Tôi có một tiện ích nhập trên cùng một máy chủ vật lý với phiên bản SQL Server của tôi. Sử dụng IDataReader tùy chỉnh , nó phân tích cú pháp các tệp phẳng và chèn chúng vào cơ sở dữ liệu bằng cách sử dụng SQLBulkCopy . Một tệp thông thường có khoảng 6 triệu hàng đủ điều kiện, trung bình có 5 cột văn bản thập phân và văn bản ngắn, khoảng 30 byte mỗi hàng.
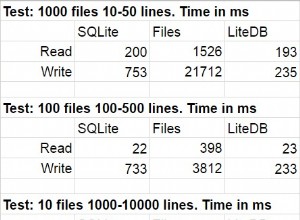
Với tình huống này, tôi nhận thấy kích thước hàng loạt là 5.000 là sự thỏa hiệp tốt nhất giữa tốc độ và mức tiêu thụ bộ nhớ. Tôi bắt đầu với 500 và thử nghiệm với lớn hơn. Tôi thấy 5000 nhanh hơn trung bình 2,5 lần so với 500. Việc chèn 6 triệu hàng mất khoảng 30 giây với kích thước lô là 5.000 và khoảng 80 giây với kích thước lô là 500.
10.000 nhanh hơn không thể đo lường được. Di chuyển lên 50.000 đã cải thiện tốc độ thêm một vài điểm phần trăm nhưng nó không đáng để tăng tải trên máy chủ. Trên 50.000 cho thấy tốc độ không được cải thiện.
Đây không phải là một công thức, nhưng là một điểm dữ liệu khác để bạn sử dụng.