Việc ghép hai hoặc nhiều tập dữ liệu thường được thể hiện nhiều nhất trong T-SQL bằng cách sử dụng UNION ALL mệnh đề. Do trình tối ưu hóa SQL Server thường có thể sắp xếp lại những thứ như nối và tổng hợp để cải thiện hiệu suất, nên khá hợp lý khi mong đợi rằng SQL Server cũng sẽ xem xét sắp xếp lại thứ tự đầu vào nối, nơi điều này sẽ mang lại lợi thế. Ví dụ:trình tối ưu hóa có thể xem xét các lợi ích của việc viết lại A UNION ALL B dưới dạng B UNION ALL A .
Trên thực tế, trình tối ưu hóa SQL Server không làm cái này. Chính xác hơn, có một số hỗ trợ hạn chế cho việc sắp xếp lại thứ tự đầu vào nối trong các bản phát hành SQL Server lên đến 2008 R2, nhưng điều này đã được loại bỏ trong SQL Server 2012 và đã không xuất hiện trở lại kể từ đó.
SQL Server 2008 R2
Về mặt trực quan, thứ tự của các đầu vào nối chỉ quan trọng nếu có mục tiêu hàng . Theo mặc định, SQL Server tối ưu hóa kế hoạch thực thi trên cơ sở tất cả các hàng đủ điều kiện sẽ được trả lại cho máy khách. Khi mục tiêu hàng có hiệu lực, trình tối ưu hóa cố gắng tìm một kế hoạch thực thi sẽ tạo ra một vài hàng đầu tiên một cách nhanh chóng.
Mục tiêu hàng có thể được đặt theo một số cách, ví dụ:sử dụng TOP , một FAST n gợi ý truy vấn hoặc bằng cách sử dụng EXISTS (bản chất của nó cần phải tìm nhiều nhất một hàng). Trong trường hợp không có mục tiêu hàng (tức là khách hàng yêu cầu tất cả các hàng), thông thường không quan trọng thứ tự các đầu vào nối được đọc:Mỗi đầu vào sẽ được xử lý đầy đủ cuối cùng trong mọi trường hợp.
Hỗ trợ giới hạn trong các phiên bản lên đến SQL Server 2008 R2 áp dụng khi có mục tiêu là chính xác một hàng . Trong trường hợp cụ thể này, SQL Server sẽ sắp xếp lại thứ tự các đầu vào nối trên cơ sở chi phí dự kiến.
Điều này không được thực hiện trong quá trình tối ưu hóa dựa trên chi phí (như người ta có thể mong đợi), mà là bản viết lại sau tối ưu hóa vào phút cuối của kết quả đầu ra của trình tối ưu hóa thông thường. Cách sắp xếp này có ưu điểm là không làm tăng không gian tìm kiếm kế hoạch dựa trên chi phí (có thể là một giải pháp thay thế cho mỗi lần sắp xếp lại có thể), trong khi vẫn tạo ra một kế hoạch được tối ưu hóa để trả về hàng đầu tiên một cách nhanh chóng.
Ví dụ
Các ví dụ sau sử dụng hai bảng có nội dung giống hệt nhau:Một triệu hàng số nguyên từ một đến một triệu. Một bảng là một đống không có chỉ mục không phân biệt; cái kia có một chỉ mục nhóm duy nhất:
CREATE TABLE dbo.Expensive
(
Val bigint NOT NULL
);
CREATE TABLE dbo.Cheap
(
Val bigint NOT NULL,
CONSTRAINT [PK dbo.Cheap Val]
UNIQUE CLUSTERED (Val)
);
GO
INSERT dbo.Cheap WITH (TABLOCKX)
(Val)
SELECT TOP (1000000)
Val = ROW_NUMBER() OVER (ORDER BY SV1.number)
FROM master.dbo.spt_values AS SV1
CROSS JOIN master.dbo.spt_values AS SV2
ORDER BY
Val
OPTION (MAXDOP 1);
GO
INSERT dbo.Expensive WITH (TABLOCKX)
(Val)
SELECT
C.Val
FROM dbo.Cheap AS C
OPTION (MAXDOP 1); Không có Mục tiêu Hàng
Truy vấn sau đây tìm kiếm các hàng giống nhau trong mỗi bảng và trả về nối của hai tập hợp:
SELECT E.Val
FROM dbo.Expensive AS E
WHERE
E.Val BETWEEN 751000 AND 751005
UNION ALL
SELECT C.Val
FROM dbo.Cheap AS C
WHERE
C.Val BETWEEN 751000 AND 751005; Kế hoạch thực thi do trình tối ưu hóa truy vấn tạo ra là:
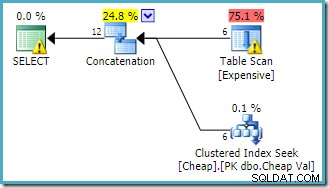
Cảnh báo trên SELECT gốc toán tử đang cảnh báo chúng ta về chỉ mục bị thiếu rõ ràng trên bảng heap. Cảnh báo trên toán tử Table Scan được Sentry One Plan Explorer thêm vào. Nó đang thu hút sự chú ý của chúng tôi đến chi phí I / O của vị từ còn lại ẩn trong quá trình quét.
Thứ tự của các đầu vào cho Ghép nối không quan trọng ở đây, bởi vì chúng tôi không đặt mục tiêu hàng. Cả hai đầu vào sẽ được đọc đầy đủ để trả về tất cả các hàng kết quả. Quan tâm (mặc dù điều này không được đảm bảo) lưu ý rằng thứ tự của các đầu vào tuân theo thứ tự văn bản của truy vấn ban đầu. Cũng lưu ý rằng thứ tự của các hàng kết quả cuối cùng cũng không được chỉ định, vì chúng tôi không sử dụng ORDER BY cấp cao nhất mệnh đề. Chúng tôi sẽ cho rằng đó là sự cố ý và thứ tự cuối cùng là không quan trọng đối với nhiệm vụ đang thực hiện.
Nếu chúng ta đảo ngược thứ tự đã viết của các bảng trong truy vấn như sau:
SELECT C.Val
FROM dbo.Cheap AS C
WHERE
C.Val BETWEEN 751000 AND 751005
UNION ALL
SELECT E.Val
FROM dbo.Expensive AS E
WHERE
E.Val BETWEEN 751000 AND 751005; Kế hoạch thực thi theo sau sự thay đổi, truy cập bảng được phân nhóm trước (một lần nữa, điều này không được đảm bảo):
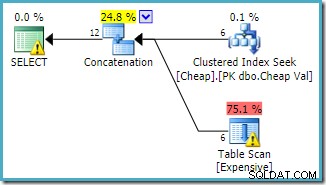
Cả hai truy vấn có thể được mong đợi có các đặc tính hiệu suất giống nhau, vì chúng thực hiện các hoạt động giống nhau, chỉ theo một thứ tự khác nhau.
Với Mục tiêu Hàng
Rõ ràng, việc thiếu lập chỉ mục trên bảng heap thường sẽ làm cho việc tìm kiếm các hàng cụ thể đắt hơn, so với thao tác tương tự trên bảng nhóm. Nếu chúng tôi yêu cầu trình tối ưu hóa một kế hoạch trả về hàng đầu tiên một cách nhanh chóng, chúng tôi hy vọng SQL Server sẽ sắp xếp lại thứ tự các đầu vào nối để bảng phân cụm giá rẻ được tham khảo trước.
Sử dụng truy vấn đề cập đến bảng heap trước và sử dụng gợi ý truy vấn NHANH 1 để chỉ định mục tiêu hàng:
SELECT E.Val
FROM dbo.Expensive AS E
WHERE
E.Val BETWEEN 751000 AND 751005
UNION ALL
SELECT C.Val
FROM dbo.Cheap AS C
WHERE
C.Val BETWEEN 751000 AND 751005
OPTION (FAST 1); Kế hoạch thực thi ước tính được tạo trên một phiên bản của SQL Server 2008 R2 là:
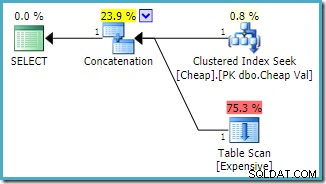
Lưu ý rằng các đầu vào nối đã được sắp xếp lại để giảm chi phí ước tính của việc trả lại hàng đầu tiên. Cũng lưu ý rằng chỉ mục bị thiếu và các cảnh báo I / O còn lại đã biến mất. Không có vấn đề gì xảy ra với hình dạng kế hoạch này khi mục tiêu là trả về một hàng càng nhanh càng tốt.
Truy vấn tương tự được thực thi trên SQL Server 2016 (sử dụng một trong hai mô hình ước lượng bản số) là:
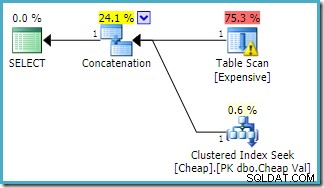
SQL Server 2016 chưa sắp xếp lại thứ tự các đầu vào nối. Cảnh báo I / O của Plan Explorer đã trở lại, nhưng đáng buồn là lần này trình tối ưu hóa đã không đưa ra cảnh báo chỉ mục bị thiếu (mặc dù nó có liên quan).
Sắp xếp lại thứ tự chung
Như đã đề cập, việc viết lại sau tối ưu hóa sắp xếp lại các đầu vào nối chỉ có hiệu quả đối với:
- SQL Server 2008 R2 trở về trước
- Mục tiêu hàng có chính xác một mục tiêu
Nếu chúng tôi thực sự chỉ muốn một hàng được trả về, thay vì một kế hoạch được tối ưu hóa để trả về hàng đầu tiên một cách nhanh chóng (nhưng cuối cùng vẫn trả về tất cả các hàng), chúng tôi có thể sử dụng TOP mệnh đề với bảng dẫn xuất hoặc biểu thức bảng chung (CTE):
SELECT TOP (1)
UA.Val
FROM
(
SELECT E.Val
FROM dbo.Expensive AS E
WHERE
E.Val BETWEEN 751000 AND 751005
UNION ALL
SELECT C.Val
FROM dbo.Cheap AS C
WHERE
C.Val BETWEEN 751000 AND 751005
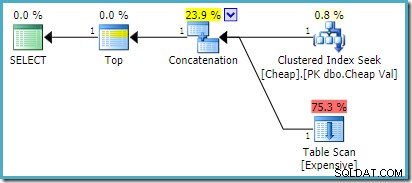
) AS UA; Trên SQL Server 2008 R2 trở xuống, điều này tạo ra kế hoạch đầu vào được sắp xếp lại thứ tự tối ưu:
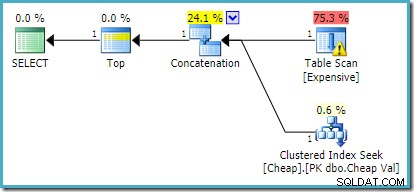
Trên SQL Server 2012, 2014 và 2016 không xảy ra việc sắp xếp lại thứ tự sau tối ưu hóa:
Nếu chúng ta muốn trả về nhiều hơn một hàng, ví dụ:sử dụng TOP (2) , cách viết lại mong muốn sẽ không được áp dụng trên SQL Server 2008 R2 ngay cả khi FAST 1 gợi ý cũng được sử dụng. Trong tình huống đó, chúng ta cần dùng đến các thủ thuật như sử dụng TOP với một biến và một OPTIMIZE FOR gợi ý:
DECLARE @TopRows bigint = 2; -- Number of rows actually needed
SELECT TOP (@TopRows)
UA.Val
FROM
(
SELECT E.Val
FROM dbo.Expensive AS E
WHERE
E.Val BETWEEN 751000 AND 751005
UNION ALL
SELECT C.Val
FROM dbo.Cheap AS C
WHERE
C.Val BETWEEN 751000 AND 751005
) AS UA
OPTION (OPTIMIZE FOR (@TopRows = 1)); -- Just a hint Gợi ý truy vấn đủ để đặt mục tiêu hàng là một, trong khi giá trị thời gian chạy của biến đảm bảo trả về số hàng (2) mong muốn.
Kế hoạch thực thi thực tế trên SQL Server 2008 R2 là:
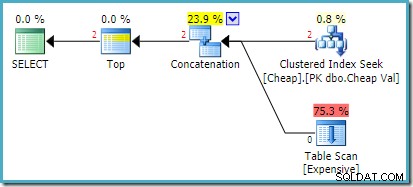
Cả hai hàng được trả về đều đến từ đầu vào tìm kiếm được sắp xếp lại và quá trình Quét bảng không được thực hiện. Plan Explorer hiển thị số lượng hàng bằng màu đỏ vì ước tính dành cho một hàng (do gợi ý) trong khi gặp hai hàng tại thời điểm chạy.
KHÔNG CÓ CÔNG ĐOÀN TẤT CẢ
Vấn đề này cũng không giới hạn ở các truy vấn được viết rõ ràng bằng UNION ALL . Các cấu trúc khác như EXISTS và OR cũng có thể dẫn đến việc trình tối ưu hóa giới thiệu một toán tử nối, có thể bị thiếu sắp xếp lại đầu vào. Có một câu hỏi gần đây về Quản trị viên Cơ sở dữ liệu Stack Exchange với chính xác vấn đề này. Chuyển đổi truy vấn từ câu hỏi đó sang sử dụng các bảng mẫu của chúng tôi:
SELECT
CASE
WHEN
EXISTS
(
SELECT 1
FROM dbo.Expensive AS E
WHERE E.Val BETWEEN 751000 AND 751005
)
OR EXISTS
(
SELECT 1
FROM dbo.Cheap AS C
WHERE C.Val BETWEEN 751000 AND 751005
)
THEN 1
ELSE 0
END; Kế hoạch thực thi trên SQL Server 2016 có bảng heap ở đầu vào đầu tiên:
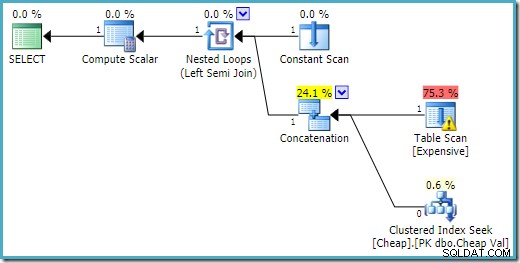
Trên SQL Server 2008 R2, thứ tự của các đầu vào được tối ưu hóa để phản ánh mục tiêu hàng đơn của phép nối bán phần:
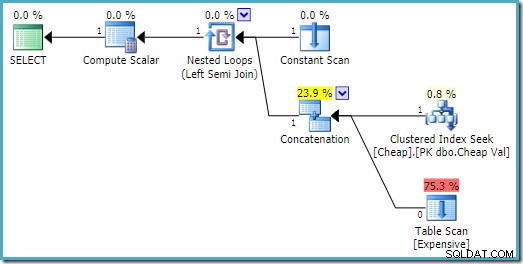
Trong phương án tối ưu hơn, quá trình quét đống không bao giờ được thực hiện.
Giải pháp thay thế
Trong một số trường hợp, người viết truy vấn sẽ thấy rõ rằng một trong các đầu vào nối sẽ luôn chạy rẻ hơn các đầu vào khác. Nếu điều đó là đúng, việc viết lại truy vấn là hoàn toàn hợp lệ để các đầu vào nối rẻ hơn xuất hiện đầu tiên theo thứ tự đã viết. Tất nhiên, điều này có nghĩa là người viết truy vấn cần phải biết về giới hạn của trình tối ưu hóa này và chuẩn bị để dựa vào hành vi không có giấy tờ.
Một vấn đề khó khăn hơn nảy sinh khi chi phí của các đầu vào nối thay đổi theo từng trường hợp, có lẽ tùy thuộc vào các giá trị tham số. Sử dụng OPTION (RECOMPILE) sẽ không trợ giúp trên SQL Server 2012 trở lên. Tùy chọn đó có thể hỗ trợ trên SQL Server 2008 R2 hoặc phiên bản cũ hơn, nhưng chỉ khi yêu cầu mục tiêu hàng đơn cũng được đáp ứng.
Nếu có lo ngại về việc dựa vào hành vi được quan sát (đầu vào nối kế hoạch truy vấn khớp với thứ tự văn bản truy vấn), hướng dẫn kế hoạch có thể được sử dụng để buộc hình dạng kế hoạch. Khi các đơn đặt hàng đầu vào khác nhau là tối ưu cho các trường hợp khác nhau, có thể sử dụng nhiều hướng dẫn kế hoạch, trong đó các điều kiện có thể được mã hóa trước một cách chính xác. Tuy nhiên, điều này hầu như không lý tưởng.
Lời kết
Trên thực tế, trình tối ưu hóa truy vấn SQL Server chứa dựa trên chi phí quy tắc thăm dò, UNIAReorderInputs , có khả năng tạo ra các biến thể thứ tự đầu vào nối và khám phá các lựa chọn thay thế trong quá trình tối ưu hóa dựa trên chi phí (không phải như một lần viết lại sau khi tối ưu hóa một lần).
Quy tắc này hiện không được kích hoạt để sử dụng chung. Theo như tôi có thể nói, nó chỉ được kích hoạt khi có hướng dẫn gói hoặc USE PLAN gợi ý là hiện tại. Điều này cho phép công cụ buộc thành công một kế hoạch đã được tạo cho một truy vấn đủ điều kiện để ghi lại thứ tự đầu vào, ngay cả khi truy vấn hiện tại không đủ điều kiện.
Cảm nhận của tôi là quy tắc thăm dò này được cố ý giới hạn cho việc sử dụng này, bởi vì các truy vấn sẽ được hưởng lợi từ việc sắp xếp lại thứ tự đầu vào nối như một phần của tối ưu hóa dựa trên chi phí được coi là không đủ phổ biến hoặc có lẽ vì lo ngại rằng nỗ lực bổ sung sẽ không trả được tắt. Quan điểm của riêng tôi là việc sắp xếp lại thứ tự đầu vào của toán tử Kết nối phải luôn được khám phá khi mục tiêu hàng có hiệu lực.
Cũng đáng tiếc là việc viết lại sau tối ưu hóa (hạn chế hơn) không hiệu quả trong SQL Server 2012 trở lên. Điều này có thể là do một lỗi nhỏ, nhưng tôi không thể tìm thấy bất cứ điều gì về điều này trong tài liệu, cơ sở kiến thức hoặc trên Connect. Tôi đã thêm một mục Kết nối mới ở đây.
Cập nhật ngày 9 tháng 8 năm 2017 :Điều này hiện đã được sửa chữa dưới cờ theo dõi 4199 cho SQL Server 2014 và 2016, hãy xem KB 4023419:
Khắc phục:Truy vấn với UNION ALL và mục tiêu hàng có thể chạy chậm hơn trong SQL Server 2014 hoặc các phiên bản mới hơn khi so sánh với SQL Server 2008 R2