Nếu cơ sở hạ tầng CNTT của bạn đang chạy trên AWS, bạn có thể đã nghe nói về Dịch vụ cơ sở dữ liệu quan hệ của Amazon (RDS), một cách dễ dàng để thiết lập, vận hành và mở rộng cơ sở dữ liệu quan hệ trên đám mây. Nó cung cấp khả năng thay đổi kích thước và hiệu quả về chi phí đồng thời tự động hóa các tác vụ quản trị tốn thời gian như cung cấp phần cứng, thiết lập cơ sở dữ liệu, vá lỗi và sao lưu. Có một số dịch vụ công cụ cơ sở dữ liệu cho RDS như MySQL, MariaDB, PostgreSQL, Microsoft SQL Server và Oracle Server.
ClusterControl 1.7.3 hoạt động tương tự như RDS vì nó hỗ trợ triển khai, quản lý, giám sát và mở rộng cụm cơ sở dữ liệu trên nền tảng AWS. Nó cũng hỗ trợ một số nền tảng đám mây khác như Google Cloud Platform và Microsoft Azure. ClusterControl hiểu cấu trúc liên kết cơ sở dữ liệu và có khả năng thực hiện khôi phục tự động, quản lý cấu trúc liên kết và nhiều tính năng nâng cao khác để kiểm soát cơ sở dữ liệu của bạn.
Trong bài đăng trên blog này, chúng tôi sẽ so sánh thời gian chuyển đổi dự phòng tự động cho Amazon Aurora, Amazon RDS cho MySQL và thiết lập MySQL Replication được ClusterControl triển khai và quản lý. Loại chuyển đổi dự phòng mà chúng tôi sẽ làm là xúc tiến nô lệ trong trường hợp chủ bị hỏng. Đây là nơi nô lệ cập nhật nhất đảm nhận vai trò chủ trong cụm để tiếp tục dịch vụ cơ sở dữ liệu.
Kiểm tra chuyển đổi dự phòng của chúng tôi
Để đo thời gian chuyển đổi dự phòng, chúng ta sẽ chạy một bài kiểm tra cập nhật kết nối MySQL đơn giản, với một vòng lặp để đếm trạng thái câu lệnh SQL kết nối với một điểm cuối cơ sở dữ liệu. Tập lệnh trông như thế này:
#!/bin/bash
_host='{MYSQL ENDPOINT}'
_user='sbtest'
_pass='password'
_port=3306
j=1
while true
do
echo -n "count $j : "
num=$(od -A n -t d -N 1 /dev/urandom |tr -d ' ')
timeout 1 bash -c "mysql -u${_user} -p${_pass} -h${_host} -P${_port} --connect-timeout=1 --disable-reconnect -A -Bse \
\"UPDATE sbtest.sbtest1 SET k = $num WHERE id = 1\" > /dev/null 2> /dev/null"
if [ $? -eq 0 ]; then
echo "OK $(date)"
else
echo "Fail ---- $(date)"
fi
j=$(( $j + 1 ))
sleep 1
done
Tập lệnh Bash ở trên chỉ cần kết nối với máy chủ MySQL và thực hiện cập nhật trên một hàng duy nhất với thời gian chờ là 1 giây trên cả lệnh máy khách Bash và mysql. Các thông số liên quan đến thời gian chờ là bắt buộc để chúng tôi có thể đo thời gian chết tính bằng giây một cách chính xác vì máy khách mysql mặc định luôn kết nối lại cho đến khi nó đến được MySQL wait_timeout. Chúng tôi đã điền trước tập dữ liệu thử nghiệm bằng lệnh sau:
$ sysbench \
/usr/share/sysbench/oltp_common.lua \
--db-driver=mysql \
--mysql-host={MYSQL HOST} \
--mysql-user=sbtest \
--mysql-db=sbtest \
--mysql-password=password \
--tables=50 \
--table-size=100000 \
prepareTập lệnh báo cáo truy vấn ở trên thành công (OK) hay không thành công (Fail). Kết quả đầu ra mẫu được hiển thị ở phía dưới.
Chuyển đổi dự phòng với Amazon RDS cho MySQL
Trong thử nghiệm của mình, chúng tôi sử dụng dịch vụ RDS thấp nhất với các thông số kỹ thuật sau:
- Phiên bản MySQL:5.7.22
- vCPU:4
- RAM:16 GB
- Loại lưu trữ:IOPS được cung cấp (SSD)
- IOPS:1000
- Bộ nhớ:100Gib
- Sao chép nhiều AZ:Có
Sau khi Amazon RDS cung cấp phiên bản DB của bạn, bạn có thể sử dụng bất kỳ ứng dụng hoặc tiện ích máy khách MySQL tiêu chuẩn nào để kết nối với phiên bản. Trong chuỗi kết nối, bạn chỉ định địa chỉ DNS từ điểm cuối phiên bản DB làm tham số máy chủ và chỉ định số cổng từ điểm cuối phiên bản DB làm tham số cổng.
Theo trang tài liệu Amazon RDS, trong trường hợp phiên bản DB của bạn ngừng hoạt động theo kế hoạch hoặc ngoài kế hoạch, Amazon RDS sẽ tự động chuyển sang bản sao dự phòng trong Vùng khả dụng khác nếu bạn đã bật Multi-AZ. Thời gian cần thiết để quá trình chuyển đổi dự phòng hoàn thành phụ thuộc vào hoạt động cơ sở dữ liệu và các điều kiện khác tại thời điểm cá thể DB chính không khả dụng. Thời gian chuyển đổi dự phòng thường là 60-120 giây.
Để bắt đầu chuyển đổi dự phòng nhiều AZ trong RDS, chúng tôi đã thực hiện thao tác khởi động lại với chọn "Khởi động lại với chuyển đổi dự phòng", như được hiển thị trong ảnh chụp màn hình sau:
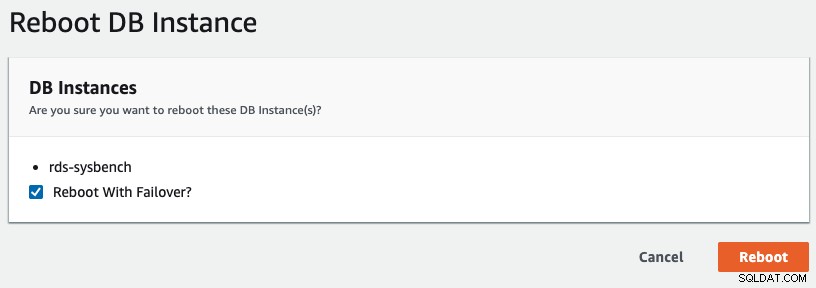
Sau đây là những gì được ứng dụng của chúng tôi quan sát thấy:
...
count 30 : OK Wed Aug 28 03:41:06 UTC 2019
count 31 : OK Wed Aug 28 03:41:07 UTC 2019
count 32 : Fail ---- Wed Aug 28 03:41:09 UTC 2019
count 33 : Fail ---- Wed Aug 28 03:41:11 UTC 2019
count 34 : Fail ---- Wed Aug 28 03:41:13 UTC 2019
count 35 : Fail ---- Wed Aug 28 03:41:15 UTC 2019
count 36 : Fail ---- Wed Aug 28 03:41:17 UTC 2019
count 37 : Fail ---- Wed Aug 28 03:41:19 UTC 2019
count 38 : Fail ---- Wed Aug 28 03:41:21 UTC 2019
count 39 : Fail ---- Wed Aug 28 03:41:23 UTC 2019
count 40 : Fail ---- Wed Aug 28 03:41:25 UTC 2019
count 41 : Fail ---- Wed Aug 28 03:41:27 UTC 2019
count 42 : Fail ---- Wed Aug 28 03:41:29 UTC 2019
count 43 : Fail ---- Wed Aug 28 03:41:31 UTC 2019
count 44 : Fail ---- Wed Aug 28 03:41:33 UTC 2019
count 45 : Fail ---- Wed Aug 28 03:41:35 UTC 2019
count 46 : OK Wed Aug 28 03:41:36 UTC 2019
count 47 : OK Wed Aug 28 03:41:37 UTC 2019
...Thời gian ngừng hoạt động của MySQL như đã thấy ở phía ứng dụng đã bắt đầu từ 03:41:09 cho đến 03:41:36, tổng cộng khoảng 27 giây. Từ các sự kiện RDS, chúng ta có thể thấy chuyển đổi dự phòng đa AZ chỉ xảy ra 15 giây sau thời gian ngừng hoạt động thực tế:
Wed, 28 Aug 2019 03:41:24 GMT Multi-AZ instance failover started.
Wed, 28 Aug 2019 03:41:33 GMT DB instance restarted
Wed, 28 Aug 2019 03:41:59 GMT Multi-AZ instance failover completed.Sau khi phiên bản cơ sở dữ liệu mới khởi động lại vào khoảng 03:41:33, dịch vụ MySQL sau đó có thể truy cập vào khoảng 3 giây sau đó.
Chuyển đổi dự phòng với Amazon Aurora cho MySQL
Amazon Aurora có thể được coi là phiên bản cao cấp của RDS, với rất nhiều tính năng đáng chú ý như sao chép nhanh hơn với bộ nhớ dùng chung, không mất dữ liệu khi chuyển đổi dự phòng và giới hạn lưu trữ lên đến 64TB. Amazon Aurora cho MySQL dựa trên MySQL Edition mã nguồn mở, nhưng bản thân nó không phải là mã nguồn mở; nó là một cơ sở dữ liệu mã nguồn đóng, độc quyền. Nó hoạt động tương tự với bản sao MySQL (một và chỉ một bản chính, với nhiều nô lệ) và chuyển đổi dự phòng được Amazon Aurora xử lý tự động.
Theo Amazon Aurora FAQS, nếu bạn có Bản sao Amazon Aurora, trong cùng một hoặc một Vùng khả dụng khác, khi bị lỗi, Aurora sẽ lật bản ghi tên chuẩn (CNAME) cho Bản sao DB của bạn để chỉ vào bản sao lành mạnh, nằm trong đến lượt được thăng chức để trở thành chính mới. Bắt đầu từ đầu đến cuối, chuyển đổi dự phòng thường hoàn thành trong vòng 30 giây.
Nếu bạn không có Bản sao Amazon Aurora (tức là một bản sao duy nhất), Aurora trước tiên sẽ cố gắng tạo một Bản sao DB mới trong cùng một Vùng khả dụng như bản sao ban đầu. Nếu không thể làm như vậy, Aurora sẽ cố gắng tạo một Phiên bản DB mới trong một Vùng khả dụng khác. Từ đầu đến cuối, quá trình chuyển đổi dự phòng thường hoàn thành trong vòng chưa đầy 15 phút.
Ứng dụng của bạn nên thử lại các kết nối cơ sở dữ liệu trong trường hợp mất kết nối.
Sau khi Amazon Aurora cung cấp phiên bản DB của bạn, bạn sẽ nhận được hai điểm cuối, một cho người viết và một cho người đọc. Điểm cuối của trình đọc cung cấp hỗ trợ cân bằng tải cho các kết nối chỉ đọc đến cụm DB. Các điểm cuối sau được lấy từ thiết lập thử nghiệm của chúng tôi:
- nhà văn - aurora-sysbench.cluster-cw9j4kdnvun9.ap-soutosystem-1.rds.amazonaws.com
- reader - aurora-sysbench.cluster-ro-cw9j4kdnvun9.ap-soutosystem-1.rds.amazonaws.com
Trong thử nghiệm của mình, chúng tôi đã sử dụng các thông số kỹ thuật của Aurora sau:
- Loại phiên bản:db.r5.large
- Phiên bản MySQL:5.7.12
- vCPU:2
- RAM:16 GB
- Sao chép nhiều AZ:Có
Để kích hoạt chuyển đổi dự phòng, chỉ cần chọn phiên bản người viết -> Hành động -> Chuyển đổi dự phòng, như được hiển thị trong ảnh chụp màn hình sau:
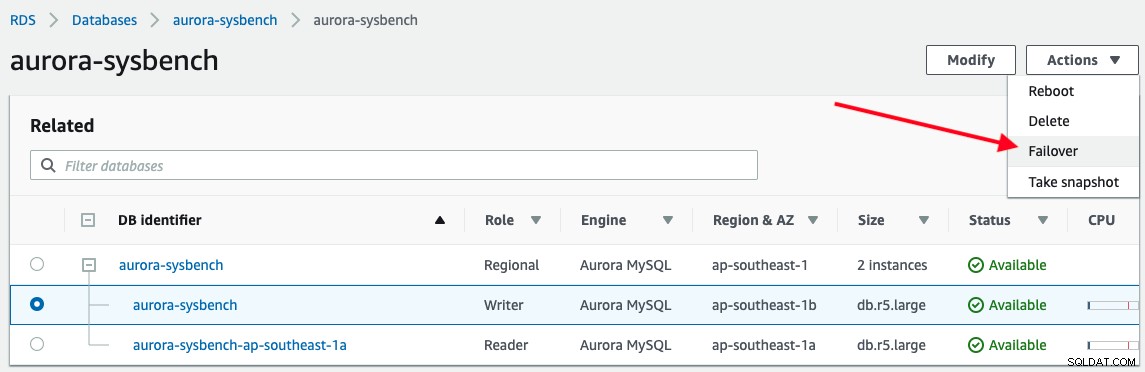
Ứng dụng của chúng tôi báo cáo kết quả đầu ra sau khi kết nối với điểm cuối của Aurora writer :
...
count 37 : OK Wed Aug 28 12:35:47 UTC 2019
count 38 : OK Wed Aug 28 12:35:48 UTC 2019
count 39 : Fail ---- Wed Aug 28 12:35:49 UTC 2019
count 40 : Fail ---- Wed Aug 28 12:35:50 UTC 2019
count 41 : Fail ---- Wed Aug 28 12:35:51 UTC 2019
count 42 : Fail ---- Wed Aug 28 12:35:52 UTC 2019
count 43 : Fail ---- Wed Aug 28 12:35:53 UTC 2019
count 44 : Fail ---- Wed Aug 28 12:35:54 UTC 2019
count 45 : Fail ---- Wed Aug 28 12:35:55 UTC 2019
count 46 : OK Wed Aug 28 12:35:56 UTC 2019
count 47 : OK Wed Aug 28 12:35:57 UTC 2019
...Thời gian ngừng hoạt động của cơ sở dữ liệu được bắt đầu từ 12:35:49 cho đến 12:35:56 với tổng thời lượng là 7 giây. Thật là ấn tượng.
Nhìn vào sự kiện cơ sở dữ liệu từ bảng điều khiển quản lý Aurora, chỉ có hai sự kiện sau đã xảy ra:
Wed, 28 Aug 2019 12:35:50 GMT A new writer was promoted. Restarting database as a reader.
Wed, 28 Aug 2019 12:35:55 GMT DB instance restartedKhông mất nhiều thời gian để Aurora thăng cấp một nô lệ trở thành chủ nhân, và giáng chức chủ nhân để trở thành nô lệ. Lưu ý rằng tất cả các bản sao Aurora đều chia sẻ cùng một khối lượng cơ bản với bản sao chính và điều này có nghĩa là việc sao chép có thể được thực hiện trong mili giây vì các bản cập nhật do bản sao chính thực hiện ngay lập tức có sẵn cho tất cả các bản sao Aurora. Do đó, nó có độ trễ sao chép tối thiểu (Amazon tuyên bố là 100 mili giây trở xuống). Điều này sẽ giúp giảm đáng kể thời gian kiểm tra sức khỏe và cải thiện thời gian hồi phục đáng kể.
Chuyển đổi dự phòng với ClusterControl
Trong ví dụ này, chúng tôi bắt chước một thiết lập tương tự với Amazon RDS bằng cách sử dụng các phiên bản m5.xlarge, với ProxySQL ở giữa để tự động chuyển đổi dự phòng từ ứng dụng bằng cách sử dụng một truy cập điểm cuối duy nhất giống như RDS. Sơ đồ sau minh họa kiến trúc của chúng tôi:
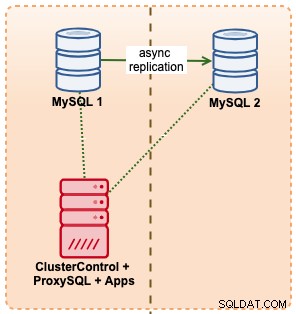
Vì chúng tôi đang có quyền truy cập trực tiếp vào các cá thể cơ sở dữ liệu, chúng tôi sẽ kích hoạt chuyển đổi dự phòng tự động bằng cách giết quá trình MySQL trên máy chủ đang hoạt động:
$ kill -9 $(pidof mysqld)Lệnh trên đã kích hoạt khôi phục tự động bên trong ClusterControl:
[11:08:49]: Job Completed.
[11:08:44]: 10.15.3.141:3306: Flushing logs to update 'SHOW SLAVE HOSTS'
[11:08:39]: 10.15.3.141:3306: Flushing logs to update 'SHOW SLAVE HOSTS'
[11:08:39]: Failover Complete. New master is 10.15.3.141:3306.
[11:08:39]: Attaching slaves to new master.
[11:08:39]: 10.15.3.141:3306: Command 'RESET SLAVE /*!50500 ALL */' succeeded.
[11:08:39]: 10.15.3.141:3306: Executing 'RESET SLAVE /*!50500 ALL */'.
[11:08:39]: 10.15.3.141:3306: Successfully stopped slave.
[11:08:39]: 10.15.3.141:3306: Stopping slave.
[11:08:39]: 10.15.3.141:3306: Successfully stopped slave.
[11:08:39]: 10.15.3.141:3306: Stopping slave.
[11:08:38]: 10.15.3.141:3306: Setting read_only=OFF and super_read_only=OFF.
[11:08:38]: 10.15.3.141:3306: Successfully stopped slave.
[11:08:38]: 10.15.3.141:3306: Stopping slave.
[11:08:38]: Stopping slaves.
[11:08:38]: 10.15.3.141:3306: Completed preparations of candidate.
[11:08:38]: 10.15.3.141:3306: Applied 0 transactions. Remaining: .
[11:08:38]: 10.15.3.141:3306: waiting up to 4294967295 seconds before timing out.
[11:08:38]: 10.15.3.141:3306: Checking if the candidate has relay log to apply.
[11:08:38]: 10.15.3.141:3306: preparing candidate.
[11:08:38]: No errant transactions found.
[11:08:38]: 10.15.3.141:3306: Skipping, same as slave 10.15.3.141:3306
[11:08:38]: Checking for errant transactions.
[11:08:37]: 10.15.3.141:3306: Setting read_only=ON and super_read_only=ON.
[11:08:37]: 10.15.3.69:3306: Can't connect to MySQL server on '10.15.3.69' (115)
[11:08:37]: 10.15.3.69:3306: Setting read_only=ON and super_read_only=ON.
[11:08:37]: 10.15.3.69:3306: Failed to CREATE USER rpl_user. Error: 10.15.3.69:3306: Query failed: Can't connect to MySQL server on '10.15.3.69' (115).
[11:08:36]: 10.15.3.69:3306: Creating user 'rpl_user'@'10.15.3.141.
[11:08:36]: 10.15.3.141:3306: Executing GRANT REPLICATION SLAVE 'rpl_user'@'10.15.3.69'.
[11:08:36]: 10.15.3.141:3306: Creating user 'rpl_user'@'10.15.3.69.
[11:08:36]: 10.15.3.141:3306: Elected as the new Master.
[11:08:36]: 10.15.3.141:3306: Slave lag is 0 seconds.
[11:08:36]: 10.15.3.141:3306 to slave list
[11:08:36]: 10.15.3.141:3306: Checking if slave can be used as a candidate.
[11:08:33]: 10.15.3.69:3306: Trying to shutdown the failed master if it is up.
[11:08:32]: 10.15.3.69:3306: Setting read_only=ON and super_read_only=ON.
[11:08:31]: 10.15.3.141:3306: Setting read_only=ON and super_read_only=ON.
[11:08:30]: 10.15.3.69:3306: Setting read_only=ON and super_read_only=ON.
[11:08:30]: 10.15.3.141:3306: ioerrno=2003 io running 0
[11:08:30]: Checking 10.15.3.141:3306
[11:08:30]: 10.15.3.69:3306: REPL_UNDEFINED
[11:08:30]: 10.15.3.69:3306
[11:08:30]: Failover to a new Master.
Job spec: Failover to a new Master.Theo quan điểm ứng dụng thử nghiệm của chúng tôi, thời gian chết đã xảy ra vào thời điểm sau khi kết nối với cổng máy chủ ProxySQL 6033:
...
count 1 : OK Wed Aug 28 11:08:24 UTC 2019
count 2 : OK Wed Aug 28 11:08:25 UTC 2019
count 3 : OK Wed Aug 28 11:08:26 UTC 2019
count 4 : Fail ---- Wed Aug 28 11:08:28 UTC 2019
count 5 : Fail ---- Wed Aug 28 11:08:30 UTC 2019
count 6 : Fail ---- Wed Aug 28 11:08:32 UTC 2019
count 7 : Fail ---- Wed Aug 28 11:08:34 UTC 2019
count 8 : Fail ---- Wed Aug 28 11:08:36 UTC 2019
count 9 : Fail ---- Wed Aug 28 11:08:38 UTC 2019
count 10 : OK Wed Aug 28 11:08:39 UTC 2019
count 11 : OK Wed Aug 28 11:08:40 UTC 2019
...Bằng cách xem xét cả các sự kiện công việc khôi phục và đầu ra từ ứng dụng của chúng tôi, nút cơ sở dữ liệu MySQL đã ngừng hoạt động 4 giây trước khi công việc khôi phục cụm bắt đầu, từ 11:08:28 cho đến 11:08:39, với tổng thời gian ngừng hoạt động của MySQL là 11 giây . Một trong những điều ấn tượng nhất về ClusterControl là, bạn có thể theo dõi tiến trình khôi phục về hành động được thực hiện và thực hiện bởi ClusterControl trong quá trình chuyển đổi dự phòng. Nó cung cấp một mức độ minh bạch mà bạn sẽ không thể có được với bất kỳ dịch vụ cơ sở dữ liệu nào của các nhà cung cấp dịch vụ đám mây.
Đối với sao chép MySQL / MariaDB / PostgreSQL, ClusterControl cho phép bạn có một cơ sở dữ liệu chi tiết hơn với sự hỗ trợ của cấu hình và thông số nâng cao sau:
- Quản lý cấu trúc liên kết nhân rộng tổng thể-tổng thể
- Quản lý cấu trúc liên kết sao chép chuỗi
- Trình xem cấu trúc liên kết
- Nô lệ trong danh sách trắng / danh sách đen được thăng cấp làm chủ
- Trình kiểm tra giao dịch sai sót
- Kết nối các sự kiện trước / sau, thành công / chuyển đổi dự phòng / chuyển đổi dự phòng với tập lệnh bên ngoài
- Tự động tạo lại nô lệ khi bị lỗi
- Mở rộng quy mô nô lệ khỏi bản sao lưu hiện có
Tóm tắt thời gian chuyển đổi dự phòng
Về thời gian chuyển đổi dự phòng, Amazon RDS Aurora cho MySQL là người chiến thắng rõ ràng với 7 giây , tiếp theo là ClusterControl 11 giây và Amazon RDS cho MySQL với 27 giây .
Lưu ý rằng đây chỉ là một bài kiểm tra đơn giản, với một khách hàng và một giao dịch mỗi giây để đo thời gian khôi phục nhanh nhất. Các giao dịch lớn hoặc quá trình khôi phục kéo dài có thể làm tăng thời gian chuyển đổi dự phòng, ví dụ:các giao dịch đang chạy dài có thể mất nhiều thời gian để quay lại khi tắt MySQL.



