
Gần đây tôi đã bị mắng vì gợi ý rằng, trong một số trường hợp, chỉ mục không phân cụm sẽ hoạt động tốt hơn cho một truy vấn cụ thể so với chỉ mục được phân cụm. Người này tuyên bố rằng chỉ mục được phân nhóm luôn tốt nhất vì nó luôn bao phủ theo định nghĩa và bất kỳ chỉ mục không được phân nhóm nào có một số hoặc tất cả các cột chính giống nhau luôn là thừa.
Tôi sẽ vui vẻ đồng ý rằng chỉ mục được phân cụm luôn bao phủ (và để tránh bất kỳ sự mơ hồ nào ở đây, chúng ta sẽ gắn bó với các bảng dựa trên đĩa với các chỉ mục B-cây truyền thống).
 Tuy nhiên, tôi không đồng ý rằng chỉ mục được phân nhóm là luôn luôn nhanh hơn chỉ mục không phân cụm. Tôi cũng không đồng ý rằng việc tạo chỉ mục không phân cụm hoặc ràng buộc duy nhất bao gồm các cột giống nhau (hoặc một số cột giống nhau) trong khóa phân nhóm luôn là thừa.
Tuy nhiên, tôi không đồng ý rằng chỉ mục được phân nhóm là luôn luôn nhanh hơn chỉ mục không phân cụm. Tôi cũng không đồng ý rằng việc tạo chỉ mục không phân cụm hoặc ràng buộc duy nhất bao gồm các cột giống nhau (hoặc một số cột giống nhau) trong khóa phân nhóm luôn là thừa.
Hãy lấy ví dụ này, Warehouse.StockItemTransactions , từ WideWorldImporters. Chỉ mục được phân nhóm được triển khai thông qua một khóa chính chỉ trên StockItemTransactionID (khá điển hình khi bạn có một số loại ID thay thế được tạo bởi IDENTITY hoặc SEQUENCE).
Đó là một điều khá phổ biến khi yêu cầu đếm toàn bộ bảng (mặc dù trong nhiều trường hợp, có nhiều cách tốt hơn). Điều này có thể là để kiểm tra thông thường hoặc là một phần của quy trình phân trang. Hầu hết mọi người sẽ làm theo cách này:
SELECT COUNT(*) FROM Warehouse.StockItemTransactions;
Với lược đồ hiện tại, lược đồ này sẽ sử dụng chỉ mục không phân cụm:
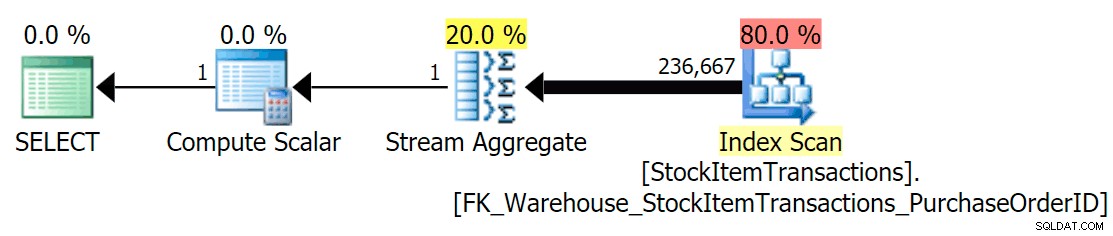
Chúng ta biết rằng chỉ mục không phân cụm không chứa tất cả các cột trong chỉ mục được phân nhóm. Thao tác đếm chỉ cần chắc chắn rằng tất cả các hàng đã được bao gồm, mà không cần quan tâm đến cột nào hiện diện, vì vậy SQL Server thường sẽ chọn chỉ mục có số trang nhỏ nhất (trong trường hợp này, chỉ mục được chọn có ~ 414 trang).
Bây giờ, hãy chạy lại truy vấn, lần này so sánh nó với một truy vấn gợi ý buộc sử dụng chỉ mục được phân nhóm.
SELECT COUNT(*) FROM Warehouse.StockItemTransactions; SELECT COUNT(*) /* with hint */ FROM Warehouse.StockItemTransactions WITH (INDEX(1));
Chúng tôi nhận được một hình dạng kế hoạch gần như giống hệt nhau, nhưng chúng tôi có thể thấy sự khác biệt lớn về số lần đọc (414 cho chỉ mục đã chọn so với 1,982 cho chỉ mục được phân nhóm):
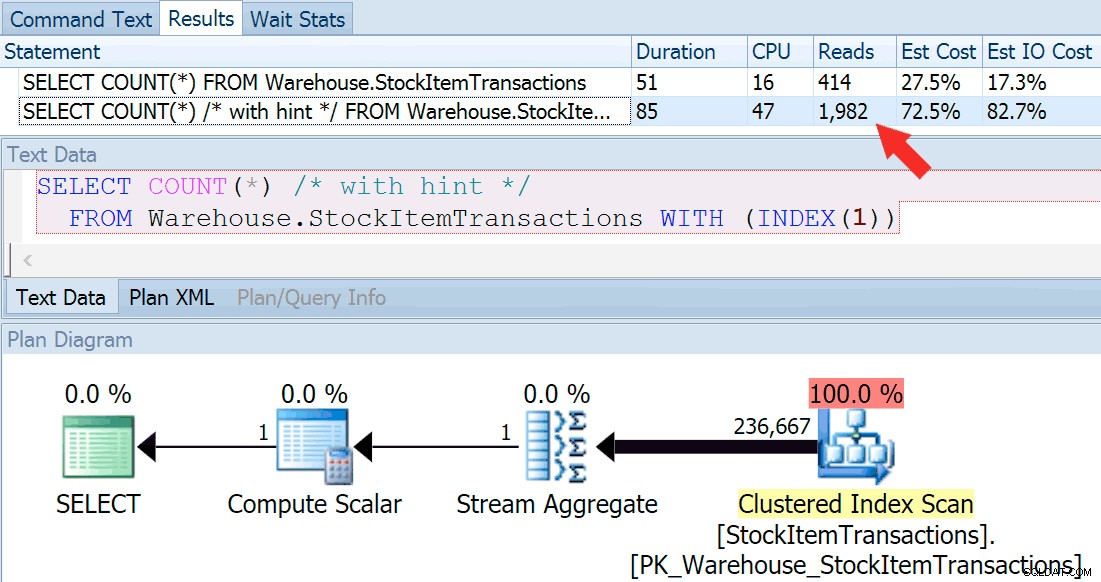
Thời lượng cao hơn một chút đối với chỉ mục được phân cụm, nhưng sự khác biệt là không đáng kể khi chúng tôi đang xử lý một lượng nhỏ dữ liệu được lưu trong bộ nhớ cache trên đĩa nhanh. Sự khác biệt đó sẽ rõ ràng hơn nhiều khi có nhiều dữ liệu hơn, trên đĩa chậm hoặc trên hệ thống có áp lực bộ nhớ.
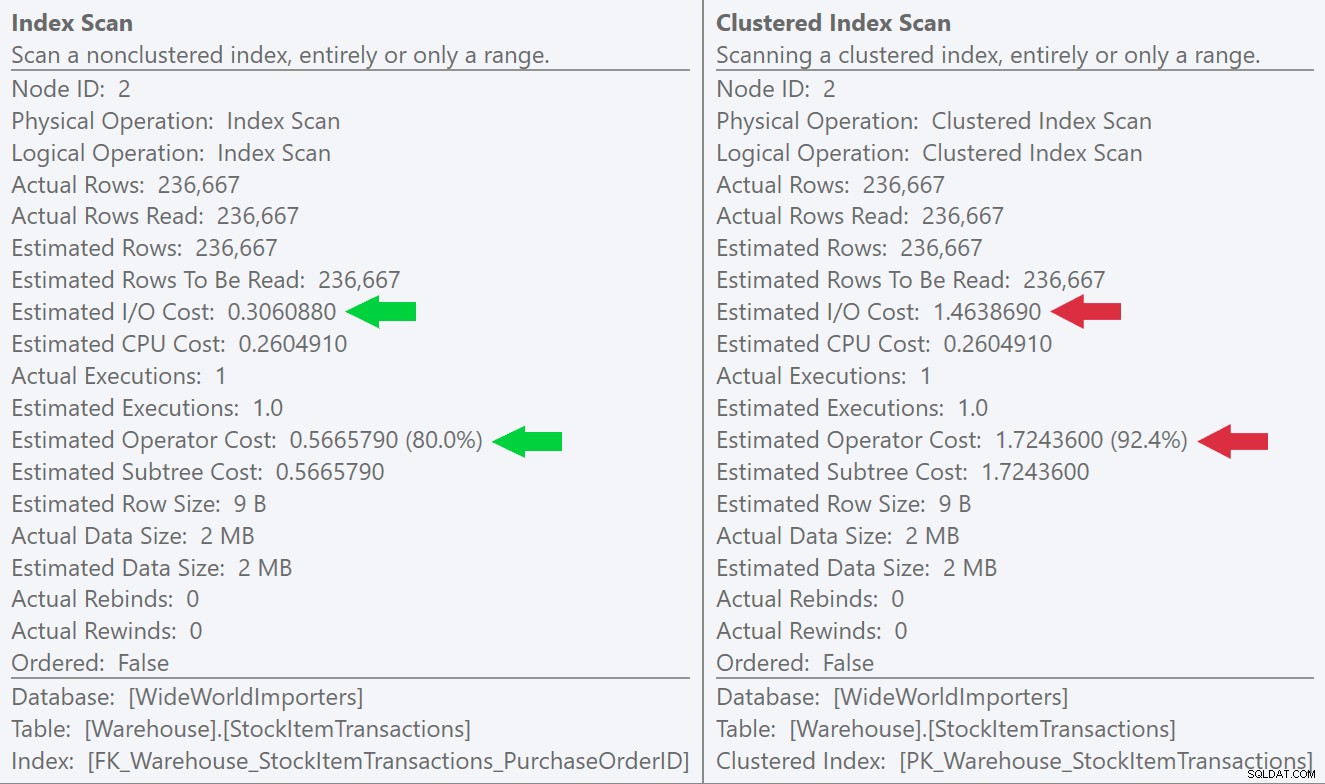
Nếu chúng ta nhìn vào chú giải công cụ cho các hoạt động quét, chúng ta có thể thấy rằng mặc dù số hàng và chi phí CPU ước tính giống hệt nhau, nhưng sự khác biệt lớn đến từ chi phí I / O ước tính (vì SQL Server biết rằng có nhiều trang hơn trong chỉ mục được phân nhóm hơn chỉ mục không được phân cụm):
Chúng ta có thể thấy sự khác biệt này rõ ràng hơn nữa nếu chúng ta tạo một chỉ mục mới, duy nhất trên chỉ cột ID (làm cho nó trở nên "thừa" với chỉ mục được phân nhóm, phải không?):
CREATE UNIQUE INDEX NewUniqueNCIIndex ON Warehouse.StockItemTransactions(StockItemTransactionID);
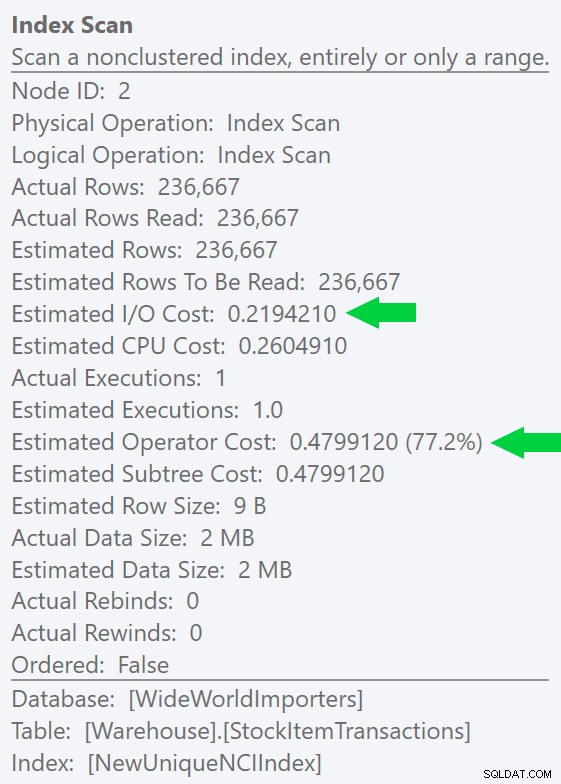 Chạy một truy vấn tương tự với gợi ý chỉ mục rõ ràng sẽ tạo ra cùng một hình dạng kế hoạch nhưng I / O ước tính thậm chí còn thấp hơn chi phí (và thậm chí thời lượng thấp hơn) - xem hình ảnh ở bên phải. Và nếu bạn chạy truy vấn ban đầu mà không có gợi ý, bạn sẽ thấy rằng SQL Server hiện cũng chọn chỉ mục này.
Chạy một truy vấn tương tự với gợi ý chỉ mục rõ ràng sẽ tạo ra cùng một hình dạng kế hoạch nhưng I / O ước tính thậm chí còn thấp hơn chi phí (và thậm chí thời lượng thấp hơn) - xem hình ảnh ở bên phải. Và nếu bạn chạy truy vấn ban đầu mà không có gợi ý, bạn sẽ thấy rằng SQL Server hiện cũng chọn chỉ mục này.
Nó có vẻ hiển nhiên, nhưng rất nhiều người sẽ tin rằng chỉ mục theo nhóm là lựa chọn tốt nhất ở đây. SQL Server hầu như luôn ưu tiên cho bất kỳ phương pháp nào cung cấp cách rẻ nhất để thực hiện tất cả các I / O và trong trường hợp quét toàn bộ, đó sẽ là chỉ mục "gầy nhất". Điều này cũng có thể xảy ra với cả hai loại tìm kiếm (quét đơn lẻ và quét phạm vi), ít nhất là khi chỉ mục đang bao phủ.
Bây giờ, như mọi khi, điều đó không theo bất kỳ cách nào có nghĩa là bạn nên tạo chỉ mục bổ sung trên tất cả các bảng của mình để đáp ứng các truy vấn đếm. Đó không chỉ là một cách không hiệu quả để kiểm tra kích thước bảng (xem lại bài viết này), mà một chỉ mục để hỗ trợ sẽ phải có nghĩa là bạn đang chạy truy vấn đó thường xuyên hơn so với việc cập nhật dữ liệu. Hãy nhớ rằng mọi chỉ mục đều yêu cầu dung lượng trên đĩa, dung lượng trên bộ nhớ và tất cả các lần ghi vào bảng cũng phải chạm vào mọi chỉ mục (sang một bên chỉ mục đã lọc).
Tóm tắt
Tôi có thể đưa ra nhiều ví dụ khác cho thấy khi nào một không phân cụm có thể hữu ích và đáng để bảo trì, ngay cả khi sao chép (các) cột chính của chỉ mục được phân nhóm. Chỉ mục không phân cụm có thể được tạo với cùng một cột chính nhưng theo thứ tự khóa khác nhau hoặc với ASC / DESC khác nhau trên chính các cột để hỗ trợ tốt hơn thứ tự bản trình bày thay thế. Bạn cũng có thể có các chỉ mục không phân cụm chỉ mang một tập hợp con nhỏ của các hàng thông qua việc sử dụng bộ lọc. Cuối cùng, nếu bạn có thể đáp ứng các truy vấn phổ biến nhất của mình với các chỉ mục gọn gàng hơn, không phân cụm, điều đó cũng tốt hơn cho việc tiêu thụ bộ nhớ.
Nhưng thực sự, quan điểm của tôi về loạt bài này chỉ là đưa ra một ví dụ phản chứng minh họa cho sự điên rồ khi đưa ra những tuyên bố chung chung như thế này. Tôi sẽ để lại cho bạn lời giải thích từ Paul White, người, trong một câu trả lời DBA.SE, giải thích tại sao một chỉ mục không phân cụm như vậy trên thực tế có thể hoạt động tốt hơn nhiều so với một chỉ mục được phân nhóm. Điều này đúng ngay cả khi cả hai đều sử dụng một trong hai loại tìm kiếm:
- Sự khác biệt giữa tìm kiếm chỉ mục theo nhóm và tìm kiếm chỉ mục không phân cụm



