Để trả lời câu hỏi của bạn tại sao SQL Server lại làm điều này, câu trả lời là truy vấn không được biên dịch theo thứ tự logic, mỗi câu lệnh được biên dịch dựa trên giá trị riêng của nó, vì vậy khi kế hoạch truy vấn cho câu lệnh chọn của bạn đang được tạo, trình tối ưu hóa không biết rằng @ val1 và @ Val2 sẽ trở thành 'val1' và 'val2' tương ứng.
Khi SQL Server không biết giá trị, nó phải phỏng đoán tốt nhất về số lần biến đó sẽ xuất hiện trong bảng, điều này đôi khi có thể dẫn đến các kế hoạch dưới mức tối ưu. Điểm chính của tôi là cùng một truy vấn với các giá trị khác nhau có thể tạo ra các kế hoạch khác nhau. Hãy tưởng tượng ví dụ đơn giản sau:
IF OBJECT_ID(N'tempdb..#T', 'U') IS NOT NULL
DROP TABLE #T;
CREATE TABLE #T (ID INT IDENTITY PRIMARY KEY, Val INT NOT NULL, Filler CHAR(1000) NULL);
INSERT #T (Val)
SELECT TOP 991 1
FROM sys.all_objects a
UNION ALL
SELECT TOP 9 ROW_NUMBER() OVER(ORDER BY a.object_id) + 1
FROM sys.all_objects a;
CREATE NONCLUSTERED INDEX IX_T__Val ON #T (Val);
Tất cả những gì tôi đã làm ở đây là tạo một bảng đơn giản và thêm 1000 hàng có giá trị 1-10 cho cột val , tuy nhiên 1 xuất hiện 991 lần và 9 cái còn lại chỉ xuất hiện một lần. Tiền đề là truy vấn này:
SELECT COUNT(Filler)
FROM #T
WHERE Val = 1;
Sẽ hiệu quả hơn nếu chỉ quét toàn bộ bảng thay vì sử dụng chỉ mục để tìm kiếm, sau đó thực hiện tra cứu 991 dấu trang để nhận giá trị cho Filler , tuy nhiên, chỉ với 1 hàng truy vấn sau:
SELECT COUNT(Filler)
FROM #T
WHERE Val = 2;
sẽ hiệu quả hơn khi thực hiện tìm kiếm chỉ mục và tra cứu dấu trang đơn lẻ để nhận giá trị cho Filler (và chạy hai truy vấn này sẽ phê chuẩn điều này)
Tôi khá chắc chắn rằng việc cắt bỏ tìm kiếm và tra cứu dấu trang thực sự khác nhau tùy thuộc vào tình huống, nhưng nó khá thấp. Sử dụng bảng ví dụ, với một chút thử và sai, tôi thấy rằng tôi cần Val cột có 38 hàng với giá trị 2 trước khi trình tối ưu hóa quét toàn bộ bảng qua tìm kiếm chỉ mục và tra cứu dấu trang:
IF OBJECT_ID(N'tempdb..#T', 'U') IS NOT NULL
DROP TABLE #T;
DECLARE @I INT = 38;
CREATE TABLE #T (ID INT IDENTITY PRIMARY KEY, Val INT NOT NULL, Filler CHAR(1000) NULL);
INSERT #T (Val)
SELECT TOP (991 - @i) 1
FROM sys.all_objects a
UNION ALL
SELECT TOP (@i) 2
FROM sys.all_objects a
UNION ALL
SELECT TOP 8 ROW_NUMBER() OVER(ORDER BY a.object_id) + 2
FROM sys.all_objects a;
CREATE NONCLUSTERED INDEX IX_T__Val ON #T (Val);
SELECT COUNT(Filler), COUNT(*)
FROM #T
WHERE Val = 2;
Vì vậy, đối với ví dụ này, giới hạn là 3,7% số hàng phù hợp.
Vì truy vấn không biết có bao nhiêu hàng sẽ khớp khi bạn đang sử dụng một biến nên nó phải đoán và cách đơn giản nhất là tìm ra tổng số hàng và chia giá trị này cho tổng số giá trị riêng biệt trong cột, vì vậy trong ví dụ này, số hàng ước tính cho WHERE val = @Val là 1000/10 =100, Thuật toán thực tế phức tạp hơn điều này, nhưng vì lợi ích của ví dụ, điều này sẽ làm được. Vì vậy, khi chúng tôi xem xét kế hoạch thực hiện cho:
DECLARE @i INT = 2;
SELECT COUNT(Filler)
FROM #T
WHERE Val = @i;
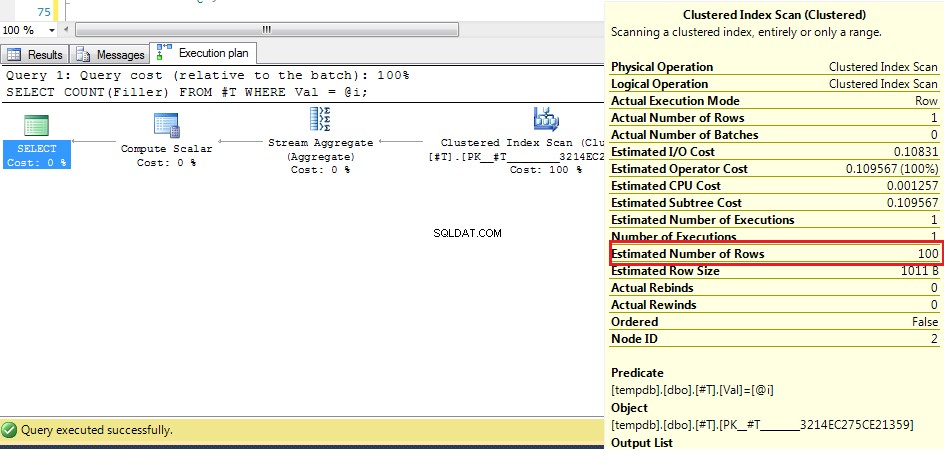
Chúng ta có thể thấy ở đây (với dữ liệu gốc) rằng số hàng ước tính là 100, nhưng số hàng thực tế là 1. Từ các bước trước, chúng ta biết rằng với hơn 38 hàng, trình tối ưu hóa sẽ chọn quét chỉ mục theo nhóm trên một chỉ mục tìm kiếm, vì vậy dự đoán tốt nhất cho số hàng cao hơn giá trị này, nên kế hoạch cho một biến không xác định là quét chỉ mục theo nhóm.
Chỉ để chứng minh thêm cho lý thuyết, nếu chúng ta tạo bảng với 1000 hàng số 1-27 phân bố đều (do đó, số hàng ước tính sẽ là khoảng 1000/27 =37,037)
IF OBJECT_ID(N'tempdb..#T', 'U') IS NOT NULL
DROP TABLE #T;
CREATE TABLE #T (ID INT IDENTITY PRIMARY KEY, Val INT NOT NULL, Filler CHAR(1000) NULL);
INSERT #T (Val)
SELECT TOP 27 ROW_NUMBER() OVER(ORDER BY a.object_id)
FROM sys.all_objects a;
INSERT #T (val)
SELECT TOP 973 t1.Val
FROM #T AS t1
CROSS JOIN #T AS t2
CROSS JOIN #T AS t3
ORDER BY t2.Val, t3.Val;
CREATE NONCLUSTERED INDEX IX_T__Val ON #T (Val);
Sau đó chạy lại truy vấn, chúng tôi nhận được một kế hoạch với tìm kiếm chỉ mục:
DECLARE @i INT = 2;
SELECT COUNT(Filler)
FROM #T
WHERE Val = @i;
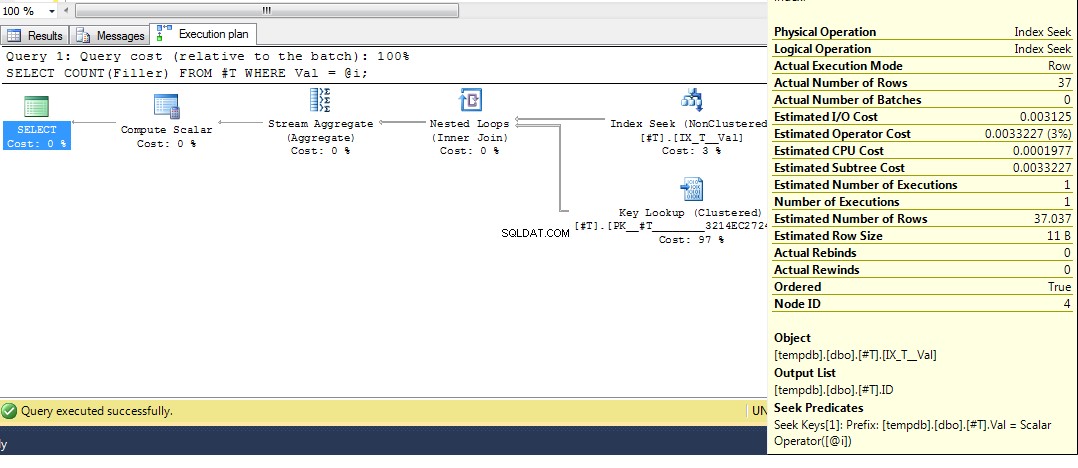
Vì vậy, hy vọng rằng khá toàn diện bao gồm lý do tại sao bạn có được kế hoạch đó. Bây giờ tôi cho rằng câu hỏi tiếp theo là làm thế nào để bạn bắt buộc một kế hoạch khác và câu trả lời là, sử dụng gợi ý truy vấn OPTION (RECOMPILE) , để buộc truy vấn biên dịch tại thời điểm thực thi khi giá trị của tham số được biết. Hoàn nguyên về dữ liệu gốc, đây là phương án tốt nhất cho Val = 2 là một tra cứu, nhưng sử dụng một biến mang lại một kế hoạch có quét chỉ mục, chúng ta có thể chạy:
DECLARE @i INT = 2;
SELECT COUNT(Filler)
FROM #T
WHERE Val = @i;
GO
DECLARE @i INT = 2;
SELECT COUNT(Filler)
FROM #T
WHERE Val = @i
OPTION (RECOMPILE);
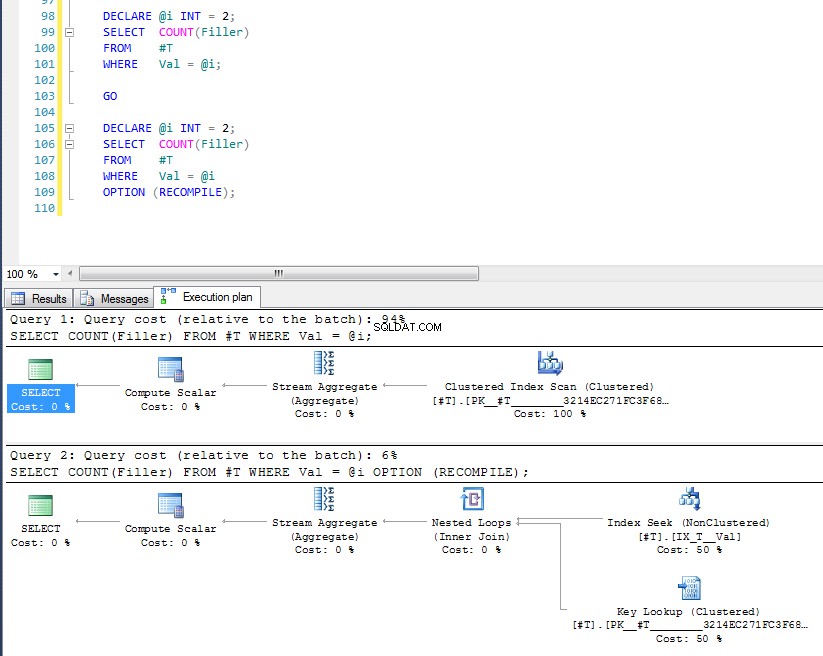
Chúng ta có thể thấy rằng cái sau sử dụng tìm kiếm chỉ mục và tra cứu khóa vì nó đã kiểm tra giá trị của biến tại thời điểm thực thi và phương án thích hợp nhất cho giá trị cụ thể đó được chọn. Sự cố với OPTION (RECOMPILE) điều đó có nghĩa là bạn không thể tận dụng các kế hoạch truy vấn đã lưu trong bộ nhớ cache, do đó, mỗi lần biên dịch truy vấn sẽ phải trả thêm phí.