Ngay sau khi bạn bắt đầu chạy một máy chủ cơ sở dữ liệu và việc sử dụng của bạn tăng lên, bạn sẽ gặp phải nhiều loại sự cố kỹ thuật, suy giảm hiệu suất và trục trặc cơ sở dữ liệu. Mỗi điều trong số này có thể dẫn đến các vấn đề lớn hơn nhiều, chẳng hạn như thất bại nghiêm trọng hoặc mất dữ liệu. Nó giống như một phản ứng dây chuyền, trong đó điều này có thể dẫn đến điều khác, gây ra ngày càng nhiều vấn đề. Các biện pháp đối phó chủ động phải được thực hiện để bạn có được một môi trường ổn định lâu nhất có thể.
Trong bài đăng blog này, chúng ta sẽ xem xét một loạt các tính năng thú vị được cung cấp bởi ClusterControl có thể giúp chúng ta khắc phục sự cố và khắc phục sự cố cơ sở dữ liệu MySQL khi chúng xảy ra.
Cảnh báo và Thông báo cho Cơ sở dữ liệu
Đối với tất cả các sự kiện không mong muốn, ClusterControl sẽ ghi lại mọi thứ trong Báo thức, có thể truy cập trên Hoạt động (Menu trên cùng) của trang ClusterControl. Đây thường là bước đầu tiên để bắt đầu khắc phục sự cố khi có sự cố. Từ trang này, chúng tôi có thể có ý tưởng về những gì đang thực sự diễn ra với cụm cơ sở dữ liệu của chúng tôi:
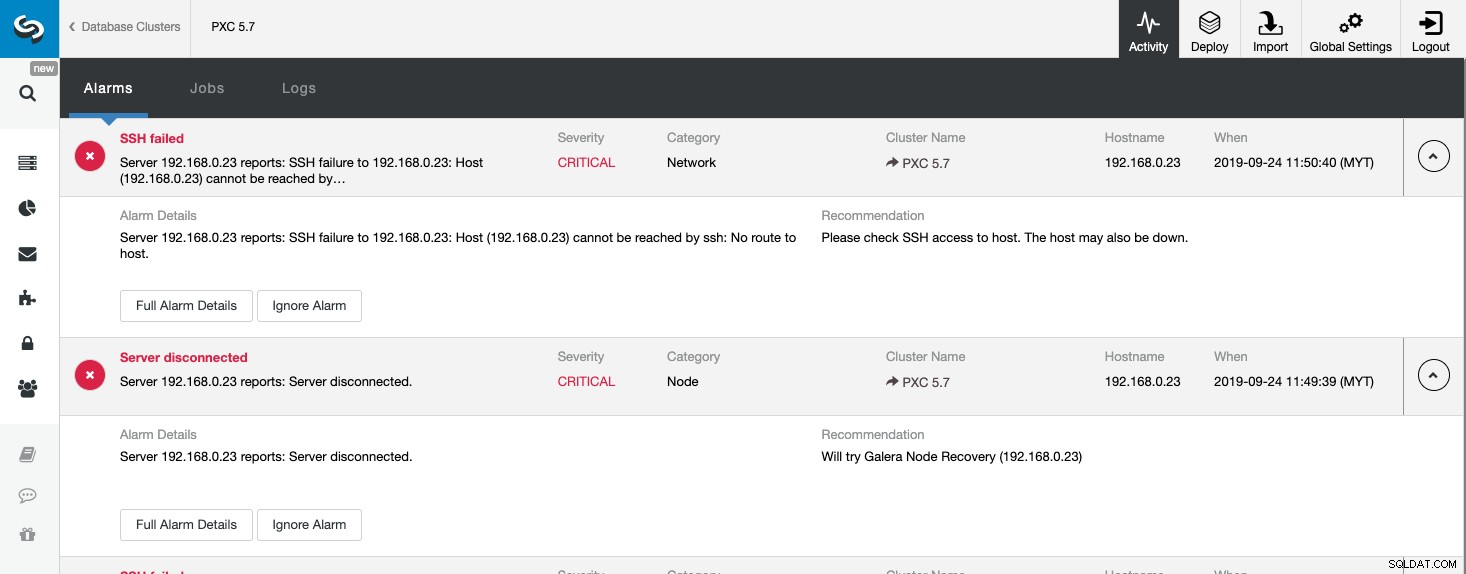
Ảnh chụp màn hình trên cho thấy một ví dụ về sự kiện không thể truy cập máy chủ, với mức độ nghiêm trọng CRITICAL , được phát hiện bởi hai thành phần, Mạng và Nút. Nếu bạn đã định cấu hình cài đặt thông báo qua email, bạn sẽ nhận được một bản sao của những cảnh báo này trong hộp thư của mình.
Khi nhấp vào "Chi tiết báo thức đầy đủ", bạn có thể nhận được các chi tiết quan trọng của báo thức như tên máy chủ, dấu thời gian, tên cụm, v.v. Nó cũng cung cấp bước khuyến nghị tiếp theo để thực hiện. Bạn cũng có thể gửi cảnh báo này dưới dạng email đến những người nhận khác được định cấu hình trong Cài đặt thông báo qua email.
Bạn cũng có thể chọn tắt tiếng báo thức bằng cách nhấp vào nút "Bỏ qua báo thức" và nó sẽ không xuất hiện trong danh sách nữa. Bỏ qua một báo động có thể hữu ích nếu bạn có một cảnh báo mức độ nghiêm trọng thấp và biết cách xử lý hoặc giải quyết vấn đề đó. Ví dụ:nếu ClusterControl phát hiện một chỉ mục trùng lặp trong cơ sở dữ liệu của bạn, thì trong một số trường hợp, các ứng dụng kế thừa của bạn sẽ cần đến một chỉ mục.
Bằng cách xem trang này, chúng ta có thể hiểu ngay điều gì đang xảy ra với cụm cơ sở dữ liệu của mình và bước tiếp theo phải làm để giải quyết vấn đề. Như trong trường hợp này, một trong các nút cơ sở dữ liệu đã gặp sự cố và không thể truy cập được qua SSH từ máy chủ ClusterControl. Ngay cả một SysAdmin mới bắt đầu bây giờ cũng sẽ biết phải làm gì tiếp theo nếu cảnh báo này xuất hiện.
Tệp nhật ký cơ sở dữ liệu tập trung
Đây là nơi chúng tôi có thể tìm hiểu xem có gì sai với máy chủ cơ sở dữ liệu của chúng tôi. Trong ClusterControl -> Nhật ký -> Nhật ký Hệ thống, bạn có thể xem tất cả các tệp nhật ký liên quan đến cụm cơ sở dữ liệu. Đối với cụm cơ sở dữ liệu dựa trên MySQL, ClusterControl kéo nhật ký ProxySQL, nhật ký lỗi MySQL và nhật ký sao lưu:
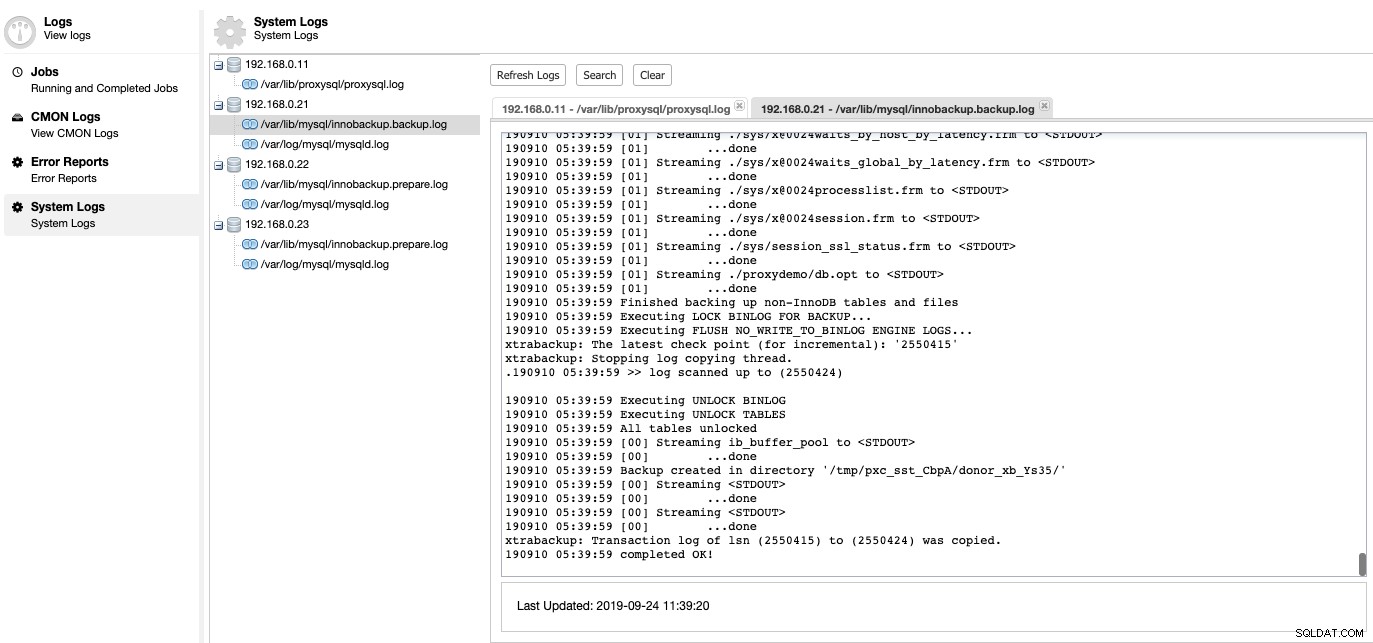
Nhấp vào "Làm mới Nhật ký" để truy xuất nhật ký mới nhất từ tất cả các máy chủ có thể truy cập vào thời điểm cụ thể đó. Nếu một nút không thể truy cập được, ClusterControl sẽ vẫn xem nhật ký đã lỗi thời vì thông tin này được lưu trữ bên trong cơ sở dữ liệu CMON. Theo mặc định, ClusterControl tiếp tục truy xuất nhật ký hệ thống 10 phút một lần, có thể định cấu hình trong Cài đặt -> Khoảng thời gian ghi nhật ký.
ClusterControl sẽ kích hoạt công việc để lấy nhật ký mới nhất từ mỗi máy chủ, như được hiển thị trong công việc "Thu thập nhật ký" sau:
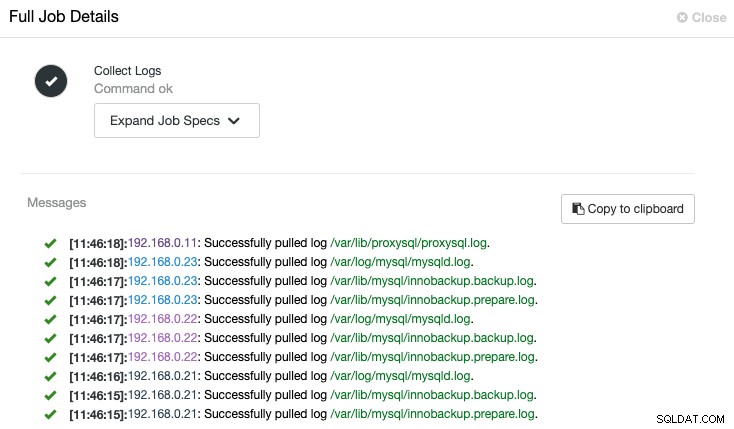
Chế độ xem tập trung của tệp nhật ký cho phép chúng tôi hiểu nhanh hơn về những gì đã xảy ra Sai lầm. Đối với một cụm cơ sở dữ liệu thường liên quan đến nhiều nút và tầng, tính năng này sẽ cải thiện đáng kể việc đọc nhật ký trong đó SysAdmin có thể so sánh các nhật ký này song song và xác định các sự kiện quan trọng, giảm tổng thời gian khắc phục sự cố.
Bảng điều khiển SSH trên web
ClusterControl cung cấp bảng điều khiển SSH dựa trên web để bạn có thể truy cập trực tiếp vào máy chủ DB thông qua giao diện người dùng ClusterControl (vì người dùng SSH được định cấu hình để kết nối với máy chủ cơ sở dữ liệu). Từ đây, chúng tôi có thể thu thập thêm nhiều thông tin cho phép chúng tôi khắc phục sự cố nhanh hơn. Mọi người đều biết khi sự cố cơ sở dữ liệu xảy ra với hệ thống sản xuất, mỗi giây thời gian chết đều có giá trị.
Để truy cập bảng điều khiển SSH qua web, chỉ cần chọn các nút trong Node -> Node Actions -> SSH Console hoặc chỉ cần nhấp vào biểu tượng bánh răng để tìm lối tắt:
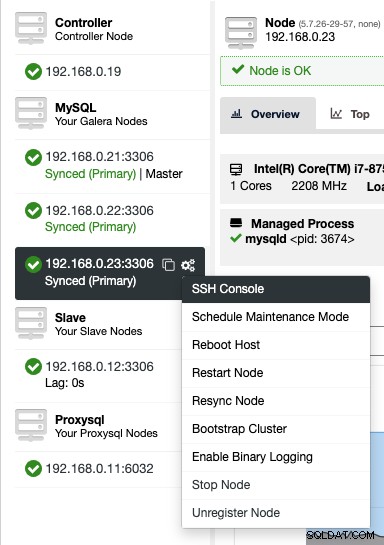
Do lo ngại về bảo mật có thể xảy ra với tính năng này, đặc biệt là đối với đa -người dùng hoặc môi trường nhiều người thuê, người ta có thể vô hiệu hóa nó bằng cách truy cập /var/www/html/clustercontrol/bootstrap.php trên máy chủ ClusterControl và đặt hằng số sau thành false:
define('SSH_ENABLED', false);Làm mới trang Giao diện người dùng ClusterControl để tải các thay đổi mới.
Vấn đề về Hiệu suất Cơ sở dữ liệu
Ngoài các tính năng theo dõi và xu hướng, ClusterControl chủ động gửi cho bạn nhiều cảnh báo và lời khuyên liên quan đến hiệu suất cơ sở dữ liệu, ví dụ:
- Sử dụng quá mức - Tài nguyên vượt qua các ngưỡng nhất định như CPU, bộ nhớ, mức sử dụng hoán đổi và dung lượng đĩa.
- Suy giảm cụm - Phân vùng theo cụm và mạng.
- Thời gian trôi dạt của hệ thống - Chênh lệch thời gian giữa tất cả các nút trong cụm (bao gồm cả nút ClusterControl).
- Nhiều cố vấn khác có liên quan đến MySQL:
- Tái tạo - độ trễ sao chép, hết hạn binlog, vị trí và tốc độ tăng trưởng
- Galera - phương pháp SST, quét tệp nhật ký GRA, trình kiểm tra địa chỉ cụm
- Kiểm tra giản đồ - Sự tồn tại của bảng không phải giao dịch trên Galera Cluster.
- Kết nối - Tỷ lệ kết nối luồng
- InnoDB - Tỷ lệ trang bẩn, tăng trưởng tệp nhật ký InnoDB
- Truy vấn chậm - Theo mặc định, ClusterControl sẽ báo động nếu phát hiện một truy vấn đang chạy hơn 30 giây. Tất nhiên, điều này có thể định cấu hình trong Cài đặt -> Cấu hình thời gian chạy -> Truy vấn dài.
- Bế tắc - Bế tắc giao dịch InnoDB và bế tắc Galera.
- Chỉ mục - Các khóa trùng lặp, bảng không có khóa chính.
Kiểm tra trang Cố vấn trong Hiệu suất -> Cố vấn để biết chi tiết về những thứ có thể được cải thiện theo đề xuất của ClusterControl. Đối với mọi cố vấn, nó cung cấp những lý do và lời khuyên như được hiển thị trong ví dụ sau cho cố vấn "Kiểm tra việc sử dụng dung lượng đĩa":
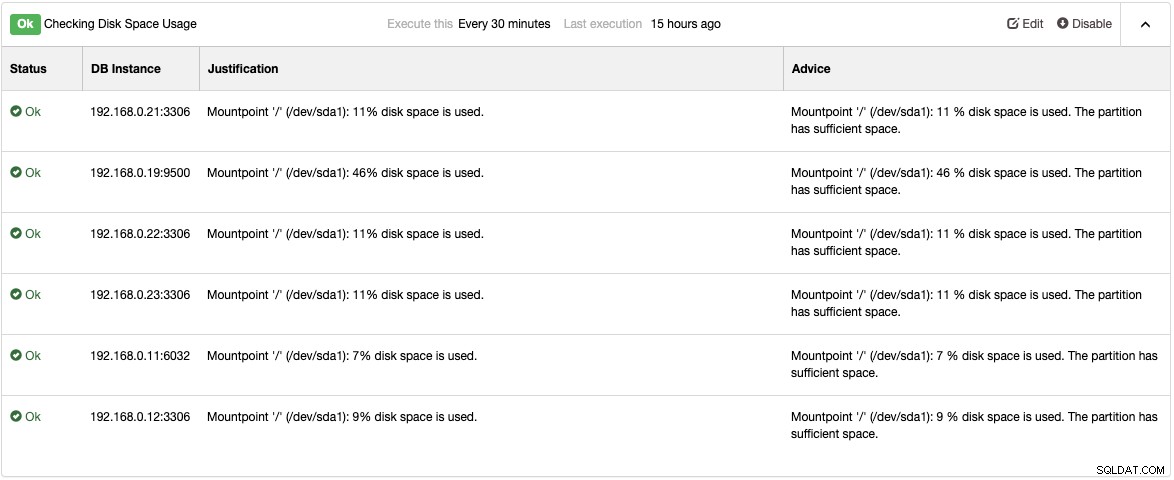
Khi sự cố hiệu suất xảy ra, bạn sẽ nhận được "Cảnh báo" (màu vàng) hoặc Trạng thái "quan trọng" (màu đỏ) trên các cố vấn này. Thường cần phải điều chỉnh thêm để khắc phục sự cố. Các cố vấn nâng cao cảnh báo, có nghĩa là, người dùng sẽ nhận được một bản sao của những cảnh báo này bên trong hộp thư nếu Thông báo qua email được định cấu hình phù hợp. Đối với mọi cảnh báo do ClusterControl hoặc các cố vấn của ClusterControl hoặc cố vấn của nó đưa ra, người dùng cũng sẽ nhận được email nếu cảnh báo đã được xóa. Chúng được cấu hình sẵn trong ClusterControl và không yêu cầu cấu hình ban đầu. Luôn có thể tùy chỉnh thêm trong Quản lý -> Studio dành cho nhà phát triển. Bạn có thể xem bài đăng trên blog này về cách viết cố vấn của riêng bạn.
ClusterControl cũng cung cấp một trang chuyên dụng liên quan đến hiệu suất cơ sở dữ liệu trong ClusterControl -> Performance. Nó cung cấp tất cả các loại thông tin chi tiết về cơ sở dữ liệu theo các phương pháp hay nhất như chế độ xem tập trung của Trạng thái DB, Biến, trạng thái InnoDB, Trình phân tích lược đồ, Nhật ký giao dịch. Những điều này khá dễ hiểu và dễ hiểu.
Đối với hiệu suất truy vấn, bạn có thể kiểm tra Truy vấn Hàng đầu và Ngoại trừ Truy vấn, trong đó ClusterControl đánh dấu các truy vấn thực hiện khác biệt đáng kể so với truy vấn trung bình của chúng. Chúng tôi đã trình bày chi tiết về chủ đề này trong bài đăng blog này, Điều chỉnh Hiệu suất Truy vấn MySQL.
Báo cáo Lỗi Cơ sở dữ liệu
ClusterControl đi kèm với một công cụ tạo báo cáo lỗi, để thu thập thông tin gỡ lỗi về cụm cơ sở dữ liệu của bạn nhằm giúp hiểu được tình hình và trạng thái hiện tại. Để tạo báo cáo lỗi, chỉ cần đi tới ClusterControl -> Nhật ký -> Báo cáo lỗi -> Tạo báo cáo lỗi:
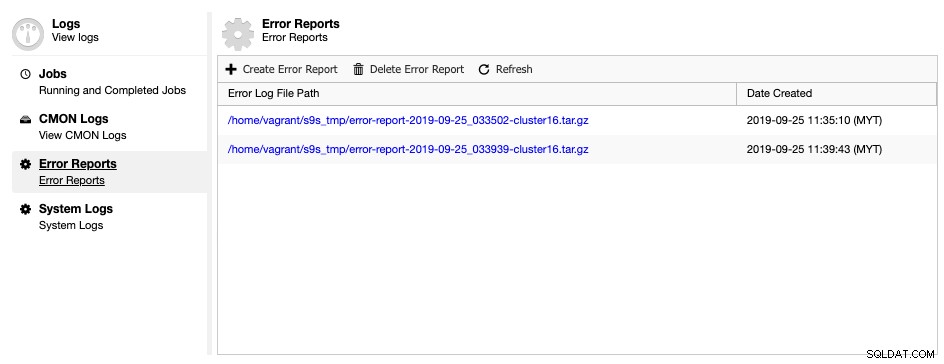
Có thể tải xuống báo cáo lỗi đã tạo từ trang này sau khi đã sẵn sàng. Báo cáo được tạo này sẽ ở định dạng TAR ball (tar.gz) và bạn có thể đính kèm nó vào một yêu cầu hỗ trợ. Vì vé hỗ trợ có giới hạn kích thước tệp là 10MB, nếu kích thước tarball lớn hơn, bạn có thể tải nó lên ổ đĩa đám mây và chỉ chia sẻ với chúng tôi liên kết tải xuống khi có sự cho phép thích hợp. Bạn có thể xóa nó sau khi chúng tôi đã có tệp. Bạn cũng có thể tạo báo cáo lỗi thông qua dòng lệnh như được giải thích trong trang tài liệu Báo cáo lỗi.
Trong trường hợp ngừng hoạt động, chúng tôi thực sự khuyên bạn nên tạo nhiều báo cáo lỗi trong và ngay sau khi ngừng hoạt động. Những báo cáo đó sẽ rất hữu ích để cố gắng hiểu điều gì đã xảy ra, hậu quả của việc ngừng hoạt động và xác minh rằng trên thực tế cụm đã trở lại trạng thái hoạt động sau một sự kiện thảm khốc.
Kết luận
Giám sát chủ động ClusterControl, cùng với một tập hợp các tính năng khắc phục sự cố, cung cấp một nền tảng hiệu quả cho người dùng để khắc phục bất kỳ loại sự cố cơ sở dữ liệu MySQL nào. Đã từ lâu là cách khắc phục sự cố kế thừa trong đó người ta phải mở nhiều phiên SSH để truy cập nhiều máy chủ và thực thi nhiều lệnh lặp lại để xác định nguyên nhân gốc rễ.
Nếu các tính năng được đề cập ở trên không giúp bạn giải quyết sự cố hoặc khắc phục sự cố cơ sở dữ liệu, bạn luôn liên hệ với Nhóm hỗ trợ của Somenines để hỗ trợ bạn. Các chuyên gia kỹ thuật tận tâm 24/7/365 của chúng tôi luôn sẵn sàng đáp ứng yêu cầu của bạn bất cứ lúc nào. Thời gian trả lời đầu tiên trung bình của chúng tôi thường dưới 30 phút.