Một vấn đề về hiệu suất mà tôi thường gặp là khi người dùng cần đối sánh một phần của chuỗi với một truy vấn như sau:
... WHERE SomeColumn LIKE N'%SomePortion%';
Với ký tự đại diện đứng đầu, vị từ này là "không phải SARGable" - chỉ là một cách nói hoa mỹ rằng chúng tôi không thể tìm thấy các hàng có liên quan bằng cách sử dụng tìm kiếm đối với chỉ mục trên SomeColumn .
Một giải pháp mà chúng tôi nhận được khá rắc rối là tìm kiếm toàn văn bản; tuy nhiên, đây là một giải pháp phức tạp và nó yêu cầu mẫu tìm kiếm bao gồm các từ đầy đủ, không sử dụng các từ dừng, v.v. Điều này có thể hữu ích nếu chúng tôi đang tìm kiếm các hàng trong đó mô tả chứa từ "mềm" (hoặc các dẫn xuất khác như "mềm hơn" hoặc "mềm"), nhưng nó không hữu ích khi chúng tôi đang tìm kiếm các chuỗi có thể chứa trong các từ (hoặc hoàn toàn không phải là từ, như tất cả các SKU sản phẩm có chứa "X45-B" hoặc tất cả các biển số xe có chứa chuỗi "7RA").
Điều gì sẽ xảy ra nếu SQL Server bằng cách nào đó biết về tất cả các phần có thể có của một chuỗi? Quá trình suy nghĩ của tôi là dọc theo dòng của trigram / trigraph trong PostgreSQL. Khái niệm cơ bản là công cụ có khả năng thực hiện tra cứu kiểu điểm trên các chuỗi con, nghĩa là bạn không phải quét toàn bộ bảng và phân tích cú pháp mọi giá trị đầy đủ.
Ví dụ cụ thể mà họ sử dụng ở đó là từ cat . Ngoài từ đầy đủ, nó có thể được chia thành các phần:c , ca và at (họ bỏ đi a và t theo định nghĩa - không có chuỗi con nào ở cuối có thể ngắn hơn hai ký tự). Trong SQL Server, chúng ta không cần nó phải phức tạp như vậy; chúng ta chỉ thực sự cần một nửa bát quái - nếu chúng ta nghĩ về việc xây dựng cấu trúc dữ liệu chứa tất cả các chuỗi con của cat , chúng tôi chỉ cần những giá trị sau:
- mèo
- tại
- t
Chúng tôi không cần c hoặc ca , bởi vì bất kỳ ai đang tìm kiếm LIKE '%ca%' có thể dễ dàng tìm thấy giá trị 1 bằng cách sử dụng LIKE 'ca%' thay thế. Tương tự, bất kỳ ai tìm kiếm LIKE '%at%' hoặc LIKE '%a%' chỉ có thể sử dụng một ký tự đại diện ở cuối đối với ba giá trị này và tìm một giá trị phù hợp (ví dụ:LIKE 'at%' sẽ tìm thấy giá trị 2 và LIKE 'a%' cũng sẽ tìm thấy giá trị 2, mà không cần phải tìm các chuỗi con đó bên trong giá trị 1, đó là nơi mà nỗi đau thực sự sẽ đến).
Vì vậy, do SQL Server không có bất kỳ thứ gì như thế này được tích hợp sẵn, làm cách nào để chúng tôi tạo ra một bát quái như vậy?
Bảng phân đoạn riêng biệt
Tôi sẽ dừng tham chiếu "trigram" ở đây vì nó không thực sự tương tự với tính năng đó trong PostgreSQL. Về cơ bản, những gì chúng ta sẽ làm là xây dựng một bảng riêng biệt với tất cả các "mảnh" của chuỗi ban đầu. (Vì vậy, trong cat ví dụ, sẽ có một bảng mới với ba hàng đó và LIKE '%pattern%' các tìm kiếm sẽ được chuyển hướng đến bảng mới đó dưới dạng LIKE 'pattern%' vị ngữ.)
Trước khi tôi bắt đầu cho biết giải pháp được đề xuất của tôi sẽ hoạt động như thế nào, hãy nói rõ rằng giải pháp này không nên được sử dụng trong mọi trường hợp LIKE '%wildcard%' tìm kiếm chậm. Do cách chúng ta sẽ "phát nổ" dữ liệu nguồn thành các đoạn, nên tính thực tế có thể bị hạn chế đối với các chuỗi nhỏ hơn, chẳng hạn như địa chỉ hoặc tên, trái ngược với các chuỗi lớn hơn, như mô tả sản phẩm hoặc tóm tắt phiên.
Một ví dụ thực tế hơn cat là xem Sales.Customer trong cơ sở dữ liệu mẫu WideWorldImporters. Nó có các dòng địa chỉ (cả nvarchar(60) ), với thông tin địa chỉ có giá trị trong cột DeliveryAddressLine2 (không rõ lý do). Ai đó có thể đang tìm kiếm bất kỳ ai sống trên đường có tên Hudecova , vì vậy họ sẽ chạy một tìm kiếm như sau:
SELECT CustomerID, DeliveryAddressLine2
FROM Sales.Customers
WHERE DeliveryAddressLine2 LIKE N'%Hudecova%';
/* This returns two rows:
CustomerID DeliveryAddressLine2
---------- ----------------------
61 1695 Hudecova Avenue
181 1846 Hudecova Crescent
*/ Như bạn mong đợi, SQL Server cần thực hiện quét để định vị hai hàng đó. Mà phải đơn giản; tuy nhiên, do sự phức tạp của bảng, truy vấn tầm thường này tạo ra một kế hoạch thực thi rất lộn xộn (quá trình quét được đánh dấu và có cảnh báo về I / O còn lại):
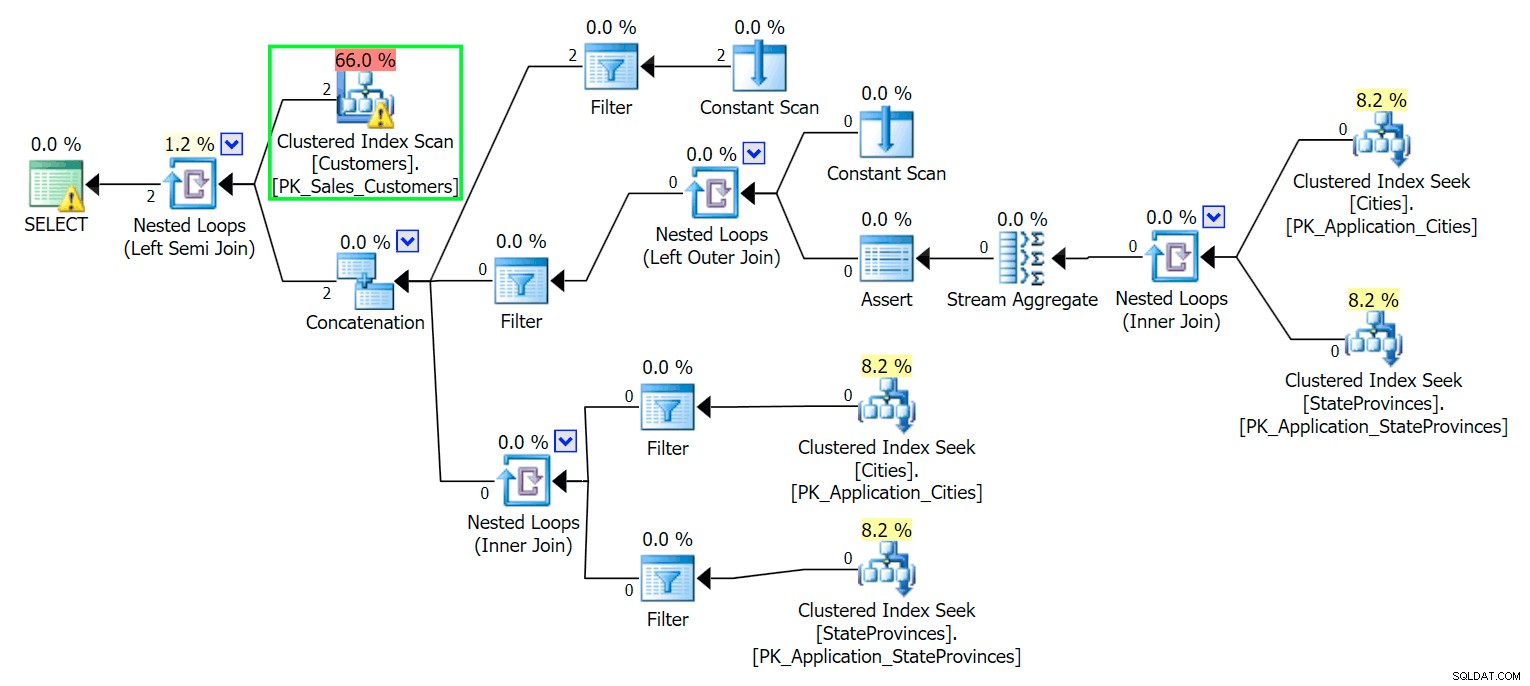
Blecch. Để giữ cho cuộc sống của chúng ta trở nên đơn giản và để đảm bảo rằng chúng ta không đuổi theo một loạt các dây màu đỏ, hãy tạo một bảng mới với một tập hợp con của các cột và để bắt đầu, chúng ta sẽ chỉ chèn hai hàng giống nhau từ phía trên:
CREATE TABLE Sales.CustomersCopy ( CustomerID int IDENTITY(1,1) CONSTRAINT PK_CustomersCopy PRIMARY KEY, CustomerName nvarchar(100) NOT NULL, DeliveryAddressLine1 nvarchar(60) NOT NULL, DeliveryAddressLine2 nvarchar(60) ); GO INSERT Sales.CustomersCopy ( CustomerName, DeliveryAddressLine1, DeliveryAddressLine2 ) SELECT CustomerName, DeliveryAddressLine1, DeliveryAddressLine2 FROM Sales.Customers WHERE DeliveryAddressLine2 LIKE N'%Hudecova%';
Bây giờ, nếu chúng ta chạy cùng một truy vấn mà chúng ta đã chạy với bảng chính, chúng ta sẽ nhận được một thứ hợp lý hơn rất nhiều để xem xét như một điểm bắt đầu. Đây vẫn sẽ là quá trình quét cho dù chúng tôi làm gì - nếu chúng tôi thêm chỉ mục với DeliveryAddressLine2 là cột quan trọng hàng đầu, rất có thể chúng tôi sẽ quét chỉ mục, với việc tra cứu khóa tùy thuộc vào việc chỉ mục có bao gồm các cột trong truy vấn hay không. Như vậy, chúng tôi nhận được một bản quét chỉ mục theo nhóm:
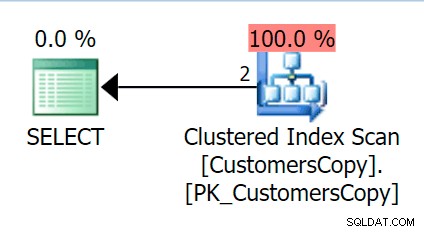
Tiếp theo, hãy tạo một hàm có chức năng "phát nổ" các giá trị địa chỉ này thành các đoạn. Chúng tôi mong đợi 1846 Hudecova Crescent , ví dụ, để có tập hợp các đoạn sau:
- 1846 Hudecova Crescent
- 846 Hudecova Crescent
- 46 Hudecova Crescent
- 6 Hudecova Crescent
- Hudecova Crescent
- Hudecova Crescent
- udecova Crescent
- decova Crescent
- ecova Crescent
- Cova Crescent
- Lưỡi liềm bầu dục
- va Crescent
- một lưỡi liềm
- Lưỡi liềm
- Lưỡi liềm
- hồi tưởng
- escent
- mùi hương
- xu
- ent
- nt
- t
Việc viết một hàm tạo ra đầu ra này là khá đơn giản - chúng ta chỉ cần một CTE đệ quy có thể được sử dụng để xem từng ký tự trong suốt độ dài của đầu vào:
CREATE FUNCTION dbo.CreateStringFragments( @input nvarchar(60) )
RETURNS TABLE WITH SCHEMABINDING
AS
RETURN
(
WITH x(x) AS
(
SELECT 1 UNION ALL SELECT x+1 FROM x WHERE x < (LEN(@input))
)
SELECT Fragment = SUBSTRING(@input, x, LEN(@input)) FROM x
);
GO
SELECT Fragment FROM dbo.CreateStringFragments(N'1846 Hudecova Crescent');
-- same output as above bulleted list Bây giờ, hãy tạo một bảng sẽ lưu trữ tất cả các đoạn địa chỉ và khách hàng mà chúng thuộc về:
CREATE TABLE Sales.CustomerAddressFragments ( CustomerID int NOT NULL, Fragment nvarchar(60) NOT NULL, CONSTRAINT FK_Customers FOREIGN KEY(CustomerID) REFERENCES Sales.CustomersCopy(CustomerID) ); CREATE CLUSTERED INDEX s_cat ON Sales.CustomerAddressFragments(Fragment, CustomerID);
Sau đó, chúng tôi có thể điền nó như thế này:
INSERT Sales.CustomerAddressFragments(CustomerID, Fragment) SELECT c.CustomerID, f.Fragment FROM Sales.CustomersCopy AS c CROSS APPLY dbo.CreateStringFragments(c.DeliveryAddressLine2) AS f;
Đối với hai giá trị của chúng tôi, giá trị này sẽ chèn 42 hàng (một địa chỉ có 20 ký tự và địa chỉ còn lại có 22). Bây giờ truy vấn của chúng tôi trở thành:
SELECT c.CustomerID, c.DeliveryAddressLine2
FROM Sales.CustomersCopy AS c
INNER JOIN Sales.CustomerAddressFragments AS f
ON f.CustomerID = c.CustomerID
AND f.Fragment LIKE N'Hudecova%'; Đây là một kế hoạch đẹp hơn nhiều - hai chỉ mục được phân nhóm * tìm kiếm * và tham gia các vòng lặp lồng nhau:
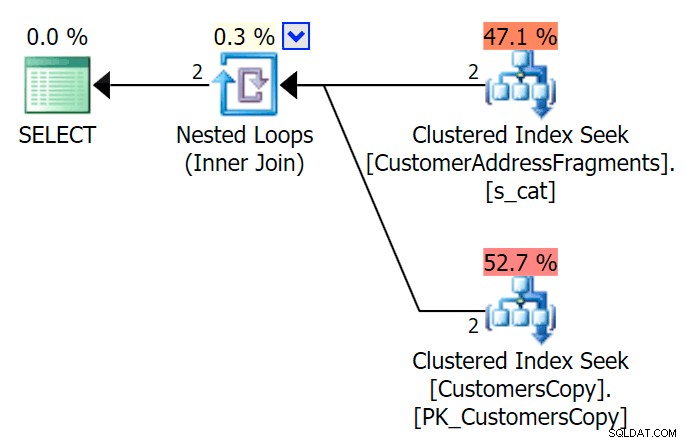
Chúng tôi cũng có thể thực hiện việc này theo cách khác, sử dụng EXISTS :
SELECT c.CustomerID, c.DeliveryAddressLine2
FROM Sales.CustomersCopy AS c
WHERE EXISTS
(
SELECT 1 FROM Sales.CustomerAddressFragments
WHERE CustomerID = c.CustomerID
AND Fragment LIKE N'Hudecova%'
); Đây là kế hoạch đó, nhìn bề ngoài có vẻ đắt hơn - nó chọn quét bảng Khách hàng sao chép. Chúng ta sẽ sớm biết lý do tại sao đây là cách tiếp cận truy vấn tốt hơn:
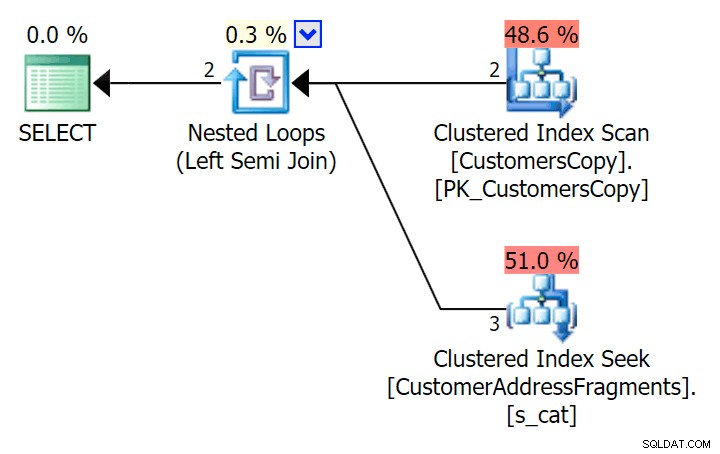
Bây giờ, trên tập dữ liệu khổng lồ gồm 42 hàng này, sự khác biệt về thời lượng và I / O là rất nhỏ nên chúng không liên quan (và trên thực tế, ở kích thước nhỏ này, việc quét so với bảng cơ sở trông rẻ hơn về I / O hơn hai kế hoạch khác sử dụng bảng phân mảnh):

Điều gì sẽ xảy ra nếu chúng ta điền vào các bảng này với nhiều dữ liệu hơn? Bản sao của tôi về Sales.Customers có 663 hàng, vì vậy nếu chúng ta kết hợp chéo với chính nó, chúng ta sẽ đến đâu đó gần 440.000 hàng. Vì vậy, chúng ta chỉ cần trộn 400K và tạo một bảng lớn hơn nhiều:
TRUNCATE TABLE Sales.CustomerAddressFragments; DELETE Sales.CustomersCopy; DBCC FREEPROCCACHE WITH NO_INFOMSGS; INSERT Sales.CustomersCopy WITH (TABLOCKX) (CustomerName, DeliveryAddressLine1, DeliveryAddressLine2) SELECT TOP (400000) c1.CustomerName, c1.DeliveryAddressLine1, c2.DeliveryAddressLine2 FROM Sales.Customers c1 CROSS JOIN Sales.Customers c2 ORDER BY NEWID(); -- fun for distribution -- this will take a bit longer - on my system, ~4 minutes -- probably because I didn't bother to pre-expand files INSERT Sales.CustomerAddressFragments WITH (TABLOCKX) (CustomerID, Fragment) SELECT c.CustomerID, f.Fragment FROM Sales.CustomersCopy AS c CROSS APPLY dbo.CreateStringFragments(c.DeliveryAddressLine2) AS f; -- repeated for compressed version of the table -- 7.25 million rows, 278MB (79MB compressed; saving those tests for another day)
Bây giờ để so sánh hiệu suất và kế hoạch thực thi với nhiều tham số tìm kiếm có thể có, tôi đã thử nghiệm ba truy vấn trên với các vị từ sau:
| Truy vấn | Dự đoán | ||||
|---|---|---|---|---|---|
| DeliveryLineAddress2 THÍCH Ở ĐÂU… | N '% Hudecova%' | N '% cova%' | N '% ova%' | N '% va%' | |
| THAM GIA… Mảnh lưới NHƯ ĐÂU… | N'Hudecova% ' | N'cova% ' | N'ova% ' | N'va% ' | |
| Ở ĐÂU TỒN TẠI (… ĐÂU Mảnh giống như…) | |||||
Khi chúng tôi xóa các chữ cái khỏi mẫu tìm kiếm, tôi sẽ thấy nhiều hàng hơn xuất ra và có thể là các chiến lược khác nhau do trình tối ưu hóa chọn. Hãy xem nó diễn ra như thế nào đối với từng mẫu:
Hudecova%
Đối với mẫu này, quá trình quét vẫn giống nhau đối với điều kiện LIKE; tuy nhiên, với nhiều dữ liệu hơn, chi phí sẽ cao hơn nhiều. Các tìm kiếm trong bảng phân mảnh thực sự mang lại hiệu quả ở số hàng này (1.206), ngay cả với ước tính thực sự thấp. Kế hoạch EXISTS thêm một loại khác biệt, mà bạn sẽ thêm vào chi phí, mặc dù trong trường hợp này, nó sẽ thực hiện ít lần đọc hơn:

 Lập kế hoạch cho JOIN vào bảng các mảnh
Lập kế hoạch cho JOIN vào bảng các mảnh 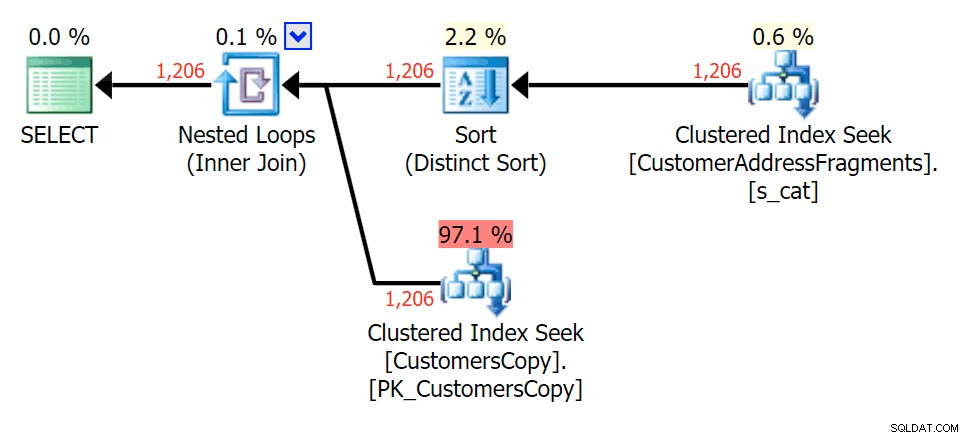 Lập kế hoạch cho bảng TỒN TẠI so với bảng phân mảnh
Lập kế hoạch cho bảng TỒN TẠI so với bảng phân mảnh cova%
Khi chúng tôi loại bỏ một số chữ cái khỏi vị ngữ của mình, chúng tôi thấy số lần đọc thực sự cao hơn một chút so với quét chỉ mục theo nhóm ban đầu và bây giờ chúng tôi kết thúc -châu hỏi các hàng. Ngay cả khi vẫn còn, thời lượng của chúng tôi vẫn thấp hơn đáng kể với cả hai truy vấn phân mảnh; sự khác biệt lần này tinh tế hơn - cả hai đều có các loại (chỉ EXISTS là khác biệt):

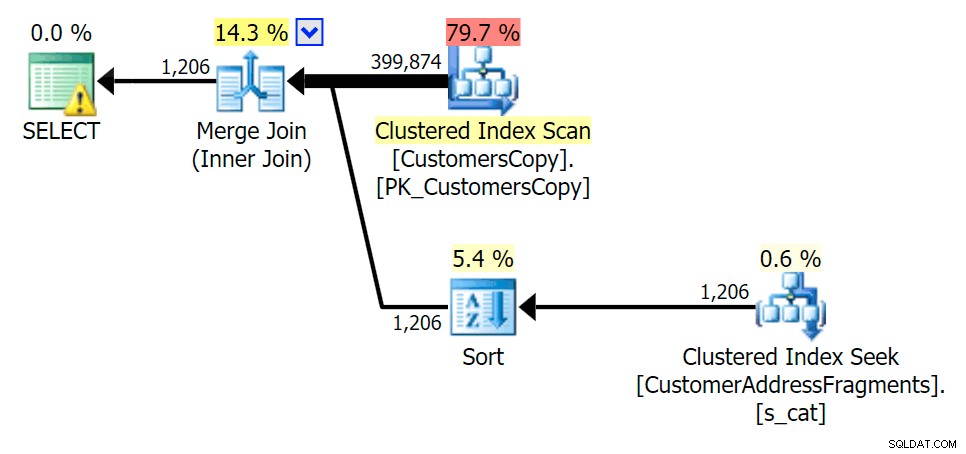 Lập kế hoạch cho phép JOIN vào bảng các mảnh
Lập kế hoạch cho phép JOIN vào bảng các mảnh 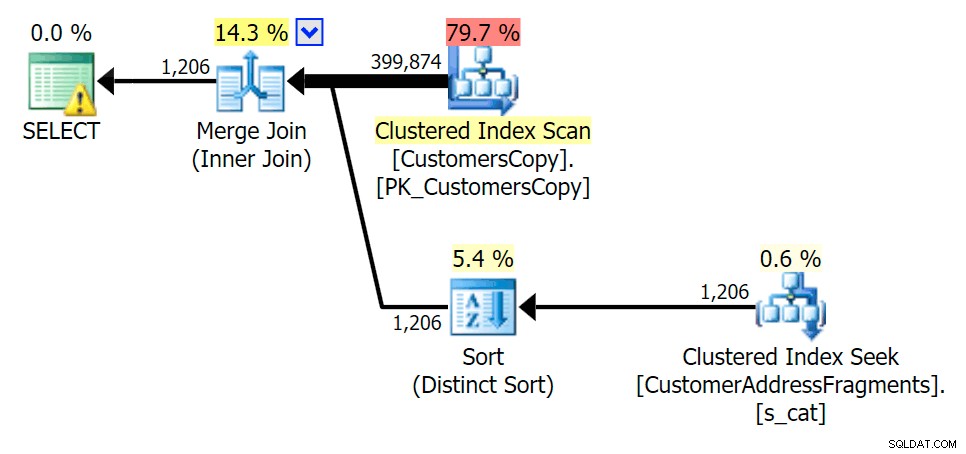 Lập kế hoạch cho bảng TỒN TẠI trên bảng phân mảnh
Lập kế hoạch cho bảng TỒN TẠI trên bảng phân mảnh ova%
Việc tước bỏ một chữ cái bổ sung không thay đổi nhiều; mặc dù điều đáng chú ý là các hàng ước tính và thực tế nhảy ở đây bao nhiêu - nghĩa là đây có thể là một mẫu chuỗi con chung. Truy vấn LIKE ban đầu vẫn chậm hơn một chút so với truy vấn phân đoạn.

 Lập kế hoạch cho JOIN vào bảng các mảnh
Lập kế hoạch cho JOIN vào bảng các mảnh 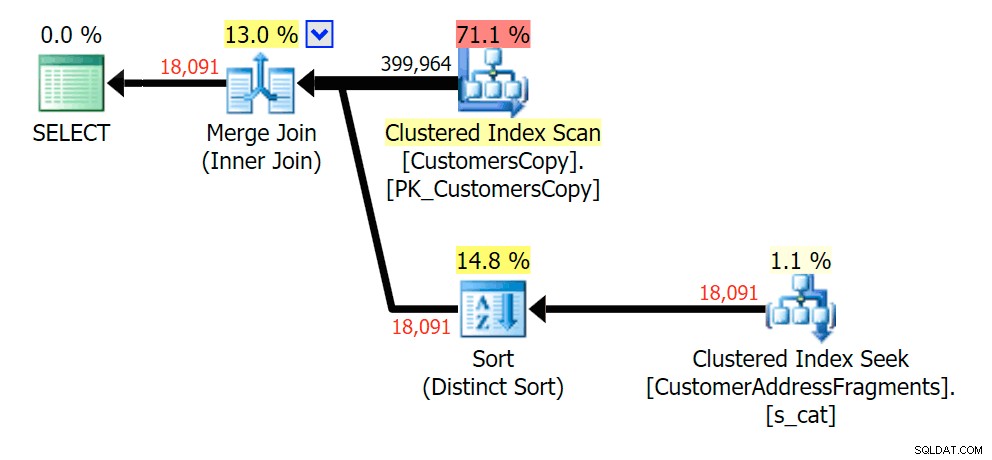 Lập kế hoạch cho bảng TỒN TẠI trên bảng phân mảnh
Lập kế hoạch cho bảng TỒN TẠI trên bảng phân mảnh va%
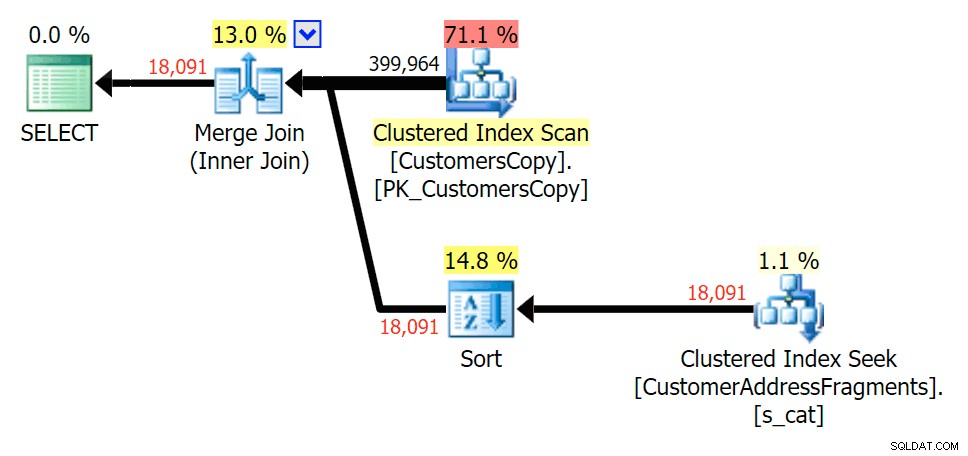
Xuống hai chữ cái, điều này giới thiệu sự khác biệt đầu tiên của chúng tôi. Lưu ý rằng JOIN tạo ra nhiều hơn nữa hàng hơn truy vấn ban đầu hoặc TỒN TẠI. Tại sao lại như vậy?

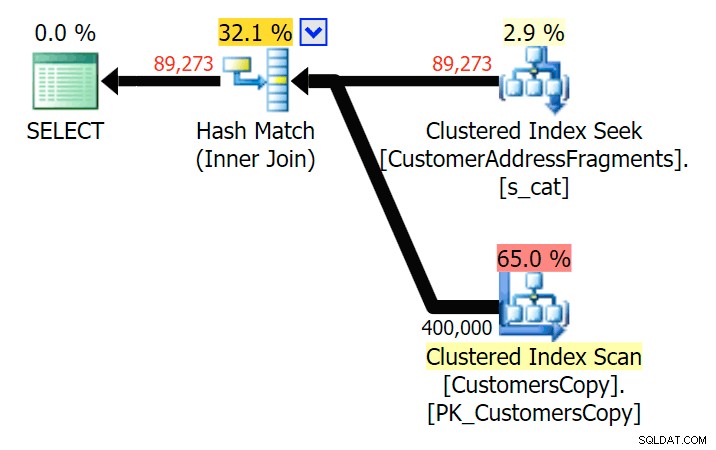 Lập kế hoạch cho JOIN vào bảng các mảnh
Lập kế hoạch cho JOIN vào bảng các mảnh 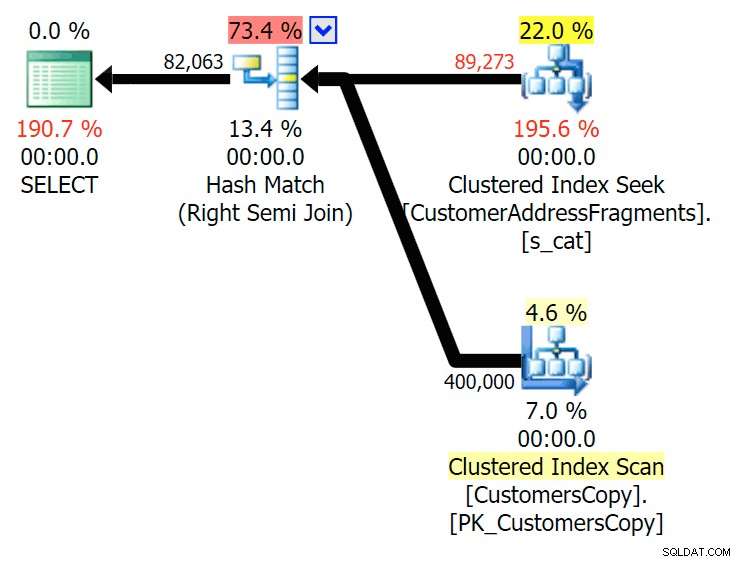 Lập kế hoạch cho bảng TỒN TẠI trên bảng phân mảnh Chúng ta không cần phải tìm đâu xa. Hãy nhớ rằng có một đoạn bắt đầu từ mỗi ký tự kế tiếp trong địa chỉ gốc, có nghĩa là
Lập kế hoạch cho bảng TỒN TẠI trên bảng phân mảnh Chúng ta không cần phải tìm đâu xa. Hãy nhớ rằng có một đoạn bắt đầu từ mỗi ký tự kế tiếp trong địa chỉ gốc, có nghĩa là 899 Valentova Road sẽ có hai hàng trong bảng phân mảnh bắt đầu bằng va (sang một bên phân biệt chữ hoa chữ thường). Vì vậy, bạn sẽ khớp trên cả Fragment = N'Valentova Road' và Fragment = N'va Road' . Tôi sẽ giúp bạn tiết kiệm việc tìm kiếm và cung cấp một ví dụ về nhiều thứ: SELECT TOP (2) c.CustomerID, c.DeliveryAddressLine2, f.Fragment FROM Sales.CustomersCopy AS c INNER JOIN Sales.CustomerAddressFragments AS f ON c.CustomerID = f.CustomerID WHERE f.Fragment LIKE N'va%' AND c.DeliveryAddressLine2 = N'899 Valentova Road' AND f.CustomerID = 351; /* CustomerID DeliveryAddressLine2 Fragment ---------- -------------------- -------------- 351 899 Valentova Road va Road 351 899 Valentova Road Valentova Road */
Điều này dễ dàng giải thích tại sao JOIN tạo ra nhiều hàng hơn; nếu bạn muốn khớp với đầu ra của truy vấn LIKE ban đầu, bạn nên sử dụng EXISTS. Thực tế là kết quả chính xác thường cũng có thể đạt được theo cách ít tốn kém tài nguyên hơn chỉ là một phần thưởng. (Tôi rất lo lắng khi thấy mọi người chọn THAM GIA nếu đó là tùy chọn hiệu quả hơn nhiều lần - bạn nên luôn ưu tiên kết quả chính xác hơn là lo lắng về hiệu suất.)
Tóm tắt
Rõ ràng là trong trường hợp cụ thể này - với cột địa chỉ là nvarchar(60) và độ dài tối đa là 26 ký tự - việc chia nhỏ từng địa chỉ thành các đoạn có thể mang lại một số giải pháp cho các tìm kiếm "ký tự đại diện hàng đầu" đắt tiền. Phần thưởng tốt hơn dường như xảy ra khi mẫu tìm kiếm lớn hơn và kết quả là độc đáo hơn. Tôi cũng đã chứng minh lý do tại sao EXISTS tốt hơn trong các trường hợp có thể có nhiều kết quả khớp - với một JOIN, bạn sẽ nhận được đầu ra dư thừa trừ khi bạn thêm một số logic "n lớn nhất cho mỗi nhóm".
Lưu ý
Tôi sẽ là người đầu tiên thừa nhận rằng giải pháp này là không hoàn hảo, không đầy đủ và không được hoàn thiện một cách triệt để:
- Bạn sẽ cần giữ bảng phân đoạn được đồng bộ hóa với bảng cơ sở bằng cách sử dụng trình kích hoạt - đơn giản nhất là chèn và cập nhật, xóa tất cả các hàng cho những khách hàng đó và chèn lại chúng, và để xóa rõ ràng là xóa các hàng khỏi phân đoạn bàn.
- Như đã đề cập, giải pháp này hoạt động tốt hơn đối với kích thước dữ liệu cụ thể này và có thể không hoạt động tốt đối với các độ dài chuỗi khác. Nó sẽ đảm bảo thử nghiệm thêm để đảm bảo nó phù hợp với kích thước cột, độ dài giá trị trung bình và độ dài thông số tìm kiếm điển hình của bạn.
- Vì chúng tôi sẽ có rất nhiều bản sao của các mảnh như "Lưỡi liềm" và "Đường phố" (đừng bận tâm đến tất cả các tên đường và số nhà giống nhau hoặc tương tự nhau), có thể chuẩn hóa nó hơn nữa bằng cách lưu trữ từng mảnh duy nhất trong bảng các mảnh, và sau đó là một bảng khác hoạt động như một bảng nối nhiều-nhiều. Việc thiết lập sẽ phức tạp hơn rất nhiều và tôi không chắc sẽ thu được nhiều thứ.
- Tôi chưa điều tra đầy đủ về quá trình nén trang, có vẻ như - ít nhất về lý thuyết - điều này có thể mang lại một số lợi ích. Tôi cũng có cảm giác rằng việc triển khai Columnstore cũng có thể có lợi trong một số trường hợp.
Dù sao, tất cả những gì đã nói, tôi chỉ muốn chia sẻ nó như một ý tưởng đang phát triển và thu hút bất kỳ phản hồi nào về tính thực tế của nó cho các trường hợp sử dụng cụ thể. Tôi có thể tìm hiểu chi tiết cụ thể hơn cho một bài đăng trong tương lai nếu bạn có thể cho tôi biết những khía cạnh nào của giải pháp này mà bạn quan tâm.



