[Phần 1 | Phần 2 | Phần 3]
Gần đây, một người nào đó tại nơi làm việc đã yêu cầu có thêm không gian để kê một chiếc bàn đang phát triển nhanh chóng. Vào thời điểm đó, nó có 3,75 tỷ hàng, được trình bày trên 143 triệu trang và chiếm ~ 1,14TB. Tất nhiên chúng ta luôn có thể ném nhiều đĩa hơn vào bàn, nhưng tôi muốn xem liệu chúng ta có thể mở rộng quy mô này hiệu quả hơn xu hướng tuyến tính hiện tại hay không. Nghe có vẻ như một công việc tuyệt vời để nén, phải không? Nhưng tôi cũng muốn thử một số giải pháp khác, bao gồm cả columnstore - điều mà mọi người rất miễn cưỡng khi thử. Tôi không phải là Niko, nhưng tôi muốn cố gắng xem nó có thể làm gì cho chúng tôi ở đây.
Lưu ý rằng tôi không tập trung vào việc báo cáo khối lượng công việc hoặc hiệu suất truy vấn đọc khác tại thời điểm này - tôi chỉ muốn xem tác động của tôi có thể có đối với dung lượng lưu trữ (và bộ nhớ) của dữ liệu này.
Đây là bảng gốc. Tôi đã thay đổi tên bảng và cột để bảo vệ người vô tội, nhưng mọi thứ khác tương đối chính xác.
CREATE TABLE dbo.tblOriginal
(
OID bigint IDENTITY(1,1) NOT NULL PRIMARY KEY, -- there are gaps!
IN1 int NOT NULL,
IN2 int NOT NULL,
VC1 varchar(3) NULL,
BI1 bigint NULL,
IN3 int NULL,
VC2 varchar(128) NOT NULL,
VC3 varchar(128) NOT NULL,
VC4 varchar(128) NULL,
NM1 numeric(24,12) NULL,
NM2 numeric(24,12) NULL,
NM3 numeric(24,12) NULL,
BI2 bigint NULL,
IN4 int NULL,
BI3 bigint NULL,
NM4 numeric(24,12) NULL,
IN5 int NULL,
NM5 numeric(24,12) NULL,
DT1 date NULL,
VC5 varchar(128) NULL,
BI4 bigint NULL,
BI5 bigint NULL,
BI6 bigint NULL,
BT1 bit NOT NULL,
NV1 nvarchar(512) NULL,
VB1 AS (HASHBYTES('MD5',VC2+VC3)),
IN6 int NULL,
IN7 int NULL,
IN8 int NULL
);
Có một số thứ nhỏ khác trong đó rộng hơn mức cần thiết và / hoặc việc nén hàng có thể bị xóa, như numeric(24,12) đó và bigint các cột có thể quá khổ sớm, nhưng tôi sẽ không quay lại nhóm ứng dụng và tìm hiểu xem có ít hiệu quả ở đó hay không và tôi sẽ bỏ qua việc nén hàng cho bài tập này và tập trung vào nén trang và cột.
Đây là một bản sao của dữ liệu, trên một máy chủ không hoạt động (8 lõi, RAM 64GB), với nhiều dung lượng đĩa (hơn 6TB). Vì vậy, trước tiên, hãy thêm một vài nhóm tệp, một nhóm dành cho kho cột tiêu chuẩn được phân nhóm và một cho phiên bản được phân vùng của bảng (nơi tất cả trừ phân vùng mới nhất sẽ được nén bằng COLUMNSTORE_ARCHIVE , vì tất cả dữ liệu cũ hơn đó hiện là "chỉ đọc và không thường xuyên"):
ALTER DATABASE OCopy ADD FILEGROUP FG_CCI; ALTER DATABASE OCopy ADD FILEGROUP FG_CCI_PARTITIONED;
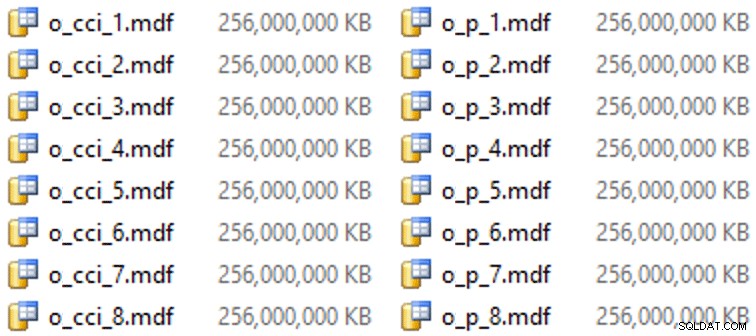
Và sau đó là một số tệp cho các nhóm tệp này (một tệp cho mỗi lõi, đẹp và có kích thước đồng nhất ở 256GB):
ALTER DATABASE OCopy ADD FILE (name = N'CCI_1', size = 250000, filename = 'K:\Data\o_cci_1.mdf') TO FILEGROUP FG_CCI; -- ... 6 more ... ALTER DATABASE OCopy ADD FILE (name = N'CCI_8', size = 250000, filename = 'K:\Data\o_cci_8.mdf') TO FILEGROUP FG_CCI; ALTER DATABASE OCopy ADD FILE (name = N'CCI_P_1', size = 250000, filename = 'K:\Data\o_p_1.mdf') TO FILEGROUP FG_CCI_PARTITIONED; -- ... 6 more ... ALTER DATABASE OCopy ADD FILE (name = N'CCI_P_8', size = 250000, filename = 'K:\Data\o_p_8.mdf') TO FILEGROUP FG_CCI_PARTITIONED;
Trên phần cứng cụ thể này (YMMV!), Quá trình này mất khoảng 10 giây cho mỗi tệp và mang lại kết quả như sau:
Để tạo các phân vùng, tôi đã ngây thơ chia dữ liệu lên "đồng đều" - hoặc tôi nghĩ vậy. Tôi chỉ lấy 3,75 tỷ hàng và phân vùng thành một thứ mà tôi nghĩ có thể quản lý được:38 phân vùng với 100 triệu hàng trong 37 phân vùng đầu tiên và phần còn lại trong phân vùng cuối cùng. (Hãy nhớ rằng đây chỉ là phần 1! Có một giả định cố hữu ở đây về việc phân phối đồng đều các giá trị trong bảng nguồn và xung quanh điều gì là tối ưu cho tập hợp nhóm hàng trong bảng đích.) Tạo lược đồ phân vùng và hàm cho điều này là sau:
CREATE PARTITION FUNCTION PF_OID([bigint]) AS RANGE LEFT FOR VALUES (100000000, 200000000, /* ... 33 more ... */ , 3600000000, 3700000000); CREATE PARTITION SCHEME PS_OID AS PARTITION PF_OID ALL TO (FG_CCI_PARTITIONED);
Tôi sử dụng RANGE LEFT bởi vì, như Cathrine Wilhelmsen tiếp tục giúp tôi nhắc nhở tôi, điều này có nghĩa là giá trị ranh giới là một phần của phân vùng bên trái của nó. Nói cách khác, các giá trị tôi đang chỉ định là giá trị tối đa trong mỗi phân vùng (với ngày tháng, bạn thường muốn RANGE RIGHT ).
Sau đó, tôi tạo hai bản sao của bảng, một bản trên mỗi nhóm tệp. Cái đầu tiên có chỉ mục cột lưu trữ theo nhóm tiêu chuẩn, điểm khác biệt duy nhất là OID cột không phải là IDENTITY và cột được tính chỉ là một varbinary(8000) :
CREATE TABLE dbo.tblCCI ( OID bigint NOT NULL, -- ... other columns ... ) ON FG_CCI; GO CREATE CLUSTERED COLUMNSTORE INDEX CCI_IX ON dbo.tblCCI;
Cái thứ hai được xây dựng trên lược đồ phân vùng, vì vậy cần một PK được đặt tên trước, sau đó phải được thay thế bằng một chỉ mục columnstore được phân cụm (mặc dù Brent Ozar cho thấy trong bài đăng ngắn gọn này rằng có một số cú pháp không trực quan sẽ thực hiện điều này trong ít bước hơn ):
CREATE TABLE dbo.tblCCI_Partitioned ( OID bigint NOT NULL, -- ... other columns ..., CONSTRAINT PK_CCI_Part PRIMARY KEY CLUSTERED (OID) ON PS_OID (OID) ); GO ALTER TABLE dbo.tblCCI_Partitioned DROP CONSTRAINT PK_CCI_Part; GO CREATE CLUSTERED COLUMNSTORE INDEX CCI_Part ON dbo.tblCCI_Partitioned ON PS_OID (OID);
Sau đó, để đặt nén lưu trữ trên tất cả trừ phân vùng cuối cùng, tôi đã chạy như sau:
ALTER TABLE dbo.tblCCI_Part
REBUILD PARTITION = ALL WITH
(
DATA_COMPRESSION = COLUMNSTORE ON PARTITIONS (38),
DATA_COMPRESSION = COLUMNSTORE_ARCHIVE ON PARTITIONS (1 TO 37)
); Bây giờ, tôi đã sẵn sàng điền dữ liệu vào các bảng này, đo thời gian thực hiện và kích thước kết quả, rồi so sánh. Tôi đã sửa đổi một tập lệnh theo lô hữu ích từ Andy Mallon và chèn tuần tự các hàng vào cả hai bảng, với kích thước lô là 10 triệu hàng. Còn nhiều thứ hơn thế này trong tập lệnh thực (bao gồm cập nhật bảng hàng đợi với tiến trình), nhưng về cơ bản:
DECLARE @BatchSize int = 10000000, @MaxID bigint, @LastID bigint = 0;
SELECT @MaxID = MAX(OID) FROM dbo.tblOriginal;
WHILE @LastID < @MaxID
BEGIN
INSERT dbo.tblCCI
(
-- all columns except the computed column
)
SELECT -- all columns except the computed column
FROM dbo.tblOriginal AS o
WHERE o.CostID >= @LastID
AND o.CostID < @LastID + @BatchSize;
SET @LastID += @BatchSize;
END Sau khi tôi điền cả hai bảng cột lưu trữ từ nguồn ban đầu (không nén), tôi đã xây dựng lại các phân vùng đó một lần nữa để dọn dẹp mọi nhóm hàng và từ điển lộn xộn. Cuối cùng, tôi đã áp dụng tính năng nén trang, tại chỗ, cho bảng nguồn. Dưới đây là thời gian và kết quả nén của từng loại:
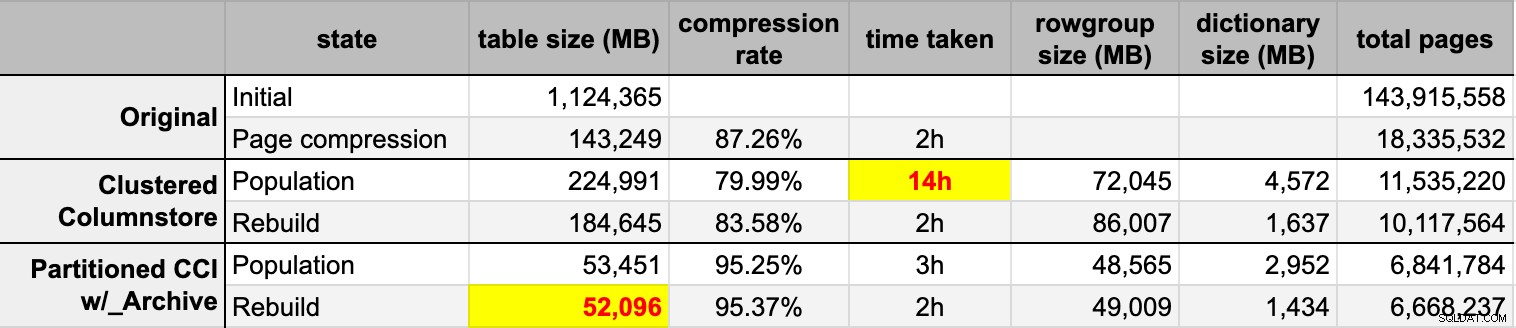
Tôi vừa ấn tượng vừa thất vọng. Ấn tượng vì dữ liệu này nén thực sự tốt - thu nhỏ dung lượng lưu trữ xuống 5% so với 1TB ban đầu là một điều tuyệt vời. Thất vọng vì:
- Tôi đã tạo các tệp dữ liệu đó theo cách quá lớn.
- Tôi không hiểu chuyện gì đã xảy ra với quá trình nén columnstore ban đầu trong 14 giờ:
- Tôi không quan sát thấy bất kỳ áp lực bộ nhớ hoặc nhật ký nào.
- Không có sự kiện tăng trưởng tệp nào.
- Thật không may, tôi không nghĩ đến việc theo dõi các lượt chờ. Không, tôi sẽ không thử lại. :-)
- Nén trang hoạt động tốt hơn so với nén columnstore thông thường - có lẽ do dữ liệu.
- Xây dựng lại các phân vùng lưu trữ cột đã sử dụng rất nhiều thời gian của CPU mà gần như bằng không.
Trong các bài đăng sắp tới và sau khi xem lại các ghi chú của tôi từ bài thuyết trình trên cột tuyệt vời của Joe Obbish tại Hội nghị thượng đỉnh PASS (mà tôi muốn liên kết trực tiếp, nếu chỉ PASS biết cách giao diện người dùng), tôi sẽ nói một chút về những thay đổi mà tôi sẽ thực hiện cấu hình máy chủ và tập lệnh tổng thể của tôi để xem liệu tôi có thể nhận được hiệu suất tốt hơn từ tập hợp cửa hàng cột.
[Phần 1 | Phần 2 | Phần 3]