Cơ sở dữ liệu quan hệ đại diện cho dữ liệu của một tổ chức trong các bảng sử dụng các cột với các kiểu dữ liệu khác nhau cho phép chúng lưu trữ các giá trị hợp lệ. Các nhà phát triển và DBA cần biết và hiểu loại dữ liệu thích hợp cho mỗi cột để có hiệu suất truy vấn tốt hơn.
Bài viết này sẽ đề cập đến các kiểu dữ liệu phổ biến VARCHAR () và NVARCHAR (), so sánh và đánh giá hiệu suất của chúng trong SQL Server.
VARCHAR [( n | tối đa )] trong SQL
VARCHAR kiểu dữ liệu đại diện cho không phải Unicode kiểu dữ liệu chuỗi có độ dài thay đổi. Bạn có thể lưu trữ các chữ cái, số và các ký tự đặc biệt trong đó.
- N đại diện cho kích thước chuỗi tính bằng byte.
- Cột kiểu dữ liệu VARCHAR lưu trữ tối đa 8000 ký tự không phải Unicode.
- Kiểu dữ liệu VARCHAR có 1 byte cho mỗi ký tự. Nếu bạn không chỉ định rõ ràng giá trị cho N, nó sẽ chiếm 1 byte bộ nhớ.
Lưu ý:Đừng nhầm lẫn N với giá trị đại diện cho số ký tự trong một chuỗi.
Truy vấn sau xác định kiểu dữ liệu VARCHAR với 100 byte dữ liệu.
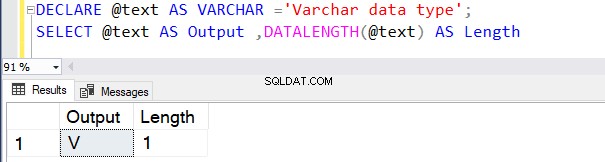
DECLARE @text AS VARCHAR(100) ='VARCHAR data type';
SELECT @text AS Output ,DATALENGTH(@text) AS Length
Nó trả về độ dài là 17 vì 1 byte trên mỗi ký tự, bao gồm cả ký tự khoảng trắng.
Truy vấn sau xác định kiểu dữ liệu VARCHAR không có bất kỳ giá trị nào của N . Do đó, SQL Server coi giá trị mặc định là 1 byte, như được hiển thị bên dưới.
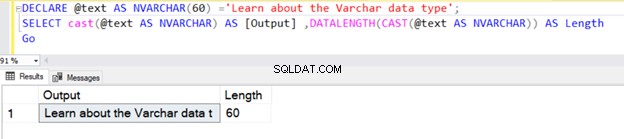
DECLARE @text AS VARCHAR ='VARCHAR data type';
SELECT @text AS Output ,DATALENGTH(@text) AS Length
Chúng ta cũng có thể sử dụng VARCHAR bằng cách sử dụng hàm CAST hoặc CONVERT. Ví dụ:trong hai ví dụ dưới đây, chúng tôi đã khai báo một biến có độ dài 100 byte và sau đó sử dụng toán tử CAST.
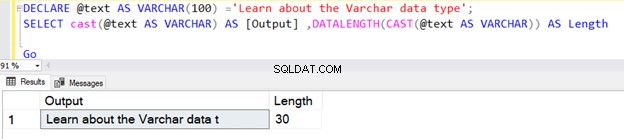
Truy vấn đầu tiên trả về độ dài là 30 vì chúng tôi không chỉ định N trong kiểu dữ liệu VARCHAR của toán tử CAST. Độ dài mặc định là 30.
DECLARE @text AS VARCHAR(100) ='Learn about the VARCHAR data type';
SELECT cast(@text AS VARCHAR) AS [Output] ,DATALENGTH(CAST(@text AS VARCHAR)) AS Length
Go
Tuy nhiên, nếu độ dài chuỗi nhỏ hơn 30, thì nó sẽ có kích thước thực của chuỗi.

NVARCHAR [( n | tối đa )] trong SQL
NVARCHAR kiểu dữ liệu dành cho Unicode kiểu dữ liệu ký tự có độ dài thay đổi. Ở đây, N đề cập đến Bộ ký tự ngôn ngữ quốc gia và được sử dụng để xác định chuỗi Unicode. Bạn có thể lưu trữ cả các ký tự không phải Unicode và Unicode (Kanji Nhật Bản, Hangul Hàn Quốc, v.v.).
- N đại diện cho kích thước chuỗi tính bằng byte.
- Nó có thể lưu trữ tối đa 4000 ký tự Unicode và không phải Unicode.
- Kiểu dữ liệu VARCHAR có 2 byte cho mỗi ký tự. Sẽ mất 2 byte bộ nhớ nếu bạn không chỉ định bất kỳ giá trị nào cho N.
Truy vấn sau xác định kiểu dữ liệu VARCHAR với 100 byte dữ liệu.
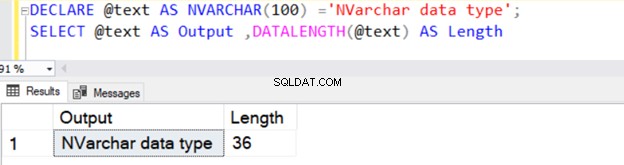
DECLARE @text AS NVARCHAR(100) ='NVARCHAR data type';
SELECT @text AS Output ,DATALENGTH(@text) AS Length
Nó trả về độ dài chuỗi là 36 vì NVARCHAR chiếm 2 byte cho mỗi ký tự lưu trữ.
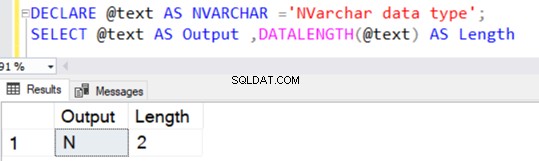
Tương tự như kiểu dữ liệu VARCHAR, NVARCHAR cũng có giá trị mặc định là 1 ký tự (2 byte) mà không chỉ định giá trị rõ ràng cho N.
Nếu chúng tôi áp dụng chuyển đổi NVARCHAR bằng cách sử dụng hàm CAST hoặc CONVERT mà không có bất kỳ giá trị N rõ ràng nào, giá trị mặc định là 30 ký tự, tức là 60 byte.
Lưu trữ các giá trị Unicode và không phải Unicode trong Kiểu dữ liệu VARCHAR
Giả sử chúng ta có một bảng ghi lại phản hồi của khách hàng từ một cổng thông tin mua sắm điện tử. Với mục đích này, chúng tôi có một bảng SQL với truy vấn sau.
CREATE TABLE UserComments
(
ID int IDENTITY (1,1),
[Language] VARCHAR(50),
[comment] VARCHAR(200),
[NewComment] NVARCHAR(200)
)
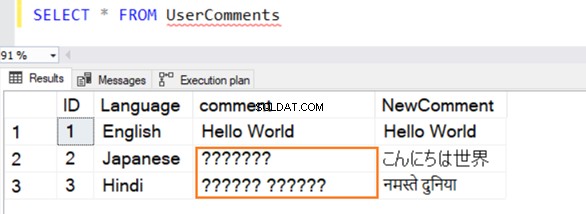
Chúng tôi chèn một số bản ghi mẫu vào bảng này bằng tiếng Anh, tiếng Nhật và tiếng Hindi. Loại dữ liệu cho [Nhận xét] là VARCHAR và [NewComment] là NVARCHAR () .
INSERT INTO UserComments ([Language],[Comment],[NewComment])
VALUES ('English','Hello World', N'Hello World')
INSERT INTO UserComments ([Language],[Comment],[NewComment])
VALUES ('Japanese','こんにちは世界', N'こんにちは世界')
INSERT INTO UserComments ([Language],[Comment],[NewComment])
VALUES ('Hindi','नमस्ते दुनिया', N'नमस्ते दुनिया')
Truy vấn thực thi thành công và nó đưa ra các hàng sau trong khi chọn một giá trị từ nó. Đối với hàng 2 và 3, nó không nhận dạng được dữ liệu nếu nó không phải bằng tiếng Anh.
Loại dữ liệu VARCHAR và NVARCHAR:So sánh hiệu suất
Chúng ta không nên kết hợp việc sử dụng kiểu dữ liệu VARCHAR và NVARCHAR trong các vị từ JOIN hoặc WHERE. Nó làm mất hiệu lực các chỉ mục hiện có vì SQL Server yêu cầu các kiểu dữ liệu giống nhau ở cả hai phía của JOIN. SQL Server cố gắng thực hiện chuyển đổi ngầm bằng cách sử dụng hàm CONVERT_IMPLICIT () trong trường hợp không khớp.
SQL Server sử dụng mức độ ưu tiên của kiểu dữ liệu để xác định kiểu dữ liệu đích. NVARCHAR có mức độ ưu tiên cao hơn kiểu dữ liệu VARCHAR. Do đó, trong quá trình chuyển đổi kiểu dữ liệu, SQL Server sẽ chuyển đổi các giá trị VARCHAR hiện có thành NVARCHAR.
CREATE TABLE #PerformanceTest
(
[ID] INT NOT NULL IDENTITY(1, 1) PRIMARY KEY,
[Col1] VARCHAR(50) NOT NULL,
[Col2] NVARCHAR(50) NOT NULL
)
CREATE INDEX [ix_performancetest_col] ON #PerformanceTest (col1)
CREATE INDEX [ix_performancetest_col2] ON #PerformanceTest (col2)
INSERT INTO #PerformanceTest VALUES ('A',N'C')
Bây giờ, hãy thực thi hai câu lệnh SELECT truy xuất các bản ghi theo kiểu dữ liệu của chúng.
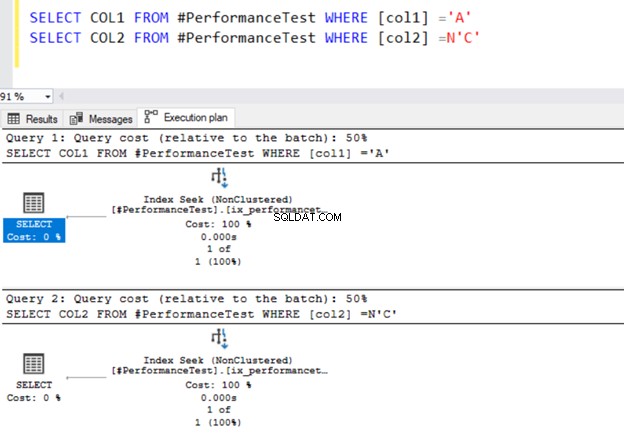
SELECT COL1 FROM #PerformanceTest WHERE [col1] ='A'
SELECT COL2 FROM #PerformanceTest WHERE [col2] =N'C'
Cả hai truy vấn đều sử dụng Toán tử tìm kiếm chỉ mục và các chỉ mục mà chúng tôi đã xác định trước đó.
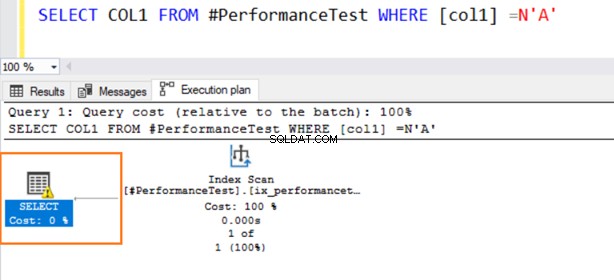
Bây giờ, chúng ta chuyển các giá trị kiểu dữ liệu để so sánh với vị từ WHERE. Cột 1 có kiểu dữ liệu VARCHAR, nhưng chúng tôi chỉ định N’A ’để đặt nó làm kiểu dữ liệu NVARCHAR.
Tương tự, col2 là kiểu dữ liệu NVARCHAR và chúng tôi chỉ định giá trị ‘C’ đề cập đến kiểu dữ liệu VARCHAR.
SELECT COL2 FROM #PerformanceTest WHERE [col2] ='C'Trong kế hoạch thực thi thực tế của truy vấn, bạn nhận được quét Chỉ mục và câu lệnh SELECT có biểu tượng cảnh báo.
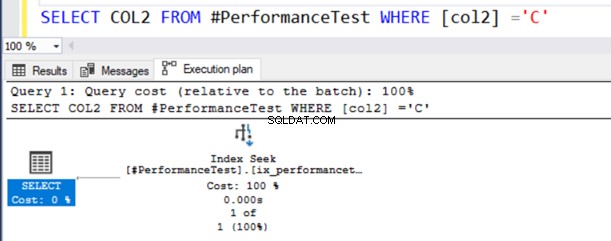
Truy vấn này hoạt động tốt vì kiểu dữ liệu NVARCHAR () có thể có cả giá trị Unicode và không phải Unicode.
Bây giờ, truy vấn thứ hai sử dụng quét Chỉ mục và đưa ra biểu tượng cảnh báo trên toán tử CHỌN.
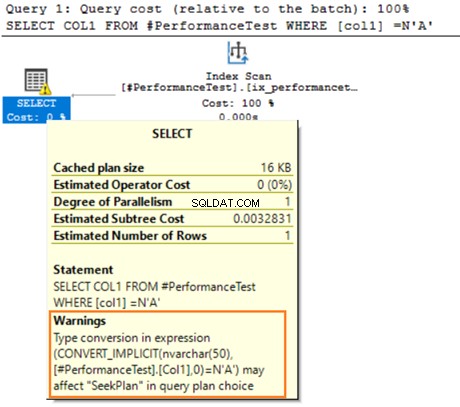
Di chuột qua câu lệnh SELECT đưa ra cảnh báo về chuyển đổi ngầm định. SQL Server không thể sử dụng chỉ mục hiện có đúng cách. Đó là do các thuật toán sắp xếp dữ liệu khác nhau cho cả kiểu dữ liệu VARCHAR và NVARCHAR.
Nếu bảng có hàng triệu hàng, SQL Server phải thực hiện công việc bổ sung và chuyển đổi dữ liệu bằng cách sử dụng chuyển đổi dữ liệu một cách ngầm định. Nó có thể ảnh hưởng tiêu cực đến hiệu suất truy vấn của bạn. Do đó, bạn nên tránh trộn và kết hợp các loại dữ liệu này trong việc tối ưu hóa các truy vấn.
Kết luận
Bạn nên xem xét các yêu cầu dữ liệu của mình trong khi thiết kế bảng cơ sở dữ liệu và kiểu dữ liệu cột của chúng một cách thích hợp. Thông thường, các máy chủ kiểu dữ liệu VARCHAR hầu hết các yêu cầu dữ liệu của bạn. Tuy nhiên, nếu bạn cần lưu trữ cả kiểu dữ liệu Unicode và không phải Unicode trong một cột, bạn có thể xem xét sử dụng NVARCHAR. Tuy nhiên, bạn nên xem lại hàm ý về hiệu suất, dung lượng lưu trữ trước khi đưa ra quyết định cuối cùng.