Tình huống tốt nhất là, trong trường hợp cơ sở dữ liệu bị lỗi, bạn có Kế hoạch khôi phục sau thảm họa (DRP) tốt và một môi trường có tính khả dụng cao với quy trình chuyển đổi dự phòng tự động, nhưng… điều gì sẽ xảy ra nếu nó không thành công một số lý do bất ngờ? Điều gì sẽ xảy ra nếu bạn cần thực hiện chuyển đổi dự phòng thủ công? Trong blog này, chúng tôi sẽ chia sẻ một số khuyến nghị cần tuân theo trong trường hợp bạn cần chuyển đổi dự phòng cơ sở dữ liệu của mình.
Kiểm tra Xác minh
Trước khi thực hiện bất kỳ thay đổi nào, bạn cần xác minh một số điều cơ bản để tránh các vấn đề mới sau quá trình chuyển đổi dự phòng.
Trạng thái Sao chép
Có thể tại thời điểm lỗi, nút phụ không được cập nhật, do lỗi mạng, tải cao hoặc một vấn đề khác, vì vậy bạn cần đảm bảo nô lệ có tất cả (hoặc gần như tất cả) thông tin. Nếu bạn có nhiều hơn một nút phụ, bạn cũng nên kiểm tra xem nút nào là nút nâng cao nhất và chọn nó để chuyển đổi dự phòng.
ví dụ:Hãy kiểm tra trạng thái sao chép trong Máy chủ MariaDB.
MariaDB [(none)]> SHOW SLAVE STATUS\G
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 192.168.100.110
Master_User: rpl_user
Master_Port: 3306
Connect_Retry: 10
Master_Log_File: binlog.000014
Read_Master_Log_Pos: 339
Relay_Log_File: relay-bin.000002
Relay_Log_Pos: 635
Relay_Master_Log_File: binlog.000014
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
Last_Errno: 0
Skip_Counter: 0
Exec_Master_Log_Pos: 339
Relay_Log_Space: 938
Until_Condition: None
Until_Log_Pos: 0
Master_SSL_Allowed: No
Seconds_Behind_Master: 0
Master_SSL_Verify_Server_Cert: No
Last_IO_Errno: 0
Last_SQL_Errno: 0
Replicate_Ignore_Server_Ids:
Master_Server_Id: 3001
Using_Gtid: Slave_Pos
Gtid_IO_Pos: 0-3001-20
Parallel_Mode: conservative
SQL_Delay: 0
SQL_Remaining_Delay: NULL
Slave_SQL_Running_State: Slave has read all relay log; waiting for the slave I/O thread to update it
Slave_DDL_Groups: 0
Slave_Non_Transactional_Groups: 0
Slave_Transactional_Groups: 0
1 row in set (0.000 sec)Trong trường hợp PostgreSQL, hơi khác một chút vì bạn cần kiểm tra trạng thái WAL và so sánh trạng thái được áp dụng với trạng thái đã tìm nạp.
postgres=# SELECT CASE WHEN pg_last_wal_receive_lsn()=pg_last_wal_replay_lsn()
postgres-# THEN 0
postgres-# ELSE EXTRACT (EPOCH FROM now() - pg_last_xact_replay_timestamp())
postgres-# END AS log_delay;
log_delay
-----------
0
(1 row)Thông tin đăng nhập
Trước khi chạy chuyển đổi dự phòng, bạn phải kiểm tra xem ứng dụng / người dùng của bạn có thể truy cập trang chủ mới của bạn bằng thông tin đăng nhập hiện tại hay không. Nếu bạn không sao chép người dùng cơ sở dữ liệu của mình, có thể thông tin đăng nhập đã bị thay đổi, vì vậy bạn cần cập nhật chúng trong các nút phụ trước khi có bất kỳ thay đổi nào.
ví dụ:Bạn có thể truy vấn bảng người dùng trong cơ sở dữ liệu mysql để kiểm tra thông tin đăng nhập của người dùng trong Máy chủ MariaDB / MySQL:
MariaDB [(none)]> SELECT Host,User,Password FROM mysql.user;
+-----------------+--------------+-------------------------------------------+
| Host | User | Password |
+-----------------+--------------+-------------------------------------------+
| localhost | root | *CD7EC70C2F7DCE88643C97381CB42633118AF8A8 |
| localhost | mysql | invalid |
| 127.0.0.1 | backupuser | *AC01ED53FA8443BFD3FC7C448F78A6F2C26C3C38 |
| 192.168.100.100 | cmon | *F80B5EE41D1FB1FA67D83E96FCB1638ABCFB86E2 |
| 127.0.0.1 | root | *CD7EC70C2F7DCE88643C97381CB42633118AF8A8 |
| ::1 | root | *CD7EC70C2F7DCE88643C97381CB42633118AF8A8 |
| localhost | backupuser | *AC01ED53FA8443BFD3FC7C448F78A6F2C26C3C38 |
| 192.168.100.112 | user1 | *CD7EC70C2F7DCE88643C97381CB42633118AF8A8 |
| localhost | cmonexporter | *0F7AD3EAF21E28201D311384753810C5066B0964 |
| 127.0.0.1 | cmonexporter | *0F7AD3EAF21E28201D311384753810C5066B0964 |
| ::1 | cmonexporter | *0F7AD3EAF21E28201D311384753810C5066B0964 |
| 192.168.100.110 | rpl_user | *EEA7B018B16E0201270B3CDC0AF8FC335048DC63 |
+-----------------+--------------+-------------------------------------------+
12 rows in set (0.001 sec)Trong trường hợp PostgreSQL, bạn có thể sử dụng lệnh ‘\ du’ để biết các vai trò và bạn cũng phải kiểm tra tệp cấu hình pg_hba.conf để quản lý quyền truy cập của người dùng (không phải thông tin đăng nhập). Vì vậy:
postgres=# \du
List of roles
Role name | Attributes | Member of
------------------+------------------------------------------------------------+-----------
admindb | Superuser, Create role, Create DB | {}
cmon_replication | Replication | {}
cmonexporter | | {}
postgres | Superuser, Create role, Create DB, Replication, Bypass RLS | {}
s9smysqlchk | Superuser, Create role, Create DB | {}Và pg_hba.conf:
# TYPE DATABASE USER ADDRESS METHOD
host replication cmon_replication localhost md5
host replication cmon_replication 127.0.0.1/32 md5
host all s9smysqlchk localhost md5
host all s9smysqlchk 127.0.0.1/32 md5
local all all trust
host all all 127.0.0.1/32 trustTruy cập Mạng / Tường lửa
Thông tin đăng nhập không phải là vấn đề duy nhất có thể xảy ra khi truy cập trang cái mới của bạn. Nếu nút nằm trong một trung tâm dữ liệu khác hoặc bạn có tường lửa cục bộ để lọc lưu lượng, bạn phải kiểm tra xem bạn có được phép truy cập nó hay không hoặc thậm chí nếu bạn có tuyến mạng để đến nút chính mới.
ví dụ:iptables. Hãy cho phép lưu lượng truy cập từ mạng 167.124.57.0/24 và kiểm tra các quy tắc hiện tại sau khi thêm nó:
$ iptables -A INPUT -s 167.124.57.0/24 -m state --state NEW -j ACCEPT
$ iptables -L -n
Chain INPUT (policy ACCEPT)
target prot opt source destination
ACCEPT all -- 167.124.57.0/24 0.0.0.0/0 state NEW
Chain FORWARD (policy ACCEPT)
target prot opt source destination
Chain OUTPUT (policy ACCEPT)
target prot opt source destinationví dụ:các tuyến đường. Giả sử nút chính mới của bạn nằm trong mạng 10.0.0.0/24, máy chủ ứng dụng của bạn ở 192.168.100.0/24 và bạn có thể truy cập mạng từ xa bằng 192.168.100.100, vì vậy trong máy chủ ứng dụng của bạn, hãy thêm tuyến đường tương ứng:
$ route add -net 10.0.0.0/24 gw 192.168.100.100
$ route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 192.168.100.1 0.0.0.0 UG 0 0 0 eth0
10.0.0.0 192.168.100.100 255.255.255.0 UG 0 0 0 eth0
169.254.0.0 0.0.0.0 255.255.0.0 U 1027 0 0 eth0
192.168.100.0 0.0.0.0 255.255.255.0 U 0 0 0 eth0Điểm Hành động
Sau khi kiểm tra tất cả các điểm được đề cập, bạn nên sẵn sàng thực hiện các hành động để chuyển đổi dự phòng cơ sở dữ liệu của mình.
Địa chỉ IP mới
Khi bạn quảng bá nút phụ, địa chỉ IP chính sẽ thay đổi, vì vậy bạn cần thay đổi địa chỉ này trong quyền truy cập ứng dụng hoặc ứng dụng khách của mình.
Sử dụng Load Balancer là một cách tuyệt vời để tránh sự cố / thay đổi này. Sau quá trình chuyển đổi dự phòng, Load Balancer sẽ phát hiện bản chính cũ đang ngoại tuyến và (tùy thuộc vào cấu hình) gửi lưu lượng đến cái mới để ghi trên đó, vì vậy bạn không cần phải thay đổi bất kỳ điều gì trong ứng dụng của mình.
ví dụ:Hãy xem ví dụ về cấu hình HAProxy:
listen haproxy_5433
bind *:5433
mode tcp
timeout client 10800s
timeout server 10800s
balance leastconn
option tcp-check
server 192.168.100.119 192.168.100.119:5432 check
server 192.168.100.120 192.168.100.120:5432 checkTrong trường hợp này, nếu một nút bị hỏng, HAProxy sẽ không gửi lưu lượng đến đó và chỉ gửi lưu lượng đến nút có sẵn.
Định cấu hình lại các nút Nô lệ
Nếu bạn có nhiều hơn một nút phụ, sau khi thăng cấp một trong số chúng, bạn phải định cấu hình lại các nút còn lại để kết nối với nút chính mới. Đây có thể là một công việc tốn nhiều thời gian, tùy thuộc vào số lượng nút.
Xác minh &Định cấu hình Bản sao lưu
Sau khi bạn đã có tất cả (thăng cấp chủ mới, cấu hình lại nô lệ, viết ứng dụng trong trang chủ mới), điều quan trọng là phải thực hiện các hành động cần thiết để ngăn chặn sự cố mới, do đó, sao lưu là điều cần thiết bước này. Hầu hết có thể bạn đã chạy chính sách sao lưu trước khi sự cố xảy ra (nếu không, bạn cần phải có nó chắc chắn), vì vậy bạn phải kiểm tra xem các bản sao lưu vẫn đang chạy hay chúng sẽ hoạt động trong cấu trúc liên kết mới. Có thể bạn đã chạy bản sao lưu trên nút chính cũ hoặc đang sử dụng nút phụ hiện là nút chính, vì vậy bạn cần kiểm tra nó để đảm bảo chính sách sao lưu của bạn vẫn hoạt động sau khi thay đổi.
Giám sát Cơ sở dữ liệu
Khi bạn thực hiện quá trình chuyển đổi dự phòng, việc giám sát là điều bắt buộc trước, trong và sau quá trình. Với điều này, bạn có thể ngăn chặn sự cố trước khi nó trở nên tồi tệ hơn, phát hiện ra sự cố không mong muốn trong quá trình chuyển đổi dự phòng hoặc thậm chí biết được liệu có vấn đề gì xảy ra sau đó hay không. Ví dụ:bạn phải theo dõi xem ứng dụng của mình có thể truy cập trang chủ mới hay không bằng cách kiểm tra số lượng kết nối đang hoạt động.
Các chỉ số chính cần theo dõi
Hãy xem một số chỉ số quan trọng nhất cần tính đến:
- Trễ sao chép
- Trạng thái sao chép
- Số lượng kết nối
- Sử dụng mạng / lỗi
- Tải máy chủ (CPU, Bộ nhớ, Đĩa)
- Nhật ký hệ thống và cơ sở dữ liệu
Khôi phục
Tất nhiên, nếu có sự cố xảy ra, bạn phải có khả năng quay trở lại. Chặn lưu lượng truy cập đến nút cũ và giữ nó càng cô lập càng tốt có thể là một chiến lược tốt cho việc này, vì vậy trong trường hợp bạn cần khôi phục, bạn sẽ có sẵn nút cũ. Nếu quá trình khôi phục diễn ra sau một vài phút, tùy thuộc vào lưu lượng truy cập, có thể bạn sẽ cần phải chèn dữ liệu của những phút này vào nút chính cũ, vì vậy hãy đảm bảo rằng bạn cũng có sẵn nút chính tạm thời và được cô lập để lấy thông tin này và áp dụng nó trở lại .
Tự động hóa quy trình chuyển đổi dự phòng với ClusterControl
Nhìn thấy tất cả các tác vụ cần thiết này để thực hiện chuyển đổi dự phòng, có lẽ hầu hết bạn muốn tự động hóa nó và tránh tất cả công việc thủ công này. Đối với điều này, bạn có thể tận dụng một số tính năng mà ClusterControl có thể cung cấp cho bạn cho các công nghệ cơ sở dữ liệu khác nhau, như tự động khôi phục, sao lưu, quản lý người dùng, giám sát, trong số các tính năng khác, tất cả từ cùng một hệ thống.
Với ClusterControl, bạn có thể xác minh trạng thái sao chép và độ trễ của nó, tạo hoặc sửa đổi thông tin đăng nhập, biết mạng và trạng thái máy chủ lưu trữ và thậm chí nhiều xác minh hơn nữa.
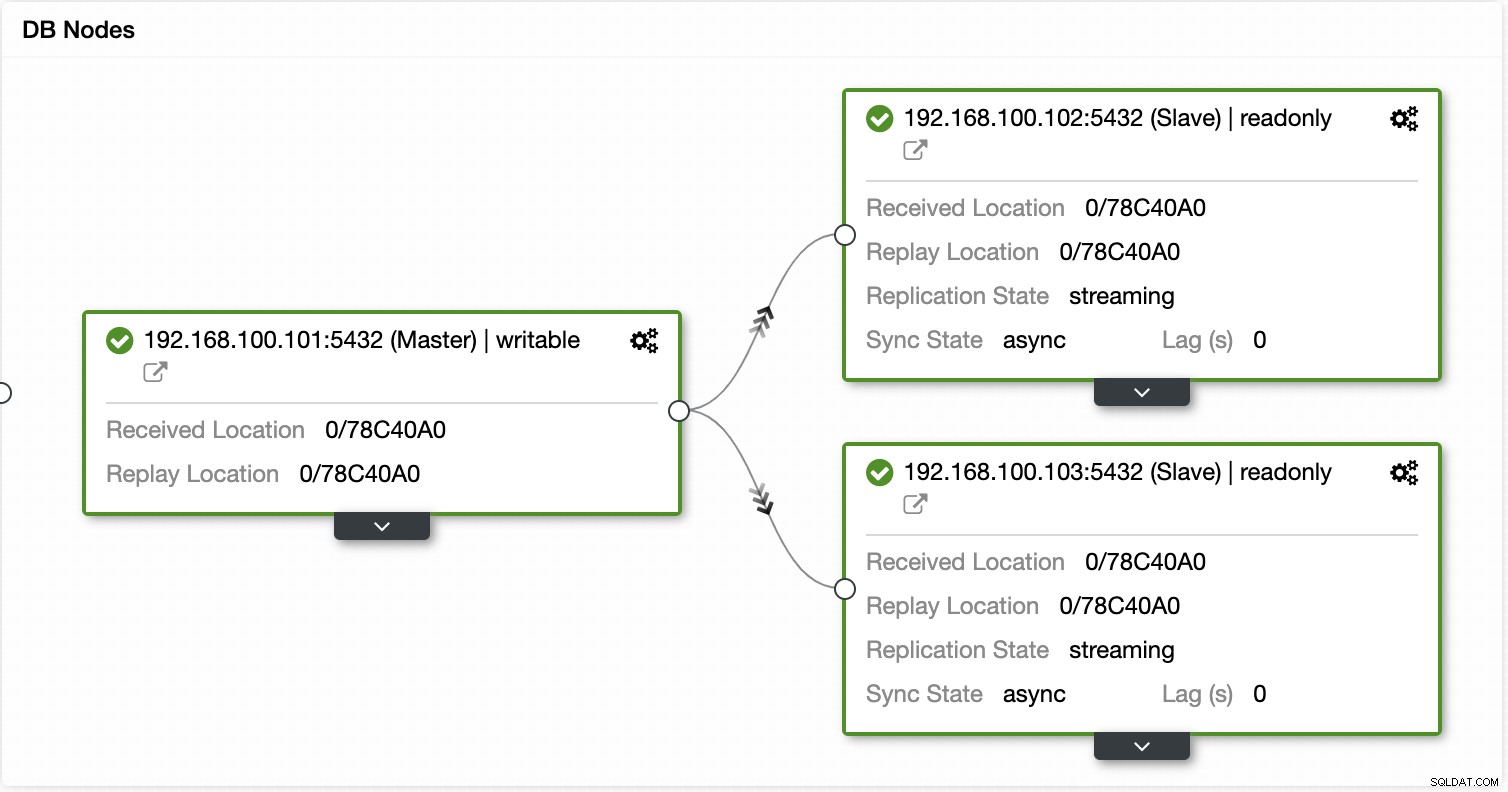
Sử dụng ClusterControl, bạn cũng có thể thực hiện các hành động cụm và nút khác nhau, chẳng hạn như quảng bá nô lệ , khởi động lại cơ sở dữ liệu và máy chủ, thêm hoặc xóa các nút cơ sở dữ liệu, thêm hoặc xóa các nút cân bằng tải, xây dựng lại nô lệ sao chép, v.v.
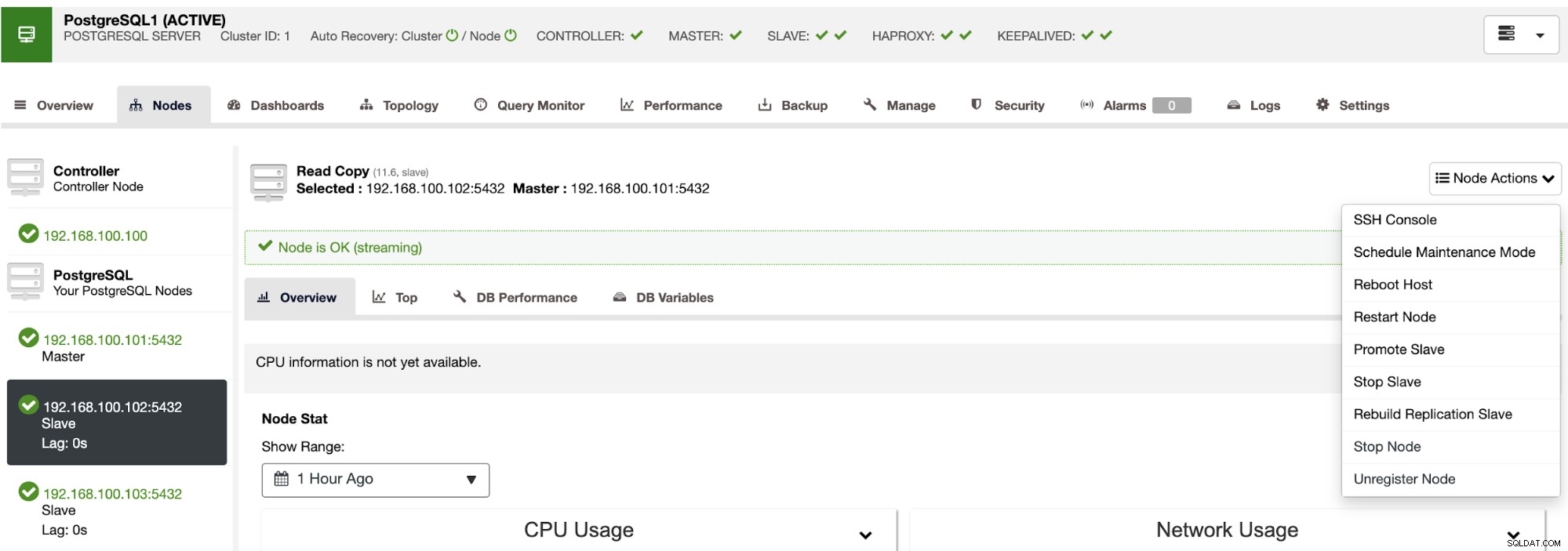
Bằng cách sử dụng các hành động này, bạn cũng có thể khôi phục dự phòng của mình nếu cần bằng cách xây dựng lại và quảng cáo cái trước.
ClusterControl có các dịch vụ giám sát và cảnh báo giúp bạn biết điều gì đang xảy ra hoặc thậm chí nếu điều gì đó đã xảy ra trước đó.
Bạn cũng có thể sử dụng phần trang tổng quan để có chế độ xem thân thiện hơn với người dùng về trạng thái hệ thống của bạn.
Kết luận
Trong trường hợp cơ sở dữ liệu chính bị lỗi, bạn sẽ muốn có tất cả thông tin tại chỗ để thực hiện các hành động cần thiết càng sớm càng tốt. Có một DRP tốt là chìa khóa để giữ cho hệ thống của bạn luôn hoạt động (hoặc gần như toàn bộ) thời gian. DRP này nên bao gồm một quy trình chuyển đổi dự phòng được ghi chép đầy đủ để có một RTO (Mục tiêu Thời gian Khôi phục) được chấp nhận cho công ty.