Những ngày này, việc chạy cơ sở dữ liệu trên cơ sở hạ tầng đám mây đang ngày càng trở nên phổ biến. Mặc dù máy ảo đám mây có thể không đáng tin cậy như máy chủ cấp doanh nghiệp, nhưng các nhà cung cấp dịch vụ đám mây chính cung cấp nhiều công cụ khác nhau để tăng tính khả dụng của dịch vụ. Trong bài đăng trên blog này, chúng tôi sẽ chỉ cho bạn cách kiến trúc cơ sở dữ liệu MySQL hoặc MariaDB của bạn để có tính khả dụng cao trên đám mây. Chúng tôi sẽ xem xét cụ thể về Dịch vụ web của Amazon và Nền tảng đám mây của Google, nhưng hầu hết các mẹo cũng có thể được sử dụng với các nhà cung cấp dịch vụ đám mây khác.
Cả AWS và Google đều cung cấp các dịch vụ cơ sở dữ liệu trên các đám mây của họ và các dịch vụ này có thể được định cấu hình để có tính khả dụng cao. Có thể có các bản sao ở các khu vực khả dụng khác nhau (hoặc các khu vực trong GCP), để tăng cơ hội sống sót cho các dịch vụ bị lỗi một phần trong một khu vực. Mặc dù dịch vụ được lưu trữ là một cách rất thuận tiện để chạy cơ sở dữ liệu, lưu ý rằng dịch vụ được thiết kế để hoạt động theo một cách cụ thể và điều đó có thể phù hợp hoặc có thể không phù hợp với yêu cầu của bạn. Vì vậy, ví dụ, AWS RDS cho MySQL có một danh sách khá hạn chế các tùy chọn khi nói đến xử lý chuyển đổi dự phòng. Việc triển khai Multi-AZ có thời gian chuyển đổi dự phòng 60-120 giây theo tài liệu. Trên thực tế, do cá thể MySQL “bóng” phải bắt đầu từ tập dữ liệu “bị hỏng”, điều này có thể mất nhiều thời gian hơn vì có thể cần nhiều công việc hơn để áp dụng hoặc khôi phục các giao dịch từ các bản ghi làm lại InnoDB. Có một tùy chọn để thăng cấp nô lệ trở thành chủ nhân, nhưng nó không khả thi vì bạn không thể khôi phục nô lệ hiện có khỏi chủ nhân mới. Trong trường hợp của một dịch vụ được quản lý, về bản chất, nó cũng phức tạp hơn và khó theo dõi các vấn đề về hiệu suất hơn. Thông tin chi tiết hơn về RDS cho MySQL và các hạn chế của nó trong bài đăng trên blog này.
Mặt khác, nếu bạn quyết định quản lý cơ sở dữ liệu, bạn đang ở trong một thế giới khác của các khả năng. Một số điều bạn có thể làm trên kim loại trần cũng có thể thực hiện được trên các phiên bản EC2 hoặc Compute Engine. Bạn không có chi phí quản lý phần cứng bên dưới, nhưng vẫn có quyền kiểm soát về cách kiến trúc hệ thống. Có hai tùy chọn chính khi thiết kế cho tính khả dụng của MySQL - MySQL replication và Galera Cluster. Hãy thảo luận về chúng.
Bản sao MySQL
Nhân rộng MySQL là một cách phổ biến để mở rộng MySQL với nhiều bản sao dữ liệu. Không đồng bộ hoặc bán đồng bộ, nó cho phép truyền các thay đổi được thực thi trên một trình ghi duy nhất, chính, tới các bản sao / nô lệ - mỗi bản sao / nô lệ sẽ chứa toàn bộ tập dữ liệu và có thể được thăng cấp để trở thành trình ghi chính mới. Bản sao cũng có thể được sử dụng để chia tỷ lệ số lần đọc, bằng cách hướng lưu lượng đọc đến bản sao và giảm tải bản chính theo cách này. Ưu điểm chính của sao chép là dễ sử dụng - nó được biết đến rộng rãi và phổ biến (nó cũng dễ định cấu hình) nên có rất nhiều tài nguyên và công cụ để giúp bạn quản lý và định cấu hình nó. ClusterControl của riêng chúng tôi là một trong số đó - bạn có thể sử dụng nó để dễ dàng triển khai thiết lập sao chép MySQL với bộ cân bằng tải tích hợp, quản lý các thay đổi cấu trúc liên kết, chuyển đổi dự phòng / phục hồi, v.v.
Một vấn đề chính đối với việc nhân bản MySQL là nó không được thiết kế để xử lý sự phân chia mạng hoặc lỗi của master. Nếu một bản chính bị hỏng, bạn phải quảng bá một trong các bản sao. Đây là một quy trình thủ công, mặc dù nó có thể được tự động hóa bằng các công cụ bên ngoài (ví dụ:ClusterControl). Cũng không có cơ chế túc số nào và không có hỗ trợ cho việc rào các trường hợp chính bị lỗi trong bản sao MySQL. Thật không may, điều này có thể dẫn đến các vấn đề nghiêm trọng trong môi trường phân tán - nếu bạn thăng cấp một cái mới trong khi cái cũ của bạn trực tuyến trở lại, bạn có thể kết thúc việc ghi vào hai nút, tạo ra sự trôi dạt dữ liệu và gây ra các vấn đề nghiêm trọng về tính nhất quán của dữ liệu.
Chúng tôi sẽ xem xét một số ví dụ sau trong bài đăng này, cho bạn biết cách phát hiện sự phân chia mạng và triển khai STONITH hoặc một số cơ chế hàng rào khác cho thiết lập sao chép MySQL của bạn.
Cụm Galera
Chúng ta đã thấy trong phần trước rằng bản sao MySQL thiếu hỗ trợ hàng rào và túc số - đây là nơi Galera Cluster tỏa sáng. Nó có hỗ trợ túc số được tích hợp sẵn, nó cũng có cơ chế hàng rào ngăn các nút được phân vùng chấp nhận ghi. Điều này làm cho Galera Cluster phù hợp hơn là sao chép trong thiết lập nhiều trung tâm dữ liệu. Galera Cluster cũng hỗ trợ nhiều người viết và có thể giải quyết xung đột khi viết. Do đó, bạn không bị giới hạn ở một người viết trong thiết lập nhiều trung tâm dữ liệu, có thể có một người viết trong mọi trung tâm dữ liệu, điều này làm giảm độ trễ giữa ứng dụng và tầng cơ sở dữ liệu của bạn. Nó không làm tăng tốc độ ghi vì mọi lần ghi vẫn phải được gửi đến mọi nút Galera để được chứng nhận, nhưng vẫn dễ dàng hơn so với việc gửi các bản ghi từ tất cả các máy chủ ứng dụng trên mạng WAN đến một máy chủ từ xa duy nhất.
Tốt như Galera, nó không phải lúc nào cũng là sự lựa chọn tốt nhất cho tất cả các khối lượng công việc. Galera không phải là bản thay thế cho MySQL / InnoDB. Nó chia sẻ các tính năng chung với MySQL “bình thường” - nó sử dụng InnoDB làm công cụ lưu trữ, nó chứa toàn bộ tập dữ liệu trên mọi nút, điều này làm cho các JOIN khả thi. Tuy nhiên, một số đặc điểm hiệu suất của Galera (như hiệu suất ghi bị ảnh hưởng bởi độ trễ mạng) khác với những gì bạn mong đợi từ thiết lập nhân rộng. Việc bảo trì cũng có vẻ khác:xử lý thay đổi lược đồ hoạt động hơi khác một chút. Một số thiết kế giản đồ không tối ưu:nếu bạn có các điểm phát sóng trong bảng của mình, chẳng hạn như các bộ đếm được cập nhật thường xuyên, điều này có thể dẫn đến các vấn đề về hiệu suất. Ngoài ra còn có sự khác biệt trong các phương pháp hay nhất liên quan đến xử lý hàng loạt - thay vì thực hiện các truy vấn trong các giao dịch lớn, bạn muốn các giao dịch của mình nhỏ.
Cấp proxy
Rất khó và cồng kềnh để xây dựng một thiết lập có tính khả dụng cao mà không có proxy. Chắc chắn, bạn có thể viết mã trong ứng dụng của mình để theo dõi các phiên bản cơ sở dữ liệu, các phiên bản không lành mạnh trong danh sách đen, theo dõi (các) bản chính có thể ghi, v.v. Nhưng điều này phức tạp hơn nhiều so với việc chỉ gửi lưu lượng truy cập đến một điểm cuối duy nhất - đó là nơi có proxy. ClusterControl cho phép bạn triển khai ProxySQL, HAProxy và MaxScale. Chúng tôi sẽ đưa ra một số ví dụ sử dụng ProxySQL, vì nó mang lại cho chúng tôi sự linh hoạt tốt trong việc kiểm soát lưu lượng cơ sở dữ liệu.
ProxySQL có thể được triển khai theo một số cách. Đối với người mới bắt đầu, nó có thể được triển khai trên các máy chủ riêng biệt và Keepalived có thể được sử dụng để cung cấp IP ảo. IP ảo sẽ được di chuyển xung quanh nếu một trong các phiên bản ProxySQL bị lỗi. Trong đám mây, thiết lập này có thể có vấn đề vì thêm IP vào giao diện thường là không đủ. Bạn sẽ phải sửa đổi cấu hình và tập lệnh Keepalived để hoạt động với IP đàn hồi (hoặc tĩnh -however nó có thể được gọi bởi nhà cung cấp dịch vụ đám mây của bạn). Sau đó, người ta sẽ sử dụng API đám mây hoặc CLI để chuyển địa chỉ IP này sang một máy chủ khác. Vì lý do này, chúng tôi khuyên bạn nên kết hợp ProxySQL với ứng dụng. Mỗi máy chủ ứng dụng sẽ được cấu hình để kết nối với ProxySQL cục bộ, sử dụng các ổ cắm Unix. Vì ProxySQL sử dụng quy trình thiên thần, các sự cố ProxySQL có thể được phát hiện / khởi động lại trong vòng một giây. Trong trường hợp phần cứng gặp sự cố, máy chủ ứng dụng cụ thể đó sẽ ngừng hoạt động cùng với ProxySQL. Các máy chủ ứng dụng còn lại vẫn có thể truy cập các phiên bản ProxySQL cục bộ tương ứng của chúng. Thiết lập cụ thể này có các tính năng bổ sung. Bảo mật - ProxySQL, kể từ phiên bản 1.4.8, không hỗ trợ SSL phía máy khách. Nó chỉ có thể thiết lập kết nối SSL giữa ProxySQL và phần phụ trợ. Sắp xếp ProxySQL trên máy chủ ứng dụng và sử dụng ổ cắm Unix là một giải pháp tốt. ProxySQL cũng có khả năng lưu các truy vấn vào bộ nhớ cache và nếu bạn định sử dụng tính năng này, bạn nên giữ nó càng gần ứng dụng càng tốt để giảm độ trễ. Chúng tôi khuyên bạn nên sử dụng mẫu này để triển khai ProxySQL.
Các thiết lập điển hình
Hãy xem các ví dụ về các thiết lập có tính khả dụng cao.
Một trung tâm dữ liệu, bản sao MySQL
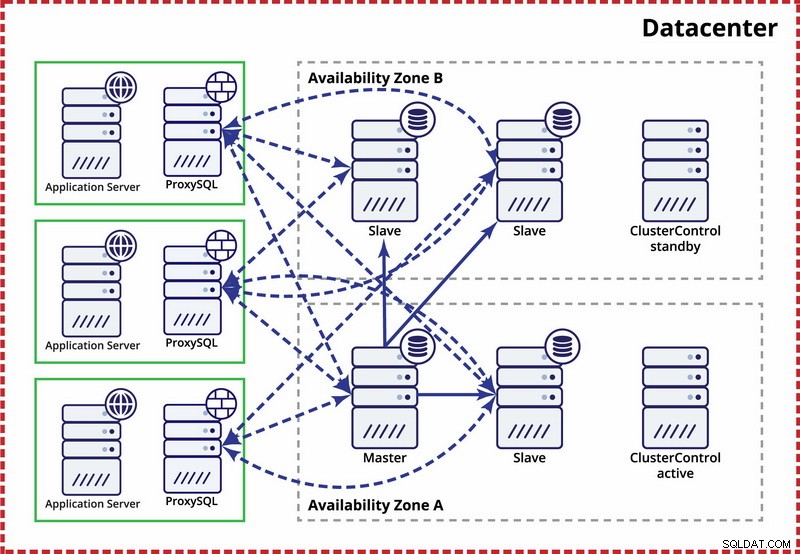
Giả định ở đây là có hai vùng riêng biệt trong trung tâm dữ liệu. Mỗi khu vực có nguồn điện, mạng và kết nối dự phòng và riêng biệt để giảm khả năng hai khu vực bị lỗi đồng thời. Có thể thiết lập cấu trúc liên kết sao chép bao trùm cả hai vùng.
Ở đây chúng tôi sử dụng ClusterControl để quản lý chuyển đổi dự phòng. Để giải quyết tình huống phân chia não bộ giữa các vùng khả dụng, chúng tôi sắp xếp ClusterControl đang hoạt động với cái chính. Chúng tôi cũng đưa vào danh sách cấm các nô lệ trong khu vực khả dụng khác để đảm bảo rằng chuyển đổi dự phòng tự động sẽ không dẫn đến khả dụng hai bản chính.
Nhiều trung tâm dữ liệu, sao chép MySQL
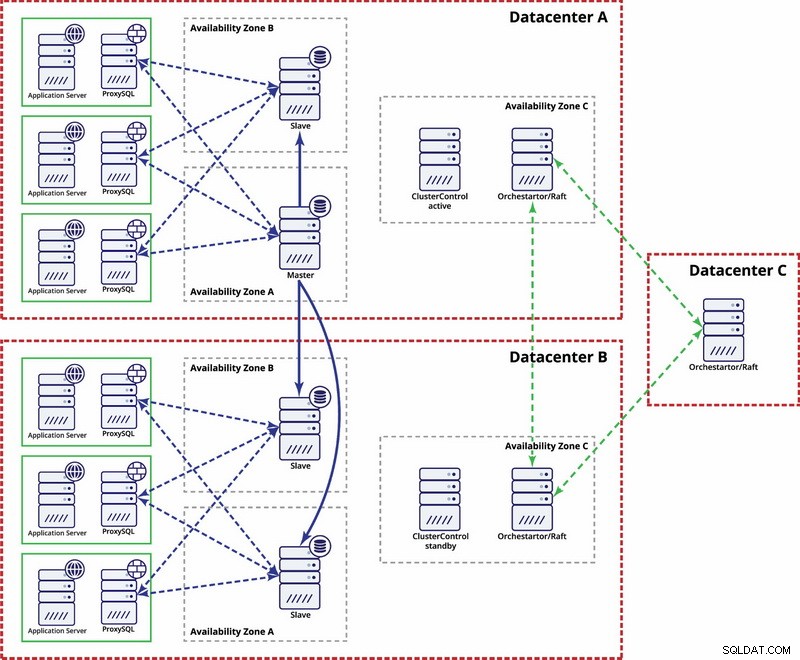
Trong ví dụ này, chúng tôi sử dụng ba trung tâm dữ liệu và Orchestrator / Raft để tính toán túc số. Bạn có thể phải viết các tập lệnh của riêng mình để triển khai STONITH nếu chủ nằm trong phân đoạn được phân vùng của cơ sở hạ tầng. ClusterControl được sử dụng cho các chức năng quản lý và khôi phục nút.
Nhiều trung tâm dữ liệu, Cụm Galera
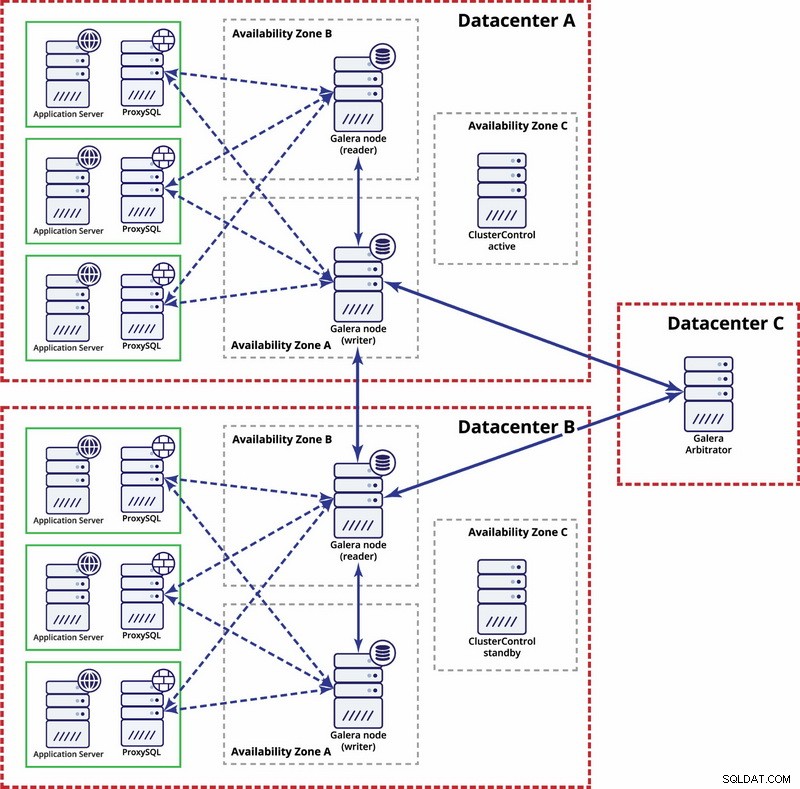
Trong trường hợp này, chúng tôi sử dụng ba trung tâm dữ liệu với trọng tài Galera ở trung tâm thứ ba - điều này có thể giúp xử lý toàn bộ sự cố của trung tâm dữ liệu và giảm nguy cơ phân vùng mạng vì trung tâm dữ liệu thứ ba có thể được sử dụng như một bộ chuyển tiếp.
Để đọc thêm, hãy xem sách trắng "Cách thiết kế môi trường cơ sở dữ liệu nguồn mở có khả năng cao" và xem phát lại hội thảo trên web "Thiết kế cơ sở dữ liệu nguồn mở để có tính khả dụng cao".