Loại bỏ và ngăn chặn phân mảnh chỉ mục từ lâu đã trở thành một phần của hoạt động bảo trì cơ sở dữ liệu thông thường, không chỉ trong SQL Server mà trên nhiều nền tảng. Phân mảnh chỉ mục ảnh hưởng đến hiệu suất vì nhiều lý do và hầu hết mọi người đều nói về tác động của các khối I / O nhỏ ngẫu nhiên có thể xảy ra về mặt vật lý đối với lưu trữ dựa trên đĩa là điều cần tránh. Mối quan tâm chung xung quanh việc phân mảnh chỉ mục là nó ảnh hưởng đến hiệu suất quét thông qua việc giới hạn kích thước của I / Os đọc trước. Dựa trên sự hiểu biết hạn chế này về các vấn đề mà phân mảnh chỉ mục gây ra mà một số người đã bắt đầu lưu hành ý tưởng rằng phân mảnh chỉ mục không quan trọng với các thiết bị Lưu trữ trạng thái rắn (SSD) và bạn có thể bỏ qua phân mảnh chỉ mục về sau.
Tuy nhiên, đó không phải là trường hợp vì một số lý do. Bài viết này sẽ giải thích và chứng minh một trong những lý do đó:sự phân mảnh chỉ mục có thể tác động bất lợi đến việc lựa chọn kế hoạch thực thi cho các truy vấn. Điều này xảy ra do phân mảnh chỉ mục thường dẫn đến chỉ mục có nhiều trang hơn (các trang bổ sung này đến từ phân chia trang , như được mô tả trong bài đăng này trên trang web này), và do đó, việc sử dụng chỉ mục đó được trình tối ưu hóa truy vấn của SQL Server coi là có chi phí cao hơn.
Hãy xem một ví dụ.
Điều đầu tiên mà chúng ta cần làm là xây dựng một cơ sở dữ liệu thử nghiệm thích hợp và tập dữ liệu để sử dụng cho việc kiểm tra xem sự phân mảnh chỉ mục có thể ảnh hưởng như thế nào đến việc lựa chọn kế hoạch truy vấn trong SQL Server. Tập lệnh sau sẽ tạo cơ sở dữ liệu với hai bảng có dữ liệu giống hệt nhau, một bảng bị phân mảnh mạnh và một bảng bị phân mảnh tối thiểu.
USE master;
GO
DROP DATABASE FragmentationTest;
GO
CREATE DATABASE FragmentationTest;
GO
USE FragmentationTest;
GO
CREATE TABLE GuidHighFragmentation
(
UniqueID UNIQUEIDENTIFIER DEFAULT NEWID() PRIMARY KEY,
FirstName nvarchar(50) NOT NULL,
LastName nvarchar(50) NOT NULL
);
GO
CREATE NONCLUSTERED INDEX IX_GuidHighFragmentation_LastName
ON GuidHighFragmentation(LastName);
GO
CREATE TABLE GuidLowFragmentation
(
UniqueID UNIQUEIDENTIFIER DEFAULT NEWSEQUENTIALID() PRIMARY KEY,
FirstName nvarchar(50) NOT NULL,
LastName nvarchar(50) NOT NULL
);
GO
CREATE NONCLUSTERED INDEX IX_GuidLowFragmentation_LastName
ON GuidLowFragmentation(LastName);
GO
INSERT INTO GuidHighFragmentation (FirstName, LastName)
SELECT TOP 100000 a.name, b.name
FROM master.dbo.spt_values AS a
CROSS JOIN master.dbo.spt_values AS b
WHERE a.name IS NOT NULL
AND b.name IS NOT NULL
ORDER BY NEWID();
GO 70
INSERT INTO GuidLowFragmentation (UniqueID, FirstName, LastName)
SELECT UniqueID, FirstName, LastName
FROM GuidHighFragmentation;
GO
ALTER INDEX ALL ON GuidLowFragmentation REBUILD;
GO Sau khi xây dựng lại chỉ mục, chúng ta có thể xem xét các cấp độ phân mảnh bằng truy vấn sau:
SELECT
OBJECT_NAME(ps.object_id) AS table_name,
i.name AS index_name,
ps.index_id,
ps.index_depth,
avg_fragmentation_in_percent,
fragment_count,
page_count,
avg_page_space_used_in_percent,
record_count
FROM sys.dm_db_index_physical_stats(
DB_ID(),
NULL,
NULL,
NULL,
'DETAILED') AS ps
JOIN sys.indexes AS i
ON ps.object_id = i.object_id
AND ps.index_id = i.index_id
WHERE index_level = 0;
GO Kết quả:

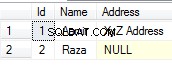
Ở đây, chúng ta có thể thấy rằng GuidHighFragmentation của chúng tôi bảng bị phân mảnh 99% và sử dụng không gian trang nhiều hơn 31% so với GuidLowFragmentation trong cơ sở dữ liệu, mặc dù chúng có cùng 7.000.000 hàng dữ liệu. Nếu chúng tôi thực hiện truy vấn tổng hợp cơ bản đối với từng bảng và so sánh các kế hoạch thực thi trên cài đặt mặc định (với các tùy chọn và giá trị cấu hình mặc định) của SQL Server bằng cách sử dụng SentryOne Plan Explorer:
-- Aggregate the data from both tables SELECT LastName, COUNT(*) FROM GuidLowFragmentation GROUP BY LastName; GO SELECT LastName, COUNT(*) FROM GuidHighFragmentation GROUP BY LastName; GO


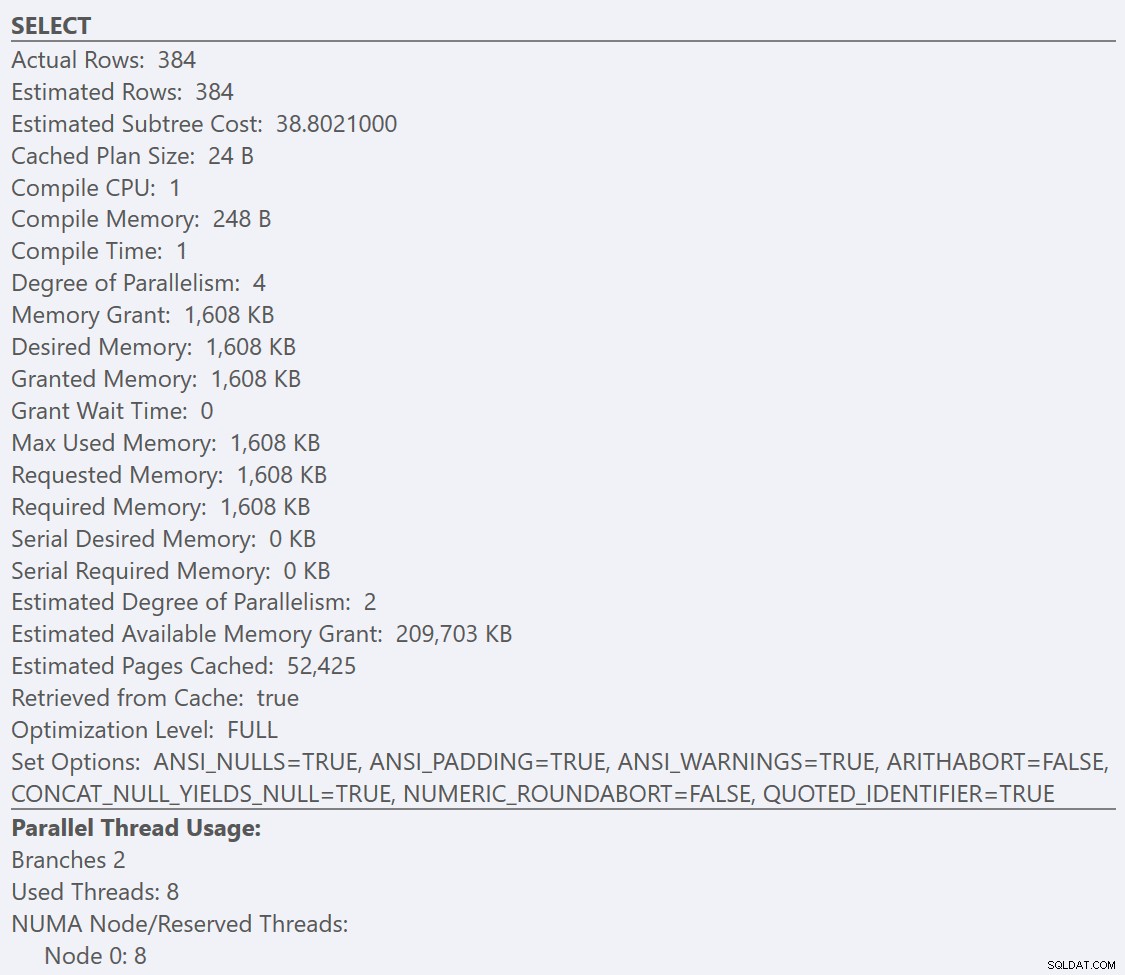

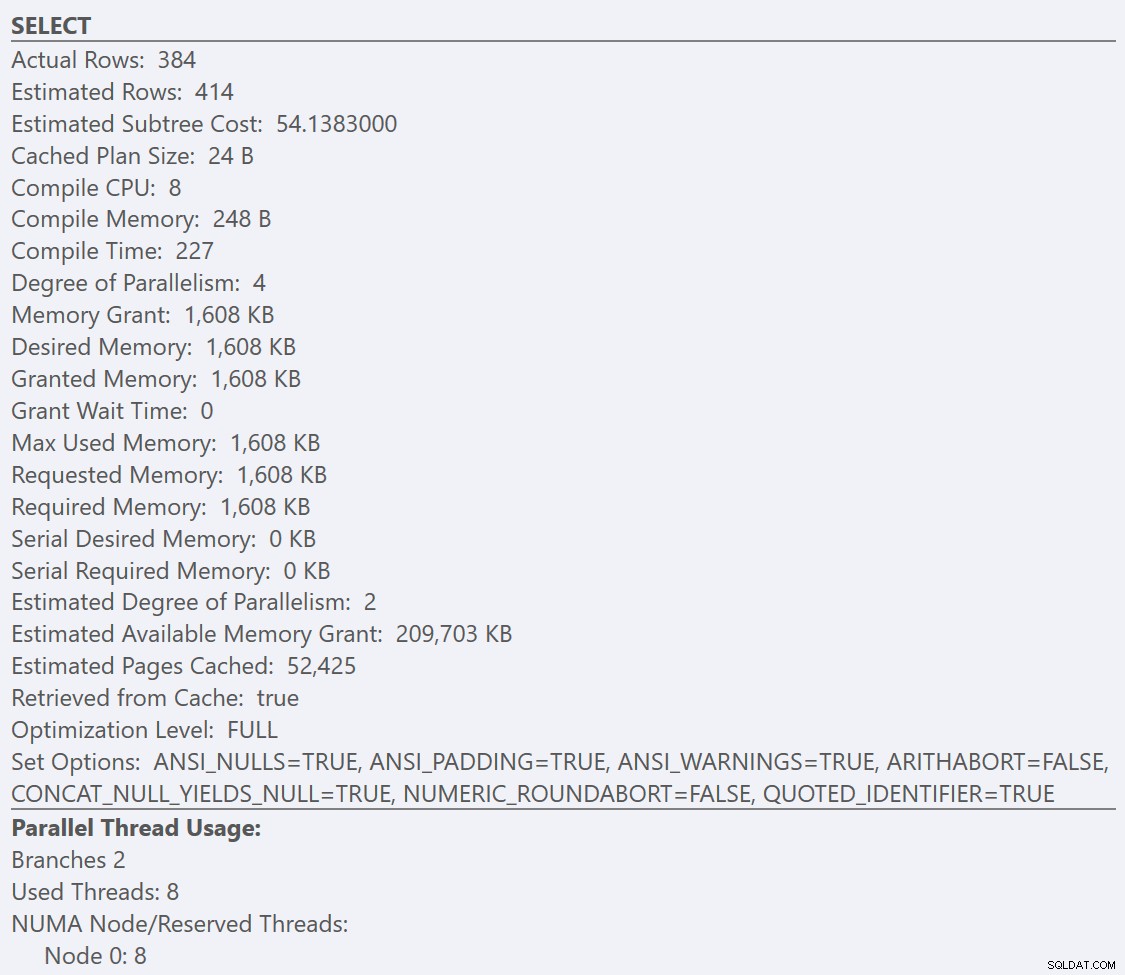
Nếu chúng ta xem xét các chú giải công cụ từ CHỌN cho mỗi kế hoạch, kế hoạch cho GuidLowFragmentation bảng có chi phí truy vấn là 38,80 (dòng thứ ba trở xuống từ đầu chú giải công cụ) so với chi phí truy vấn là 54,14 cho kế hoạch cho kế hoạch GuidHighFragmentation.
Theo cấu hình mặc định cho SQL Server, cả hai truy vấn này đều tạo ra một kế hoạch thực thi song song vì chi phí truy vấn ước tính cao hơn 'ngưỡng chi phí cho song song' tùy chọn sp_configure mặc định là 5. Điều này là do trình tối ưu hóa truy vấn trước tiên tạo ra một chuỗi kế hoạch (chỉ có thể được thực thi bởi một luồng duy nhất) khi biên dịch kế hoạch cho một truy vấn. Nếu chi phí ước tính của gói nối tiếp đó vượt quá giá trị "ngưỡng chi phí cho chế độ song song" đã định cấu hình, thì một gói song song sẽ được tạo và lưu vào bộ nhớ đệm.
Tuy nhiên, điều gì sẽ xảy ra nếu tùy chọn sp_configure 'ngưỡng chi phí cho chế độ song song' không được đặt thành mặc định là 5 và được đặt cao hơn? Cách tốt nhất (và một cách đúng) là tăng tùy chọn này từ mức mặc định thấp là 5 lên bất kỳ đâu từ 25 đến 50 (hoặc thậm chí cao hơn nhiều) để ngăn các truy vấn nhỏ phải chịu thêm chi phí khi thực hiện song song.
EXEC sys.sp_configure N'show advanced options', N'1'; RECONFIGURE; GO EXEC sys.sp_configure N'cost threshold for parallelism', N'50'; RECONFIGURE; GO EXEC sys.sp_configure N'show advanced options', N'0'; RECONFIGURE; GO
Sau khi tuân theo các nguyên tắc về phương pháp hay nhất và tăng 'ngưỡng chi phí cho tính song song' lên 50, việc chạy lại các truy vấn dẫn đến cùng một kế hoạch thực thi cho GuidHighFragmentation nhưng là GuidLowFragmentation truy vấn chi phí nối tiếp, 44,68, hiện thấp hơn giá trị "ngưỡng chi phí cho tính song song" (hãy nhớ chi phí song song ước tính của nó là 38,80), vì vậy chúng tôi nhận được kế hoạch thực hiện nối tiếp:
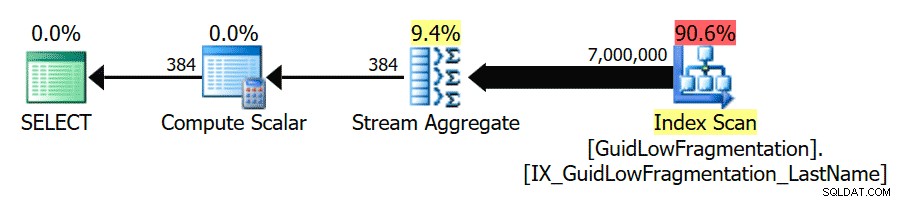
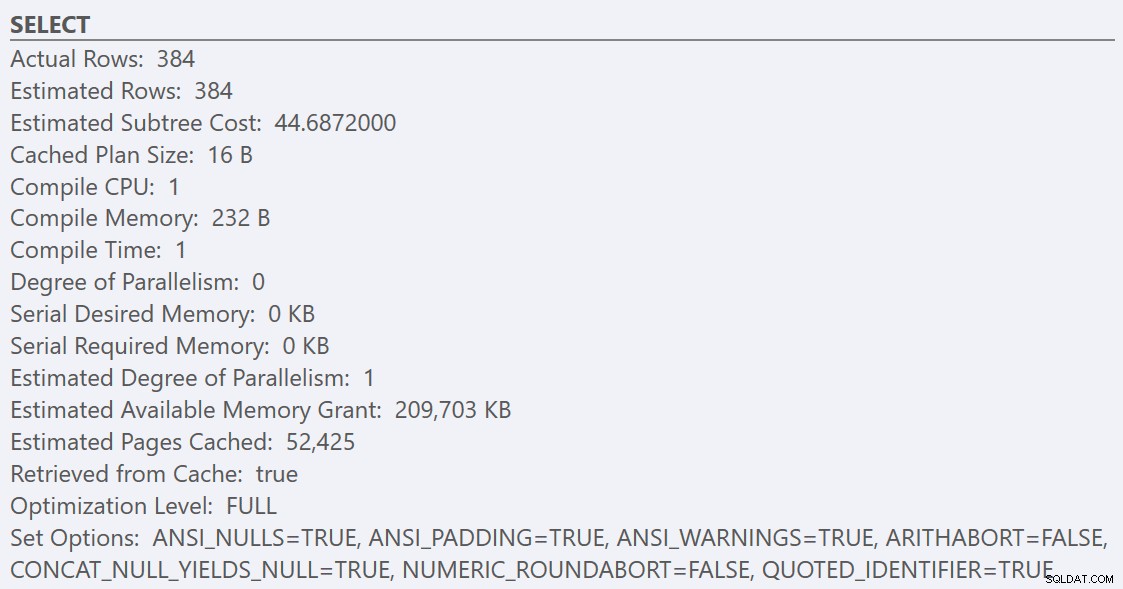
Không gian trang bổ sung trong GuidHighFragmentation chỉ mục nhóm giữ chi phí trên cài đặt phương pháp hay nhất cho "ngưỡng chi phí cho tính song song" và dẫn đến một kế hoạch song song.
Bây giờ hãy tưởng tượng rằng đây là một hệ thống mà bạn đã làm theo hướng dẫn thực tiễn tốt nhất và ban đầu định cấu hình 'ngưỡng chi phí cho tính song song' ở giá trị 50. Sau đó, bạn đã làm theo lời khuyên sai lầm là chỉ bỏ qua hoàn toàn việc phân mảnh chỉ mục.
Thay vì đây là một truy vấn cơ bản, nó phức tạp hơn, nhưng nếu nó cũng được thực thi rất thường xuyên trên hệ thống của bạn và do phân mảnh chỉ mục, số trang tính chi phí so với kế hoạch song song, nó sẽ sử dụng nhiều CPU hơn và kết quả là tác động đến hiệu suất khối lượng công việc tổng thể.
Công việc của bạn là gì? Bạn có tăng 'ngưỡng chi phí cho song song' để truy vấn duy trì kế hoạch thực thi nối tiếp không? Bạn có gợi ý truy vấn với OPTION (MAXDOP 1) và chỉ buộc nó vào một kế hoạch thực thi nối tiếp không?
Hãy nhớ rằng phân mảnh chỉ mục có thể không chỉ ảnh hưởng đến một bảng trong cơ sở dữ liệu của bạn, vì bây giờ bạn đang bỏ qua nó hoàn toàn; có khả năng là nhiều chỉ mục được phân nhóm và không được phân cụm bị phân mảnh và có số lượng trang cao hơn mức cần thiết, do đó, chi phí của nhiều hoạt động I / O đang tăng lên do sự phân mảnh chỉ mục rộng rãi, dẫn đến nhiều truy vấn tiềm ẩn không hiệu quả kế hoạch.
Tóm tắt
Bạn không thể bỏ qua hoàn toàn việc phân mảnh chỉ mục như một số người có thể muốn bạn tin. Trong số những nhược điểm khác của việc làm này, chi phí tích lũy của việc thực thi truy vấn sẽ bắt kịp bạn, với sự thay đổi của kế hoạch truy vấn vì trình tối ưu hóa truy vấn là trình tối ưu hóa dựa trên chi phí và do đó, đúng ra là sử dụng các chỉ mục phân mảnh đó đắt hơn.
Các truy vấn và kịch bản ở đây rõ ràng là có sẵn, nhưng chúng tôi đã thấy những thay đổi về kế hoạch thực thi gây ra bởi sự phân mảnh trong cuộc sống thực trên các hệ thống máy khách.
Bạn cần đảm bảo rằng bạn đang giải quyết sự phân mảnh chỉ mục cho những chỉ mục mà sự phân mảnh gây ra các vấn đề về hiệu suất khối lượng công việc, bất kể bạn đang sử dụng phần cứng nào.