Một trong những cách phổ biến nhất để đạt được tính khả dụng cao cho MySQL là sao chép. Việc nhân rộng đã tồn tại trong nhiều năm và trở nên ổn định hơn nhiều với sự ra đời của GTID. Nhưng ngay cả với những cải tiến này, quá trình sao chép có thể bị phá vỡ do nhiều lý do khác nhau - ví dụ:khi master và slave không đồng bộ vì các bản ghi được gửi trực tiếp đến slave. Làm thế nào để bạn khắc phục sự cố sao chép và làm thế nào để bạn khắc phục chúng?
Trong bài đăng trên blog này, chúng ta sẽ thảo luận về một số vấn đề phổ biến với sao chép và cách khắc phục chúng với ClusterControl. Hãy bắt đầu với cái đầu tiên.
Việc sao chép bị dừng do một số lỗi
Hầu hết các DBA MySQL thường sẽ gặp loại vấn đề này ít nhất một lần trong sự nghiệp của họ. Vì nhiều lý do khác nhau, một nô lệ có thể bị hỏng hoặc có thể ngừng đồng bộ hóa với chủ. Khi điều này xảy ra, điều đầu tiên cần làm để bắt đầu khắc phục sự cố là kiểm tra nhật ký lỗi để tìm thông báo. Hầu hết thời gian, thông báo lỗi có thể dễ dàng theo dõi trong nhật ký lỗi hoặc bằng cách chạy truy vấn TRẠNG THÁI CHẬM HIỂN THỊ.
Hãy xem ví dụ sau từ TRẠNG THÁI HIỂN THỊ TRƯỢT:
********** 0. row **********
Slave_IO_State:
Master_Host: 10.2.9.71
Master_User: cmon_replication
Master_Port: 3306
Connect_Retry: 10
Master_Log_File: binlog.000111
Read_Master_Log_Pos: 255477362
Relay_Log_File: relay-bin.000001
Relay_Log_Pos: 4
Relay_Master_Log_File: binlog.000111
Slave_IO_Running: No
Slave_SQL_Running: Yes
Replicate_Do_DB:
Replicate_Ignore_DB:
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
Last_Errno: 0
Last_Error:
Skip_Counter: 0
Exec_Master_Log_Pos: 255477362
Relay_Log_Space: 256
Until_Condition: None
Until_Log_File:
Until_Log_Pos: 0
Master_SSL_Allowed: No
Master_SSL_CA_File:
Master_SSL_CA_Path:
Master_SSL_Cert:
Master_SSL_Cipher:
Master_SSL_Key:
Seconds_Behind_Master:
Master_SSL_Verify_Server_Cert: No
Last_IO_Errno: 1236
Last_IO_Error: Got fatal error 1236 from master when reading data from binary log: 'Could not find GTID state requested by slave in any binlog files. Probably the slave state is too old and required binlog files have been purged.'
Last_SQL_Errno: 0
Last_SQL_Error:
Replicate_Ignore_Server_Ids:
Master_Server_Id: 1000
Master_SSL_Crl:
Master_SSL_Crlpath:
Using_Gtid: Slave_Pos
Gtid_IO_Pos: 1000-1000-2268440
Replicate_Do_Domain_Ids:
Replicate_Ignore_Domain_Ids:
Parallel_Mode: optimistic
SQL_Delay: 0
SQL_Remaining_Delay:
Slave_SQL_Running_State: Slave has read all relay log; waiting for more updates
Slave_DDL_Groups: 0
Slave_Non_Transactional_Groups: 0
Slave_Transactional_Groups: 0Chúng ta có thể thấy rõ lỗi liên quan đến Lỗi nghiêm trọng 1236 từ chủ khi đọc dữ liệu từ bản ghi nhị phân:'Không thể tìm thấy trạng thái GTID do nô lệ yêu cầu trong bất kỳ tệp binlog nào. Có lẽ trạng thái nô lệ đã quá cũ và các tệp binlog cần thiết đã bị xóa. '. Nói một cách dễ hiểu, lỗi đang nói với chúng tôi về cơ bản là có sự không nhất quán trong dữ liệu và các tệp nhật ký nhị phân bắt buộc đã bị xóa.
Đây là một ví dụ điển hình trong đó quá trình sao chép ngừng hoạt động. Bên cạnh HIỂN THỊ TRẠNG THÁI CHẬM, bạn cũng có thể theo dõi trạng thái trong tab “Tổng quan” của cụm trong ClusterControl. Vậy làm thế nào để khắc phục điều này với ClusterControl? Bạn có hai tùy chọn để thử:
-
Bạn có thể thử khởi động lại nô lệ từ “Node Action”
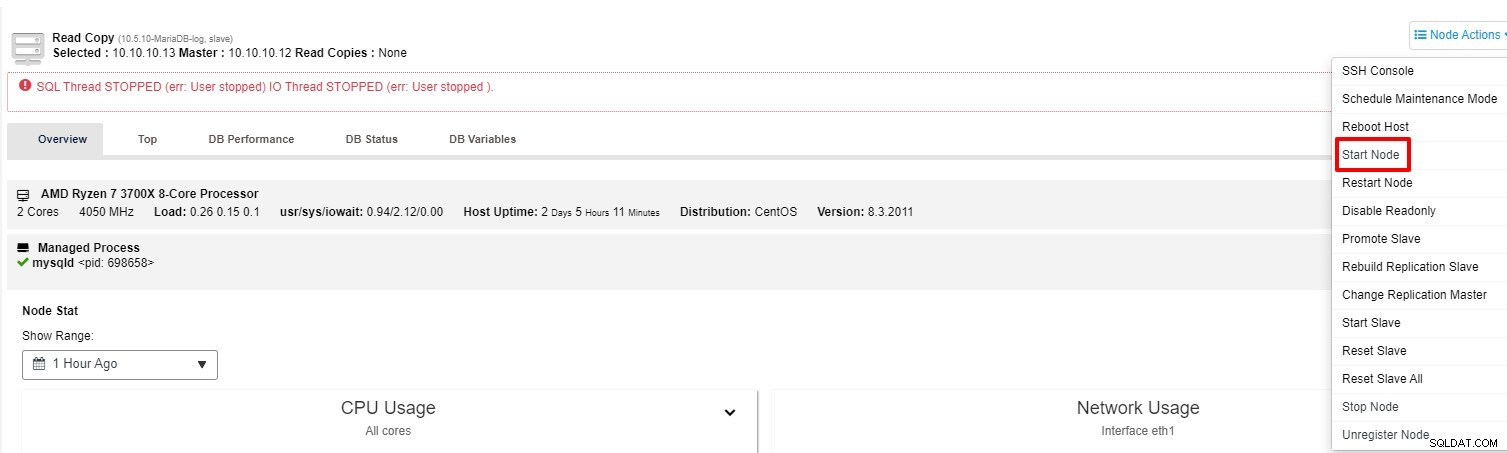
-
Nếu nô lệ vẫn không hoạt động, bạn có thể chạy công việc "Rebuild Replication Slave" từ “Node Action”
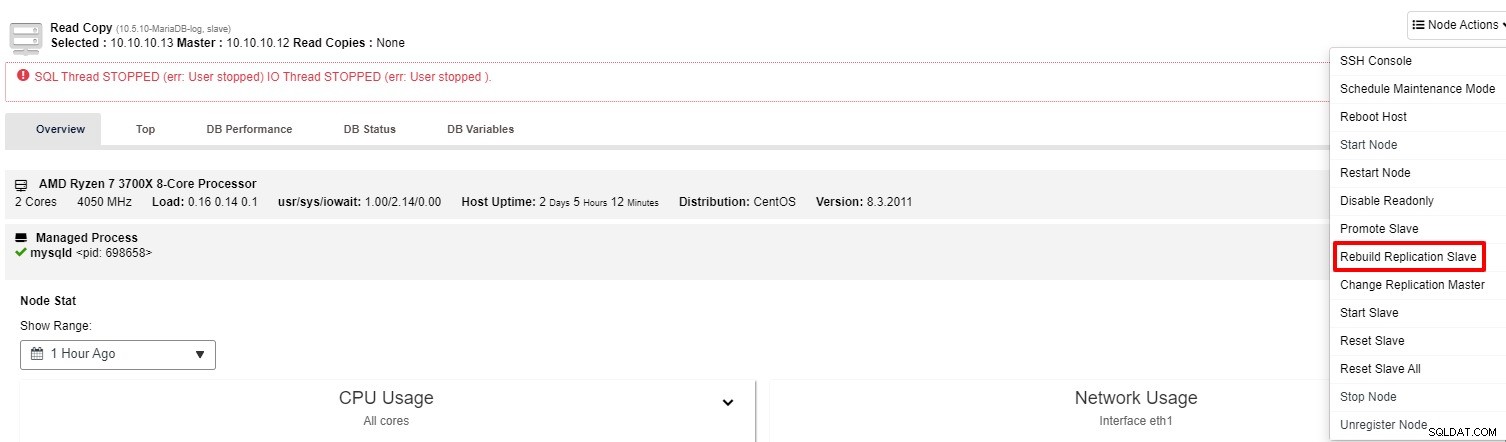
Thông thường, tùy chọn thứ hai sẽ giải quyết được sự cố. ClusterControl sẽ thực hiện một bản sao lưu của chính và xây dựng lại nô lệ bị hỏng bằng cách khôi phục dữ liệu. Sau khi dữ liệu được khôi phục, máy chủ sẽ được kết nối với máy chủ để nó có thể bắt kịp.
Cũng có nhiều cách thủ công để xây dựng lại nô lệ như được liệt kê bên dưới, bạn cũng có thể tham khảo liên kết này để biết thêm chi tiết:
-
Sử dụng Mysqldump để xây dựng lại MySQL Slave không nhất quán
-
Sử dụng Mydumper để tạo lại MySQL Slave không nhất quán
-
Sử dụng Ảnh chụp nhanh để tạo lại MySQL Slave không nhất quán
-
Sử dụng Xtrabackup hoặc Mariabackup để tạo lại MySQL Slave không nhất quán
Thúc đẩy nô lệ để trở thành chủ nhân
Theo thời gian, hệ điều hành hoặc cơ sở dữ liệu cần được vá hoặc nâng cấp để duy trì sự ổn định và bảo mật. Một trong những phương pháp hay nhất để giảm thiểu thời gian chết, đặc biệt là đối với một bản nâng cấp lớn là thúc đẩy một trong những nô lệ để làm chủ sau khi nâng cấp được thực hiện thành công trên nút cụ thể đó.
Bằng cách thực hiện điều này, bạn có thể trỏ ứng dụng của mình tới trang cái mới và bản sao chủ-tớ sẽ tiếp tục hoạt động. Trong thời gian chờ đợi, bạn cũng có thể yên tâm tiến hành nâng cấp trên bản chính cũ. Với ClusterControl, điều này có thể được thực hiện với một vài cú nhấp chuột chỉ giả sử bản sao được định cấu hình là dựa trên ID giao dịch toàn cầu hoặc viết tắt là dựa trên GTID. Để tránh bất kỳ sự mất mát dữ liệu nào, bạn nên dừng mọi truy vấn ứng dụng trong trường hợp thiết bị chính cũ đang hoạt động chính xác. Đây không phải là tình huống duy nhất mà bạn có thể thăng cấp cho nô lệ. Trong trường hợp nút chính không hoạt động, bạn cũng có thể thực hiện hành động này.
Không có ClusterControl, có một số bước để thúc đẩy nô lệ. Mỗi bước cũng cần một vài truy vấn để chạy:
-
Gỡ xuống trang cái theo cách thủ công
-
Chọn nô lệ cao cấp nhất làm chủ nhân và chuẩn bị cho nó
-
Kết nối lại các nô lệ khác với chủ mới
-
Thay đổi chủ cũ thành nô lệ
Tuy nhiên, các bước để Quảng bá Slave với ClusterControl chỉ bằng vài cú nhấp chuột:Cluster> Nodes> chọn nút nô lệ> Thúc đẩy Slave theo ảnh chụp màn hình bên dưới:
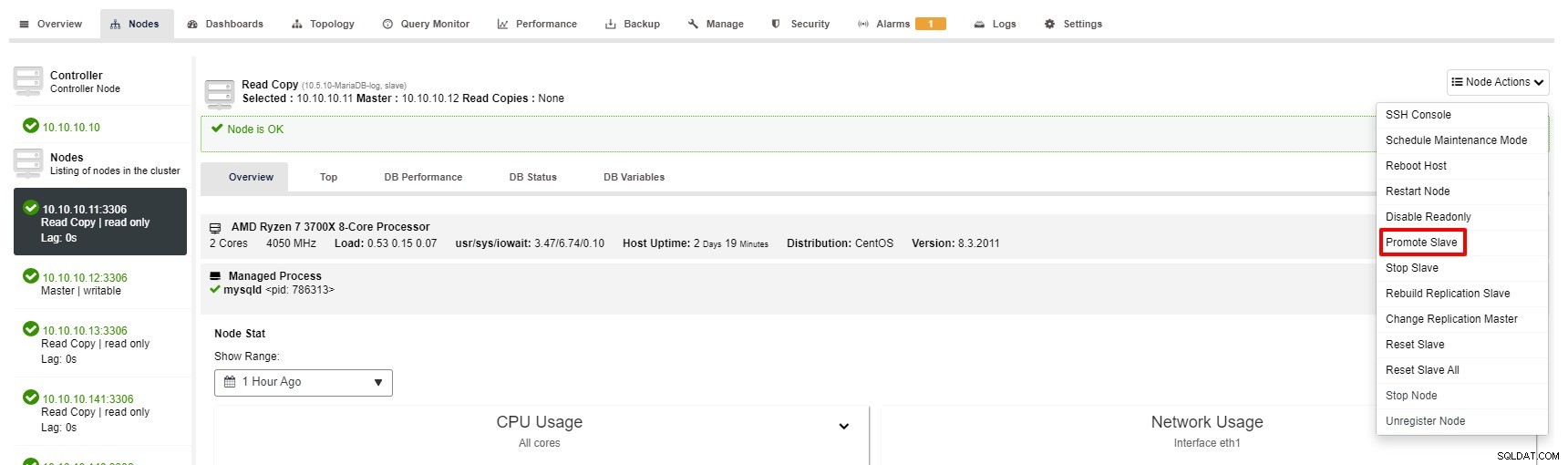
Master trở nên không khả dụng
Hãy tưởng tượng bạn có các giao dịch lớn cần chạy nhưng cơ sở dữ liệu không hoạt động. Không quan trọng bạn cẩn thận như thế nào, đây có lẽ là tình huống nghiêm trọng hoặc quan trọng nhất đối với thiết lập sao chép. Khi điều này xảy ra, cơ sở dữ liệu của bạn không thể chấp nhận một lần ghi, điều này thật tệ. Bên cạnh đó, (các) ứng dụng của bạn, tất nhiên, sẽ không hoạt động bình thường.
Có một số lý do hoặc nguyên nhân dẫn đến vấn đề này. Một số ví dụ là lỗi phần cứng, lỗi hệ điều hành, lỗi cơ sở dữ liệu, v.v. Là một DBA, bạn cần nhanh chóng hành động để khôi phục cơ sở dữ liệu chính.
Nhờ chức năng cụm "Tự động Khôi phục" có sẵn trong ClusterControl, quá trình chuyển đổi dự phòng có thể được tự động hóa. Nó có thể được bật hoặc tắt chỉ với một cú nhấp chuột. Như tên gọi, những gì nó sẽ làm là hiển thị toàn bộ cấu trúc liên kết khi cần thiết. Ví dụ, một bản sao chủ-nô lệ phải có ít nhất một chủ nhân còn sống tại bất kỳ thời điểm nào, bất kể số lượng nô lệ hiện có. Khi trang cái không có sẵn, nó sẽ tự động thăng cấp một trong các nô lệ.
Hãy xem ảnh chụp màn hình bên dưới:
Trong ảnh chụp màn hình ở trên, chúng ta có thể thấy rằng “Auto Recovery” được bật cho cả Cluster và Node. Trong cấu trúc liên kết, lưu ý rằng địa chỉ IP chính hiện tại là 10.10.10.11. Điều gì sẽ xảy ra nếu chúng tôi gỡ bỏ nút chính cho mục đích thử nghiệm?
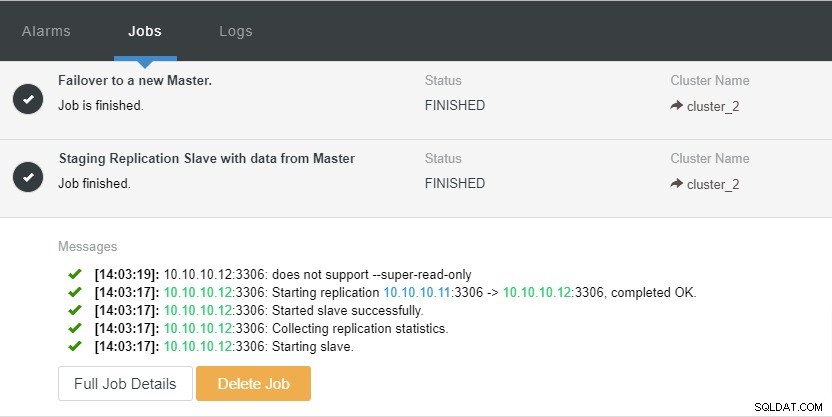
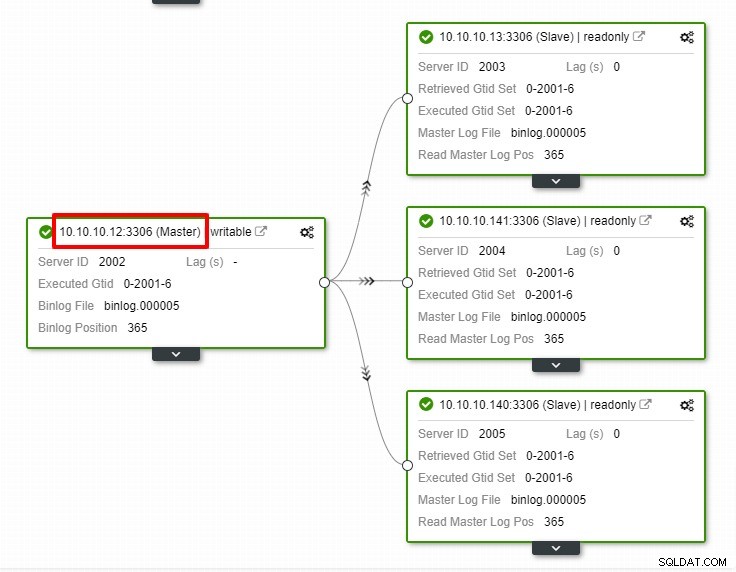
Như bạn có thể thấy, nút phụ có IP 10.10.10.12 sẽ tự động thăng cấp lên master, để cấu hình lại cấu trúc liên kết nhân rộng. Thay vì làm điều đó theo cách thủ công, tất nhiên, sẽ bao gồm rất nhiều bước, ClusterControl giúp bạn duy trì thiết lập sao chép của mình bằng cách loại bỏ rắc rối.
Kết luận
Trong bất kỳ trường hợp không may nào xảy ra với bản sao của bạn, cách khắc phục rất đơn giản và ít phức tạp hơn với ClusterControl. ClusterControl giúp bạn nhanh chóng khôi phục các sự cố sao chép, giúp tăng thời gian hoạt động của cơ sở dữ liệu.