Một trong nhiều tính năng mới được giới thiệu trở lại trong SQL Server 2008 là Nén dữ liệu. Nén ở cấp độ hàng hoặc cấp độ trang mang lại cơ hội tiết kiệm dung lượng đĩa, với việc đánh đổi yêu cầu CPU nhiều hơn một chút để nén và giải nén dữ liệu. Người ta thường tranh luận rằng phần lớn các hệ thống bị ràng buộc IO chứ không phải ràng buộc CPU, vì vậy sự đánh đổi là xứng đáng. Cuộc đuổi bắt? Bạn phải sử dụng Phiên bản Doanh nghiệp để sử dụng Nén dữ liệu. Với việc phát hành SQL Server 2016 SP1, điều đó đã thay đổi! Nếu bạn đang chạy Phiên bản tiêu chuẩn của SQL Server 2016 SP1 trở lên, thì bây giờ bạn có thể sử dụng Nén dữ liệu. Ngoài ra còn có một chức năng tích hợp mới để nén, COMPRESS (và đối tác của nó là DECOMPRESS). Nén dữ liệu không hoạt động trên dữ liệu ngoài hàng, vì vậy nếu bạn có một cột như NVARCHAR (MAX) trong bảng của mình với các giá trị thường có kích thước lớn hơn 8000 byte, thì dữ liệu đó sẽ không được nén (cảm ơn Adam Machanic đã nhắc nhở đó) . Chức năng COMPRESS giải quyết vấn đề này và nén dữ liệu có kích thước lên đến 2GB. Hơn nữa, trong khi tôi tranh luận rằng hàm chỉ nên được sử dụng cho dữ liệu lớn, nằm ngoài hàng, tôi nghĩ rằng việc so sánh nó trực tiếp với việc nén hàng và nén trang là một thử nghiệm đáng giá.
THIẾT LẬP
Đối với dữ liệu thử nghiệm, tôi đang làm việc từ tập lệnh mà Aaron Bertrand đã sử dụng trước đây, nhưng tôi đã thực hiện một số chỉnh sửa. Tôi đã tạo một cơ sở dữ liệu riêng để thử nghiệm nhưng bạn có thể sử dụng tempdb hoặc một cơ sở dữ liệu mẫu khác, sau đó tôi bắt đầu với bảng Khách hàng có ba cột NVARCHAR. Tôi đã cân nhắc việc tạo các cột lớn hơn và điền chúng bằng các chuỗi ký tự lặp lại, nhưng việc sử dụng văn bản có thể đọc được sẽ cho một mẫu thực tế hơn và do đó cung cấp độ chính xác cao hơn.
Lưu ý: Nếu bạn quan tâm đến việc triển khai nén và muốn biết nó sẽ ảnh hưởng như thế nào đến việc lưu trữ và hiệu suất trong môi trường của bạn, TÔI RẤT KHUYẾN CÁO RẰNG BẠN THỬ NGHIỆM NÓ. Tôi đang cung cấp cho bạn phương pháp luận với dữ liệu mẫu; việc triển khai điều này trong môi trường của bạn sẽ không liên quan đến công việc bổ sung.
Bạn sẽ lưu ý bên dưới rằng sau khi tạo cơ sở dữ liệu, chúng tôi đang bật Query Store. Tại sao phải tạo một bảng riêng biệt để thử và theo dõi số liệu hiệu suất của chúng tôi khi chúng tôi chỉ có thể sử dụng chức năng được tích hợp sẵn trong SQL Server ?!
USE [master]; GO CREATE DATABASE [CustomerDB] CONTAINMENT = NONE ON PRIMARY ( NAME = N'CustomerDB', FILENAME = N'C:\Databases\CustomerDB.mdf' , SIZE = 4096MB , MAXSIZE = UNLIMITED, FILEGROWTH = 65536KB ) LOG ON ( NAME = N'CustomerDB_log', FILENAME = N'C:\Databases\CustomerDB_log.ldf' , SIZE = 2048MB , MAXSIZE = UNLIMITED , FILEGROWTH = 65536KB ); GO ALTER DATABASE [CustomerDB] SET COMPATIBILITY_LEVEL = 130; GO ALTER DATABASE [CustomerDB] SET RECOVERY SIMPLE; GO ALTER DATABASE [CustomerDB] SET QUERY_STORE = ON; GO ALTER DATABASE [CustomerDB] SET QUERY_STORE ( OPERATION_MODE = READ_WRITE, CLEANUP_POLICY = (STALE_QUERY_THRESHOLD_DAYS = 30), DATA_FLUSH_INTERVAL_SECONDS = 60, INTERVAL_LENGTH_MINUTES = 5, MAX_STORAGE_SIZE_MB = 256, QUERY_CAPTURE_MODE = ALL, SIZE_BASED_CLEANUP_MODE = AUTO, MAX_PLANS_PER_QUERY = 200 ); GO
Bây giờ chúng ta sẽ thiết lập một số thứ bên trong cơ sở dữ liệu:
USE [CustomerDB]; GO ALTER DATABASE SCOPED CONFIGURATION SET MAXDOP = 0; GO -- note: I removed the unique index on [Email] that was in Aaron's version CREATE TABLE [dbo].[Customers] ( [CustomerID] [int] NOT NULL, [FirstName] [nvarchar](64) NOT NULL, [LastName] [nvarchar](64) NOT NULL, [EMail] [nvarchar](320) NOT NULL, [Active] [bit] NOT NULL DEFAULT 1, [Created] [datetime] NOT NULL DEFAULT SYSDATETIME(), [Updated] [datetime] NULL, CONSTRAINT [PK_Customers] PRIMARY KEY CLUSTERED ([CustomerID]) ); GO CREATE NONCLUSTERED INDEX [Active_Customers] ON [dbo].[Customers]([FirstName],[LastName],[EMail]) WHERE ([Active]=1); GO CREATE NONCLUSTERED INDEX [PhoneBook_Customers] ON [dbo].[Customers]([LastName],[FirstName]) INCLUDE ([EMail]);
Với bảng đã tạo, chúng tôi sẽ thêm một số dữ liệu, nhưng chúng tôi đang thêm 5 triệu hàng thay vì 1 triệu. Quá trình này mất khoảng tám phút để chạy trên máy tính xách tay của tôi.
INSERT dbo.Customers WITH (TABLOCKX)
(CustomerID, FirstName, LastName, EMail, [Active])
SELECT rn = ROW_NUMBER() OVER (ORDER BY n), fn, ln, em, a
FROM
(
SELECT TOP (5000000) fn, ln, em, a = MAX(a), n = MAX(NEWID())
FROM
(
SELECT fn, ln, em, a, r = ROW_NUMBER() OVER (PARTITION BY em ORDER BY em)
FROM
(
SELECT TOP (20000000)
fn = LEFT(o.name, 64),
ln = LEFT(c.name, 64),
em = LEFT(o.name, LEN(c.name)%5+1) + '.'
+ LEFT(c.name, LEN(o.name)%5+2) + '@'
+ RIGHT(c.name, LEN(o.name + c.name)%12 + 1)
+ LEFT(RTRIM(CHECKSUM(NEWID())),3) + '.com',
a = CASE WHEN c.name LIKE '%y%' THEN 0 ELSE 1 END
FROM sys.all_objects AS o CROSS JOIN sys.all_columns AS c
ORDER BY NEWID()
) AS x
) AS y WHERE r = 1
GROUP BY fn, ln, em
ORDER BY n
) AS z
ORDER BY rn;
GO Bây giờ chúng ta sẽ tạo thêm ba bảng:một để nén hàng, một để nén trang và một cho hàm COMPRESS. Lưu ý rằng với hàm COMPRESS, bạn phải tạo các cột dưới dạng kiểu dữ liệu VARBINARY. Do đó, không có chỉ mục không phân biệt nào trên bảng (vì bạn không thể tạo khóa chỉ mục trên cột varbinary).
CREATE TABLE [dbo].[Customers_Page] ( [CustomerID] [int] NOT NULL, [FirstName] [nvarchar](64) NOT NULL, [LastName] [nvarchar](64) NOT NULL, [EMail] [nvarchar](320) NOT NULL, [Active] [bit] NOT NULL DEFAULT 1, [Created] [datetime] NOT NULL DEFAULT SYSDATETIME(), [Updated] [datetime] NULL, CONSTRAINT [PK_Customers_Page] PRIMARY KEY CLUSTERED ([CustomerID]) ); GO CREATE NONCLUSTERED INDEX [Active_Customers_Page] ON [dbo].[Customers_Page]([FirstName],[LastName],[EMail]) WHERE ([Active]=1); GO CREATE NONCLUSTERED INDEX [PhoneBook_Customers_Page] ON [dbo].[Customers_Page]([LastName],[FirstName]) INCLUDE ([EMail]); GO CREATE TABLE [dbo].[Customers_Row] ( [CustomerID] [int] NOT NULL, [FirstName] [nvarchar](64) NOT NULL, [LastName] [nvarchar](64) NOT NULL, [EMail] [nvarchar](320) NOT NULL, [Active] [bit] NOT NULL DEFAULT 1, [Created] [datetime] NOT NULL DEFAULT SYSDATETIME(), [Updated] [datetime] NULL, CONSTRAINT [PK_Customers_Row] PRIMARY KEY CLUSTERED ([CustomerID]) ); GO CREATE NONCLUSTERED INDEX [Active_Customers_Row] ON [dbo].[Customers_Row]([FirstName],[LastName],[EMail]) WHERE ([Active]=1); GO CREATE NONCLUSTERED INDEX [PhoneBook_Customers_Row] ON [dbo].[Customers_Row]([LastName],[FirstName]) INCLUDE ([EMail]); GO CREATE TABLE [dbo].[Customers_Compress] ( [CustomerID] [int] NOT NULL, [FirstName] [varbinary](max) NOT NULL, [LastName] [varbinary](max) NOT NULL, [EMail] [varbinary](max) NOT NULL, [Active] [bit] NOT NULL DEFAULT 1, [Created] [datetime] NOT NULL DEFAULT SYSDATETIME(), [Updated] [datetime] NULL, CONSTRAINT [PK_Customers_Compress] PRIMARY KEY CLUSTERED ([CustomerID]) ); GO
Tiếp theo, chúng tôi sẽ sao chép dữ liệu từ [dbo]. [Khách hàng] sang ba bảng khác. Đây là cách CHÈN thẳng cho trang và bảng hàng của chúng tôi và mất khoảng hai đến ba phút cho mỗi lần CHÈN, nhưng có một vấn đề về khả năng mở rộng với chức năng COMPRESS:cố gắng chèn 5 triệu hàng trong một lần không hợp lý. Tập lệnh bên dưới chèn các hàng theo lô 50.000 và chỉ chèn 1 triệu hàng thay vì 5 triệu. Tôi biết, điều đó có nghĩa là chúng tôi không thực sự táo với táo ở đây để so sánh, nhưng tôi đồng ý với điều đó. Việc chèn 1 triệu hàng mất 10 phút trên máy tính của tôi; Vui lòng chỉnh sửa tập lệnh và chèn 5 triệu hàng cho các thử nghiệm của riêng bạn.
INSERT dbo.Customers_Page WITH (TABLOCKX) (CustomerID, FirstName, LastName, EMail, [Active]) SELECT CustomerID, FirstName, LastName, EMail, [Active] FROM dbo.Customers; GO INSERT dbo.Customers_Row WITH (TABLOCKX) (CustomerID, FirstName, LastName, EMail, [Active]) SELECT CustomerID, FirstName, LastName, EMail, [Active] FROM dbo.Customers; GO SET NOCOUNT ON DECLARE @StartID INT = 1 DECLARE @EndID INT = 50000 DECLARE @Increment INT = 50000 DECLARE @IDMax INT = 1000000 WHILE @StartID < @IDMax BEGIN INSERT dbo.Customers_Compress WITH (TABLOCKX) (CustomerID, FirstName, LastName, EMail, [Active]) SELECT top 100000 CustomerID, COMPRESS(FirstName), COMPRESS(LastName), COMPRESS(EMail), [Active] FROM dbo.Customers WHERE [CustomerID] BETWEEN @StartID AND @EndID; SET @StartID = @StartID + @Increment; SET @EndID = @EndID + @Increment; END
Với tất cả các bảng của chúng tôi đã được điền, chúng tôi có thể kiểm tra kích thước. Tại thời điểm này, chúng tôi chưa thực hiện nén ROW hoặc PAGE, nhưng chức năng COMPRESS đã được sử dụng:
SELECT [o].[name], [i].[index_id], [i].[name], [p].[rows], (8*SUM([au].[used_pages]))/1024 AS [IndexSize(MB)], [p].[data_compression_desc] FROM [sys].[allocation_units] [au] JOIN [sys].[partitions] [p] ON [au].[container_id] = [p].[partition_id] JOIN [sys].[objects] [o] ON [p].[object_id] = [o].[object_id] JOIN [sys].[indexes] [i] ON [p].[object_id] = [i].[object_id] AND [p].[index_id] = [i].[index_id] WHERE [o].[is_ms_shipped] = 0 GROUP BY [o].[name], [i].[index_id], [i].[name], [p].[rows], [p].[data_compression_desc] ORDER BY [o].[name], [i].[index_id];
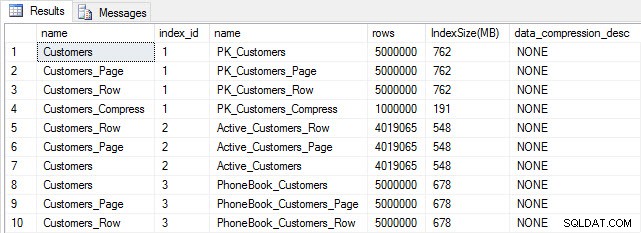 Kích thước bảng và chỉ mục sau khi chèn
Kích thước bảng và chỉ mục sau khi chèn
Như mong đợi, tất cả các bảng ngoại trừ Customer_Compress đều có cùng kích thước. Bây giờ chúng ta sẽ xây dựng lại các chỉ mục trên tất cả các bảng, triển khai nén hàng và trang trên các Customer_Row và Customer_Page, tương ứng.
ALTER INDEX ALL ON dbo.Customers REBUILD; GO ALTER INDEX ALL ON dbo.Customers_Page REBUILD WITH (DATA_COMPRESSION = PAGE); GO ALTER INDEX ALL ON dbo.Customers_Row REBUILD WITH (DATA_COMPRESSION = ROW); GO ALTER INDEX ALL ON dbo.Customers_Compress REBUILD;
Nếu chúng tôi kiểm tra kích thước bảng sau khi nén, bây giờ chúng tôi có thể thấy mức tiết kiệm dung lượng đĩa của mình:
SELECT [o].[name], [i].[index_id], [i].[name], [p].[rows], (8*SUM([au].[used_pages]))/1024 AS [IndexSize(MB)], [p].[data_compression_desc] FROM [sys].[allocation_units] [au] JOIN [sys].[partitions] [p] ON [au].[container_id] = [p].[partition_id] JOIN [sys].[objects] [o] ON [p].[object_id] = [o].[object_id] JOIN [sys].[indexes] [i] ON [p].[object_id] = [i].[object_id] AND [p].[index_id] = [i].[index_id] WHERE [o].[is_ms_shipped] = 0 GROUP BY [o].[name], [i].[index_id], [i].[name], [p].[rows], [p].[data_compression_desc] ORDER BY [i].[index_id], [IndexSize(MB)] DESC;
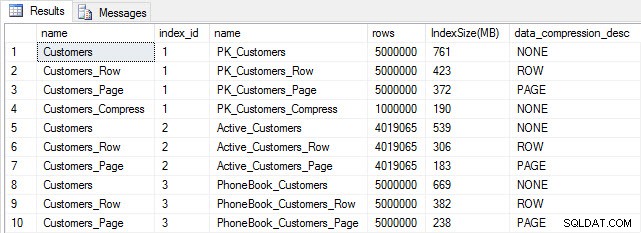
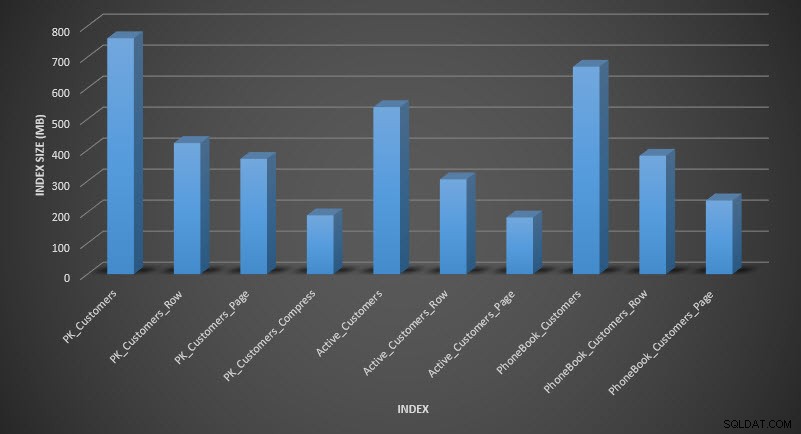 Kích thước chỉ mục sau khi nén
Kích thước chỉ mục sau khi nén
Như mong đợi, việc nén hàng và trang làm giảm đáng kể kích thước của bảng và các chỉ mục của nó. Hàm COMPRESS giúp chúng tôi tiết kiệm được nhiều không gian nhất - chỉ mục được phân nhóm có kích thước bằng một phần tư kích thước của bảng gốc.
KIỂM TRA HIỆU SUẤT QUERY
Trước khi chúng tôi kiểm tra hiệu suất truy vấn, hãy lưu ý rằng chúng tôi có thể sử dụng Query Store để xem hiệu suất INSERT và REBUILD:
SELECT [q].[query_id], [qt].[query_sql_text], SUM([rs].[count_executions]) [ExecutionCount], AVG([rs].[avg_duration])/1000 [AvgDuration_ms], AVG([rs].[avg_cpu_time]) [AvgCPU], AVG([rs].[avg_logical_io_reads]) [AvgLogicalReads], AVG([rs].[avg_physical_io_reads]) [AvgPhysicalReads] FROM [sys].[query_store_query] [q] JOIN [sys].[query_store_query_text] [qt] ON [q].[query_text_id] = [qt].[query_text_id] LEFT OUTER JOIN [sys].[objects] [o] ON [q].[object_id] = [o].[object_id] JOIN [sys].[query_store_plan] [p] ON [q].[query_id] = [p].[query_id] JOIN [sys].[query_store_runtime_stats] [rs] ON [p].[plan_id] = [rs].[plan_id] WHERE [qt].[query_sql_text] LIKE '%INSERT%' OR [qt].[query_sql_text] LIKE '%ALTER%' GROUP BY [q].[query_id], [q].[object_id], [o].[name], [qt].[query_sql_text], [rs].[plan_id] ORDER BY [q].[query_id];
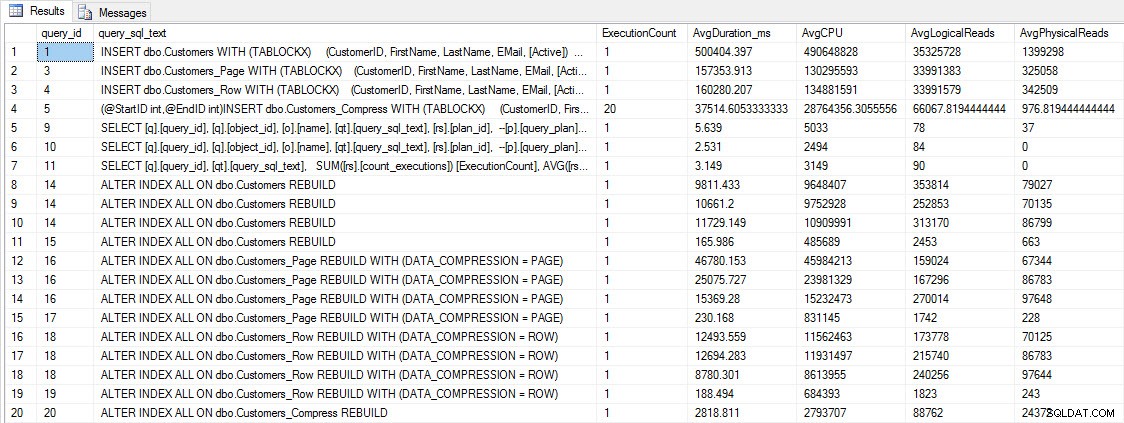 INSERT và REBUILD số liệu hiệu suất
INSERT và REBUILD số liệu hiệu suất
Mặc dù dữ liệu này rất thú vị, nhưng tôi tò mò hơn về cách nén ảnh hưởng đến các truy vấn CHỌN hàng ngày của tôi. Tôi có một bộ ba thủ tục được lưu trữ mà mỗi thủ tục có một truy vấn SELECT để mỗi chỉ mục được sử dụng. Tôi đã tạo các thủ tục này cho mỗi bảng, sau đó viết một tập lệnh để kéo các giá trị cho họ và tên để sử dụng cho thử nghiệm. Đây là tập lệnh để tạo các thủ tục.
Khi chúng tôi đã tạo các thủ tục được lưu trữ, chúng tôi có thể chạy tập lệnh bên dưới để gọi chúng. Bắt đầu và sau đó đợi vài phút…
SET NOCOUNT ON; GO DECLARE @RowNum INT = 1; DECLARE @Round INT = 1; DECLARE @ID INT = 1; DECLARE @FN NVARCHAR(64); DECLARE @LN NVARCHAR(64); DECLARE @SQLstring NVARCHAR(MAX); DROP TABLE IF EXISTS #FirstNames, #LastNames; SELECT DISTINCT [FirstName], DENSE_RANK() OVER (ORDER BY [FirstName]) AS RowNum INTO #FirstNames FROM [dbo].[Customers] SELECT DISTINCT [LastName], DENSE_RANK() OVER (ORDER BY [LastName]) AS RowNum INTO #LastNames FROM [dbo].[Customers] WHILE 1=1 BEGIN SELECT @FN = ( SELECT [FirstName] FROM #FirstNames WHERE RowNum = @RowNum) SELECT @LN = ( SELECT [LastName] FROM #LastNames WHERE RowNum = @RowNum) SET @FN = SUBSTRING(@FN, 1, 5) + '%' SET @LN = SUBSTRING(@LN, 1, 5) + '%' EXEC [dbo].[usp_FindActiveCustomer_C] @FN; EXEC [dbo].[usp_FindAnyCustomer_C] @LN; EXEC [dbo].[usp_FindSpecificCustomer_C] @ID; EXEC [dbo].[usp_FindActiveCustomer_P] @FN; EXEC [dbo].[usp_FindAnyCustomer_P] @LN; EXEC [dbo].[usp_FindSpecificCustomer_P] @ID; EXEC [dbo].[usp_FindActiveCustomer_R] @FN; EXEC [dbo].[usp_FindAnyCustomer_R] @LN; EXEC [dbo].[usp_FindSpecificCustomer_R] @ID; EXEC [dbo].[usp_FindActiveCustomer_CS] @FN; EXEC [dbo].[usp_FindAnyCustomer_CS] @LN; EXEC [dbo].[usp_FindSpecificCustomer_CS] @ID; IF @ID < 5000000 BEGIN SET @ID = @ID + @Round END ELSE BEGIN SET @ID = 2 END IF @Round < 26 BEGIN SET @Round = @Round + 1 END ELSE BEGIN IF @RowNum < 2260 BEGIN SET @RowNum = @RowNum + 1 SET @Round = 1 END ELSE BEGIN SET @RowNum = 1 SET @Round = 1 END END END GO
Sau vài phút, hãy xem nội dung trong Cửa hàng truy vấn:
SELECT [q].[query_id], [q].[object_id], [o].[name], [qt].[query_sql_text], SUM([rs].[count_executions]) [ExecutionCount], CAST(AVG([rs].[avg_duration])/1000 AS DECIMAL(10,2)) [AvgDuration_ms], CAST(AVG([rs].[avg_cpu_time]) AS DECIMAL(10,2)) [AvgCPU], CAST(AVG([rs].[avg_logical_io_reads]) AS DECIMAL(10,2)) [AvgLogicalReads], CAST(AVG([rs].[avg_physical_io_reads]) AS DECIMAL(10,2)) [AvgPhysicalReads] FROM [sys].[query_store_query] [q] JOIN [sys].[query_store_query_text] [qt] ON [q].[query_text_id] = [qt].[query_text_id] JOIN [sys].[objects] [o] ON [q].[object_id] = [o].[object_id] JOIN [sys].[query_store_plan] [p] ON [q].[query_id] = [p].[query_id] JOIN [sys].[query_store_runtime_stats] [rs] ON [p].[plan_id] = [rs].[plan_id] WHERE [q].[object_id] <> 0 GROUP BY [q].[query_id], [q].[object_id], [o].[name], [qt].[query_sql_text], [rs].[plan_id] ORDER BY [o].[name];
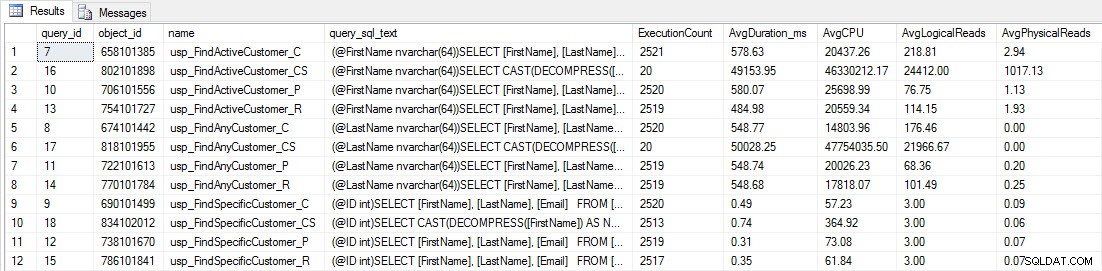
Bạn sẽ thấy rằng hầu hết các thủ tục được lưu trữ chỉ được thực thi 20 lần vì hai thủ tục chống lại [dbo]. [Customer_Compress] thực sự là chậm. Đây không phải là một bất ngờ; cả [FirstName] và [LastName] đều không được lập chỉ mục, vì vậy bất kỳ truy vấn nào cũng sẽ phải quét bảng. Tôi không muốn hai truy vấn đó làm chậm quá trình thử nghiệm của mình, vì vậy tôi sẽ sửa đổi khối lượng công việc và nhận xét EXEC [dbo]. [Usp_FindActiveCustomer_CS] và EXEC [dbo]. [Usp_FindAnyCustomer_CS] rồi bắt đầu lại. Lần này, tôi sẽ để nó chạy trong khoảng 10 phút và khi tôi nhìn lại đầu ra của Cửa hàng truy vấn, bây giờ tôi có một số dữ liệu tốt. Dưới đây là các con số thô, với biểu đồ yêu thích của người quản lý.
 Dữ liệu hiệu suất từ Cửa hàng truy vấn
Dữ liệu hiệu suất từ Cửa hàng truy vấn
 Thời lượng thủ tục đã lưu
Thời lượng thủ tục đã lưu
 CPU quy trình được lưu trữ
CPU quy trình được lưu trữ
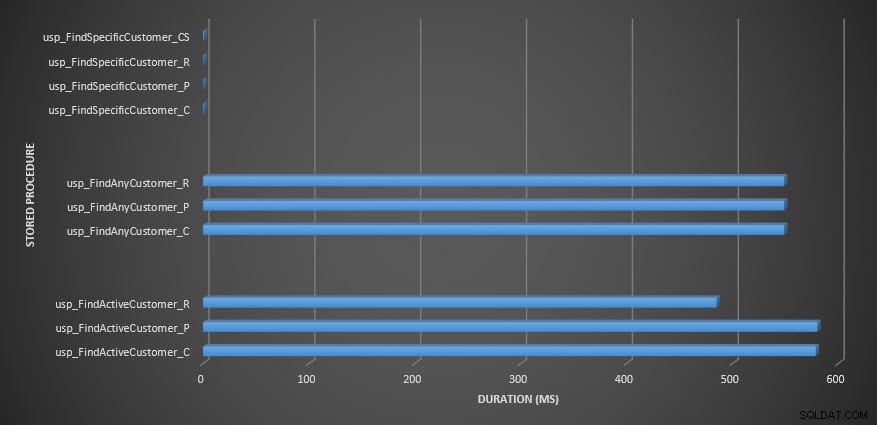
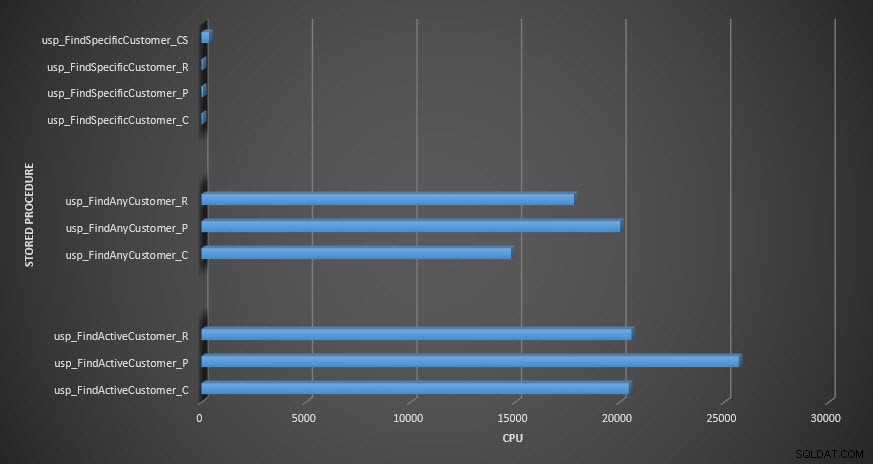
Nhắc nhở:Tất cả các thủ tục được lưu trữ kết thúc bằng _C đều từ bảng không nén. Các thủ tục kết thúc bằng _R là bảng được nén theo hàng, những thủ tục kết thúc bằng _P được nén trang và quy trình có _CS sử dụng hàm COMPRESS (Tôi đã xóa kết quả cho bảng đã nói cho usp_FindAnyCustomer_CS và usp_FindActiveCustomer_CS vì chúng làm lệch biểu đồ quá nhiều nên chúng tôi đã mất khác biệt trong phần còn lại của dữ liệu). Các thủ tục usp_FindAnyCustomer_ * và usp_FindActiveCustomer_ * đã sử dụng các chỉ mục không phân biệt và trả về hàng nghìn hàng cho mỗi lần thực thi.
Tôi dự kiến thời lượng sẽ cao hơn đối với các thủ tục usp_FindAnyCustomer_ * và usp_FindActiveCustomer_ * đối với các bảng nén hàng và trang, so với bảng không nén, do chi phí giải nén dữ liệu. Dữ liệu của Cửa hàng truy vấn không hỗ trợ mong đợi của tôi - thời lượng cho hai thủ tục được lưu trữ đó gần như giống nhau (hoặc ít hơn trong một trường hợp!) Trên ba bảng đó. IO logic cho các truy vấn gần như giống nhau trên các bảng không nén và trang và hàng được nén.
Về mặt CPU, trong thủ tục lưu trữ usp_FindActiveCustomer và usp_FindAnyCustomer, nó luôn cao hơn đối với các bảng nén. CPU có thể so sánh với thủ tục usp_FindSpecificCustomer, luôn là một tra cứu đơn lẻ dựa trên chỉ mục được phân nhóm. Lưu ý rằng CPU cao (nhưng thời lượng tương đối thấp) cho quy trình usp_FindSpecificCustomer so với bảng [dbo]. [Customer_Compress], yêu cầu hàm DECOMPRESS để hiển thị dữ liệu ở định dạng có thể đọc được.
TÓM TẮT
CPU bổ sung cần thiết để truy xuất dữ liệu nén tồn tại và có thể được đo lường bằng cách sử dụng Query Store hoặc các phương pháp cơ sở truyền thống. Dựa trên thử nghiệm ban đầu này, CPU có thể so sánh được với các tra cứu singleton, nhưng sẽ tăng lên khi có nhiều dữ liệu hơn. Tôi muốn buộc SQL Server giải nén hơn chỉ 10 trang - tôi muốn ít nhất 100 trang. Tôi đã thực thi các biến thể của tập lệnh này, trong đó hàng chục nghìn hàng được trả về và kết quả phù hợp với những gì bạn thấy ở đây. Kỳ vọng của tôi là để thấy sự khác biệt đáng kể về thời lượng do thời gian giải nén dữ liệu, các truy vấn sẽ cần trả về hàng trăm nghìn hoặc hàng triệu hàng. Nếu bạn đang ở trong hệ thống OLTP, bạn không muốn trả lại nhiều hàng như vậy, vì vậy các bài kiểm tra ở đây sẽ cung cấp cho bạn ý tưởng về cách nén có thể ảnh hưởng đến hiệu suất. Nếu bạn đang ở trong kho dữ liệu, thì bạn có thể sẽ thấy thời lượng cao hơn cùng với CPU cao hơn khi trả về các tập dữ liệu lớn. Mặc dù chức năng COMPRESS tiết kiệm không gian đáng kể so với nén trang và hàng, nhưng hiệu suất bị ảnh hưởng về mặt CPU và không thể lập chỉ mục các cột được nén do loại dữ liệu của chúng, chỉ làm cho nó khả thi đối với khối lượng lớn dữ liệu sẽ không đã tìm kiếm.



