánh giá các biểu thức "động" trong mệnh đề WHERE và trong mệnh đề ORDER BY tại thời điểm biên dịch.
Chúng tôi có thể cố gắng giải quyết những vấn đề này theo một số cách:
- Sử dụng một loạt các câu lệnh IF-ELSE
- Chia thủ tục thành các thủ tục được lưu trữ riêng biệt
- Sử dụng TÙY CHỌN (RECOMPILE)
- Tạo truy vấn động
Sử dụng một loạt câu lệnh IF-ELSE
Ý tưởng rất đơn giản:thay vì các biểu thức "động" trong mệnh đề WHERE và trong mệnh đề ORDER BY, chúng ta có thể chia việc thực thi thành 4 nhánh bằng cách sử dụng các câu lệnh IF-ELSE — một nhánh cho mỗi hành vi có thể xảy ra.
Ví dụ, sau đây là mã cho nhánh đầu tiên:
IF @CustomerID IS NULL AND @SortOrder = N'OrderDate' BEGIN SELECT TOP (10) SalesOrderID = SalesOrders.SalesOrderID , OrderDate = CAST (SalesOrders.OrderDate AS DATE) , OrderStatus = SalesOrders.[Status] , CustomerID = SalesOrders.CustomerID , OrderTotal = SUM (SalesOrderDetails.LineTotal) FROM Sales.SalesOrderHeader AS SalesOrders INNER JOIN Sales.SalesOrderDetail AS SalesOrderDetails ON SalesOrders.SalesOrderID = SalesOrderDetails.SalesOrderID GROUP BY SalesOrders.SalesOrderID, SalesOrders.OrderDate, SalesOrders.DueDate, SalesOrders.[Status], SalesOrders.CustomerID ORDER BY SalesOrders.OrderDate ASC; END;
Cách tiếp cận này có thể giúp tạo ra các kế hoạch tốt hơn, nhưng nó có một số hạn chế.
Đầu tiên, thủ tục được lưu trữ trở nên khá dài và khó viết, đọc và duy trì hơn. Và đây là khi chúng ta chỉ có hai tham số. Nếu chúng ta có 3 tham số, chúng ta sẽ có 8 nhánh. Hãy tưởng tượng rằng bạn cần thêm một cột vào mệnh đề SELECT. Bạn sẽ phải thêm cột trong 8 truy vấn khác nhau. Nó trở thành cơn ác mộng bảo trì, với nguy cơ cao do lỗi của con người.
Thứ hai, chúng ta vẫn gặp vấn đề về bộ nhớ đệm kế hoạch và đánh giá tham số ở một mức độ nào đó. Điều này là do trong lần thực thi đầu tiên, trình tối ưu hóa sẽ tạo một kế hoạch cho cả 4 truy vấn dựa trên các giá trị tham số trong lần thực thi đó. Giả sử rằng lần thực thi đầu tiên sẽ sử dụng các giá trị mặc định cho các tham số. Cụ thể, giá trị của @CustomerID sẽ là NULL. Tất cả các truy vấn sẽ được tối ưu hóa dựa trên giá trị đó, bao gồm cả truy vấn có mệnh đề WHERE (SalesOrders.CustomerID =@CustomerID). Trình tối ưu hóa sẽ ước tính 0 hàng cho những truy vấn này. Bây giờ, giả sử rằng lần thực thi thứ hai sẽ sử dụng giá trị không phải null cho @CustomerID. Kế hoạch đã lưu trong bộ nhớ cache, ước tính 0 hàng, sẽ được sử dụng, mặc dù khách hàng có thể có nhiều đơn đặt hàng trong bảng.
Chia thủ tục thành các thủ tục được lưu trữ riêng biệt
Thay vì 4 nhánh trong cùng một thủ tục được lưu trữ, chúng ta có thể tạo 4 thủ tục được lưu trữ riêng biệt, mỗi nhánh có các tham số liên quan và truy vấn tương ứng. Sau đó, chúng ta có thể viết lại ứng dụng để quyết định thủ tục được lưu trữ nào sẽ thực thi theo các hành vi mong muốn. Hoặc, nếu chúng ta muốn nó trong suốt với ứng dụng, chúng ta có thể viết lại thủ tục được lưu trữ ban đầu để quyết định thủ tục nào sẽ thực thi dựa trên các giá trị tham số. Chúng tôi sẽ sử dụng các câu lệnh IF-ELSE giống nhau, nhưng thay vì thực hiện một truy vấn trong mỗi nhánh, chúng tôi sẽ thực hiện một thủ tục được lưu trữ riêng biệt.
Ưu điểm là chúng tôi giải quyết được vấn đề bộ nhớ đệm kế hoạch vì mỗi thủ tục được lưu trữ hiện có kế hoạch riêng của nó và kế hoạch cho mỗi thủ tục được lưu trữ sẽ được tạo trong lần thực thi đầu tiên dựa trên đánh giá tham số.
Nhưng chúng tôi vẫn gặp vấn đề về bảo trì. Một số người có thể nói rằng bây giờ nó thậm chí còn tồi tệ hơn, bởi vì chúng tôi cần duy trì nhiều thủ tục được lưu trữ. Một lần nữa, nếu chúng ta tăng số lượng tham số lên 3, chúng ta sẽ có 8 thủ tục được lưu trữ riêng biệt.
Sử dụng TÙY CHỌN (RECOMPILE)
TÙY CHỌN (RECOMPILE) hoạt động như một phép thuật. Bạn chỉ cần nói các từ (hoặc thêm chúng vào truy vấn), và điều kỳ diệu sẽ xảy ra. Thực sự, nó giải quyết rất nhiều vấn đề vì nó biên dịch truy vấn trong thời gian chạy và nó thực hiện nó cho mọi lần thực thi.
Nhưng bạn phải cẩn thận vì bạn biết những gì họ nói:"Với quyền lực lớn thì trách nhiệm lớn." Nếu bạn sử dụng TÙY CHỌN (RECOMPILE) trong một truy vấn được thực thi rất thường xuyên trên hệ thống OLTP bận rộn, thì bạn có thể giết hệ thống vì máy chủ cần biên dịch và tạo một kế hoạch mới trong mỗi lần thực thi, sử dụng nhiều tài nguyên CPU. Điều này thực sự nguy hiểm. Tuy nhiên, nếu truy vấn chỉ được thực thi một lần trong một thời gian, giả sử cứ sau vài phút lại thực hiện một lần, thì nó có thể là an toàn. Nhưng luôn kiểm tra tác động trong môi trường cụ thể của bạn.
Trong trường hợp của chúng tôi, giả sử chúng tôi có thể sử dụng OPTION (RECOMPILE) một cách an toàn, tất cả những gì chúng tôi phải làm là thêm các từ ma thuật vào cuối truy vấn của chúng tôi, như được hiển thị bên dưới:
ALTER PROCEDURE Sales.GetOrders ( @CustomerID AS INT = NULL , @SortOrder AS SYSNAME = N'OrderDate' ) AS SELECT TOP (10) SalesOrderID = SalesOrders.SalesOrderID , OrderDate = CAST (SalesOrders.OrderDate AS DATE) , OrderStatus = SalesOrders.[Status] , CustomerID = SalesOrders.CustomerID , OrderTotal = SUM (SalesOrderDetails.LineTotal) FROM Sales.SalesOrderHeader AS SalesOrders INNER JOIN Sales.SalesOrderDetail AS SalesOrderDetails ON SalesOrders.SalesOrderID = SalesOrderDetails.SalesOrderID WHERE SalesOrders.CustomerID = @CustomerID OR @CustomerID IS NULL GROUP BY SalesOrders.SalesOrderID , SalesOrders.OrderDate , SalesOrders.DueDate , SalesOrders.[Status] , SalesOrders.CustomerID ORDER BY CASE @SortOrder WHEN N'OrderDate' THEN SalesOrders.OrderDate WHEN N'SalesOrderID' THEN SalesOrders.SalesOrderID END ASC OPTION (RECOMPILE); GO
Bây giờ, chúng ta hãy xem điều kỳ diệu trong hành động. Ví dụ:sau đây là kế hoạch cho hành vi thứ hai:
EXECUTE Sales.GetOrders @CustomerID = 11006; GO
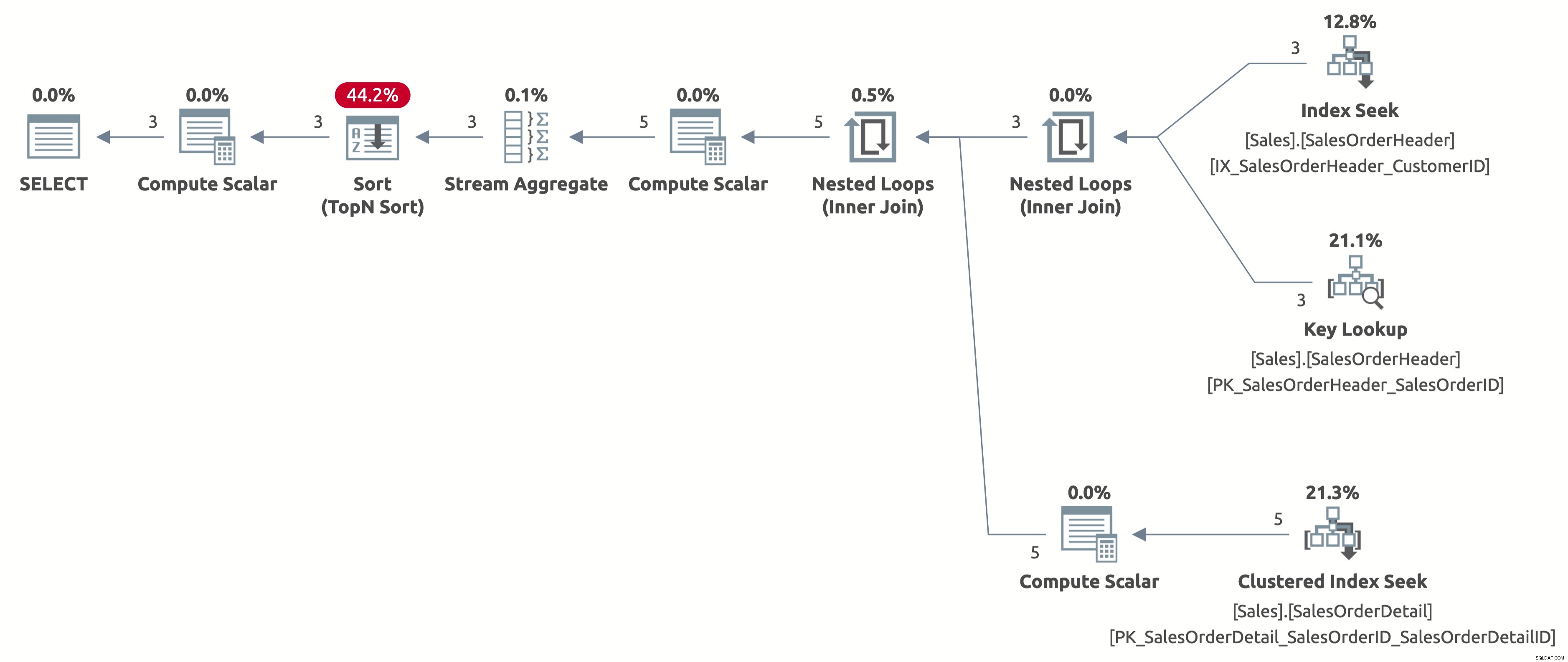
Bây giờ chúng tôi nhận được một tìm kiếm chỉ mục hiệu quả với ước tính chính xác là 2,6 hàng. Chúng ta vẫn cần sắp xếp theo Ngày đặt hàng, nhưng bây giờ việc sắp xếp trực tiếp theo Ngày đặt hàng và chúng ta không phải tính biểu thức CASE trong mệnh đề ORDER BY nữa. Đây là kế hoạch tốt nhất có thể cho hành vi truy vấn này dựa trên các chỉ mục có sẵn.
Đây là kết quả của thống kê IO:
- Bảng 'SalesOrderDetail'. Quét đếm 3, đọc logic 9
- Bảng 'SalesOrderHeader'. Quét đếm 1, đọc lôgic 11
Lý do mà TÙY CHỌN (RECOMPILE) rất hiệu quả trong trường hợp này là nó giải quyết chính xác hai vấn đề mà chúng ta gặp phải ở đây. Hãy nhớ rằng vấn đề đầu tiên là bộ nhớ đệm kế hoạch. OPTION (RECOMPILE) loại bỏ hoàn toàn vấn đề này vì nó biên dịch lại truy vấn mọi lúc. Vấn đề thứ hai là trình tối ưu hóa không có khả năng đánh giá biểu thức phức tạp trong mệnh đề WHERE và trong mệnh đề ORDER BY tại thời điểm biên dịch. Vì TÙY CHỌN (RECOMPILE) xảy ra trong thời gian chạy, nó giải quyết được vấn đề. Bởi vì trong thời gian chạy, trình tối ưu hóa có nhiều thông tin hơn so với thời gian biên dịch và nó tạo ra tất cả sự khác biệt.
Bây giờ, hãy xem điều gì sẽ xảy ra khi chúng ta thử hành vi thứ ba:
EXECUTE Sales.GetOrders @SortOrder = N'SalesOrderID'; GO
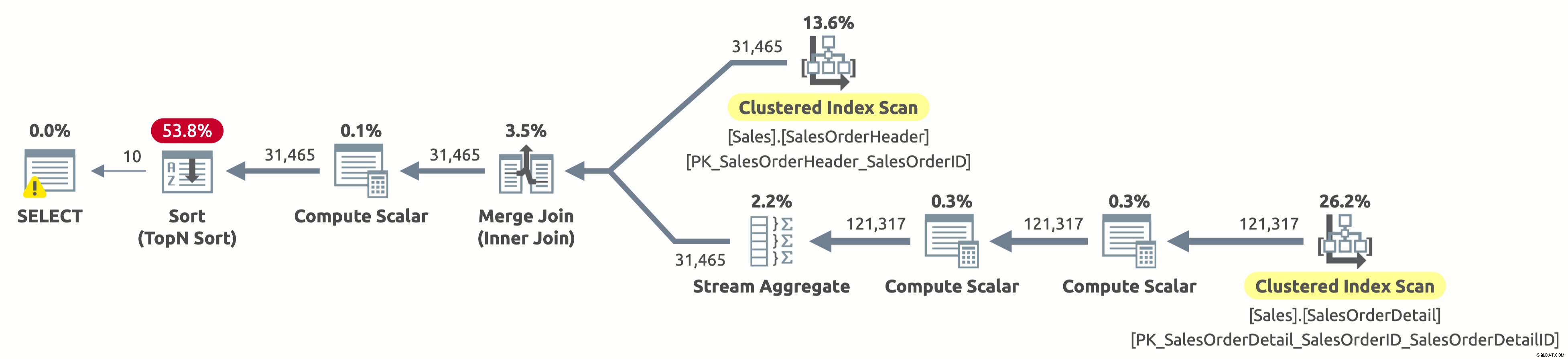
Houston chúng ta có một vấn đề. Kế hoạch vẫn quét toàn bộ cả hai bảng và sau đó sắp xếp mọi thứ, thay vì chỉ quét 10 hàng đầu tiên từ Sales.SalesOrderHeader và tránh sắp xếp hoàn toàn. Điều gì đã xảy ra?
Đây là một "trường hợp" thú vị và nó liên quan đến biểu thức CASE trong mệnh đề ORDER BY. Biểu thức CASE đánh giá danh sách các điều kiện và trả về một trong các biểu thức kết quả. Nhưng các biểu thức kết quả có thể có các kiểu dữ liệu khác nhau. Vì vậy, kiểu dữ liệu của toàn bộ biểu thức CASE sẽ là gì? Vâng, biểu thức CASE luôn trả về kiểu dữ liệu có mức độ ưu tiên cao nhất. Trong trường hợp của chúng tôi, cột OrderDate có kiểu dữ liệu DATETIME, trong khi cột SalesOrderID có kiểu dữ liệu INT. Kiểu dữ liệu DATETIME có mức độ ưu tiên cao hơn, do đó, biểu thức CASE luôn trả về DATETIME.
Điều này có nghĩa là nếu chúng ta muốn sắp xếp theo SalesOrderID, biểu thức CASE trước tiên cần phải chuyển đổi ngầm định giá trị của SalesOrderID thành DATETIME cho mỗi hàng trước khi sắp xếp nó. Xem toán tử Tính toán vô hướng ở bên phải của toán tử Sắp xếp trong kế hoạch ở trên? Đó chính xác là những gì nó làm.
Bản thân đây là một vấn đề và nó cho thấy mức độ nguy hiểm của việc trộn các kiểu dữ liệu khác nhau trong một biểu thức CASE duy nhất.
Chúng ta có thể giải quyết vấn đề này bằng cách viết lại mệnh đề ORDER BY theo những cách khác, nhưng nó sẽ làm cho mã trở nên xấu hơn và khó đọc và khó bảo trì. Vì vậy, tôi sẽ không đi theo hướng đó.
Thay vào đó, hãy thử phương pháp tiếp theo…
Tạo truy vấn động
Vì mục tiêu của chúng tôi là tạo 4 cấu trúc truy vấn khác nhau trong một truy vấn duy nhất, nên SQL động có thể rất hữu ích trong trường hợp này. Ý tưởng là xây dựng truy vấn động dựa trên các giá trị tham số. Bằng cách này, chúng ta có thể xây dựng 4 cấu trúc truy vấn khác nhau trong một mã duy nhất mà không cần phải duy trì 4 bản sao của truy vấn. Mỗi cấu trúc truy vấn sẽ biên dịch một lần, khi nó được thực thi lần đầu tiên và nó sẽ có được kế hoạch tốt nhất vì nó không chứa bất kỳ biểu thức phức tạp nào.
Giải pháp này rất giống với giải pháp có nhiều thủ tục được lưu trữ, nhưng thay vì duy trì 8 thủ tục được lưu trữ cho 3 tham số, chúng tôi chỉ duy trì một mã duy nhất tạo truy vấn động.
Tôi biết, SQL động cũng xấu và đôi khi có thể khá khó bảo trì, nhưng tôi nghĩ nó vẫn dễ dàng hơn so với việc duy trì nhiều thủ tục được lưu trữ và nó không mở rộng theo cấp số nhân khi số lượng tham số tăng lên.
Sau đây là mã:
ALTER PROCEDURE Sales.GetOrders ( @CustomerID AS INT = NULL , @SortOrder AS SYSNAME = N'OrderDate' ) AS DECLARE @Command AS NVARCHAR(MAX); SET @Command = N' SELECT TOP (10) SalesOrderID = SalesOrders.SalesOrderID , OrderDate = CAST (SalesOrders.OrderDate AS DATE) , OrderStatus = SalesOrders.[Status] , CustomerID = SalesOrders.CustomerID , OrderTotal = SUM (SalesOrderDetails.LineTotal) FROM Sales.SalesOrderHeader AS SalesOrders INNER JOIN Sales.SalesOrderDetail AS SalesOrderDetails ON SalesOrders.SalesOrderID = SalesOrderDetails.SalesOrderID ' + CASE WHEN @CustomerID IS NULL THEN N'' ELSE N'WHERE SalesOrders.CustomerID = @pCustomerID ' END + N'GROUP BY SalesOrders.SalesOrderID , SalesOrders.OrderDate , SalesOrders.DueDate , SalesOrders.[Status] , SalesOrders.CustomerID ORDER BY ' + CASE @SortOrder WHEN N'OrderDate' THEN N'SalesOrders.OrderDate' WHEN N'SalesOrderID' THEN N'SalesOrders.SalesOrderID' END + N' ASC; '; EXECUTE sys.sp_executesql @stmt = @Command , @params = N'@pCustomerID AS INT' , @pCustomerID = @CustomerID; GO
Lưu ý rằng tôi vẫn sử dụng thông số nội bộ cho ID khách hàng và tôi thực thi mã động bằng sys.sp_executesql để truyền giá trị tham số. Điều này quan trọng vì hai lý do. Đầu tiên, để tránh nhiều tập hợp có cùng cấu trúc truy vấn cho các giá trị khác nhau của @CustomerID. Thứ hai, để tránh chèn SQL.
Nếu bạn cố gắng thực thi thủ tục được lưu trữ ngay bây giờ bằng cách sử dụng các giá trị tham số khác nhau, bạn sẽ thấy rằng mỗi hành vi truy vấn hoặc cấu trúc truy vấn sẽ nhận được kế hoạch thực thi tốt nhất và mỗi một trong 4 kế hoạch chỉ được biên dịch một lần.
Ví dụ, sau đây là kế hoạch cho hành vi thứ ba:
EXECUTE Sales.GetOrders @SortOrder = N'SalesOrderID'; GO
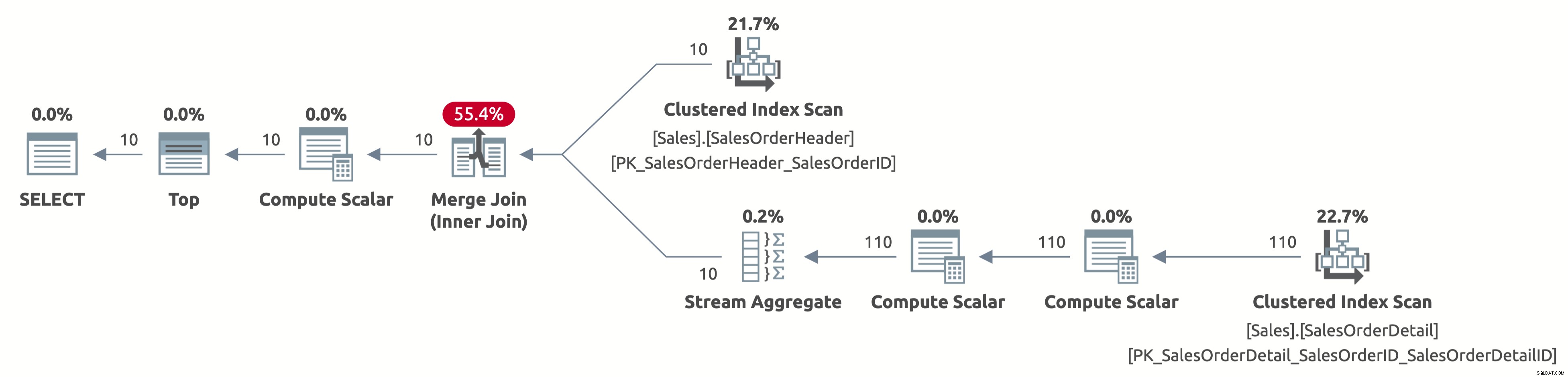
Bây giờ, chúng tôi chỉ quét 10 hàng đầu tiên từ bảng Sales.SalesOrderHeader và chúng tôi cũng chỉ quét 110 hàng đầu tiên từ bảng Sales.SalesOrderDetail. Ngoài ra, không có toán tử Sắp xếp vì dữ liệu đã được sắp xếp theo SalesOrderID.
Đây là kết quả của thống kê IO:
- Bảng 'SalesOrderDetail'. Quét đếm 1, đọc logic 4
- Bảng 'SalesOrderHeader'. Quét đếm 1, đọc logic 3
Kết luận
Khi bạn sử dụng các tham số để thay đổi cấu trúc truy vấn của mình, không sử dụng các biểu thức phức tạp trong truy vấn để dẫn xuất hành vi mong đợi. Trong hầu hết các trường hợp, điều này sẽ dẫn đến hiệu suất kém và vì những lý do chính đáng. Lý do đầu tiên là kế hoạch sẽ được tạo dựa trên lần thực thi đầu tiên và sau đó tất cả các lần thực thi tiếp theo sẽ sử dụng lại cùng một kế hoạch, chỉ phù hợp với một cấu trúc truy vấn. Lý do thứ hai là trình tối ưu hóa bị hạn chế về khả năng đánh giá các biểu thức phức tạp đó tại thời điểm biên dịch.
Có một số cách để khắc phục những vấn đề này, và chúng tôi đã xem xét chúng trong bài viết này. Trong hầu hết các trường hợp, phương pháp tốt nhất sẽ là tạo truy vấn động dựa trên các giá trị tham số. Bằng cách đó, mỗi cấu trúc truy vấn sẽ được biên dịch một lần với kế hoạch tốt nhất có thể.
Khi bạn tạo truy vấn bằng SQL động, hãy đảm bảo sử dụng các tham số nếu thích hợp và xác minh rằng mã của bạn an toàn.