Nối theo nhóm là một vấn đề phổ biến trong SQL Server, không có tính năng trực tiếp và cố ý nào để hỗ trợ nó (như XMLAGG trong Oracle, STRING_AGG hoặc ARRAY_TO_STRING (ARRAY_AGG ()) trong PostgreSQL và GROUP_CONCAT trong MySQL). Nó đã được yêu cầu, nhưng vẫn chưa thành công, bằng chứng là trong các mục Kết nối sau:
- Connect # 247118:SQL cần phiên bản của hàm MySQL group_Concat (Hoãn lại)
- Kết nối # 728969:Các chức năng được đặt có thứ tự - Mệnh đề TRONG NHÓM (Đã đóng là sẽ không khắc phục được)
** CẬP NHẬT Tháng 1 năm 2017 ** :STRING_AGG () sẽ có trong SQL Server 2017; đọc về nó ở đây, ở đây và ở đây.
Kết hợp được nhóm là gì?
Đối với nối nhóm chưa được khởi tạo, là khi bạn muốn lấy nhiều hàng dữ liệu và nén chúng thành một chuỗi duy nhất (thường có các dấu phân cách như dấu phẩy, tab hoặc dấu cách). Một số người có thể gọi đây là "liên kết ngang". Một ví dụ trực quan nhanh chóng cho thấy cách chúng tôi nén danh sách vật nuôi của từng thành viên trong gia đình, từ nguồn chuẩn hóa thành đầu ra "phẳng":
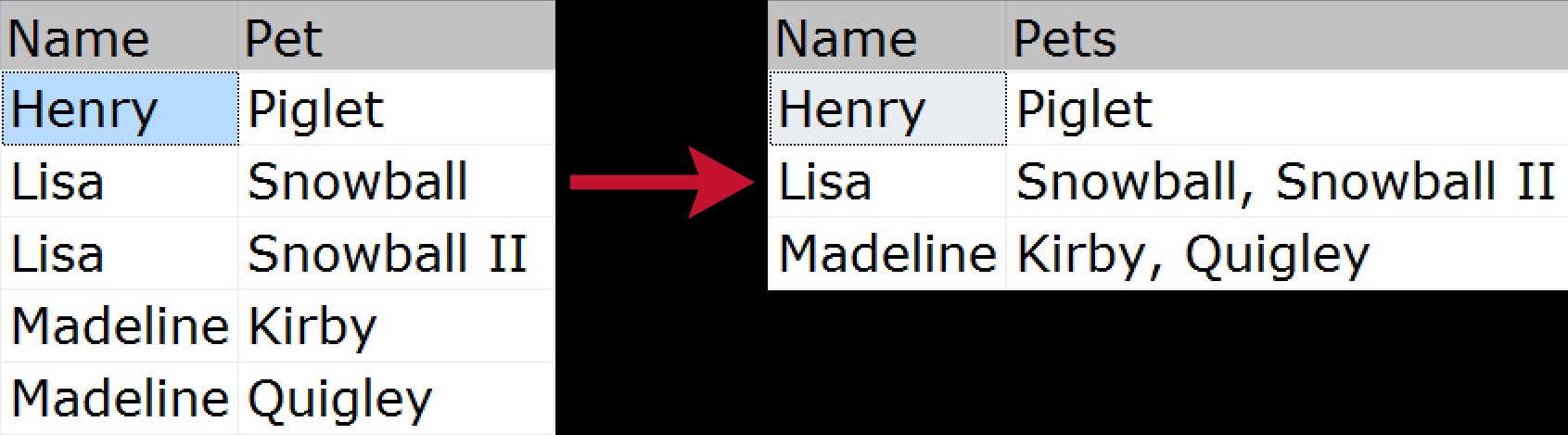
Đã có nhiều cách để giải quyết vấn đề này trong những năm qua; đây chỉ là một số, dựa trên dữ liệu mẫu sau:
CREATE TABLE dbo.FamilyMemberPets ( Name SYSNAME, Pet SYSNAME, PRIMARY KEY(Name,Pet) ); INSERT dbo.FamilyMemberPets(Name,Pet) VALUES (N'Madeline',N'Kirby'), (N'Madeline',N'Quigley'), (N'Henry', N'Piglet'), (N'Lisa', N'Snowball'), (N'Lisa', N'Snowball II');
Tôi sẽ không trình bày một danh sách đầy đủ về mọi phương pháp nối theo nhóm từng được hình thành, vì tôi muốn tập trung vào một vài khía cạnh của cách tiếp cận được đề xuất của mình, nhưng tôi muốn chỉ ra một vài khía cạnh phổ biến hơn:
UDF vô hướng
CREATE FUNCTION dbo.ConcatFunction
(
@Name SYSNAME
)
RETURNS NVARCHAR(MAX)
WITH SCHEMABINDING
AS
BEGIN
DECLARE @s NVARCHAR(MAX);
SELECT @s = COALESCE(@s + N', ', N'') + Pet
FROM dbo.FamilyMemberPets
WHERE Name = @Name
ORDER BY Pet;
RETURN (@s);
END
GO
SELECT Name, Pets = dbo.ConcatFunction(Name)
FROM dbo.FamilyMemberPets
GROUP BY Name
ORDER BY Name; Lưu ý:có lý do chúng tôi không làm điều này:
SELECT DISTINCT Name, Pets = dbo.ConcatFunction(Name) FROM dbo.FamilyMemberPets ORDER BY Name;
Với DISTINCT , hàm được chạy cho mỗi hàng đơn lẻ, sau đó các bản sao sẽ bị loại bỏ; với GROUP BY , các bản sao sẽ bị xóa trước.
Thời gian chạy ngôn ngữ chung (CLR)
Điều này sử dụng GROUP_CONCAT_S chức năng tìm thấy tại https://groupconcat.codeplex.com/:
SELECT Name, Pets = dbo.GROUP_CONCAT_S(Pet, 1) FROM dbo.FamilyMemberPets GROUP BY Name ORDER BY Name;
CTE đệ quy
Có một số biến thể về đệ quy này; cái này lấy ra một tập hợp các tên riêng biệt làm mỏ neo:
;WITH x as
(
SELECT Name, Pet = CONVERT(NVARCHAR(MAX), Pet),
r1 = ROW_NUMBER() OVER (PARTITION BY Name ORDER BY Pet)
FROM dbo.FamilyMemberPets
),
a AS
(
SELECT Name, Pet, r1 FROM x WHERE r1 = 1
),
r AS
(
SELECT Name, Pet, r1 FROM a WHERE r1 = 1
UNION ALL
SELECT x.Name, r.Pet + N', ' + x.Pet, x.r1
FROM x INNER JOIN r
ON r.Name = x.Name
AND x.r1 = r.r1 + 1
)
SELECT Name, Pets = MAX(Pet)
FROM r
GROUP BY Name
ORDER BY Name
OPTION (MAXRECURSION 0); Con trỏ
Không có nhiều để nói ở đây; con trỏ thường không phải là cách tiếp cận tối ưu, nhưng đây có thể là lựa chọn duy nhất của bạn nếu bạn gặp khó khăn trên SQL Server 2000:
DECLARE @t TABLE(Name SYSNAME, Pets NVARCHAR(MAX),
PRIMARY KEY (Name));
INSERT @t(Name, Pets)
SELECT Name, N''
FROM dbo.FamilyMemberPets GROUP BY Name;
DECLARE @name SYSNAME, @pet SYSNAME, @pets NVARCHAR(MAX);
DECLARE c CURSOR LOCAL FAST_FORWARD
FOR SELECT Name, Pet
FROM dbo.FamilyMemberPets
ORDER BY Name, Pet;
OPEN c;
FETCH c INTO @name, @pet;
WHILE @@FETCH_STATUS = 0
BEGIN
UPDATE @t SET Pets += N', ' + @pet
WHERE Name = @name;
FETCH c INTO @name, @pet;
END
CLOSE c; DEALLOCATE c;
SELECT Name, Pets = STUFF(Pets, 1, 1, N'')
FROM @t
ORDER BY Name;
GO Cập nhật kỳ quặc
Một số người * thích * cách tiếp cận này; Tôi không hiểu gì về sự hấp dẫn cả.
DECLARE @Name SYSNAME, @Pets NVARCHAR(MAX);
DECLARE @t TABLE(Name SYSNAME, Pet SYSNAME, Pets NVARCHAR(MAX),
PRIMARY KEY (Name, Pet));
INSERT @t(Name, Pet)
SELECT Name, Pet FROM dbo.FamilyMemberPets
ORDER BY Name, Pet;
UPDATE @t SET @Pets = Pets = COALESCE(
CASE COALESCE(@Name, N'')
WHEN Name THEN @Pets + N', ' + Pet
ELSE Pet END, N''),
@Name = Name;
SELECT Name, Pets = MAX(Pets)
FROM @t
GROUP BY Name
ORDER BY Name; ĐỐI VỚI XML PATH
Khá dễ dàng phương pháp ưa thích của tôi, ít nhất một phần vì nó là cách duy nhất để * đảm bảo * đặt hàng mà không cần sử dụng con trỏ hoặc CLR. Điều đó nói rằng, đây là một phiên bản rất thô không giải quyết được một số vấn đề cố hữu khác mà tôi sẽ thảo luận thêm về:
SELECT Name, Pets = STUFF((SELECT N', ' + Pet FROM dbo.FamilyMemberPets AS p2 WHERE p2.name = p.name ORDER BY Pet FOR XML PATH(N'')), 1, 2, N'') FROM dbo.FamilyMemberPets AS p GROUP BY Name ORDER BY Name;
Tôi đã thấy rất nhiều người nhầm tưởng rằng CONCAT() mới chức năng được giới thiệu trong SQL Server 2012 là câu trả lời cho các yêu cầu tính năng này. Hàm đó chỉ có nghĩa là hoạt động đối với các cột hoặc biến trong một hàng duy nhất; nó không thể được sử dụng để nối các giá trị giữa các hàng.
Tìm hiểu thêm về FOR XML PATH
FOR XML PATH('') riêng nó thì không đủ tốt - nó đã biết các vấn đề với việc thu hút XML. Ví dụ:nếu bạn cập nhật một trong các tên vật nuôi để bao gồm dấu ngoặc vuông HTML hoặc dấu và:
UPDATE dbo.FamilyMemberPets SET Pet = N'Qui>gle&y' WHERE Pet = N'Quigley';
Chúng được dịch sang các thực thể an toàn với XML ở đâu đó:
Qui>gle&y
Vì vậy, tôi luôn sử dụng PATH, TYPE).value() , như sau:
SELECT Name, Pets = STUFF((SELECT N', ' + Pet FROM dbo.FamilyMemberPets AS p2 WHERE p2.name = p.name ORDER BY Pet FOR XML PATH(N''), TYPE).value(N'.[1]', N'nvarchar(max)'), 1, 2, N'') FROM dbo.FamilyMemberPets AS p GROUP BY Name ORDER BY Name;
Tôi cũng luôn sử dụng NVARCHAR , bởi vì bạn không bao giờ biết khi nào một số cột bên dưới sẽ chứa Unicode (hoặc sau này được thay đổi để làm như vậy).
Bạn có thể thấy các giống sau bên trong .value() , hoặc thậm chí những người khác:
... TYPE).value(N'.', ... ... TYPE).value(N'(./text())[1]', ...
Chúng có thể thay thế cho nhau, tất cả cuối cùng đều đại diện cho cùng một chuỗi; sự khác biệt về hiệu suất giữa chúng (thêm bên dưới) là không đáng kể và có thể hoàn toàn không xác định.
Một vấn đề khác mà bạn có thể gặp phải là các ký tự ASCII nhất định không thể biểu diễn trong XML; ví dụ:nếu chuỗi chứa ký tự 0x001A (CHAR(26) ), bạn sẽ nhận được thông báo lỗi này:
FOR XML không thể tuần tự hóa dữ liệu cho nút 'NoName' vì nó chứa một ký tự (0x001A) không được phép trong XML. Để truy xuất dữ liệu này bằng FOR XML, hãy chuyển đổi nó sang kiểu dữ liệu nhị phân, varbinary hoặc hình ảnh và sử dụng lệnh BINARY BASE64.
Điều này có vẻ khá phức tạp đối với tôi, nhưng hy vọng bạn không phải lo lắng về nó vì bạn không lưu trữ dữ liệu như thế này hoặc ít nhất là bạn không cố gắng sử dụng nó trong nối nhóm. Nếu đúng như vậy, bạn có thể phải quay lại một trong các cách tiếp cận khác.
Hiệu suất
Dữ liệu mẫu trên giúp dễ dàng chứng minh rằng các phương pháp này đều làm được những gì chúng ta mong đợi, nhưng thật khó để so sánh chúng một cách có ý nghĩa. Vì vậy, tôi điền vào bảng với một tập hợp lớn hơn nhiều:
TRUNCATE TABLE dbo.FamilyMemberPets; INSERT dbo.FamilyMemberPets(Name,Pet) SELECT o.name, c.name FROM sys.all_objects AS o INNER JOIN sys.all_columns AS c ON o.[object_id] = c.[object_id] ORDER BY o.name, c.name;
Đối với tôi, đây là 575 đối tượng, với tổng số 7.080 hàng; đối tượng rộng nhất có 142 cột. Một lần nữa, phải thừa nhận rằng, tôi không bắt đầu so sánh mọi cách tiếp cận đơn lẻ được hình thành trong lịch sử của SQL Server; chỉ là một số điểm nổi bật tôi đã đăng ở trên. Đây là kết quả:
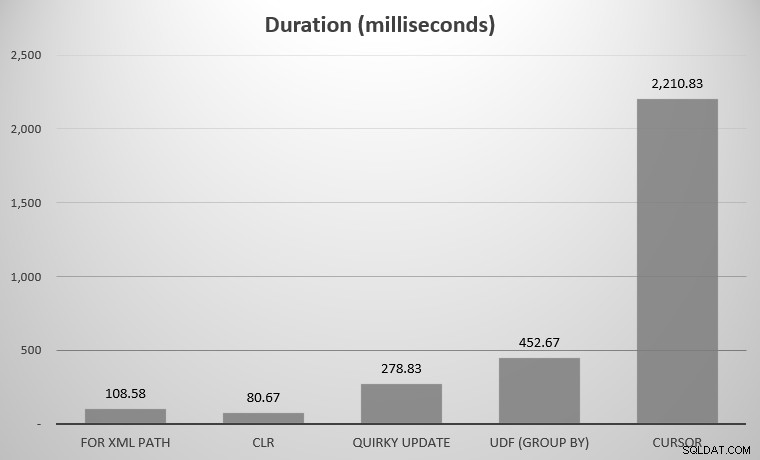
Bạn có thể nhận thấy một vài ứng cử viên bị thiếu; UDF sử dụng DISTINCT và CTE đệ quy nằm ngoài biểu đồ đến nỗi chúng sẽ làm lệch tỷ lệ. Dưới đây là kết quả của tất cả bảy phương pháp tiếp cận ở dạng bảng:
| Phương pháp tiếp cận | Thời lượng (mili giây) |
|---|---|
| ĐỐI VỚI XML PATH | 108,58 |
| CLR | 80,67 |
| Cập nhật kỳ quặc | 278,83 |
| UDF (GROUP BY) | 452,67 |
| UDF (DISTINCT) | 5.893,67 |
| Con trỏ | 2.210,83 |
| CTE đệ quy | 70.240,58 |
Thời lượng trung bình, tính bằng mili giây, cho tất cả các phương pháp tiếp cận
Cũng lưu ý rằng các biến thể trên FOR XML PATH đã được thử nghiệm độc lập nhưng cho thấy sự khác biệt rất nhỏ nên tôi chỉ kết hợp chúng để lấy trung bình. Nếu bạn thực sự muốn biết, hãy .[1] ký hiệu hoạt động nhanh nhất trong các thử nghiệm của tôi; YMMV.
Kết luận
Nếu bạn không ở trong một cửa hàng nơi CLR là rào cản theo bất kỳ cách nào, và đặc biệt nếu bạn không chỉ giao dịch với các tên đơn giản hoặc các chuỗi khác, bạn chắc chắn nên xem xét dự án CodePlex. Đừng thử và phát minh lại bánh xe, đừng thử các thủ thuật và thủ thuật không trực quan để thực hiện CROSS APPLY hoặc các cấu trúc khác hoạt động nhanh hơn một chút so với các cách tiếp cận không phải CLR ở trên. Chỉ cần lấy những gì hoạt động và cắm nó vào. Và tuyệt vời, vì bạn cũng nhận được mã nguồn, bạn có thể cải thiện nó hoặc mở rộng nó nếu bạn muốn.
Nếu CLR là một vấn đề, thì FOR XML PATH có thể là lựa chọn tốt nhất của bạn, nhưng bạn vẫn cần phải đề phòng những nhân vật khó tính. Nếu bạn gặp khó khăn trên SQL Server 2000, tùy chọn khả thi duy nhất của bạn là UDF (hoặc mã tương tự không được bao bọc trong UDF).
Lần tới
Một số điều tôi muốn khám phá trong bài đăng tiếp theo:xóa các bản sao khỏi danh sách, sắp xếp danh sách theo thứ khác với giá trị của chính nó, các trường hợp đặt bất kỳ cách tiếp cận nào trong số này vào UDF có thể gây khó khăn và các trường hợp sử dụng thực tế cho chức năng này.