Tháng trước, tôi đã tham gia một thử thách Quần đảo đặc biệt. Nhiệm vụ là xác định các khoảng thời gian hoạt động cho mỗi ID dịch vụ, chấp nhận khoảng cách lên đến một số giây đầu vào (@allowedgap ). Lưu ý là giải pháp phải tương thích trước năm 2012, vì vậy bạn không thể sử dụng các chức năng như LAG và LEAD hoặc tổng hợp các chức năng cửa sổ với một khung. Tôi nhận được một số giải pháp rất thú vị do Toby Ovod-Everett, Peter Larsson và Kamil Kosno đăng trong phần bình luận. Đảm bảo xem qua các giải pháp của họ vì tất cả chúng đều khá sáng tạo.
Thật kỳ lạ, một số giải pháp chạy chậm hơn với chỉ số được đề xuất so với không có nó. Trong bài viết này, tôi đề xuất một lời giải thích cho điều này.
Mặc dù tất cả các giải pháp đều thú vị nhưng ở đây tôi muốn tập trung vào giải pháp của Kamil Kosno, một nhà phát triển ETL của Zopa. Trong giải pháp của mình, Kamil đã sử dụng một kỹ thuật rất sáng tạo để mô phỏng LAG và LEAD mà không cần LAG và LEAD. Bạn có thể sẽ thấy kỹ thuật này hữu ích nếu bạn cần thực hiện các phép tính giống LAG / LEAD bằng cách sử dụng mã tương thích trước năm 2012.
Tại sao một số giải pháp nhanh hơn mà không có chỉ mục được đề xuất?
Xin nhắc lại, tôi đã đề xuất sử dụng chỉ mục sau để hỗ trợ các giải pháp cho thách thức:
CREATE INDEX idx_sid_ltm_lid ON dbo.EventLog(serviceid, logtime, logid);
Giải pháp tương thích trước năm 2012 của tôi như sau:
DECLARE @allowedgap AS INT = 66; -- in seconds
WITH C1 AS
(
SELECT logid, serviceid,
logtime AS s, -- important, 's' > 'e', for later ordering
DATEADD(second, @allowedgap, logtime) AS e,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, logid) AS counteach
FROM dbo.EventLog
),
C2 AS
(
SELECT logid, serviceid, logtime, eventtype, counteach,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, eventtype DESC, logid) AS countboth
FROM C1
UNPIVOT(logtime FOR eventtype IN (s, e)) AS U
),
C3 AS
(
SELECT serviceid, eventtype, logtime,
(ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, eventtype DESC, logid) - 1) / 2 + 1 AS grp
FROM C2
CROSS APPLY ( VALUES( CASE
WHEN eventtype = 's' THEN
counteach - (countboth - counteach)
WHEN eventtype = 'e' THEN
(countboth - counteach) - counteach
END ) ) AS A(countactive)
WHERE (eventtype = 's' AND countactive = 1)
OR (eventtype = 'e' AND countactive = 0)
)
SELECT serviceid, s AS starttime, DATEADD(second, -@allowedgap, e) AS endtime
FROM C3
PIVOT( MAX(logtime) FOR eventtype IN (s, e) ) AS P; Hình 1 có kế hoạch cho giải pháp của tôi với chỉ mục được đề xuất.
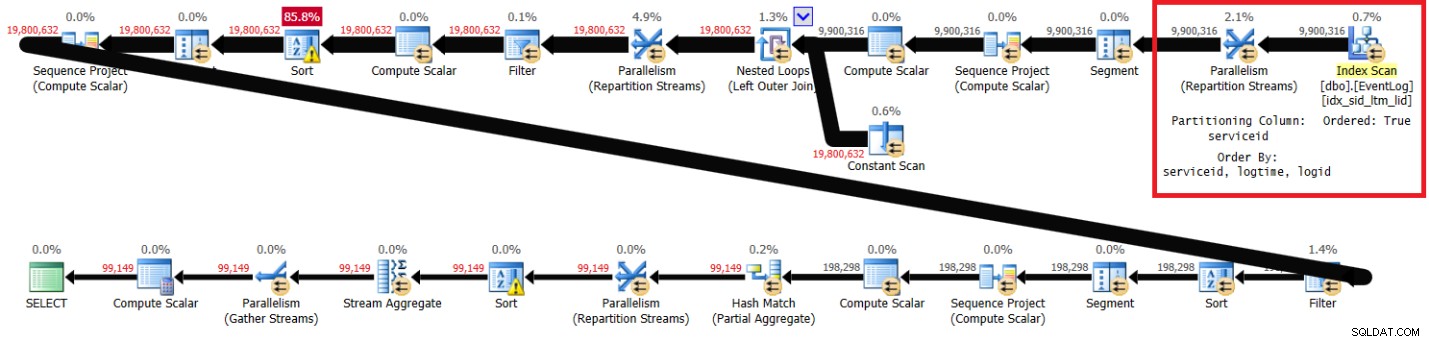 Hình 1:Kế hoạch cho giải pháp của Itzik với chỉ mục được đề xuất
Hình 1:Kế hoạch cho giải pháp của Itzik với chỉ mục được đề xuất
Lưu ý rằng kế hoạch quét chỉ mục được đề xuất theo thứ tự khóa (Thuộc tính có thứ tự là Đúng), phân vùng các luồng theo serviceid bằng cách sử dụng trao đổi bảo toàn thứ tự, sau đó áp dụng tính toán ban đầu của số hàng dựa trên thứ tự chỉ mục mà không cần sắp xếp. Sau đây là thống kê hiệu suất mà tôi nhận được cho việc thực thi truy vấn này trên máy tính xách tay của mình (thời gian đã trôi qua, thời gian CPU và thời gian chờ cao nhất được biểu thị bằng giây):
elapsed: 43, CPU: 60, logical reads: 144,120 , top wait: CXPACKET: 166
Sau đó, tôi đã bỏ chỉ mục được đề xuất và chuyển đổi giải pháp:
DROP INDEX idx_sid_ltm_lid ON dbo.EventLog;
Tôi nhận được kế hoạch được hiển thị trong Hình 2.
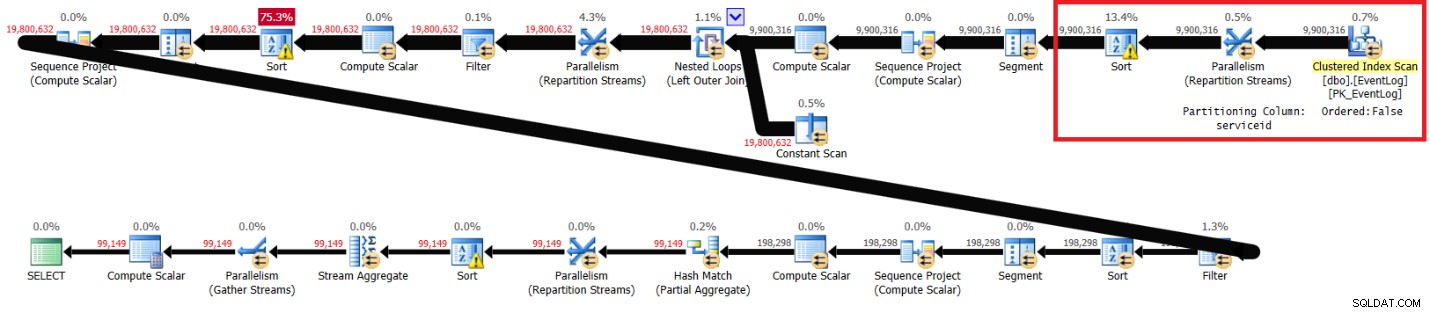 Hình 2:Kế hoạch cho giải pháp của Itzik không có chỉ mục được đề xuất
Hình 2:Kế hoạch cho giải pháp của Itzik không có chỉ mục được đề xuất
Các phần được đánh dấu trong hai kế hoạch cho thấy sự khác biệt. Kế hoạch không có chỉ mục được đề xuất sẽ thực hiện quét không có thứ tự chỉ mục được phân nhóm, phân vùng các luồng theo serviceid bằng cách sử dụng trao đổi không bảo toàn thư mục, sau đó sắp xếp các hàng như chức năng cửa sổ cần (theo serviceid, logtime, logid). Phần còn lại của công việc dường như giống nhau trong cả hai kế hoạch. Bạn sẽ nghĩ rằng kế hoạch không có chỉ mục được đề xuất sẽ chậm hơn vì nó có một loại bổ sung mà kế hoạch khác không có. Nhưng đây là thống kê hiệu suất mà tôi nhận được cho gói này trên máy tính xách tay của mình:
elapsed: 31, CPU: 89, logical reads: 172,598 , CXPACKET waits: 84
Có nhiều thời gian CPU hơn, một phần là do sắp xếp bổ sung; có nhiều I / O tham gia hơn, có thể là do sự cố tràn phân loại bổ sung; tuy nhiên, thời gian trôi qua nhanh hơn khoảng 30 phần trăm. Điều gì có thể giải thích điều này? Một cách để thử và tìm ra điều này là chạy truy vấn trong SSMS với tùy chọn Thống kê truy vấn trực tiếp được bật. Khi tôi làm điều này, toán tử Song song (Dòng phân vùng lại) ngoài cùng bên phải đã hoàn thành trong 6 giây mà không có chỉ mục được đề xuất và trong 35 giây với chỉ mục được đề xuất. Sự khác biệt chính là cái trước lấy dữ liệu được sắp xếp trước từ một chỉ mục và là một trao đổi bảo toàn đơn đặt hàng. Loại thứ hai lấy dữ liệu không có thứ tự và không phải là một trao đổi duy trì trật tự. Các sàn giao dịch bảo quản đơn đặt hàng có xu hướng đắt hơn các sàn giao dịch không đặt hàng. Ngoài ra, ít nhất ở phần ngoài cùng bên phải của kế hoạch cho đến lần sắp xếp đầu tiên, phần trước phân phối các hàng theo thứ tự như cột phân vùng trao đổi, vì vậy bạn không nhận được tất cả các chuỗi để thực sự xử lý các hàng song song. Càng về sau, phân phối các hàng không có thứ tự, vì vậy bạn có được tất cả các luồng xử lý các hàng thực sự song song. Bạn có thể thấy rằng thời gian chờ hàng đầu trong cả hai kế hoạch là CXPACKET, nhưng trong trường hợp trước thì thời gian chờ gấp đôi thời gian chờ sau, cho bạn biết rằng xử lý song song trong trường hợp sau là tối ưu hơn. Có thể có một số yếu tố khác xảy ra mà tôi không nghĩ đến. Nếu bạn có thêm ý tưởng có thể giải thích sự khác biệt đáng ngạc nhiên về hiệu suất, vui lòng chia sẻ.
Trên máy tính xách tay của tôi, điều này dẫn đến việc thực thi không có chỉ mục được đề xuất nhanh hơn so với máy có chỉ mục được đề xuất. Tuy nhiên, trên một máy thử nghiệm khác, nó lại diễn ra theo cách khác. Rốt cuộc, bạn có một loại bổ sung, với tiềm năng lan tỏa.
Vì tò mò, tôi đã thử nghiệm thực thi nối tiếp (với tùy chọn MAXDOP 1) với chỉ mục được đề xuất tại chỗ và nhận được số liệu thống kê hiệu suất sau trên máy tính xách tay của tôi:
elapsed: 42, CPU: 40, logical reads: 143,519
Như bạn có thể thấy, thời gian chạy tương tự như thời gian chạy của quá trình thực thi song song với chỉ mục được đề xuất tại chỗ. Tôi chỉ có 4 CPU logic trong máy tính xách tay của mình. Tất nhiên, số dặm của bạn có thể thay đổi với các phần cứng khác nhau. Vấn đề là, bạn nên thử nghiệm các lựa chọn thay thế khác nhau, bao gồm cả có và không có lập chỉ mục mà bạn cho rằng sẽ hữu ích. Kết quả đôi khi gây ngạc nhiên và phản trực giác.
Giải pháp của Kamil
Tôi thực sự bị hấp dẫn bởi giải pháp của Kamil và đặc biệt thích cách anh ấy mô phỏng LAG và LEAD bằng một kỹ thuật tương thích trước năm 2012.
Đây là mã triển khai bước đầu tiên trong giải pháp:
SELECT serviceid, logtime, ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) AS end_time, ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) - 1 AS start_time FROM dbo.EventLog;
Mã này tạo ra kết quả sau (chỉ hiển thị dữ liệu cho serviceid 1):
serviceid logtime end_time start_time ---------- -------------------- --------- ----------- 1 2018-09-12 08:00:00 1 0 1 2018-09-12 08:01:01 2 1 1 2018-09-12 08:01:59 3 2 1 2018-09-12 08:03:00 4 3 1 2018-09-12 08:05:00 5 4 1 2018-09-12 08:06:02 6 5 ...
Bước này tính toán hai số hàng cách nhau một số cho mỗi hàng, được phân vùng theo serviceid và được sắp xếp theo thời gian đăng nhập. Số hàng hiện tại đại diện cho thời gian kết thúc (gọi nó là end_time) và số hàng hiện tại trừ đi một số đại diện cho thời gian bắt đầu (gọi nó là start_time).
Đoạn mã sau thực hiện bước thứ hai của giải pháp:
WITH RNS AS
(
SELECT
serviceid,
logtime,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) AS end_time,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) - 1 AS start_time
FROM dbo.EventLog
)
SELECT *
FROM RNS
UNPIVOT(rownum FOR time_type IN (start_time, end_time)) AS U; Bước này tạo ra kết quả sau:
serviceid logtime rownum time_type ---------- -------------------- ------- ----------- 1 2018-09-12 08:00:00 0 start_time 1 2018-09-12 08:00:00 1 end_time 1 2018-09-12 08:01:01 1 start_time 1 2018-09-12 08:01:01 2 end_time 1 2018-09-12 08:01:59 2 start_time 1 2018-09-12 08:01:59 3 end_time 1 2018-09-12 08:03:00 3 start_time 1 2018-09-12 08:03:00 4 end_time 1 2018-09-12 08:05:00 4 start_time 1 2018-09-12 08:05:00 5 end_time 1 2018-09-12 08:06:02 5 start_time 1 2018-09-12 08:06:02 6 end_time ...
Bước này bỏ chia từng hàng thành hai hàng, sao chép từng mục nhập nhật ký — một lần cho loại thời gian start_time và một lần nữa cho end_time. Như bạn có thể thấy, ngoài số hàng tối thiểu và tối đa, mỗi số hàng xuất hiện hai lần — một lần với thời gian ghi của sự kiện hiện tại (start_time) và một lần với thời gian ghi của sự kiện trước đó (end_time).
Đoạn mã sau thực hiện bước thứ ba trong giải pháp:
WITH RNS AS
(
SELECT
serviceid,
logtime,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) AS end_time,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) - 1 AS start_time
FROM dbo.EventLog
)
SELECT *
FROM RNS
UNPIVOT(rownum FOR time_type IN (start_time, end_time)) AS U
PIVOT(MAX(logtime) FOR time_type IN(start_time, end_time)) AS P; Mã này tạo ra kết quả sau:
serviceid rownum start_time end_time ----------- -------------------- --------------------------- --------------------------- 1 0 2018-09-12 08:00:00 NULL 1 1 2018-09-12 08:01:01 2018-09-12 08:00:00 1 2 2018-09-12 08:01:59 2018-09-12 08:01:01 1 3 2018-09-12 08:03:00 2018-09-12 08:01:59 1 4 2018-09-12 08:05:00 2018-09-12 08:03:00 1 5 2018-09-12 08:06:02 2018-09-12 08:05:00 1 6 NULL 2018-09-12 08:06:02 ...
Bước này xoay vòng dữ liệu, nhóm các cặp hàng có cùng số hàng và trả về một cột cho thời gian ghi nhật ký sự kiện hiện tại (start_time) và một cột khác cho thời gian ghi nhật ký sự kiện trước đó (end_time). Phần này mô phỏng một cách hiệu quả chức năng LAG.
Đoạn mã sau thực hiện bước thứ tư trong giải pháp:
DECLARE @allowedgap AS INT = 66;
WITH RNS AS
(
SELECT
serviceid,
logtime,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) AS end_time,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) - 1 AS start_time
FROM dbo.EventLog
)
SELECT serviceid, rownum, start_time, end_time,
ROW_NUMBER() OVER (ORDER BY serviceid,rownum) AS start_time_grp,
ROW_NUMBER() OVER (ORDER BY serviceid,rownum) -1 AS end_time_grp
FROM RNS
UNPIVOT(rownum FOR time_type IN (start_time, end_time)) AS U
PIVOT(MAX(logtime) FOR time_type IN(start_time, end_time)) AS P
WHERE ISNULL(DATEDIFF(second, end_time, start_time), @allowedgap + 1) > @allowedgap; Mã này tạo ra kết quả sau:
serviceid rownum start_time end_time start_time_grp end_time_grp ---------- ------- -------------------- -------------------- --------------- ------------- 1 0 2018-09-12 08:00:00 NULL 1 0 1 4 2018-09-12 08:05:00 2018-09-12 08:03:00 2 1 1 6 NULL 2018-09-12 08:06:02 3 2 ...
Bước này lọc các cặp trong đó chênh lệch giữa thời gian kết thúc trước đó và thời gian bắt đầu hiện tại lớn hơn khoảng cách cho phép và các hàng chỉ có một sự kiện. Bây giờ, bạn cần kết nối thời gian bắt đầu của mỗi hàng hiện tại với thời gian kết thúc của hàng tiếp theo. Điều này yêu cầu một phép tính giống như LEAD. Để đạt được điều này, một lần nữa, mã tạo các số hàng cách nhau một, chỉ lần này số hàng hiện tại đại diện cho thời gian bắt đầu (start_time_grp) và số hàng hiện tại trừ đi một số đại diện cho thời gian kết thúc (end_time_grp).
Giống như trước đây, bước tiếp theo (số 5) là bỏ chia các hàng. Đây là mã triển khai bước này:
DECLARE @allowedgap AS INT = 66;
WITH RNS AS
(
SELECT
serviceid,
logtime,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) AS end_time,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) - 1 AS start_time
FROM dbo.EventLog
),
Ranges as
(
SELECT serviceid, rownum, start_time, end_time,
ROW_NUMBER() OVER (ORDER BY serviceid,rownum) AS start_time_grp,
ROW_NUMBER() OVER (ORDER BY serviceid,rownum) -1 AS end_time_grp
FROM RNS
UNPIVOT(rownum FOR time_type IN (start_time, end_time)) AS U
PIVOT(MAX(logtime) FOR time_type IN(start_time, end_time)) AS P
WHERE ISNULL(DATEDIFF(second, end_time, start_time), @allowedgap + 1) > @allowedgap
)
SELECT *
FROM Ranges
UNPIVOT(grp FOR grp_type IN(start_time_grp, end_time_grp)) AS U; Đầu ra:
serviceid rownum start_time end_time grp grp_type ---------- ------- -------------------- -------------------- ---- --------------- 1 0 2018-09-12 08:00:00 NULL 0 end_time_grp 1 4 2018-09-12 08:05:00 2018-09-12 08:03:00 1 end_time_grp 1 0 2018-09-12 08:00:00 NULL 1 start_time_grp 1 6 NULL 2018-09-12 08:06:02 2 end_time_grp 1 4 2018-09-12 08:05:00 2018-09-12 08:03:00 2 start_time_grp 1 6 NULL 2018-09-12 08:06:02 3 start_time_grp ...
Như bạn có thể thấy, cột grp là duy nhất cho mỗi hòn đảo trong ID dịch vụ.
Bước 6 là bước cuối cùng trong giải pháp. Đây là mã triển khai bước này, cũng là mã giải pháp hoàn chỉnh:
DECLARE @allowedgap AS INT = 66;
WITH RNS AS
(
SELECT
serviceid,
logtime,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) AS end_time,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) - 1 AS start_time
FROM dbo.EventLog
),
Ranges as
(
SELECT serviceid, rownum, start_time, end_time,
ROW_NUMBER() OVER (ORDER BY serviceid,rownum) AS start_time_grp,
ROW_NUMBER() OVER (ORDER BY serviceid,rownum) -1 AS end_time_grp
FROM RNS
UNPIVOT(rownum FOR time_type IN (start_time, end_time)) AS U
PIVOT(MAX(logtime) FOR time_type IN(start_time, end_time)) AS P
WHERE ISNULL(DATEDIFF(second, end_time, start_time), @allowedgap + 1) > @allowedgap
)
SELECT
serviceid, MIN(start_time) AS start_time, MAX(end_time) AS end_time
FROM Ranges
UNPIVOT(grp FOR grp_type IN(start_time_grp, end_time_grp)) AS U
GROUP BY serviceid, grp
HAVING (MIN(start_time) IS NOT NULL AND MAX(end_time) IS NOT NULL); Bước này tạo ra kết quả sau:
serviceid start_time end_time ----------- --------------------------- --------------------------- 1 2018-09-12 08:00:00 2018-09-12 08:03:00 1 2018-09-12 08:05:00 2018-09-12 08:06:02 ...
Bước này nhóm các hàng theo serviceid và grp, chỉ lọc các nhóm có liên quan và trả về start_time tối thiểu khi bắt đầu đảo và thời gian kết thúc tối đa là cuối đảo.
Hình 3 có kế hoạch mà tôi nhận được cho giải pháp này với chỉ mục được đề xuất tại chỗ:
CREATE INDEX idx_sid_ltm_lid ON dbo.EventLog(serviceid, logtime, logid);
Lập kế hoạch với chỉ số được đề xuất trong Hình 3.
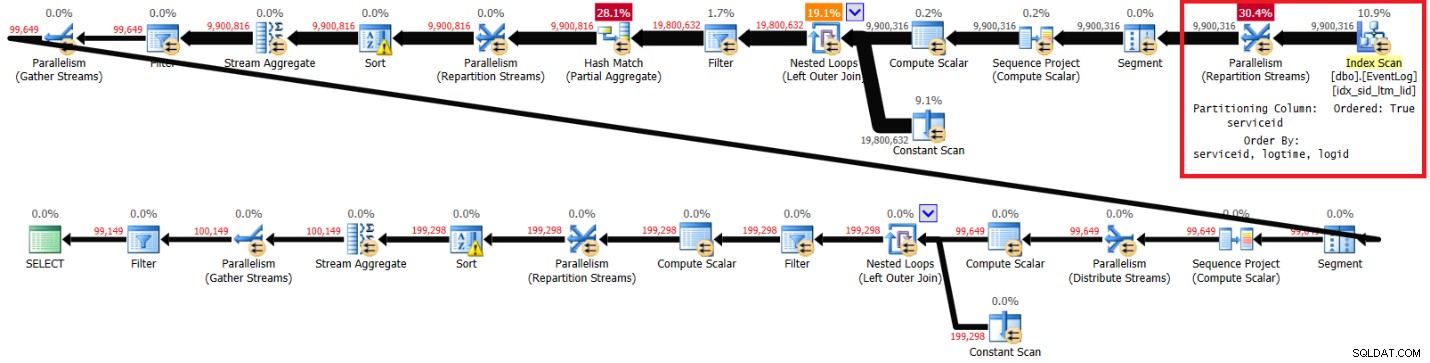 Hình 3:Kế hoạch cho giải pháp của Kamil với chỉ số được đề xuất
Hình 3:Kế hoạch cho giải pháp của Kamil với chỉ số được đề xuất
Dưới đây là thống kê hiệu suất mà tôi nhận được cho lần thực thi này trên máy tính xách tay của mình:
elapsed: 44, CPU: 66, logical reads: 72979, top wait: CXPACKET: 148
Sau đó, tôi đã bỏ chỉ mục được đề xuất và chuyển đổi giải pháp:
DROP INDEX idx_sid_ltm_lid ON dbo.EventLog;
Tôi nhận được kế hoạch được hiển thị trong Hình 4 để thực hiện mà không có chỉ mục được đề xuất.
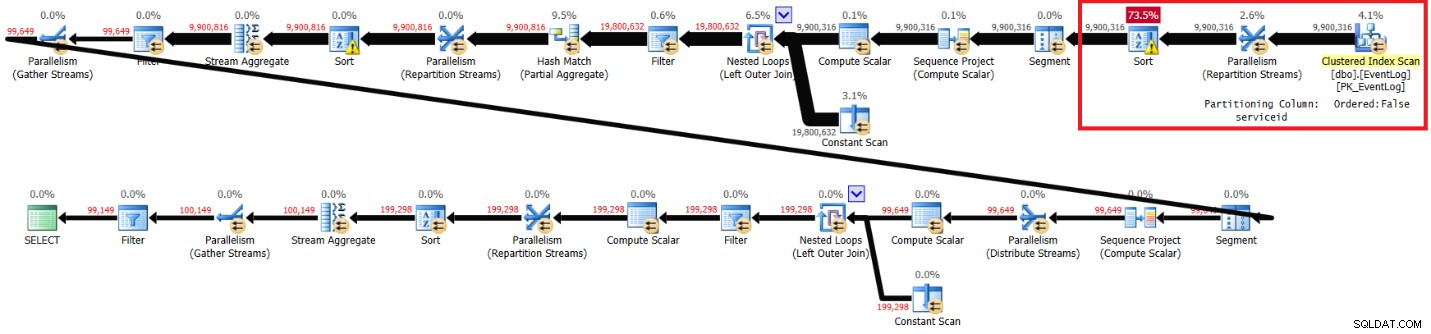 Hình 4:Kế hoạch cho giải pháp của Kamil không có chỉ mục được đề xuất
Hình 4:Kế hoạch cho giải pháp của Kamil không có chỉ mục được đề xuất
Dưới đây là thống kê hiệu suất mà tôi nhận được cho lần thực thi này:
elapsed: 30, CPU: 85, logical reads: 94813, top wait: CXPACKET: 70
Thời gian chạy, thời gian CPU và thời gian chờ CXPACKET rất giống với giải pháp của tôi, mặc dù số lần đọc logic thấp hơn. Giải pháp của Kamil cũng chạy nhanh hơn trên máy tính xách tay của tôi mà không có chỉ mục được đề xuất và có vẻ như đó là do những lý do tương tự.
Kết luận
Dị thường là một điều tốt. Chúng khiến bạn tò mò và khiến bạn phải đi nghiên cứu nguyên nhân gốc rễ của vấn đề, và kết quả là, học hỏi những điều mới. Thật thú vị khi thấy rằng một số truy vấn, trên một số máy nhất định, chạy nhanh hơn mà không cần lập chỉ mục được khuyến nghị.
Một lần nữa, cảm ơn Toby, Peter và Kamil vì các giải pháp của bạn. Trong bài viết này, tôi đề cập đến giải pháp của Kamil, với kỹ thuật sáng tạo của anh ấy để mô phỏng LAG và LEAD với số hàng, bỏ chia và xoay vòng. Bạn sẽ thấy kỹ thuật này hữu ích khi cần các phép tính giống LAG và LEAD phải được hỗ trợ trên các môi trường trước năm 2012.