Trong bài đăng trên blog trước, chúng ta đã trình bày những kiến thức cơ bản về quy mô - nó là gì, các loại là gì, điều gì cần phải có nếu chúng ta muốn mở rộng quy mô. Bài đăng trên blog này sẽ tập trung vào những thách thức và cách chúng ta có thể mở rộng quy mô.
Thử thách mở rộng quy mô
Chia tỷ lệ cơ sở dữ liệu không phải là nhiệm vụ dễ dàng nhất vì nhiều lý do. Hãy tập trung một chút vào những thách thức liên quan đến việc mở rộng cơ sở hạ tầng cơ sở dữ liệu của bạn.
Dịch vụ hiệu quả
Chúng ta có thể phân biệt hai loại dịch vụ khác nhau:không trạng thái và có trạng thái. Các dịch vụ không trạng thái là những dịch vụ không dựa trên bất kỳ loại dữ liệu hiện có nào. Bạn chỉ cần tiếp tục, bắt đầu một dịch vụ như vậy và nó sẽ vui vẻ hoạt động. Bạn không phải lo lắng về trạng thái của dữ liệu cũng như dịch vụ. Nếu có, nó sẽ hoạt động bình thường và bạn có thể dễ dàng phân bổ lưu lượng truy cập qua nhiều trường hợp dịch vụ chỉ bằng cách thêm nhiều bản sao hoặc bản sao của VM hiện có, vùng chứa hoặc tương tự. Ví dụ về một dịch vụ như vậy có thể là một ứng dụng web - được triển khai từ kho lưu trữ, có một máy chủ web được định cấu hình đúng, dịch vụ đó sẽ chỉ bắt đầu và hoạt động bình thường.
Vấn đề với cơ sở dữ liệu là cơ sở dữ liệu là mọi thứ trừ trạng thái. Dữ liệu phải được đưa vào cơ sở dữ liệu, nó phải được xử lý và tồn tại lâu dài. Hình ảnh của cơ sở dữ liệu chỉ là một vài gói được cài đặt trên hình ảnh hệ điều hành và, nếu không có dữ liệu và cấu hình thích hợp, nó sẽ khá vô dụng. Điều này làm tăng thêm sự phức tạp của việc mở rộng cơ sở dữ liệu. Đối với các dịch vụ không trạng thái, chỉ cần triển khai chúng và định cấu hình một số bộ cân bằng tải để đưa các phiên bản mới vào khối lượng công việc. Đối với cơ sở dữ liệu triển khai cơ sở dữ liệu, phiên bản chỉ là điểm bắt đầu. Xa hơn nữa là quản lý dữ liệu - bạn phải chuyển dữ liệu từ phiên bản cơ sở dữ liệu hiện có của mình sang phiên bản mới. Đây có thể là một phần quan trọng của vấn đề và thời gian cần thiết để các phiên bản mới bắt đầu xử lý lưu lượng. Chỉ sau khi dữ liệu đã được chuyển, chúng tôi mới có thể thiết lập các nút mới để trở thành một phần của cấu trúc liên kết sao chép hiện có - dữ liệu phải được cập nhật trên chúng theo thời gian thực, dựa trên lưu lượng truy cập đến các nút khác.
Thời gian cần thiết để mở rộng quy mô
Thực tế là cơ sở dữ liệu là các dịch vụ trạng thái là lý do trực tiếp dẫn đến thách thức thứ hai mà chúng ta phải đối mặt khi muốn mở rộng cơ sở hạ tầng cơ sở dữ liệu. Dịch vụ không trạng thái - bạn chỉ cần khởi động chúng và thế là xong. Nó là một quá trình khá nhanh chóng. Đối với cơ sở dữ liệu, bạn phải chuyển dữ liệu. Nó sẽ mất bao lâu, nó phụ thuộc vào nhiều yếu tố. Tập dữ liệu lớn đến mức nào? Lưu trữ nhanh như thế nào? Mạng nhanh như thế nào? Các bước khác cần thiết để cung cấp cho nút mới dữ liệu mới là gì? Dữ liệu được nén / giải nén hay được mã hóa / giải mã trong quá trình này? Trong thế giới thực, có thể mất từ vài phút đến nhiều giờ để cung cấp dữ liệu trên một nút mới. Điều này hạn chế nghiêm trọng các trường hợp bạn có thể mở rộng môi trường cơ sở dữ liệu của mình. Tải trọng đột ngột, tạm thời? Không thực sự, chúng có thể đã biến mất từ lâu trước khi bạn có thể bắt đầu các nút cơ sở dữ liệu bổ sung. Tăng tải đột ngột và nhất quán? Có, có thể giải quyết vấn đề này bằng cách thêm nhiều nút hơn nhưng có thể mất hàng giờ đồng hồ để đưa chúng lên và để chúng tiếp quản lưu lượng truy cập từ các nút cơ sở dữ liệu hiện có.
Tải thêm do quá trình mở rộng quy mô
Điều rất quan trọng cần lưu ý là thời gian cần thiết để mở rộng quy mô chỉ là một mặt của vấn đề. Mặt còn lại là tải do quá trình mở rộng quy mô gây ra. Như chúng tôi đã đề cập trước đó, bạn phải chuyển toàn bộ tập dữ liệu sang các nút mới được thêm vào. Đây không phải là thứ mà bạn có thể bỏ qua, vì nó có thể là một quá trình dài hàng giờ đồng hồ để đọc dữ liệu từ đĩa, gửi nó qua mạng và lưu trữ nó ở một vị trí mới. Nếu nhà tài trợ, nút nơi bạn đọc dữ liệu, bị quá tải, bạn cần xem xét nó sẽ hoạt động như thế nào nếu nó sẽ buộc phải thực hiện thêm hoạt động I / O nặng nề? Liệu cụm của bạn có thể đảm nhận thêm khối lượng công việc nếu nó đã bị áp lực nặng nề và dàn trải mỏng không? Câu trả lời có thể không dễ dàng nhận được vì tải trên các nút có thể ở các dạng khác nhau. Tải theo giới hạn CPU sẽ là trường hợp tốt nhất vì hoạt động I / O phải thấp và các hoạt động đĩa bổ sung sẽ có thể quản lý được. Mặt khác, tải giới hạn I / O có thể làm chậm quá trình truyền dữ liệu đáng kể, ảnh hưởng nghiêm trọng đến khả năng mở rộng quy mô của cụm.
Ghi tỷ lệ
Quy trình mở rộng quy mô mà chúng tôi đã đề cập trước đó bị giới hạn khá nhiều đối với việc mở rộng quy mô lần đọc. Điều tối quan trọng là phải hiểu rằng viết theo tỷ lệ là một câu chuyện hoàn toàn khác. Bạn có thể mở rộng quy mô lượt đọc bằng cách thêm nhiều nút hơn và trải rộng lượt đọc trên nhiều nút phụ trợ hơn. Viết không dễ mở rộng. Đối với người mới bắt đầu, bạn không thể mở rộng các bài viết như vậy. Tất nhiên, mọi nút chứa toàn bộ tập dữ liệu được yêu cầu xử lý tất cả các lần ghi được thực hiện ở đâu đó trong cụm vì chỉ bằng cách áp dụng tất cả các sửa đổi cho tập dữ liệu, nó mới có thể duy trì tính nhất quán. Vì vậy, khi bạn nghĩ về nó, bất kể bạn thiết kế cụm của mình như thế nào và bạn sử dụng công nghệ gì, mọi thành viên của cụm đều phải thực hiện mọi lần ghi. Cho dù đó là bản sao, sao chép tất cả các ghi từ nút chính hoặc nút của nó trong một cụm đa chủ như Galera hoặc InnoDB Cluster thực hiện tất cả các thay đổi đối với tập dữ liệu được thực hiện trên tất cả các nút khác của cụm, kết quả là giống nhau. Ghi không mở rộng quy mô chỉ đơn giản bằng cách thêm nhiều nút hơn vào cụm.
Làm cách nào để chúng ta có thể mở rộng Cơ sở dữ liệu?
Vì vậy, chúng tôi biết mình đang phải đối mặt với những thách thức nào. Các tùy chọn mà chúng tôi có là gì? Làm cách nào chúng ta có thể mở rộng cơ sở dữ liệu?
Bằng cách thêm các bản sao
Trước hết, chúng tôi sẽ mở rộng quy mô đơn giản bằng cách thêm nhiều nút hơn. Chắc chắn, nó sẽ mất thời gian và chắc chắn, nó không phải là một quá trình bạn có thể mong đợi để xảy ra ngay lập tức. Chắc chắn, bạn sẽ không thể chia tỷ lệ các bài viết như vậy. Mặt khác, vấn đề điển hình nhất mà bạn sẽ phải đối mặt là tải CPU do các truy vấn SELECT gây ra và như chúng ta đã thảo luận, các lần đọc có thể đơn giản được thu nhỏ bằng cách thêm nhiều nút hơn vào cụm. Nhiều nút hơn để đọc từ đó có nghĩa là tải trên mỗi một trong số chúng sẽ được giảm bớt. Khi bạn đang bắt đầu hành trình vào vòng đời của ứng dụng của mình, chỉ cần giả sử rằng đây là những gì bạn sẽ xử lý. Tải CPU, truy vấn không hiệu quả. Rất ít khả năng bạn sẽ cần mở rộng các lần viết cho đến khi tiến xa hơn trong vòng đời, khi ứng dụng của bạn đã hoàn thiện và bạn phải đối phó với số lượng khách hàng.
Bởi sharding
Việc thêm các nút sẽ không giải quyết được vấn đề ghi, đó là những gì chúng tôi đã thiết lập. Thay vào đó, những gì bạn phải làm là sharding - chia nhỏ tập dữ liệu trên toàn bộ cụm. Trong trường hợp này, mỗi nút chỉ chứa một phần dữ liệu, không phải tất cả mọi thứ. Điều này cho phép chúng tôi cuối cùng bắt đầu ghi quy mô. Giả sử chúng ta có bốn nút, mỗi nút chứa một nửa tập dữ liệu.
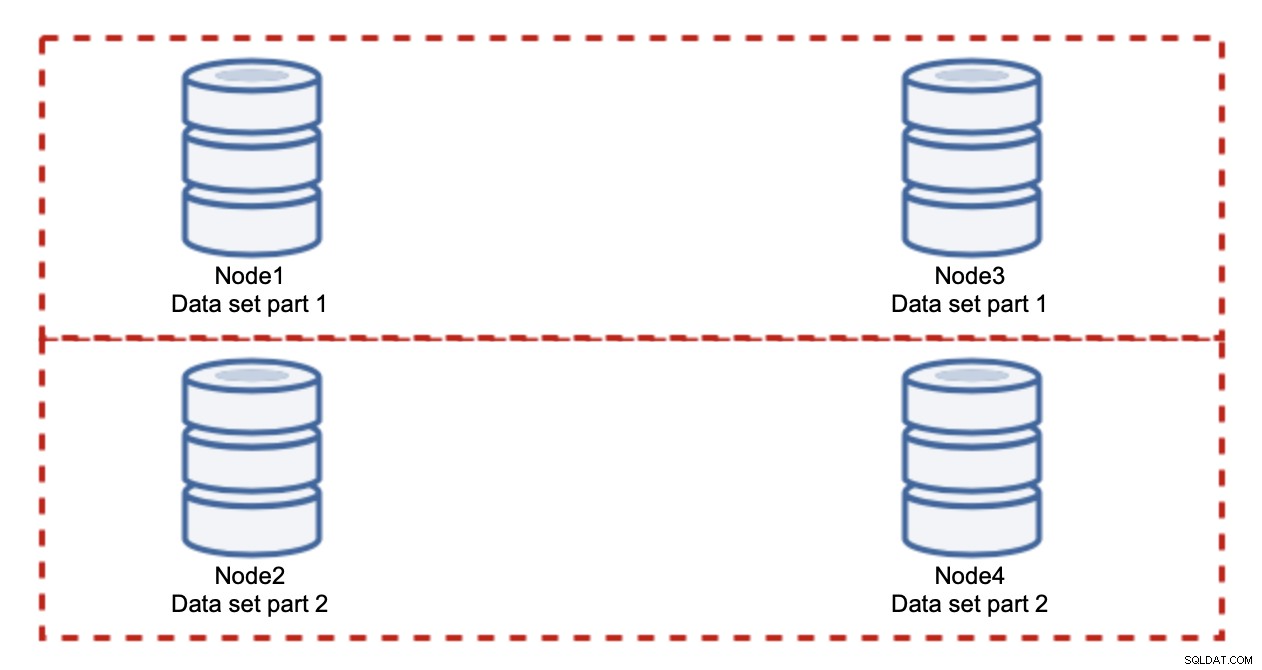
Như bạn có thể thấy, ý tưởng này rất đơn giản. Nếu việc ghi liên quan đến phần 1 của tập dữ liệu, nó sẽ được thực hiện trên node1 và node3. Nếu nó liên quan đến phần 2 của tập dữ liệu, nó sẽ được thực thi trên node2 và node4. Bạn có thể coi các nút cơ sở dữ liệu như các đĩa trong RAID. Ở đây chúng tôi có một ví dụ về RAID10, hai cặp nhân bản, để dự phòng. Trong triển khai thực tế, nó có thể phức tạp hơn, bạn có thể có nhiều hơn một bản sao dữ liệu để cải thiện tính khả dụng cao. Ý chính là, giả sử phân chia dữ liệu hoàn toàn công bằng, một nửa số lần ghi sẽ đến nút1 và nút3 và nửa nút còn lại 2 và 4. Nếu bạn muốn chia tải hơn nữa, bạn có thể giới thiệu cặp nút thứ ba:
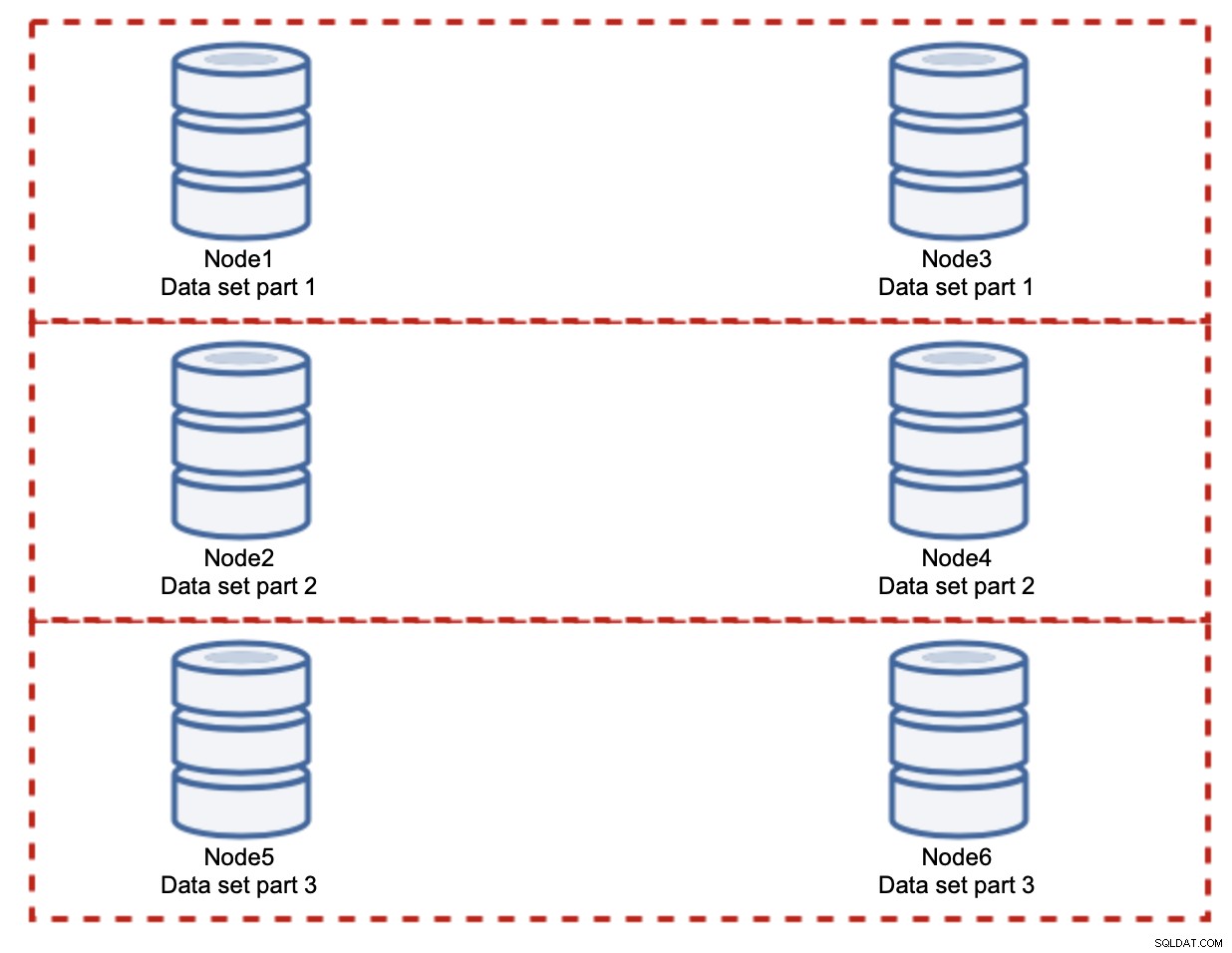
Trong trường hợp này, một lần nữa, giả sử phân chia hoàn toàn công bằng, mỗi cặp sẽ chịu trách nhiệm về 33% tổng số lần ghi vào cụm.
Điều này tóm tắt khá nhiều ý tưởng về sharding. Trong ví dụ của chúng tôi, bằng cách thêm nhiều phân đoạn hơn, chúng tôi có thể giảm hoạt động ghi trên các nút cơ sở dữ liệu xuống 33% tải I / O ban đầu. Như bạn có thể tưởng tượng, điều này không có mặt hạn chế.
Làm cách nào để tìm dữ liệu của tôi nằm trên phân đoạn nào? Chi tiết nằm ngoài phạm vi của lệnh gọi này nhưng trong ngắn hạn, bạn có thể triển khai một số loại hàm trên một cột nhất định (modulo hoặc băm trên cột 'id') hoặc bạn có thể xây dựng một siêu cơ sở dữ liệu riêng biệt, nơi bạn sẽ lưu trữ các chi tiết về cách dữ liệu được phân phối.
Chúng tôi hy vọng rằng bạn thấy loạt blog ngắn này có nhiều thông tin và bạn hiểu rõ hơn về những thách thức khác nhau mà chúng ta phải đối mặt khi muốn mở rộng môi trường cơ sở dữ liệu. Nếu bạn có bất kỳ nhận xét hoặc đề xuất nào về chủ đề này, vui lòng bình luận bên dưới bài đăng này và chia sẻ kinh nghiệm của bạn