Tuần trước, tôi đã trình bày phiên T-SQL:Thói quen xấu và Các phương pháp hay nhất trong hội nghị GroupBy. Phát lại video và các tài liệu khác có sẵn tại đây:
- T-SQL:Các thói quen xấu và các phương pháp hay nhất
Một trong những mục tôi luôn đề cập trong phiên đó là tôi thường thích GROUP BY hơn DISTINCT khi loại bỏ các bản sao. Mặc dù DISTINCT giải thích rõ hơn về mục đích và GROUP BY chỉ được yêu cầu khi có các tập hợp, chúng có thể hoán đổi cho nhau trong nhiều trường hợp.
Hãy bắt đầu với một cái gì đó đơn giản bằng cách sử dụng Wide World Importers. Hai truy vấn này tạo ra cùng một kết quả:
SELECT DISTINCT Description FROM Sales.OrderLines; SELECT Description FROM Sales.OrderLines GROUP BY Description;
Và trên thực tế, thu được kết quả của chúng bằng cách sử dụng cùng một kế hoạch thực hiện:

Cùng một toán tử, cùng một số lần đọc, sự khác biệt không đáng kể về CPU và tổng thời lượng (chúng thay phiên nhau "chiến thắng").
Vì vậy, tại sao tôi lại khuyên bạn nên sử dụng cú pháp GROUP BY đơn giản hơn và ít trực quan hơn DISTINCT? Vâng, trong trường hợp đơn giản này, đó là một lần lật đồng xu. Tuy nhiên, trong những trường hợp phức tạp hơn, DISTINCT có thể thực hiện nhiều công việc hơn. Về cơ bản, DISTINCT thu thập tất cả các hàng, bao gồm bất kỳ biểu thức nào cần được đánh giá, sau đó loại bỏ các bản sao. GROUP BY có thể (một lần nữa, trong một số trường hợp) lọc ra các hàng trùng lặp trước thực hiện bất kỳ công việc nào trong số đó.
Ví dụ, hãy nói về tổng hợp chuỗi. Trong khi ở trong SQL Server v.Next, bạn sẽ có thể sử dụng STRING_AGG (xem bài đăng ở đây và tại đây), phần còn lại của chúng tôi phải tiếp tục với FOR XML PATH (và trước khi bạn cho tôi biết về CTE đệ quy tuyệt vời như thế nào cho việc này, vui lòng đọc bài đăng này, quá). Chúng tôi có thể có một truy vấn như thế này, truy vấn này cố gắng trả lại tất cả các Đơn hàng từ bảng Sales.OrderLines, cùng với các mô tả mặt hàng dưới dạng danh sách được phân tách bằng dấu sổ đứng:
SELECT o.OrderID, OrderItems = STUFF((SELECT N'|' + Description FROM Sales.OrderLines WHERE OrderID = o.OrderID FOR XML PATH(N''), TYPE).value(N'text()[1]', N'nvarchar(max)'),1,1,N'') FROM Sales.OrderLines AS o;
Đây là một truy vấn điển hình để giải quyết loại vấn đề này, với kế hoạch thực thi sau (cảnh báo trong tất cả các kế hoạch chỉ dành cho chuyển đổi ngầm ra khỏi bộ lọc XPath):
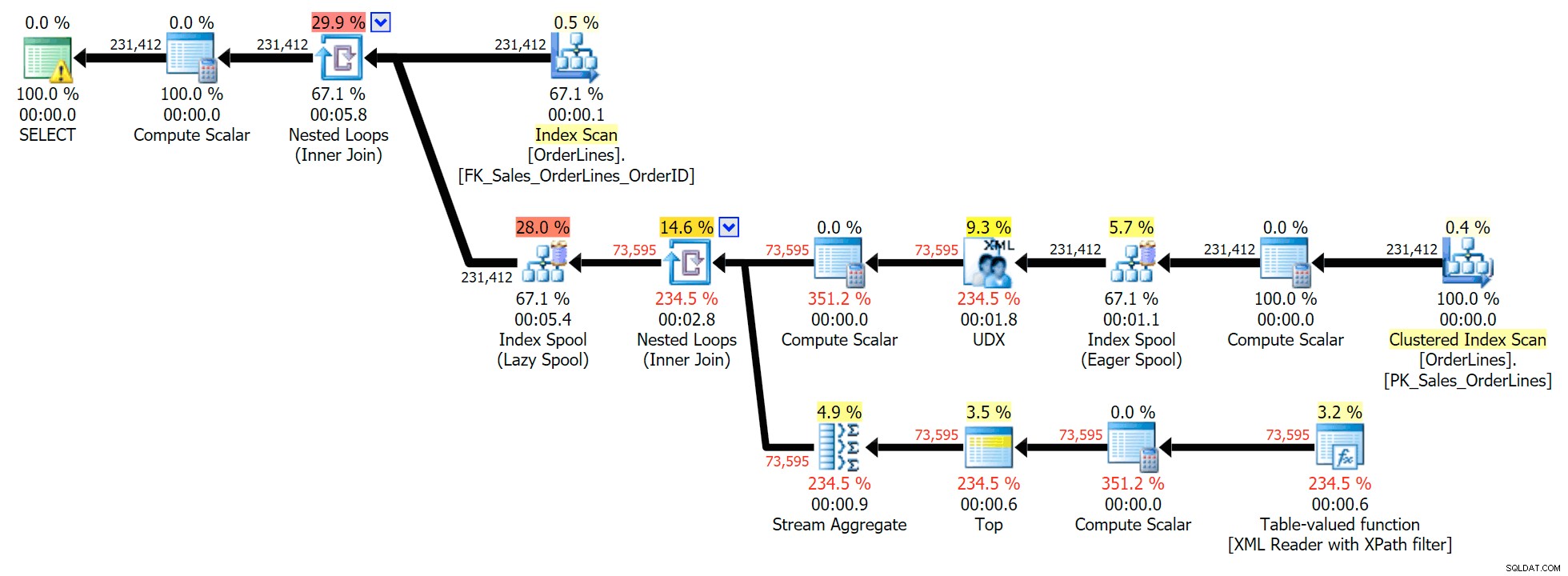
Tuy nhiên, nó có một vấn đề mà bạn có thể nhận thấy ở số lượng hàng đầu ra. Bạn chắc chắn có thể phát hiện ra nó khi tình cờ quét đầu ra:

Đối với mọi đơn đặt hàng, chúng tôi thấy danh sách được phân tách bằng dấu sổ đứng, nhưng chúng tôi thấy một hàng cho từng mặt hàng trong mỗi đơn đặt hàng. Phản ứng giật đầu gối là ném một DISTINCT vào danh sách cột:
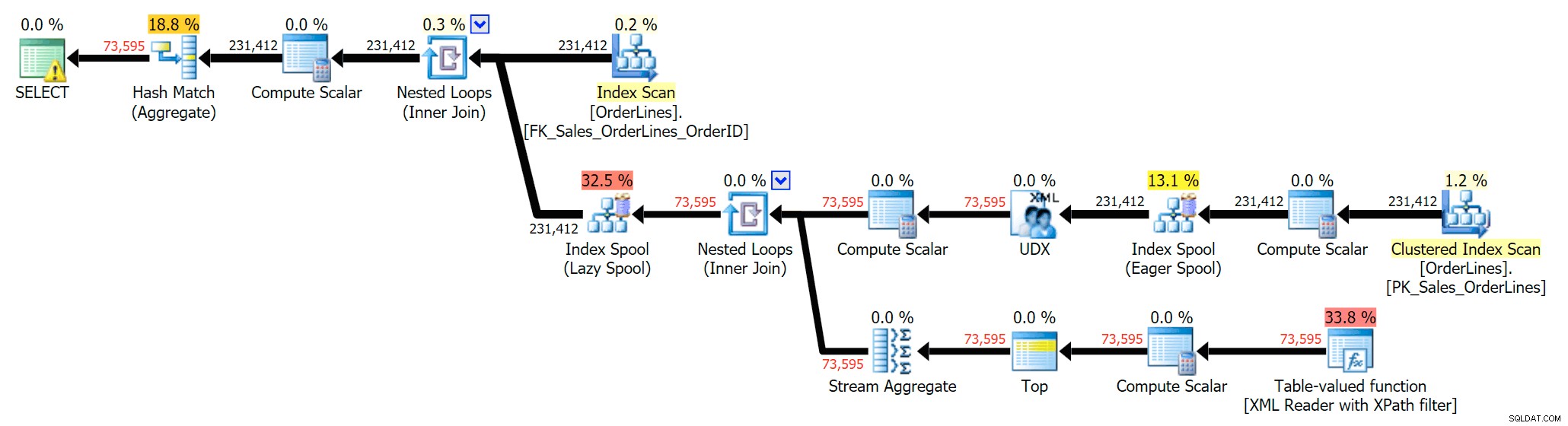
SELECT DISTINCT o.OrderID, OrderItems = STUFF((SELECT N'|' + Description FROM Sales.OrderLines WHERE OrderID = o.OrderID FOR XML PATH(N''), TYPE).value(N'text()[1]', N'nvarchar(max)'),1,1,N'') FROM Sales.OrderLines AS o;
Điều đó giúp loại bỏ các bản sao (và thay đổi các thuộc tính sắp xếp trên bản quét, vì vậy kết quả sẽ không nhất thiết xuất hiện theo thứ tự có thể dự đoán được) và tạo ra kế hoạch thực thi sau:
Một cách khác để thực hiện việc này là thêm GROUP BY cho OrderID (vì truy vấn con không cần rõ ràng được tham chiếu lại trong GROUP BY):
SELECT o.OrderID, OrderItems = STUFF((SELECT N'|' + Description FROM Sales.OrderLines WHERE OrderID = o.OrderID FOR XML PATH(N''), TYPE).value(N'text()[1]', N'nvarchar(max)'),1,1,N'') FROM Sales.OrderLines AS o GROUP BY o.OrderID;
Điều này tạo ra kết quả giống nhau (mặc dù đơn đặt hàng đã trả lại) và một kế hoạch hơi khác:
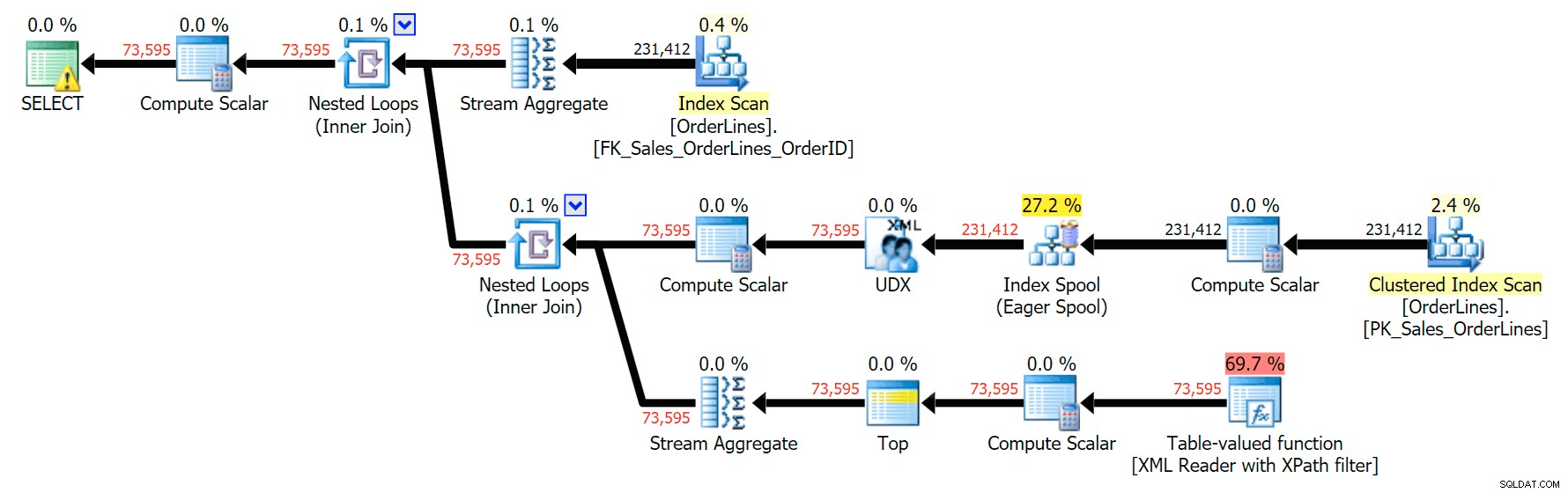
Tuy nhiên, các chỉ số hiệu suất rất thú vị để so sánh.

Biến thể DISTINCT mất thời gian gấp 4 lần, sử dụng gấp 4 lần CPU và gần 6 lần số lần đọc khi so sánh với biến thể GROUP BY. (Hãy nhớ rằng, những truy vấn này trả về cùng một kết quả.)
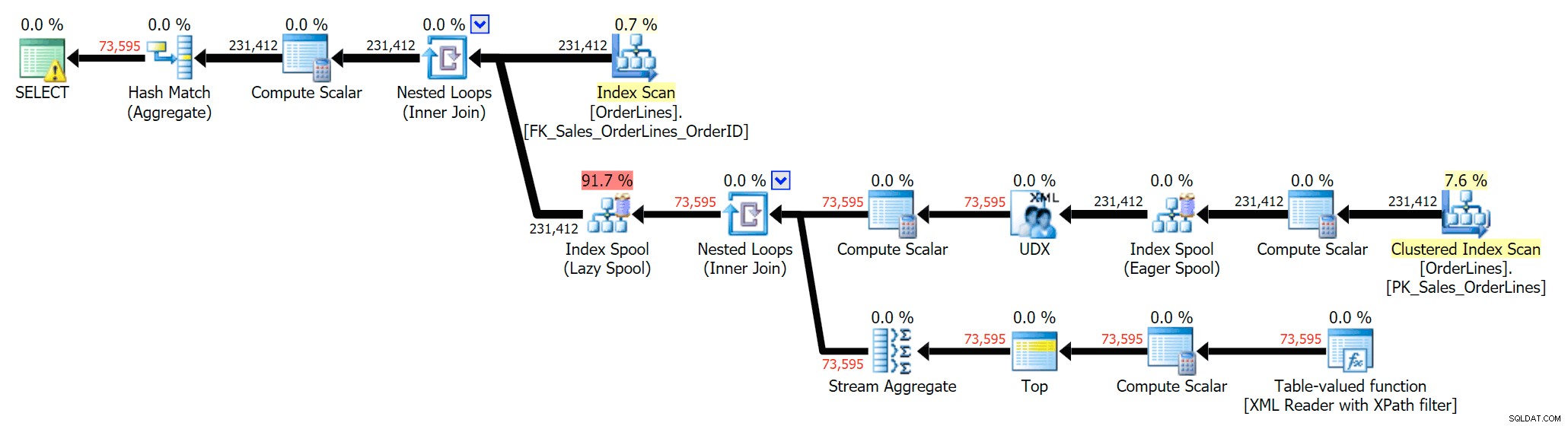
Chúng tôi cũng có thể so sánh các kế hoạch thực thi khi chúng tôi thay đổi chi phí từ CPU + I / O kết hợp thành I / O chỉ, một tính năng dành riêng cho Plan Explorer. Chúng tôi cũng hiển thị các giá trị được tính lại (dựa trên thực tế chi phí quan sát được trong quá trình thực thi truy vấn, một tính năng cũng chỉ có trong Plan Explorer). Đây là gói DISTINCT:
Và đây là kế hoạch GROUP BY:
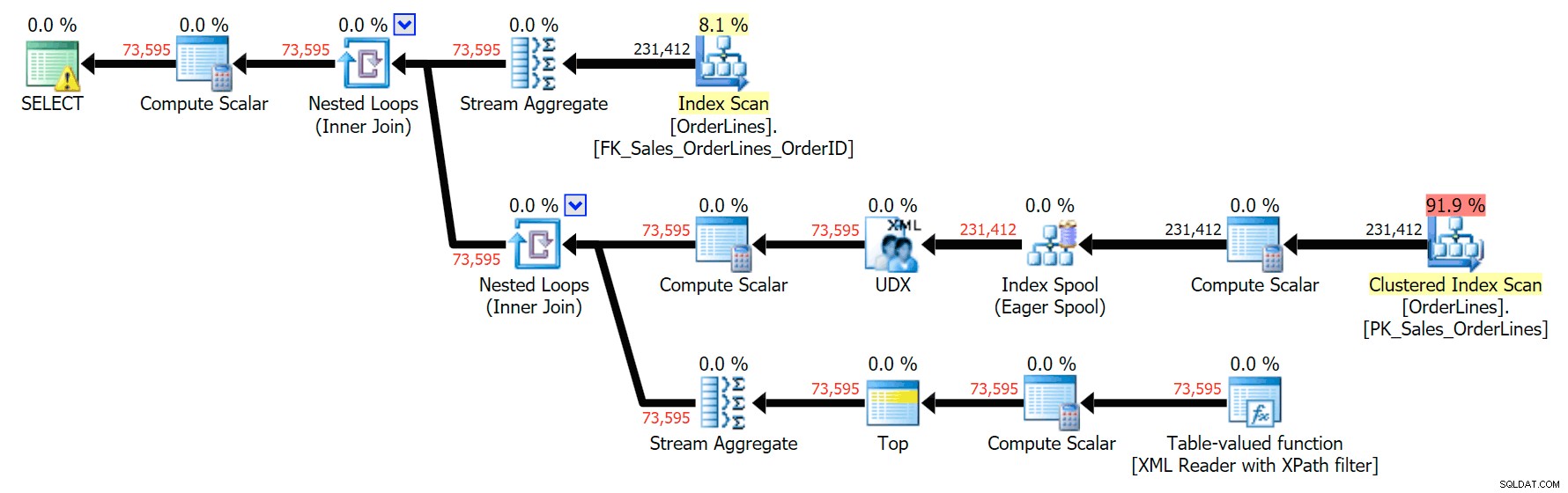
Bạn có thể thấy rằng, trong gói GROUP BY, hầu như tất cả chi phí I / O đều nằm trong quá trình quét (đây là chú giải công cụ cho quá trình quét CI, hiển thị chi phí I / O là ~ 3,4 "đô la truy vấn"). Tuy nhiên, trong kế hoạch DISTINCT, hầu hết chi phí I / O nằm trong chỉ mục (và đây là chú giải công cụ; chi phí I / O ở đây là ~ 41,4 "tiền truy vấn"). Lưu ý rằng CPU cũng cao hơn rất nhiều với ống chỉ mục. Chúng ta sẽ nói về "tiền truy vấn" vào lúc khác, nhưng vấn đề là bộ chỉ mục đắt hơn 10 lần so với quá trình quét - nhưng quá trình quét vẫn giống nhau 3,4 trong cả hai kế hoạch. Đây là một lý do mà nó luôn làm tôi khó chịu khi mọi người nói rằng họ cần "sửa chữa" nhà điều hành trong kế hoạch với chi phí cao nhất. Một số nhà điều hành trong kế hoạch sẽ luôn luôn là cái đắt nhất; điều đó không có nghĩa là nó cần được sửa.
@ AaronBertrand những truy vấn đó không thực sự tương đương về mặt logic - DISTINCT là trên cả hai cột, trong khi GROUP BY của bạn chỉ nằm trên một
- Adam Machanic (@AdamMachanic) ngày 20 tháng 1 năm 2017
Mặc dù Adam Machanic đúng khi nói rằng các truy vấn này khác nhau về ngữ nghĩa, nhưng kết quả là giống nhau - chúng tôi nhận được cùng một số hàng, chứa chính xác các kết quả giống nhau và chúng tôi đã làm điều đó với số lần đọc và CPU ít hơn nhiều.
Vì vậy, trong khi DISTINCT và GROUP BY giống hệt nhau trong nhiều tình huống, đây là một trường hợp mà phương pháp GROUP BY chắc chắn dẫn đến hiệu suất tốt hơn (với cái giá là ý định khai báo ít rõ ràng hơn trong chính truy vấn). Tôi muốn biết liệu bạn có nghĩ rằng có bất kỳ trường hợp nào mà DISTINCT tốt hơn GROUP BY, ít nhất là về mặt hiệu suất, ít chủ quan hơn nhiều so với phong cách hoặc liệu một tuyên bố có cần phải tự ghi lại hay không.
Bài đăng này phù hợp với loạt bài "bất ngờ và giả định" của tôi vì nhiều điều chúng tôi coi là chân lý dựa trên những quan sát hạn chế hoặc các trường hợp sử dụng cụ thể có thể được kiểm tra khi sử dụng trong các tình huống khác. Chúng tôi chỉ cần nhớ dành thời gian để làm điều đó như một phần của tối ưu hóa truy vấn SQL…
Tài liệu tham khảo
- Kết hợp được nhóm trong SQL Server
- Kết hợp được nhóm:Sắp xếp và loại bỏ các bản trùng lặp
- Bốn trường hợp sử dụng thực tế cho kết nối được nhóm
- SQL Server v.Next:Hiệu suất STRING_AGG ()
- SQL Server v.Next:Hiệu suất STRING_AGG, Phần 2