Kể từ khi ClusterControl 1.2.11 được phát hành vào năm 2015, MariaDB MaxScale đã được hỗ trợ như một bộ cân bằng tải cơ sở dữ liệu. Trong nhiều năm, MaxScale đã phát triển và trưởng thành, bổ sung thêm một số tính năng phong phú. Gần đây MariaDB MaxScale 2.2 đã được phát hành và nó giới thiệu một số tính năng mới bao gồm quản lý chuyển đổi dự phòng cụm nhân bản.
MariaDB MaxScale cho phép triển khai master / slave với tính khả dụng cao, tự động chuyển đổi dự phòng, chuyển đổi thủ công và tự động tham gia lại. Nếu cái chủ không thành công, MariaDB MaxScale có thể tự động thăng cấp nô lệ cập nhật nhất thành chủ. Nếu khôi phục được cái chủ bị lỗi, MariaDB MaxScale có thể tự động định cấu hình lại nó như một nô lệ cho cái chủ mới. Ngoài ra, quản trị viên có thể thực hiện chuyển đổi thủ công để thay đổi trang cái theo yêu cầu.
Trong các blog trước đây của chúng tôi, chúng tôi đã thảo luận về cách Triển khai MaxScale bằng ClusterControl cũng như Triển khai MariaDB MaxScale trên Docker. Đối với những người chưa quen thuộc với MariaDB MaxScale, nó là một proxy cơ sở dữ liệu nâng cao, trình cắm thêm cho các máy chủ cơ sở dữ liệu MariaDB. Maxscale nằm giữa các ứng dụng khách và máy chủ cơ sở dữ liệu, định tuyến các truy vấn của máy khách và phản hồi của máy chủ. Nó cũng giám sát các máy chủ, nhanh chóng nhận thấy bất kỳ thay đổi nào về trạng thái máy chủ hoặc cấu trúc liên kết sao chép.
Mặc dù Maxscale chia sẻ một số đặc điểm của các công nghệ cân bằng tải khác như ProxySQL, nhưng tính năng chuyển đổi dự phòng mới này (là một phần của cơ chế giám sát và tự động phát hiện) lại nổi bật. Trong blog này, chúng ta sẽ thảo luận về chức năng mới thú vị này của Maxscale.
Tổng quan về Cơ chế chuyển đổi dự phòng MariaDB MaxScale
Phát hiện chính
Màn hình giờ đây ít có khả năng đột ngột thay đổi máy chủ chính, ngay cả khi một máy chủ khác có nhiều nô lệ hơn máy chủ hiện tại. DBA có thể buộc chọn lại bản chính bằng cách đặt chế độ chỉ đọc bản chính hiện tại hoặc bằng cách xóa tất cả các nô lệ của nó nếu bản chính bị lỗi.
Chỉ một máy chủ có thể có cờ trạng thái Chính tại một thời điểm, ngay cả trong thiết lập nhiều quản trị viên. Các máy chủ khác trong nhóm multimaster được gắn cờ trạng thái Relay Master và Slave.
Switchover New Master Autoselection
Giờ đây, lệnh chuyển đổi có thể được gọi chỉ với tên phiên bản màn hình làm tham số. Trong trường hợp này, màn hình sẽ tự động chọn một máy chủ để quảng cáo.
Phát hiện trễ sao chép
Giờ đây, phép đo độ trễ sao chép chỉ đơn giản là đọc Seconds_Behind_Master -trường của sản lượng địa vị nô lệ của nô lệ. Nô lệ tính toán giá trị này bằng cách so sánh tem thời gian trong sự kiện binlog mà nô lệ hiện đang xử lý với đồng hồ của chính nô lệ. Nếu một nô lệ có nhiều kết nối phụ, thì độ trễ nhỏ nhất sẽ được sử dụng.
Tự động chuyển đổi sau khi phát hiện dung lượng đĩa thấp
Với các phiên bản Máy chủ MariaDB gần đây, trình giám sát giờ đây có thể kiểm tra dung lượng ổ đĩa trên chương trình phụ trợ và phát hiện xem máy chủ có sắp hết hay không. Khi điều này xảy ra, màn hình có thể được đặt để tự động chuyển đổi từ chế độ chính có dung lượng ổ đĩa thấp. Các nô lệ cũng có thể được đặt ở chế độ bảo trì. Dung lượng ổ đĩa cũng là một yếu tố được cân nhắc khi chọn quảng cáo chính mới.
Hãy xem converthover_on_low_disk_space và Maint_on_low_disk_space để biết thêm thông tin.
Tính năng Đặt lại Nhân bản
reset-sao chép lệnh giám sát xóa tất cả các kết nối phụ và nhật ký nhị phân, sau đó thiết lập nhân rộng. Hữu ích khi dữ liệu được đồng bộ hóa nhưng gtid thì không.
Xử lý sự kiện đã lên lịch trong chuyển đổi dự phòng / chuyển mạch / tham gia lại
Các sự kiện máy chủ do luồng trình lập lịch sự kiện khởi chạy hiện được xử lý trong các hoạt động sửa đổi cụm. Xem handle_server_events để biết thêm thông tin.
Hỗ trợ chính bên ngoài
Màn hình có thể phát hiện xem một máy chủ trong cụm có đang sao chép từ một máy chủ bên ngoài (máy chủ không được giám sát bởi màn hình MaxScale) hay không. Nếu máy chủ nhân bản là máy chủ chính của cụm thì bản thân cụm đó được coi là có máy chủ bên ngoài.
Nếu xảy ra chuyển đổi / chuyển đổi dự phòng, máy chủ chính mới được đặt để sao chép từ máy chủ chính bên ngoài cụm. Tên người dùng và mật khẩu cho bản sao được xác định trong replication_user và replication_password. Địa chỉ và cổng được sử dụng là những địa chỉ được hiển thị bằng HIỂN THỊ TẤT CẢ TRẠNG THÁI SLAVES trên máy chủ chủ cụm cũ. Trong trường hợp chuyển đổi, bản chính cũ cũng ngừng sao chép từ máy chủ bên ngoài để bảo toàn cấu trúc liên kết.
Sau khi chuyển đổi dự phòng, bản chính mới sẽ sao chép từ bản chính bên ngoài. Nếu bản chính cũ bị lỗi quay trở lại trực tuyến, nó cũng đang sao chép từ máy chủ bên ngoài. Để bình thường hóa tình huống, hãy bật auto_rejoin hoặc thực hiện rein theo cách thủ công. Thao tác này sẽ chuyển hướng cái chính cũ đến cái cái cụm hiện tại.
Chuyển đổi dự phòng hữu ích và áp dụng như thế nào?
Việc chuyển đổi dự phòng giúp bạn giảm thiểu thời gian chết, thực hiện bảo trì hàng ngày hoặc xử lý các bảo trì tai hại và không mong muốn đôi khi có thể xảy ra vào những thời điểm không may. Với khả năng của MaxScale để cách ly các ứng dụng khách khỏi máy chủ cơ sở dữ liệu phụ trợ, nó bổ sung thêm chức năng có giá trị giúp giảm thiểu thời gian chết.
Plugin giám sát MaxScale liên tục giám sát trạng thái của các máy chủ cơ sở dữ liệu phụ trợ. Sau đó, plugin định tuyến của MaxScale sử dụng thông tin trạng thái này để luôn định tuyến các truy vấn đến các máy chủ cơ sở dữ liệu phụ trợ đang được sử dụng. Sau đó, nó có thể gửi các truy vấn đến các cụm cơ sở dữ liệu phụ trợ, ngay cả khi một số máy chủ của một cụm đang được bảo trì hoặc gặp sự cố.
Khả năng cấu hình cao của MaxScale cho phép các thay đổi trong cấu hình cụm vẫn trong suốt đối với các ứng dụng khách. Ví dụ:nếu một máy chủ mới cần được thêm vào hoặc xóa về mặt quản trị khỏi một cụm chủ-tớ, bạn có thể chỉ cần thêm cấu hình MaxScale vào danh sách máy chủ gồm các plugin màn hình và bộ định tuyến thông qua bảng điều khiển maxadmin CLI. Ứng dụng khách sẽ hoàn toàn không biết về thay đổi này và sẽ tiếp tục gửi các truy vấn cơ sở dữ liệu đến cổng lắng nghe của MaxScale.
Đặt một máy chủ cơ sở dữ liệu trong bảo trì rất đơn giản và dễ dàng. Chỉ cần thực hiện lệnh sau bằng cách sử dụng maxctrl và MaxScale sẽ ngừng gửi bất kỳ truy vấn nào đến máy chủ này. Ví dụ,
maxctrl: set server DB_785 maintenance
OKSau đó, kiểm tra trạng thái máy chủ như sau,
maxctrl: list servers
┌────────┬───────────────┬──────┬─────────────┬──────────────────────┬────────────┐
│ Server │ Address │ Port │ Connections │ State │ GTID │
├────────┼───────────────┼──────┼─────────────┼──────────────────────┼────────────┤
│ DB_783 │ 192.168.10.10 │ 3306 │ 0 │ Master, Running │ 0-43001-70 │
├────────┼───────────────┼──────┼─────────────┼──────────────────────┼────────────┤
│ DB_784 │ 192.168.10.20 │ 3306 │ 0 │ Slave, Running │ 0-43001-70 │
├────────┼───────────────┼──────┼─────────────┼──────────────────────┼────────────┤
│ DB_785 │ 192.168.10.30 │ 3306 │ 0 │ Maintenance, Running │ 0-43001-70 │
└────────┴───────────────┴──────┴─────────────┴──────────────────────┴────────────┘Khi ở chế độ bảo trì, MaxScale sẽ ngừng định tuyến bất kỳ yêu cầu mới nào đến máy chủ. Đối với các yêu cầu hiện tại, MaxScale sẽ không giết các phiên này, mà cho phép nó hoàn thành việc thực thi và sẽ không làm gián đoạn bất kỳ truy vấn đang chạy nào khi ở chế độ bảo trì. Ngoài ra, hãy lưu ý rằng chế độ bảo trì không liên tục. Nếu MaxScale khởi động lại khi một nút ở chế độ bảo trì, phiên bản mới của MariaDB MaxScale sẽ không tuân theo chế độ này. Nếu nhiều cá thể MariaDB MaxScale được định cấu hình để sử dụng nút thì chế độ bảo trì phải được đặt trong mỗi cá thể MariaDB MaxScale. Tuy nhiên, nếu nhiều dịch vụ trong một phiên bản MariaDB MaxScale đang sử dụng máy chủ thì bạn chỉ cần đặt chế độ bảo trì một lần trên máy chủ cho tất cả các dịch vụ để lưu ý sự thay đổi chế độ.
Sau khi thực hiện xong việc bảo trì, chỉ cần xóa máy chủ bằng lệnh sau. Ví dụ,
maxctrl: clear server DB_785 maintenance
OKKiểm tra xem nó có được đặt trở lại bình thường hay không, chỉ cần chạy lệnh danh sách máy chủ .
Bạn cũng có thể áp dụng các hành động quản trị nhất định thông qua ClusterControl UI. Xem ảnh chụp màn hình ví dụ bên dưới:
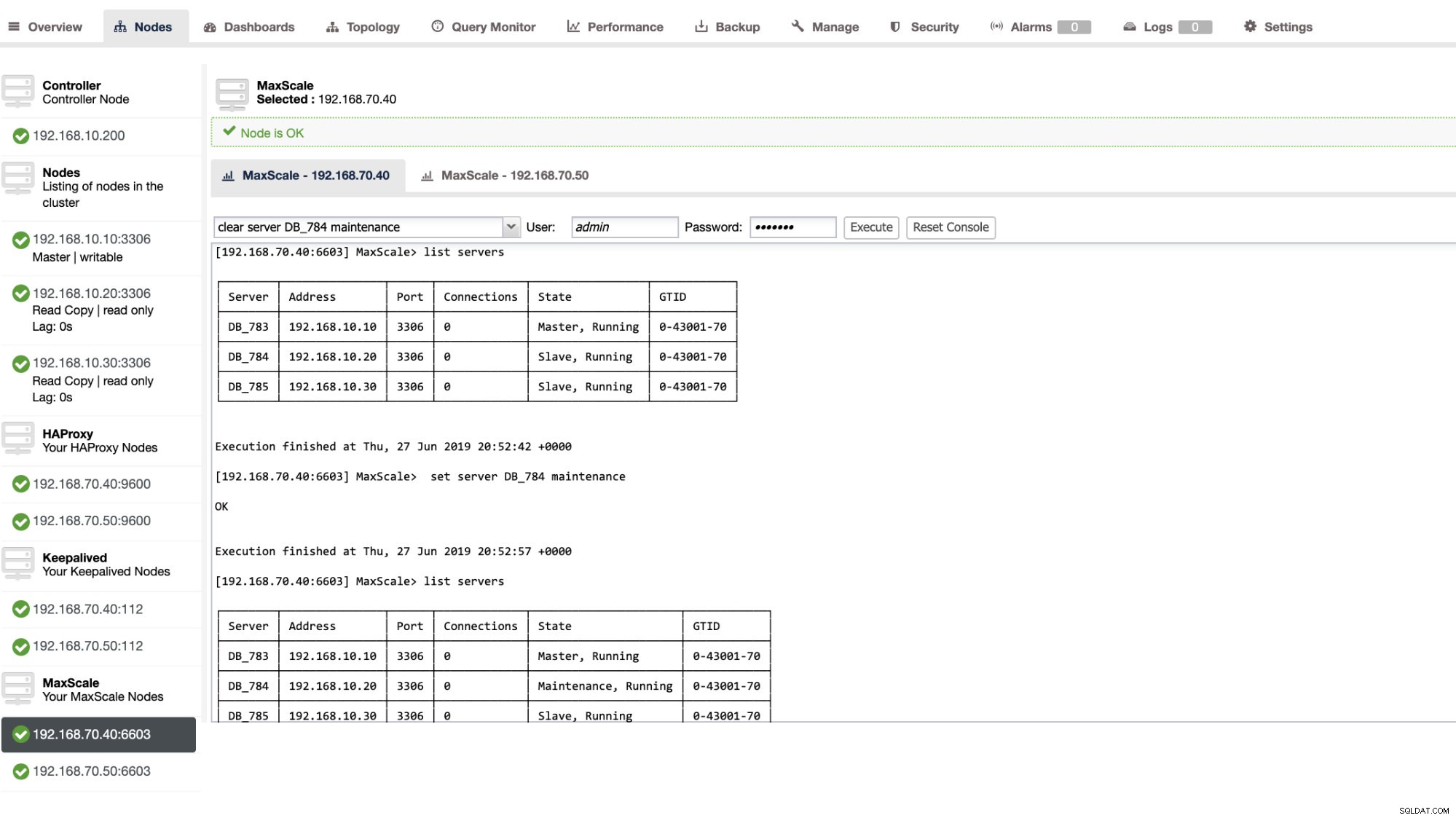
Trong hành động chuyển đổi dự phòng MaxScale
Tự động chuyển đổi dự phòng
Chuyển đổi dự phòng MaxScale của MariaDB hoạt động rất hiệu quả và cấu hình lại nô lệ cho phù hợp như mong đợi. Trong thử nghiệm này, chúng tôi có tập hợp tệp cấu hình sau được tạo và quản lý bởi ClusterControl. Xem bên dưới:
[replication_monitor]
type=monitor
servers=DB_783,DB_784,DB_785
disk_space_check_interval=1000
disk_space_threshold=/:85
detect_replication_lag=true
enforce_read_only_slaves=true
failcount=3
auto_failover=1
auto_rejoin=true
monitor_interval=300
password=725DE70F196694B277117DC825994D44
user=maxscalecc
replication_password=5349E1268CC4AF42B919A42C8E52D185
replication_user=rpl_user
module=mariadbmonLưu ý rằng, chỉ auto_failover và auto_rejoin là các biến mà tôi đã thêm vì ClusterControl sẽ không thêm điều này theo mặc định khi bạn thiết lập bộ cân bằng tải MaxScale (xem blog này về cách thiết lập MaxScale bằng ClusterControl). Đừng quên rằng bạn cần khởi động lại MariaDB MaxScale khi bạn đã áp dụng các thay đổi trong tệp cấu hình của mình. Chỉ cần chạy,
systemctl restart maxscalevà bạn tốt để đi.
Trước khi tiến hành kiểm tra chuyển đổi dự phòng, trước tiên hãy kiểm tra tình trạng của cụm:
maxctrl: list servers
┌────────┬───────────────┬──────┬─────────────┬─────────────────┬────────────┐
│ Server │ Address │ Port │ Connections │ State │ GTID │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_783 │ 192.168.10.10 │ 3306 │ 0 │ Master, Running │ 0-43001-75 │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_784 │ 192.168.10.20 │ 3306 │ 0 │ Slave, Running │ 0-43001-75 │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_785 │ 192.168.10.30 │ 3306 │ 0 │ Slave, Running │ 0-43001-75 │
└────────┴───────────────┴──────┴─────────────┴─────────────────┴────────────┘Trông tuyệt!
Tôi đã giết chủ chỉ bằng lệnh sát thủ thuần túy KILL -9 $ (pidof mysqld) trong nút chính của tôi và không có gì ngạc nhiên khi màn hình đã nhanh chóng nhận ra điều này và kích hoạt chuyển đổi dự phòng. Xem nhật ký như sau:
Lỗi2019-06-28 06:39:14.306 error : (mon_log_connect_error): Monitor was unable to connect to server DB_783[192.168.10.10:3306] : 'Can't connect to MySQL server on '192.168.10.10' (115)'
2019-06-28 06:39:14.329 notice : (mon_log_state_change): Server changed state: DB_783[192.168.10.10:3306]: master_down. [Master, Running] -> [Down]
2019-06-28 06:39:14.329 warning: (handle_auto_failover): Master has failed. If master status does not change in 2 monitor passes, failover begins.
2019-06-28 06:39:15.011 notice : (select_promotion_target): Selecting a server to promote and replace 'DB_783'. Candidates are: 'DB_784', 'DB_785'.
2019-06-28 06:39:15.011 warning: (warn_replication_settings): Slave 'DB_784' has gtid_strict_mode disabled. Enabling this setting is recommended. For more information, see https://mariadb.com/kb/en/library/gtid/#gtid_strict_mode
2019-06-28 06:39:15.012 warning: (warn_replication_settings): Slave 'DB_785' has gtid_strict_mode disabled. Enabling this setting is recommended. For more information, see https://mariadb.com/kb/en/library/gtid/#gtid_strict_mode
2019-06-28 06:39:15.012 notice : (select_promotion_target): Selected 'DB_784'.
2019-06-28 06:39:15.012 notice : (handle_auto_failover): Performing automatic failover to replace failed master 'DB_783'.
2019-06-28 06:39:15.017 notice : (redirect_slaves_ex): Redirecting 'DB_785' to replicate from 'DB_784' instead of 'DB_783'.
2019-06-28 06:39:15.024 notice : (redirect_slaves_ex): All redirects successful.
2019-06-28 06:39:15.527 notice : (wait_cluster_stabilization): All redirected slaves successfully started replication from 'DB_784'.
2019-06-28 06:39:15.527 notice : (handle_auto_failover): Failover 'DB_783' -> 'DB_784' performed.
2019-06-28 06:39:15.634 notice : (mon_log_state_change): Server changed state: DB_784[192.168.10.20:3306]: new_master. [Slave, Running] -> [Master, Running]
2019-06-28 06:39:20.165 notice : (mon_log_state_change): Server changed state: DB_783[192.168.10.10:3306]: slave_up. [Down] -> [Slave, Running]Bây giờ chúng ta hãy xem xét tình trạng của cụm của nó,
maxctrl: list servers
┌────────┬───────────────┬──────┬─────────────┬─────────────────┬────────────┐
│ Server │ Address │ Port │ Connections │ State │ GTID │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_783 │ 192.168.10.10 │ 3306 │ 0 │ Down │ 0-43001-75 │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_784 │ 192.168.10.20 │ 3306 │ 0 │ Master, Running │ 0-43001-75 │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_785 │ 192.168.10.30 │ 3306 │ 0 │ Slave, Running │ 0-43001-75 │
└────────┴───────────────┴──────┴─────────────┴─────────────────┴────────────┘Nút 192.168.10.10 trước đây là nút chính đã bị lỗi. Tôi đã cố gắng khởi động lại và xem liệu tự động tham gia lại có kích hoạt hay không và như bạn nhận thấy trong nhật ký tại thời điểm 2019-06-28 06:39:20.165, quá nhanh để nắm bắt trạng thái của nút và sau đó thiết lập cấu hình tự động mà không gặp khó khăn gì để DBA bật nó lên.
Bây giờ, kiểm tra lần cuối trạng thái của nó, nó có vẻ hoạt động hoàn hảo như mong đợi. Xem bên dưới:
maxctrl: list servers
┌────────┬───────────────┬──────┬─────────────┬─────────────────┬────────────┐
│ Server │ Address │ Port │ Connections │ State │ GTID │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_783 │ 192.168.10.10 │ 3306 │ 0 │ Slave, Running │ 0-43001-75 │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_784 │ 192.168.10.20 │ 3306 │ 0 │ Master, Running │ 0-43001-75 │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_785 │ 192.168.10.30 │ 3306 │ 0 │ Slave, Running │ 0-43001-75 │
└────────┴───────────────┴──────┴─────────────┴─────────────────┴────────────┘Chủ cũ của tôi đã được sửa và phục hồi và tôi muốn chuyển sang
Chuyển sang chủ cũ của bạn cũng không có gì phức tạp. Bạn có thể vận hành điều này với maxctrl (hoặc maxadmin trong các phiên bản trước của MaxScale) hoặc thông qua giao diện người dùng ClusterControl (như đã trình bày trước đây).
Chúng ta hãy chỉ tham khảo trạng thái trước đó của tình trạng cụm sao chép trước đó và muốn chuyển 192.168.10.10 (hiện tại là nô lệ), trở lại trạng thái chính của nó. Trước khi chúng tôi tiếp tục, trước tiên bạn có thể cần xác định màn hình bạn sẽ sử dụng. Bạn có thể xác minh điều này bằng lệnh sau:
maxctrl: list monitors
┌─────────────────────┬─────────┬────────────────────────┐
│ Monitor │ State │ Servers │
├─────────────────────┼─────────┼────────────────────────┤
│ replication_monitor │ Running │ DB_783, DB_784, DB_785 │
└─────────────────────┴─────────┴────────────────────────┘Sau khi có nó, bạn có thể thực hiện lệnh sau để chuyển đổi:
maxctrl: call command mariadbmon switchover replication_monitor DB_783 DB_784
OKSau đó, kiểm tra lại trạng thái của cụm,
maxctrl: list servers
┌────────┬───────────────┬──────┬─────────────┬─────────────────┬────────────┐
│ Server │ Address │ Port │ Connections │ State │ GTID │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_783 │ 192.168.10.10 │ 3306 │ 0 │ Master, Running │ 0-43001-75 │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_784 │ 192.168.10.20 │ 3306 │ 0 │ Slave, Running │ 0-43001-75 │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_785 │ 192.168.10.30 │ 3306 │ 0 │ Slave, Running │ 0-43001-75 │
└────────┴───────────────┴──────┴─────────────┴─────────────────┴────────────┘Trông thật hoàn hảo!
Nhật ký sẽ cho bạn thấy rõ ràng nó đã diễn ra như thế nào và chuỗi hành động của nó trong quá trình chuyển đổi. Xem chi tiết bên dưới:
Lỗi2019-06-28 07:03:48.064 error : (switchover_prepare): 'DB_784' is not a valid promotion target for switchover because it is already the master.
2019-06-28 07:03:48.064 error : (manual_switchover): Switchover cancelled.
2019-06-28 07:04:30.700 notice : (create_start_slave): Slave connection from DB_784 to [192.168.10.10]:3306 created and started.
2019-06-28 07:04:30.700 notice : (redirect_slaves_ex): Redirecting 'DB_785' to replicate from 'DB_783' instead of 'DB_784'.
2019-06-28 07:04:30.708 notice : (redirect_slaves_ex): All redirects successful.
2019-06-28 07:04:31.209 notice : (wait_cluster_stabilization): All redirected slaves successfully started replication from 'DB_783'.
2019-06-28 07:04:31.209 notice : (manual_switchover): Switchover 'DB_784' -> 'DB_783' performed.
2019-06-28 07:04:31.318 notice : (mon_log_state_change): Server changed state: DB_783[192.168.10.10:3306]: new_master. [Slave, Running] -> [Master, Running]
2019-06-28 07:04:31.318 notice : (mon_log_state_change): Server changed state: DB_784[192.168.10.20:3306]: new_slave. [Master, Running] -> [Slave, Running]Trong trường hợp chuyển nhầm, nó sẽ không tiếp tục và do đó nó sẽ tạo ra lỗi như được hiển thị trong nhật ký ở trên. Vì vậy, bạn sẽ an toàn và không có bất ngờ đáng sợ nào cả.
Làm cho MaxScale của bạn luôn sẵn sàng
Mặc dù nó hơi lạc đề về chuyển đổi dự phòng, nhưng tôi muốn bổ sung một số điểm có giá trị ở đây liên quan đến tính khả dụng cao và cách nó liên quan đến chuyển đổi dự phòng MariaDB MaxScale.
Làm cho MaxScale của bạn luôn khả dụng là một phần quan trọng trong trường hợp hệ thống của bạn gặp sự cố, gặp sự cố đĩa hoặc hỏng máy ảo. Những tình huống này là không thể tránh khỏi và có thể ảnh hưởng đến trạng thái thiết lập chuyển đổi dự phòng tự động của bạn khi các chu kỳ bảo trì không mong muốn này xảy ra.
Đối với môi trường kiểu cụm sao chép, điều này rất có lợi và rất được khuyến khích cho một thiết lập MaxScale cụ thể. Mục đích của việc này là, chỉ một cá thể MaxScale được phép sửa đổi cụm tại bất kỳ thời điểm nào. Nếu bạn đã thiết lập với Keepalived, đây là nơi hiển thị các phiên bản có trạng thái MASTER. Bản thân MaxScale không biết trạng thái của nó, nhưng với maxctrl (hoặc maxadmin trong các phiên bản trước) có thể đặt một phiên bản MaxScale thành chế độ thụ động. Kể từ phiên bản 2.2.2, MaxScale thụ động hoạt động tương tự như hoạt động với điểm khác biệt là nó sẽ không thực hiện chuyển đổi dự phòng, chuyển đổi hoặc tham gia lại. Ngay cả các phiên bản thủ công của các lệnh này cũng sẽ kết thúc bằng lỗi. Sự khác biệt về chế độ thụ động / chủ động có thể được mở rộng trong tương lai, vì vậy hãy theo dõi những thay đổi như vậy trong MaxScale. Để làm điều này, chỉ cần làm như sau:
maxctrl: alter maxscale passive true
OKBạn có thể xác minh điều này sau đó bằng cách chạy lệnh dưới đây:
[example@sqldat.com vagrant]# maxctrl -u admin -p mariadb -h 127.0.0.1:8989 show maxscale|grep 'passive'
│ │ "passive": true, │Nếu bạn muốn kiểm tra cách thiết lập khả dụng cao với Keepalived, vui lòng xem bài đăng này từ MariaDB.
Xử lý VIP
Ngoài ra, vì MaxScale không tích hợp sẵn tính năng xử lý VIP, bạn có thể sử dụng Keepalived để xử lý điều đó cho bạn. Bạn chỉ có thể sử dụng virtual_ipaddress được gán cho nút trạng thái MASTER. Điều này có thể dẫn đến quản lý IP ảo giống như MHA thực hiện với biến master_failover_script. Như đã đề cập trước đó, hãy xem bài đăng trên blog thiết lập Keepalived với MaxScale này của MariaDB.
Kết luận
MariaDB MaxScale rất giàu tính năng và có nhiều khả năng, không chỉ giới hạn ở việc trở thành một proxy và bộ cân bằng tải, mà nó còn cung cấp cơ chế chuyển đổi dự phòng mà các tổ chức lớn đang tìm kiếm. Nó gần như là một phần mềm phù hợp với mọi kích thước, nhưng tất nhiên đi kèm với những hạn chế mà một ứng dụng nhất định có thể cần để tương phản với các trình cân bằng tải khác như ProxySQL.
ClusterControl cũng cung cấp cơ chế tự động phát hiện chủ và tự động chuyển đổi dự phòng, cộng với khôi phục cụm và nút với khả năng triển khai Maxscale và các công nghệ cân bằng tải khác.
Mỗi công cụ này đều có các tính năng và chức năng đa dạng, nhưng MariaDB MaxScale được hỗ trợ tốt trong ClusterControl và có thể được triển khai khả thi cùng với Keepalived, HAProxy để giúp bạn tăng tốc cho công việc hàng ngày của mình.