Giống như bất kỳ ngôn ngữ lập trình nào, T-SQL cũng có những lỗi và cạm bẫy phổ biến, một số lỗi gây ra kết quả không chính xác và những lỗi khác gây ra các vấn đề về hiệu suất. Trong nhiều trường hợp đó, có những phương pháp hay nhất có thể giúp bạn tránh gặp rắc rối. Tôi đã khảo sát các MVP Nền tảng dữ liệu của Microsoft hỏi về các lỗi và cạm bẫy mà họ thường thấy hoặc họ chỉ thấy là đặc biệt thú vị và các phương pháp hay nhất mà họ sử dụng để tránh những lỗi đó. Tôi có rất nhiều trường hợp thú vị.
Rất cảm ơn Erland Sommarskog, Aaron Bertrand, Alejandro Mesa, Umachandar Jayachandran (UC), Fabiano Neves Amorim, Milos Radivojevic, Simon Sabin, Adam Machanic, Thomas Grohser và Chan Ming Man đã chia sẻ kiến thức và kinh nghiệm của bạn!
Bài viết này là bài đầu tiên trong một loạt bài về chủ đề này. Mỗi bài viết tập trung vào một chủ đề nhất định. Tháng này, tôi tập trung vào các lỗi, cạm bẫy và các phương pháp hay nhất liên quan đến thuyết xác định. Một phép tính xác định là một phép tính được đảm bảo tạo ra các kết quả có thể lặp lại với các đầu vào giống nhau. Có rất nhiều lỗi và cạm bẫy là kết quả của việc sử dụng các phép tính không xác định. Trong bài viết này, tôi đề cập đến ý nghĩa của việc sử dụng thứ tự không xác định, hàm không xác định, nhiều tham chiếu đến biểu thức bảng với phép tính không xác định và việc sử dụng biểu thức CASE và hàm NULLIF với phép tính không xác định.
Tôi sử dụng cơ sở dữ liệu mẫu TSQLV5 trong nhiều ví dụ trong loạt bài này.
Thứ tự không xác định
Một nguồn phổ biến cho các lỗi trong T-SQL là sử dụng thứ tự không xác định. Đó là, khi thứ tự theo danh sách của bạn không xác định duy nhất một hàng. Đó có thể là thứ tự bản trình bày, thứ tự TOP / OFFSET-FETCH hoặc thứ tự cửa sổ.
Lấy ví dụ một kịch bản phân trang cổ điển bằng cách sử dụng bộ lọc TẮT-FETCH. Bạn cần truy vấn bảng Sales.Orders trả lại một trang gồm 10 hàng cùng một lúc, được sắp xếp theo ngày đặt hàng, giảm dần (gần đây nhất trước). Tôi sẽ sử dụng các hằng số cho các phần tử bù đắp và tìm nạp để đơn giản hóa, nhưng thông thường chúng là các biểu thức dựa trên các tham số đầu vào.
Truy vấn sau (gọi là Truy vấn 1) trả về trang đầu tiên của 10 đơn đặt hàng gần đây nhất:
USE TSQLV5; SELECT orderid, orderdate, custid FROM Sales.Orders ORDER BY orderdate DESC OFFSET 0 ROWS FETCH NEXT 10 ROWS ONLY;
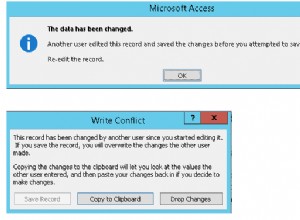
Kế hoạch cho Truy vấn 1 được thể hiện trong Hình 1.
 Hình 1:Kế hoạch cho truy vấn 1
Hình 1:Kế hoạch cho truy vấn 1
Truy vấn sắp xếp thứ tự các hàng theo ngày đặt hàng, giảm dần. Cột ngày đặt hàng không xác định duy nhất một hàng. Thứ tự không xác định này có nghĩa là về mặt khái niệm, không có ưu tiên nào giữa các hàng có cùng ngày. Trong trường hợp ràng buộc, điều quyết định hàng SQL Server sẽ thích hơn là những thứ như lựa chọn kế hoạch và bố cục dữ liệu vật lý — không phải thứ mà bạn có thể dựa vào là có thể lặp lại. Kế hoạch trong Hình 1 quét chỉ mục vào ngày đặt hàng được sắp xếp ngược lại. Điều này xảy ra là bảng này có một chỉ mục nhóm trên orderid và trong một bảng nhóm, khóa chỉ mục nhóm được sử dụng như một bộ định vị hàng trong các chỉ mục không phân nhóm. Nó thực sự được định vị ngầm là phần tử quan trọng cuối cùng trong tất cả các chỉ mục không phân biệt mặc dù về mặt lý thuyết, SQL Server có thể đã đặt nó trong chỉ mục dưới dạng một cột được bao gồm. Vì vậy, mặc nhiên, chỉ mục không phân tán trên orderdate thực sự được xác định trên (orderdate, orderid). Do đó, trong quá trình quét ngược chỉ mục theo thứ tự của chúng tôi, giữa các hàng được ràng buộc dựa trên ngày thứ tự, một hàng có giá trị thứ tự cao hơn được truy cập trước một hàng có giá trị thứ tự thấp hơn. Truy vấn này tạo ra kết quả sau:
orderid orderdate custid ----------- ---------- ----------- 11077 2019-05-06 65 11076 2019-05-06 9 11075 2019-05-06 68 11074 2019-05-06 73 11073 2019-05-05 58 11072 2019-05-05 20 11071 2019-05-05 46 11070 2019-05-05 44 11069 2019-05-04 80 *** 11068 2019-05-04 62
Tiếp theo, sử dụng truy vấn sau (gọi là Truy vấn 2) để lấy trang thứ hai gồm 10 hàng:
SELECT orderid, orderdate, custid FROM Sales.Orders ORDER BY orderdate DESC OFFSET 10 ROWS FETCH NEXT 10 ROWS ONLY;
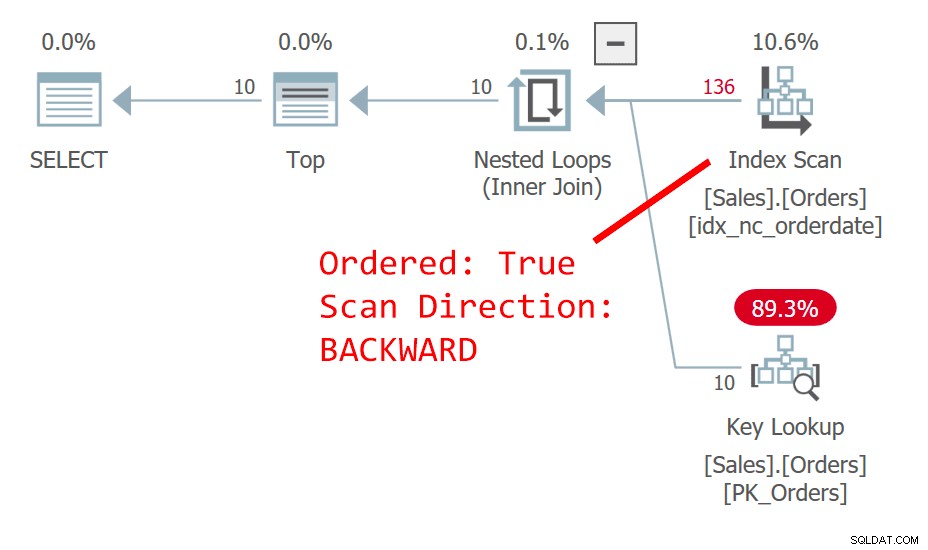
Kế hoạch cho Truy vấn được thể hiện trong Hình 2.
Hình 2:Kế hoạch cho truy vấn 2
Trình tối ưu hóa chọn một kế hoạch khác — một kế hoạch quét chỉ mục được nhóm theo kiểu không có thứ tự và sử dụng Sắp xếp TopN để hỗ trợ yêu cầu của toán tử Hàng đầu để xử lý bộ lọc tìm nạp bù đắp. Lý do cho sự thay đổi là kế hoạch trong Hình 1 sử dụng chỉ mục không bao phủ không phân biệt và trang bạn ở càng xa thì càng cần phải tra cứu nhiều hơn. Với yêu cầu trang thứ hai, bạn đã vượt qua điểm giới hạn biện minh cho việc sử dụng chỉ mục không che phủ.
Mặc dù quá trình quét chỉ mục theo cụm, được định nghĩa với orderid là khóa, là một bản không có thứ tự, công cụ lưu trữ sử dụng quét thứ tự chỉ mục trong nội bộ. Điều này liên quan đến kích thước của chỉ mục. Lên đến 64 trang, công cụ lưu trữ thường thích quét theo thứ tự chỉ mục hơn quét theo thứ tự phân bổ. Ngay cả khi chỉ mục lớn hơn, dưới mức cô lập đã cam kết đọc và dữ liệu không được đánh dấu là chỉ đọc, công cụ lưu trữ sử dụng quét thứ tự chỉ mục để tránh đọc hai lần và bỏ qua các hàng do chia tách trang xảy ra trong quá trình quét. Trên thực tế, trong các điều kiện đã cho, giữa các hàng có cùng ngày, kế hoạch này truy cập vào một hàng có thứ tự thấp hơn trước một hàng có thứ tự cao hơn.
Truy vấn này tạo ra kết quả sau:
orderid orderdate custid ----------- ---------- ----------- 11069 2019-05-04 80 *** 11064 2019-05-01 71 11065 2019-05-01 46 11066 2019-05-01 89 11060 2019-04-30 27 11061 2019-04-30 32 11062 2019-04-30 66 11063 2019-04-30 37 11057 2019-04-29 53 11058 2019-04-29 6
Hãy quan sát rằng ngay cả khi dữ liệu cơ bản không thay đổi, bạn vẫn nhận được cùng một đơn hàng (với ID đơn hàng 11069) được trả về ở cả trang đầu tiên và trang thứ hai!
Hy vọng rằng, thực hành tốt nhất ở đây là rõ ràng. Thêm một tiebreaker vào đơn đặt hàng của bạn theo danh sách để có được một thứ tự xác định. Ví dụ:sắp xếp theo thứ tự giảm dần, thứ tự giảm dần.
Hãy thử yêu cầu lại trang đầu tiên, lần này với thứ tự xác định:
SELECT orderid, orderdate, custid FROM Sales.Orders ORDER BY orderdate DESC, orderid DESC OFFSET 0 ROWS FETCH NEXT 10 ROWS ONLY;
Bạn nhận được kết quả đầu ra sau đây, được đảm bảo:
orderid orderdate custid ----------- ---------- ----------- 11077 2019-05-06 65 11076 2019-05-06 9 11075 2019-05-06 68 11074 2019-05-06 73 11073 2019-05-05 58 11072 2019-05-05 20 11071 2019-05-05 46 11070 2019-05-05 44 11069 2019-05-04 80 11068 2019-05-04 62
Yêu cầu trang thứ hai:
SELECT orderid, orderdate, custid FROM Sales.Orders ORDER BY orderdate DESC, orderid DESC OFFSET 10 ROWS FETCH NEXT 10 ROWS ONLY;
Bạn nhận được kết quả đầu ra sau đây, được đảm bảo:
orderid orderdate custid ----------- ---------- ----------- 11067 2019-05-04 17 11066 2019-05-01 89 11065 2019-05-01 46 11064 2019-05-01 71 11063 2019-04-30 37 11062 2019-04-30 66 11061 2019-04-30 32 11060 2019-04-30 27 11059 2019-04-29 67 11058 2019-04-29 6
Miễn là không có thay đổi nào trong dữ liệu cơ bản, bạn được đảm bảo nhận được các trang liên tiếp mà không có sự lặp lại hoặc bỏ qua hàng giữa các trang.
Theo cách tương tự, sử dụng các hàm cửa sổ như ROW_NUMBER với thứ tự không xác định, bạn có thể nhận được các kết quả khác nhau cho cùng một truy vấn tùy thuộc vào hình dạng kế hoạch và thứ tự truy cập thực tế giữa các mối quan hệ. Hãy xem xét truy vấn sau (gọi nó là Truy vấn 3), thực hiện yêu cầu trang đầu tiên bằng cách sử dụng số hàng (buộc sử dụng chỉ mục vào ngày đặt hàng cho mục đích minh họa):
WITH C AS
(
SELECT orderid, orderdate, custid,
ROW_NUMBER() OVER(ORDER BY orderdate DESC) AS n
FROM Sales.Orders WITH (INDEX(idx_nc_orderdate))
)
SELECT orderid, orderdate, custid
FROM C
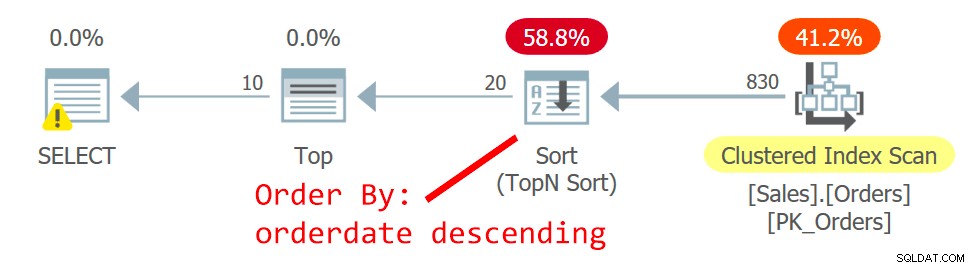
WHERE n BETWEEN 1 AND 10; Kế hoạch cho truy vấn này được thể hiện trong Hình 3:
Hình 3:Kế hoạch cho truy vấn 3
Bạn có các điều kiện rất giống ở đây với các điều kiện tôi đã mô tả trước đó cho Truy vấn 1 với kế hoạch của nó được hiển thị trước đó trong Hình 1. Giữa các hàng có mối quan hệ trong giá trị ngày thứ tự, kế hoạch này truy cập một hàng có giá trị thứ tự cao hơn trước một hàng có giá trị thấp hơn giá trị orderid. Truy vấn này tạo ra kết quả sau:
orderid orderdate custid ----------- ---------- ----------- 11077 2019-05-06 65 11076 2019-05-06 9 11075 2019-05-06 68 11074 2019-05-06 73 11073 2019-05-05 58 11072 2019-05-05 20 11071 2019-05-05 46 11070 2019-05-05 44 11069 2019-05-04 80 *** 11068 2019-05-04 62
Tiếp theo, chạy lại truy vấn (gọi là Truy vấn 4), yêu cầu trang đầu tiên, chỉ lần này buộc sử dụng chỉ mục được phân nhóm PK_Orders:
WITH C AS
(
SELECT orderid, orderdate, custid,
ROW_NUMBER() OVER(ORDER BY orderdate DESC) AS n
FROM Sales.Orders WITH (INDEX(PK_Orders))
)
SELECT orderid, orderdate, custid
FROM C
WHERE n BETWEEN 1 AND 10; Kế hoạch cho truy vấn này được thể hiện trong Hình 4.

Hình 4:Kế hoạch cho truy vấn 4
Lần này, bạn có các điều kiện rất giống với các điều kiện tôi đã mô tả trước đó cho Truy vấn 2 với kế hoạch của nó được hiển thị trước đó trong Hình 2. Giữa các hàng có mối ràng buộc trong giá trị ngày thứ tự, kế hoạch này truy cập một hàng có giá trị thứ tự thấp hơn trước một hàng có giá trị giá trị orderid cao hơn. Truy vấn này tạo ra kết quả sau:
orderid orderdate custid ----------- ---------- ----------- 11074 2019-05-06 73 11075 2019-05-06 68 11076 2019-05-06 9 11077 2019-05-06 65 11070 2019-05-05 44 11071 2019-05-05 46 11072 2019-05-05 20 11073 2019-05-05 58 11067 2019-05-04 17 *** 11068 2019-05-04 62
Quan sát rằng hai lần thực thi tạo ra các kết quả khác nhau mặc dù không có gì thay đổi trong dữ liệu cơ bản.
Một lần nữa, phương pháp hay nhất ở đây rất đơn giản — sử dụng thứ tự xác định bằng cách thêm dấu buộc, như sau:
WITH C AS
(
SELECT orderid, orderdate, custid,
ROW_NUMBER() OVER(ORDER BY orderdate DESC, orderid DESC) AS n
FROM Sales.Orders
)
SELECT orderid, orderdate, custid
FROM C
WHERE n BETWEEN 1 AND 10; Truy vấn này tạo ra kết quả sau:
orderid orderdate custid ----------- ---------- ----------- 11077 2019-05-06 65 11076 2019-05-06 9 11075 2019-05-06 68 11074 2019-05-06 73 11073 2019-05-05 58 11072 2019-05-05 20 11071 2019-05-05 46 11070 2019-05-05 44 11069 2019-05-04 80 11068 2019-05-04 62
Tập hợp trả về được đảm bảo có thể lặp lại bất kể hình dạng kế hoạch.
Có lẽ điều đáng nói là vì truy vấn này không có thứ tự trình bày theo mệnh đề trong truy vấn bên ngoài, nên không có thứ tự trình bày được đảm bảo nào ở đây. Nếu bạn cần một bảo đảm như vậy, bạn phải thêm một thứ tự xuất trình theo từng điều khoản, như sau:
WITH C AS
(
SELECT orderid, orderdate, custid,
ROW_NUMBER() OVER(ORDER BY orderdate DESC, orderid DESC) AS n
FROM Sales.Orders
)
SELECT orderid, orderdate, custid
FROM C
WHERE n BETWEEN 1 AND 10
ORDER BY n; Các hàm không xác định
Một hàm không xác định là một hàm cung cấp các đầu vào giống nhau, có thể trả về các kết quả khác nhau trong các lần thực thi khác nhau của hàm. Các ví dụ cổ điển là SYSDATETIME, NEWID và RAND (khi được gọi mà không có hạt đầu vào). Hành vi của các hàm không xác định trong T-SQL có thể gây ngạc nhiên cho một số người và có thể dẫn đến lỗi và cạm bẫy trong một số trường hợp.
Nhiều người giả định rằng khi bạn gọi một hàm không xác định như một phần của truy vấn, hàm sẽ được đánh giá riêng biệt trên mỗi hàng. Trong thực tế, hầu hết các hàm không xác định được đánh giá một lần cho mỗi tham chiếu trong truy vấn. Hãy xem xét truy vấn sau đây làm ví dụ:
SELECT orderid, SYSDATETIME() AS dt, RAND() AS rnd FROM Sales.Orders;
Vì chỉ có một tham chiếu đến mỗi hàm không xác định SYSDATETIME và RAND trong truy vấn, mỗi hàm này chỉ được đánh giá một lần và kết quả của nó được lặp lại trên tất cả các hàng kết quả. Tôi nhận được kết quả sau khi chạy truy vấn này:
orderid dt rnd ----------- --------------------------- ---------------------- 11008 2019-02-04 17:03:07.9229177 0.962042872007464 11019 2019-02-04 17:03:07.9229177 0.962042872007464 11039 2019-02-04 17:03:07.9229177 0.962042872007464 11040 2019-02-04 17:03:07.9229177 0.962042872007464 11045 2019-02-04 17:03:07.9229177 0.962042872007464 11051 2019-02-04 17:03:07.9229177 0.962042872007464 11054 2019-02-04 17:03:07.9229177 0.962042872007464 11058 2019-02-04 17:03:07.9229177 0.962042872007464 11059 2019-02-04 17:03:07.9229177 0.962042872007464 11061 2019-02-04 17:03:07.9229177 0.962042872007464 ...
Ví dụ về việc không hiểu hành vi này có thể dẫn đến lỗi, giả sử rằng bạn cần viết một truy vấn trả về ba đơn đặt hàng ngẫu nhiên từ bảng Sales.Orders. Một nỗ lực ban đầu phổ biến là sử dụng truy vấn TOP với thứ tự dựa trên hàm RAND, nghĩ rằng hàm sẽ được đánh giá riêng biệt trên mỗi hàng, như sau:
SELECT TOP (3) orderid FROM Sales.Orders ORDER BY RAND();
Trong thực tế, hàm chỉ được đánh giá một lần cho toàn bộ truy vấn; do đó, tất cả các hàng đều nhận được cùng một kết quả và việc sắp xếp thứ tự hoàn toàn không bị ảnh hưởng. Trên thực tế, nếu bạn kiểm tra kế hoạch cho truy vấn này, bạn sẽ thấy không có toán tử Sắp xếp. Khi tôi chạy truy vấn này nhiều lần, tôi vẫn nhận được cùng một kết quả:
orderid ----------- 11008 11019 11039
Truy vấn thực sự tương đương với truy vấn không có mệnh đề ORDER BY, trong đó thứ tự trình bày không được đảm bảo. Vì vậy, về mặt kỹ thuật, thứ tự là không xác định và về mặt lý thuyết các lần thực thi khác nhau có thể dẫn đến thứ tự khác nhau, và do đó dẫn đến lựa chọn khác nhau của 3 hàng trên cùng. Tuy nhiên, khả năng xảy ra điều này là thấp và bạn không thể nghĩ giải pháp này là tạo ra ba hàng ngẫu nhiên trong mỗi lần thực thi.
Một ngoại lệ đối với quy tắc mà một hàm không xác định được gọi một lần cho mỗi tham chiếu trong truy vấn là hàm NEWID, hàm này trả về một mã định danh duy nhất trên toàn cầu (GUID). Khi được sử dụng trong một truy vấn, hàm này is được gọi riêng cho mỗi hàng. Truy vấn sau đây chứng minh điều này:
SELECT orderid, NEWID() AS mynewid FROM Sales.Orders;
Truy vấn này đã tạo ra kết quả sau:
orderid mynewid ----------- ------------------------------------ 11008 D6417542-C78A-4A2D-9517-7BB0FCF3B932 11019 E2E46BF1-4FA6-4EF2-8328-18B86259AD5D 11039 2917D923-AC60-44F5-92D7-FF84E52250CC 11040 B6287B49-DAE7-4C6C-98A8-7DB8A879581C 11045 2E14D8F7-21E5-4039-BF7E-0A27D1A0E186 11051 FA0B7B3E-BA41-4D80-8581-782EB88836C0 11054 1E6146BB-FEE7-4FF4-A4A2-3243AA2CBF78 11058 49302EA9-0243-4502-B9D2-46D751E6EFA9 11059 F5BB7CB2-3B17-4D01-ABD2-04F3C5115FCF 11061 09E406CA-0251-423B-8DF5-564E1257F93E ...
Bản thân giá trị của NEWID là khá ngẫu nhiên. Nếu bạn áp dụng hàm CHECKSUM bên trên nó, bạn sẽ nhận được một kết quả số nguyên với phân phối ngẫu nhiên thậm chí còn tốt hơn. Vì vậy, một cách để nhận ba đơn đặt hàng ngẫu nhiên là sử dụng truy vấn TOP với thứ tự dựa trên CHECKSUM (NEWID ()), như sau:
SELECT TOP (3) orderid FROM Sales.Orders ORDER BY CHECKSUM(NEWID());
Chạy truy vấn này nhiều lần và nhận thấy rằng bạn nhận được một bộ ba đơn đặt hàng ngẫu nhiên khác nhau mỗi lần. Tôi nhận được kết quả sau trong một lần thực thi:
orderid ----------- 11031 10330 10962
Và kết quả sau trong một lần thực thi khác:
orderid ----------- 10308 10885 10444
Ngoài NEWID, điều gì sẽ xảy ra nếu bạn cần sử dụng một hàm không xác định như SYSDATETIME trong một truy vấn và bạn cần nó được đánh giá riêng trên mỗi hàng? Một cách để đạt được điều này là sử dụng một hàm do người dùng xác định (UDF) gọi hàm không xác định, như sau:
CREATE OR ALTER FUNCTION dbo.MySysDateTime() RETURNS DATETIME2
AS
BEGIN
RETURN SYSDATETIME();
END;
GO Sau đó, bạn gọi UDF trong truy vấn như vậy (gọi nó là Truy vấn 5):
SELECT orderid, dbo.MySysDateTime() AS mydt FROM Sales.Orders;
UDF được thực thi trên mỗi hàng lần này. Tuy nhiên, bạn cần lưu ý rằng có một hình phạt hiệu suất khá rõ ràng liên quan đến việc thực thi trên mỗi hàng của UDF. Hơn nữa, việc gọi một T-SQL UDF vô hướng là một chất ức chế song song.
Kế hoạch cho truy vấn này được thể hiện trong Hình 5.
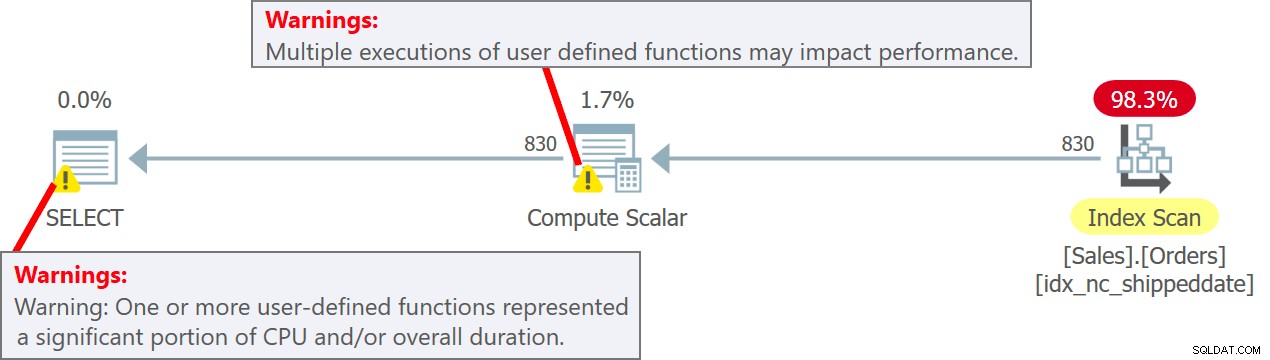
Hình 5:Kế hoạch cho truy vấn 5
Lưu ý trong kế hoạch rằng thực sự UDF được gọi trên mỗi hàng nguồn trong toán tử Tính vô hướng. Cũng lưu ý rằng SentryOne Plan Explorer cảnh báo bạn về hình phạt hiệu suất tiềm ẩn liên quan đến việc sử dụng UDF cả trong toán tử Compute Scalar và trong nút gốc của kế hoạch.
Tôi nhận được kết quả sau từ việc thực thi truy vấn này:
orderid mydt ----------- --------------------------- 11008 2019-02-04 17:07:03.7221339 11019 2019-02-04 17:07:03.7221339 11039 2019-02-04 17:07:03.7221339 ... 10251 2019-02-04 17:07:03.7231315 10255 2019-02-04 17:07:03.7231315 10248 2019-02-04 17:07:03.7231315 ... 10416 2019-02-04 17:07:03.7241304 10420 2019-02-04 17:07:03.7241304 10421 2019-02-04 17:07:03.7241304 ...
Quan sát rằng các hàng đầu ra có nhiều giá trị ngày và giờ khác nhau trong cột mydt.
Bạn có thể đã nghe nói rằng SQL Server 2019 giải quyết sự cố hiệu suất phổ biến do UDF T-SQL vô hướng gây ra bằng cách nội tuyến các hàm như vậy. Tuy nhiên, UDF phải đáp ứng một danh sách các yêu cầu để có thể nội tuyến. Một trong những yêu cầu là UDF không gọi bất kỳ hàm nội tại không xác định nào như SYSDATETIME. Lý do cho yêu cầu này là có lẽ bạn đã tạo chính xác UDF để thực hiện trên mỗi hàng. Nếu UDF có nội tuyến, hàm không xác định bên dưới sẽ chỉ được thực thi một lần cho toàn bộ truy vấn. Trên thực tế, kế hoạch trong Hình 5 đã được tạo trong SQL Server 2019 và bạn có thể thấy rõ ràng rằng UDF không có nội dung. Đó là do việc sử dụng hàm không xác định SYSDATETIME. Bạn có thể kiểm tra xem UDF có nội tuyến trong SQL Server 2019 hay không bằng cách truy vấn thuộc tính is_inlineable trong chế độ xem sys.sql_modules, như sau:
SELECT is_inlineable FROM sys.sql_modules WHERE object_id = OBJECT_ID(N'dbo.MySysDateTime');
Mã này tạo ra kết quả sau cho bạn biết rằng UDF MySysDateTime không thể nội dòng:
is_inlineable ------------- 0
Để chứng minh một UDF có thể nội dòng, dưới đây là định nghĩa về UDF được gọi là EndOfyear chấp nhận ngày nhập và trả về ngày cuối năm tương ứng:
CREATE OR ALTER FUNCTION dbo.EndOfYear(@dt AS DATE) RETURNS DATE
AS
BEGIN
RETURN DATEADD(year, DATEDIFF(year, '18991231', @dt), '18991231');
END;
GO Ở đây không sử dụng các hàm không xác định và mã cũng đáp ứng các yêu cầu khác đối với nội tuyến. Bạn có thể xác minh rằng UDF có thể nội dòng bằng cách sử dụng mã sau:
SELECT is_inlineable FROM sys.sql_modules WHERE object_id = OBJECT_ID(N'dbo.EndOfYear');
Mã này tạo ra kết quả sau:
is_inlineable ------------- 1
Truy vấn sau (gọi là Truy vấn 6) sử dụng UDF EndOfYear để lọc các đơn hàng được đặt vào một ngày cuối năm:
SELECT orderid FROM Sales.Orders WHERE orderdate = dbo.EndOfYear(orderdate);
Kế hoạch cho truy vấn này được thể hiện trong Hình 6.
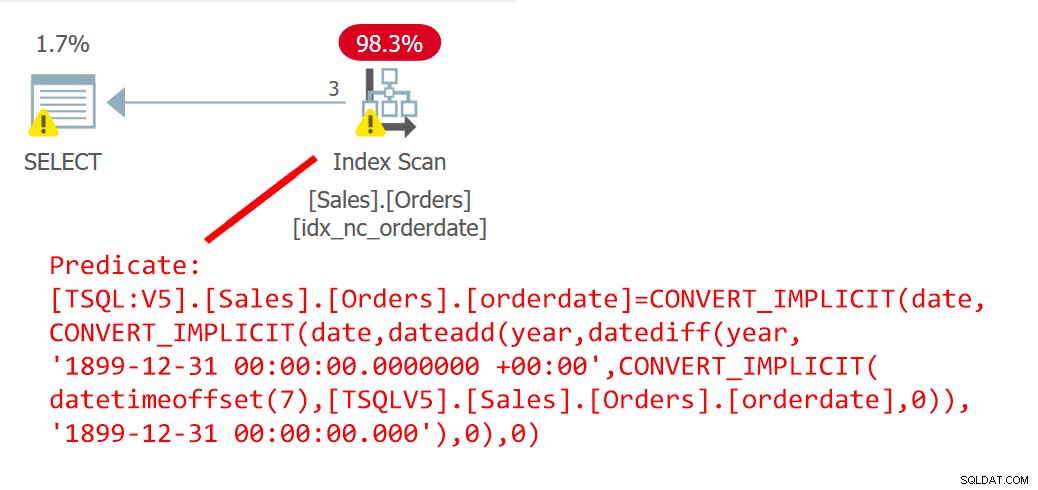
Hình 6:Kế hoạch cho truy vấn 6
Kế hoạch cho thấy rõ ràng rằng UDF đã có nội dung.
Biểu thức bảng, không xác định và nhiều tham chiếu
Như đã đề cập, các hàm không xác định như SYSDATETIME được gọi một lần cho mỗi tham chiếu trong một truy vấn. Nhưng điều gì sẽ xảy ra nếu bạn tham chiếu một hàm như vậy trong một truy vấn trong một biểu thức bảng như CTE và sau đó có một truy vấn bên ngoài với nhiều tham chiếu đến CTE? Nhiều người không nhận ra rằng mỗi tham chiếu đến biểu thức bảng được mở rộng riêng biệt và mã nội tuyến dẫn đến nhiều tham chiếu đến hàm không xác định cơ bản. Với một chức năng như SYSDATETIME, tùy thuộc vào thời gian chính xác của mỗi lần thực thi, bạn có thể nhận được một kết quả khác nhau cho mỗi lần thực thi. Một số người thấy hành vi này đáng ngạc nhiên.
Điều này có thể được minh họa bằng đoạn mã sau:
DECLARE @i AS INT = 1, @rc AS INT = NULL;
WHILE 1 = 1
BEGIN;
WITH C1 AS
(
SELECT SYSDATETIME() AS dt
),
C2 AS
(
SELECT dt FROM C1
UNION
SELECT dt FROM C1
)
SELECT @rc = COUNT(*) FROM C2;
IF @rc > 1 BREAK;
SET @i += 1;
END;
SELECT @rc AS distinctvalues, @i AS iterations; Nếu cả hai tham chiếu đến C1 trong truy vấn ở C2 đại diện cho cùng một điều, mã này sẽ dẫn đến một vòng lặp vô hạn. Tuy nhiên, vì hai tham chiếu được mở rộng riêng biệt, khi thời gian sao cho mỗi lệnh gọi diễn ra trong một khoảng thời gian 100 nano giây khác nhau (độ chính xác của giá trị kết quả), kết quả kết hợp thành hai hàng và mã sẽ ngắt khỏi vòng. Chạy mã này và xem cho chính mình. Thật vậy, sau một số lần lặp lại, nó bị hỏng. Tôi nhận được kết quả sau trong một trong những lần thực thi:
distinctvalues iterations -------------- ----------- 2 448
Cách tốt nhất là tránh sử dụng các biểu thức bảng như CTE và dạng xem, khi truy vấn bên trong sử dụng các phép tính không xác định và truy vấn bên ngoài đề cập đến biểu thức bảng nhiều lần. Đó là điều tất nhiên trừ khi bạn hiểu các hàm ý và bạn đồng ý với chúng. Các tùy chọn thay thế có thể là duy trì kết quả truy vấn bên trong, giả sử trong một bảng tạm thời, sau đó truy vấn bảng tạm thời bất kỳ số lần nào bạn cần.
Để chứng minh các ví dụ mà việc không tuân theo phương pháp hay nhất có thể khiến bạn gặp rắc rối, giả sử rằng bạn cần viết một truy vấn ghép nối các nhân viên từ bảng HR.E Employees một cách ngẫu nhiên. Bạn nghĩ ra truy vấn sau (gọi là truy vấn 7) để xử lý tác vụ:
WITH C AS
(
SELECT empid, firstname, lastname, ROW_NUMBER() OVER(ORDER BY CHECKSUM(NEWID())) AS n
FROM HR.Employees
)
SELECT
C1.empid AS empid1, C1.firstname AS firstname1, C1.lastname AS lastname1,
C2.empid AS empid2, C2.firstname AS firstname2, C2.lastname AS lastname2
FROM C AS C1
INNER JOIN C AS C2
ON C1.n = C2.n + 1; Kế hoạch cho truy vấn này được thể hiện trong Hình 7.
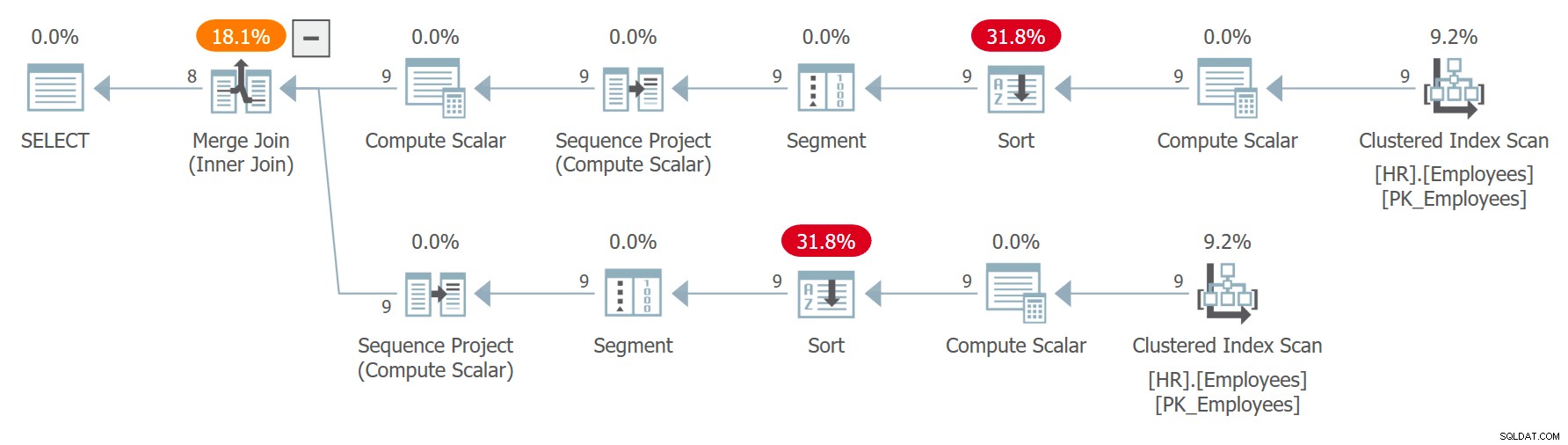
Hình 7:Kế hoạch cho Truy vấn 7
Quan sát rằng hai tham chiếu đến C được mở rộng riêng biệt và số hàng được tính độc lập cho mỗi tham chiếu được sắp xếp theo các lệnh gọi độc lập của biểu thức CHECKSUM (NEWID ()). Điều này có nghĩa là cùng một nhân viên không được đảm bảo nhận được cùng một số hàng trong hai tham chiếu mở rộng. Nếu một nhân viên nhận được số hàng x trong C1 và số hàng x - 1 trong C2, truy vấn sẽ ghép nối nhân viên với anh ta hoặc chính họ. Ví dụ:tôi nhận được kết quả sau trong một trong các lần thực thi:
empid1 firstname1 lastname1 empid2 firstname2 lastname2 ----------- ---------- -------------------- ----------- ---------- -------------------- 3 Judy Lew 6 Paul Suurs 9 Patricia Doyle *** 9 Patricia Doyle *** 5 Sven Mortensen 4 Yael Peled 6 Paul Suurs 8 Maria Cameron 8 Maria Cameron 5 Sven Mortensen 2 Don Funk *** 2 Don Funk *** 4 Yael Peled 3 Judy Lew 7 Russell King *** 7 Russell King ***
Quan sát rằng ở đây có ba trường hợp tự cặp. Điều này dễ thấy hơn bằng cách thêm bộ lọc vào truy vấn bên ngoài tìm kiếm cụ thể các cặp tự, như sau:
WITH C AS
(
SELECT empid, firstname, lastname, ROW_NUMBER() OVER(ORDER BY CHECKSUM(NEWID())) AS n
FROM HR.Employees
)
SELECT
C1.empid AS empid1, C1.firstname AS firstname1, C1.lastname AS lastname1,
C2.empid AS empid2, C2.firstname AS firstname2, C2.lastname AS lastname2
FROM C AS C1
INNER JOIN C AS C2
ON C1.n = C2.n + 1
WHERE C1.empid = C2.empid; Bạn có thể cần chạy truy vấn này nhiều lần để xem vấn đề. Dưới đây là một ví dụ cho kết quả mà tôi nhận được trong một trong những lần thực thi:
empid1 firstname1 lastname1 empid2 firstname2 lastname2 ----------- ---------- -------------------- ----------- ---------- -------------------- 5 Sven Mortensen 5 Sven Mortensen 2 Don Funk 2 Don Funk
Theo phương pháp hay nhất, một cách để giải quyết vấn đề này là duy trì kết quả truy vấn bên trong trong một bảng tạm thời và sau đó truy vấn nhiều trường hợp của bảng tạm thời nếu cần.
Một ví dụ khác minh họa các lỗi có thể do sử dụng thứ tự không xác định và nhiều tham chiếu đến biểu thức bảng. Giả sử rằng bạn cần truy vấn bảng Sales.Orders và để thực hiện phân tích xu hướng, bạn muốn ghép từng đơn hàng với đơn hàng tiếp theo dựa trên ngày đặt hàng. Giải pháp của bạn phải tương thích với các hệ thống trước SQL Server 2012, nghĩa là bạn không thể sử dụng các hàm LAG / LEAD rõ ràng. Bạn quyết định sử dụng CTE tính toán các số hàng để định vị các hàng dựa trên thứ tự ngày đặt hàng, sau đó kết hợp hai phiên bản của CTE, ghép nối các đơn hàng dựa trên độ lệch 1 giữa các số hàng, giống như vậy (gọi là Truy vấn 8):
WITH C AS
(
SELECT *, ROW_NUMBER() OVER(ORDER BY orderdate DESC) AS n
FROM Sales.Orders
)
SELECT
C1.orderid AS orderid1, C1.orderdate AS orderdate1, C1.custid AS custid1,
C2.orderid AS orderid2, C2.orderdate AS orderdate2
FROM C AS C1
LEFT OUTER JOIN C AS C2
ON C1.n = C2.n + 1; Kế hoạch cho truy vấn này được thể hiện trong Hình 8.
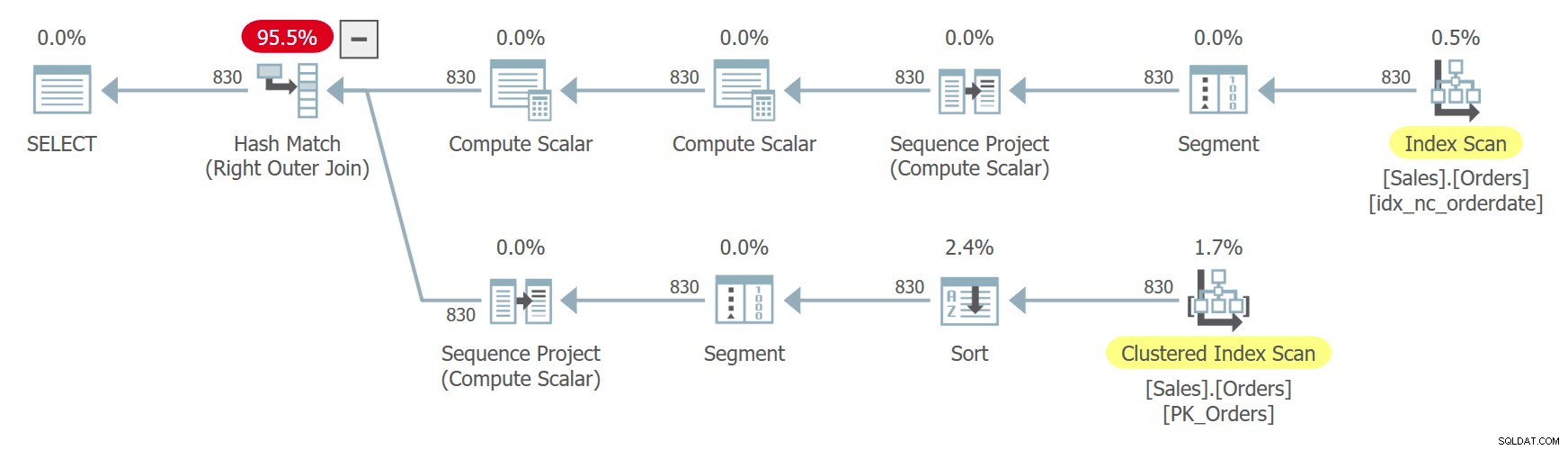 Hình 8:Kế hoạch cho Truy vấn 8
Hình 8:Kế hoạch cho Truy vấn 8
Thứ tự số hàng không mang tính xác định vì ngày đặt hàng không phải là duy nhất. Quan sát rằng hai tham chiếu đến CTE được mở rộng riêng biệt. Thật kỳ lạ, vì truy vấn đang tìm kiếm một tập hợp con khác nhau của các cột từ mỗi trường hợp, trình tối ưu hóa quyết định sử dụng một chỉ mục khác trong mỗi trường hợp. Trong một trường hợp, nó sử dụng tính năng quét ngược theo thứ tự của chỉ mục vào ngày orderdate, hiệu quả quét các hàng có cùng ngày dựa trên thứ tự giảm dần của orderid. Trong trường hợp khác, nó quét chỉ mục được phân cụm, sắp xếp thứ tự sai và sau đó sắp xếp, nhưng hiệu quả giữa các hàng có cùng ngày, nó truy cập các hàng theo thứ tự tăng dần. Đó là do lý luận tương tự mà tôi đã cung cấp trong phần về trật tự không xác định trước đó. Điều này có thể dẫn đến việc cùng một hàng nhận được số hàng x trong một trường hợp và số hàng x - 1 trong trường hợp kia. Trong trường hợp như vậy, phép nối sẽ kết thúc khớp với một lệnh với chính nó thay vì khớp với lệnh tiếp theo như nó nên làm.
Tôi nhận được kết quả sau khi thực hiện truy vấn này:
orderid1 orderdate1 custid1 orderid2 orderdate2 ----------- ---------- ----------- ----------- ---------- 11074 2019-05-06 73 NULL NULL 11075 2019-05-06 68 11077 2019-05-06 11076 2019-05-06 9 11076 2019-05-06 *** 11077 2019-05-06 65 11075 2019-05-06 11070 2019-05-05 44 11074 2019-05-06 11071 2019-05-05 46 11073 2019-05-05 11072 2019-05-05 20 11072 2019-05-05 *** ...
Quan sát các tự đối sánh trong kết quả. Một lần nữa, vấn đề có thể được xác định dễ dàng hơn bằng cách thêm bộ lọc tìm kiếm các kết quả tự khớp, như sau:
WITH C AS
(
SELECT *, ROW_NUMBER() OVER(ORDER BY orderdate DESC) AS n
FROM Sales.Orders
)
SELECT
C1.orderid AS orderid1, C1.orderdate AS orderdate1, C1.custid AS custid1,
C2.orderid AS orderid2, C2.orderdate AS orderdate2
FROM C AS C1
LEFT OUTER JOIN C AS C2
ON C1.n = C2.n + 1
WHERE C1.orderid = C2.orderid; Tôi nhận được kết quả sau từ truy vấn này:
orderid1 orderdate1 custid1 orderid2 orderdate2 ----------- ---------- ----------- ----------- ---------- 11076 2019-05-06 9 11076 2019-05-06 11072 2019-05-05 20 11072 2019-05-05 11062 2019-04-30 66 11062 2019-04-30 11052 2019-04-27 34 11052 2019-04-27 11042 2019-04-22 15 11042 2019-04-22 ...
Thực tiễn tốt nhất ở đây là đảm bảo rằng bạn sử dụng thứ tự duy nhất để đảm bảo tính xác định bằng cách thêm một tiebreaker như orderid vào mệnh đề thứ tự cửa sổ. Vì vậy, mặc dù bạn có nhiều tham chiếu đến cùng một CTE, số hàng sẽ giống nhau trong cả hai. Nếu bạn muốn tránh lặp lại các phép tính, bạn cũng có thể xem xét việc duy trì kết quả truy vấn bên trong, nhưng sau đó bạn cần tính đến chi phí cộng thêm của công việc đó.
CASE / NULLIF và các hàm không xác định
Khi bạn có nhiều tham chiếu đến một hàm không xác định trong một truy vấn, mỗi tham chiếu sẽ được đánh giá riêng biệt. Điều có thể gây ngạc nhiên và thậm chí dẫn đến lỗi là đôi khi bạn viết một tham chiếu, nhưng mặc nhiên nó được chuyển đổi thành nhiều tham chiếu. Đó là tình huống với một số cách sử dụng biểu thức CASE và hàm IIF.
Hãy xem xét ví dụ sau:
SELECT CASE ABS(CHECKSUM(NEWID())) % 2 WHEN 0 THEN 'Even' WHEN 1 THEN 'Odd' END;
Ở đây, kết quả của biểu thức được kiểm tra là một giá trị nguyên không âm, vì vậy rõ ràng nó phải là chẵn hoặc lẻ. Nó không thể không chẵn cũng không lẻ. However, if you run this code enough times, you will sometimes get a NULL indicating that the implied ELSE NULL clause of the CASE expression was activated. The reason for this is that the above expression translates to the following:
SELECT
CASE
WHEN ABS(CHECKSUM(NEWID())) % 2 = 0 THEN 'Even'
WHEN ABS(CHECKSUM(NEWID())) % 2 = 1 THEN 'Odd'
ELSE NULL
END; In the converted expression there are two separate references to the tested expression that generates a random nonnegative value, and each gets evaluated separately. One possible path is that the first evaluation produces an odd number, the second produces an even number, and then the ELSE NULL clause is activated.
Here’s a very similar situation with the NULLIF function:
SELECT NULLIF(ABS(CHECKSUM(NEWID())) % 2, 0);
This expression generates a random nonnegative value, and is supposed to return 1 when it’s odd, and NULL otherwise. It’s never supposed to return 0 since in such a case the 0 is supposed to be replaced with a NULL. Run it a few times and you will see that in some cases you get a 0. The reason for this is that the above expression internally translates to the following one:
SELECT
CASE
WHEN ABS(CHECKSUM(NEWID())) % 2 = 0 THEN NULL
ELSE ABS(CHECKSUM(NEWID())) % 2
END; A possible path is that the first WHEN clause generates a random odd value, so the ELSE clause is activated, and the ELSE clause generates a random even value so the % 2 calculation results in a 0.
In both cases this behavior is standard, so the bug is more in the eyes of the beholder based on your expectations and your choice of how to write the code. The best practice in both cases is to persist the result of the original calculation and then interact with the persisted result. If it’s a single value, store the result in a variable first. If you’re querying tables, first persist the result of the nondeterministic calculation in a column in a temporary table, and then apply the CASE/IIF logic in the query against the temporary table.
Kết luận
This article is the first in a series about T-SQL bugs, pitfalls and best practices, and is the result of discussions with fellow Microsoft Data Platform MVPs who shared their experiences. This time I focused on bugs and pitfalls that resulted from using nondeterministic order and nondeterministic calculations. In future articles I’ll continue with other themes. If you have bugs and pitfalls that you often stumble into, or that you find as particularly interesting, please do share!