Một vài tuần trước, tôi đã viết về việc tôi ngạc nhiên như thế nào trước hiệu suất của một hàm gốc mới trong SQL Server 2016, STRING_SPLIT() :
- Sự ngạc nhiên và giả định về hiệu suất:STRING_SPLIT ()
Sau khi bài đăng được xuất bản, tôi đã nhận được một số nhận xét (công khai và riêng tư) với các đề xuất này (hoặc các câu hỏi mà tôi đã chuyển thành đề xuất):
- Chỉ định kiểu dữ liệu đầu ra rõ ràng cho phương pháp JSON, để phương pháp đó không bị ảnh hưởng bởi chi phí hiệu suất tiềm ẩn do dự phòng của
nvarchar(max). - Thử nghiệm một cách tiếp cận hơi khác, trong đó dữ liệu thực sự được thực hiện - cụ thể là
SELECT INTO #temp. - Hiển thị cách số lượng hàng ước tính so với các phương pháp hiện có, đặc biệt là khi lồng các phép toán tách biệt.
Tôi đã trả lời ngoại tuyến cho một số người, nhưng tôi nghĩ rằng nên đăng bài theo dõi ở đây.
Công bằng hơn với JSON
Hàm JSON ban đầu trông giống như thế này, không có đặc điểm kỹ thuật nào cho kiểu dữ liệu đầu ra:
CREATE FUNCTION dbo.SplitStrings_JSON
...
RETURN (SELECT value FROM OPENJSON( CHAR(91) + @List + CHAR(93) )); Tôi đã đổi tên nó và tạo thêm hai cái nữa, với các định nghĩa sau:
CREATE FUNCTION dbo.SplitStrings_JSON_int
...
RETURN (SELECT value FROM OPENJSON( CHAR(91) + @List + CHAR(93) )
WITH ([value] int '$'));
GO
CREATE FUNCTION dbo.SplitStrings_JSON_varchar
...
RETURN (SELECT value FROM OPENJSON( CHAR(91) + @List + CHAR(93) )
WITH ([value] varchar(100) '$')); Tôi nghĩ rằng điều này sẽ cải thiện đáng kể hiệu suất, nhưng than ôi, đây không phải là trường hợp. Tôi đã chạy lại các bài kiểm tra và kết quả như sau:
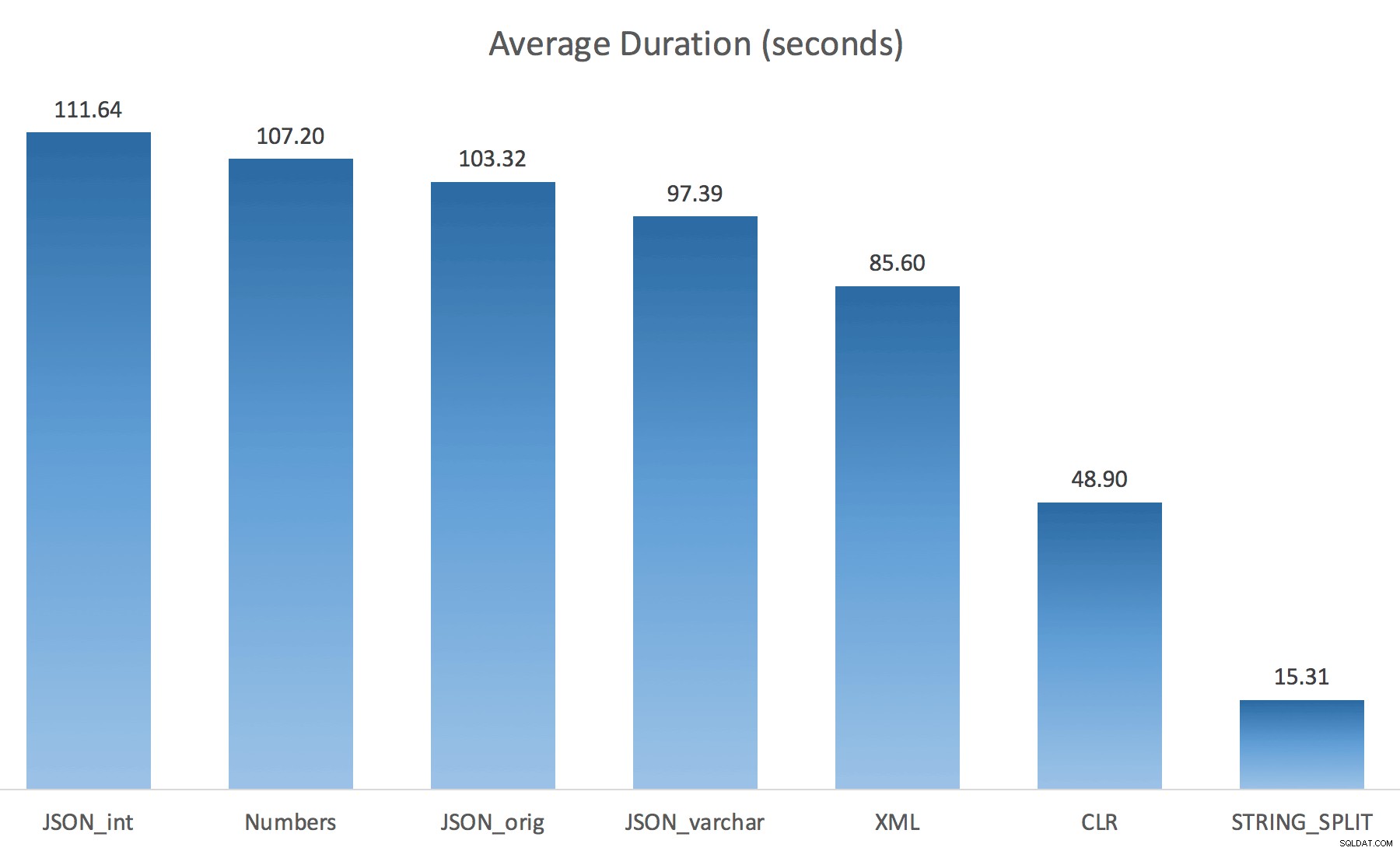
Số lần chờ được quan sát trong một trường hợp ngẫu nhiên của thử nghiệm (được lọc cho những người> 25):
| CLR | IO_COMPLETION | 1.595 |
| SOS_SCHEDULER_YIELD | 76 | |
| RESERVED_MEMORY_ALLOCATION_EXT | 76 | |
| MEMORY_ALLOCATION_EXT | 28 | |
| JSON_int | MEMORY_ALLOCATION_EXT | 6.294 |
| SOS_SCHEDULER_YIELD | 95 | |
| JSON_original | MEMORY_ALLOCATION_EXT | 4.307 |
| SOS_SCHEDULER_YIELD | 83 | |
| JSON_varchar | MEMORY_ALLOCATION_EXT | 6.110 |
| SOS_SCHEDULER_YIELD | 87 | |
| Số | SOS_SCHEDULER_YIELD | 96 |
| XML | MEMORY_ALLOCATION_EXT | 1.917 |
| IO_COMPLETION | 1,616 | |
| SOS_SCHEDULER_YIELD | 147 | |
| RESERVED_MEMORY_ALLOCATION_EXT | 73 |
Đã quan sát thấy số lần chờ> 25 (lưu ý rằng không có mục nhập nào cho STRING_SPLIT )
Trong khi thay đổi từ mặc định thành varchar(100) đã cải thiện hiệu suất một chút, mức tăng không đáng kể và chuyển thành int thực sự đã làm cho nó tồi tệ hơn. Thêm vào cái này mà bạn có thể cần thêm STRING_ESCAPE() vào chuỗi đến trong một số trường hợp, đề phòng trường hợp chúng có các ký tự sẽ làm xáo trộn quá trình phân tích cú pháp JSON. Kết luận của tôi vẫn là đây là một cách gọn gàng để sử dụng chức năng JSON mới, nhưng chủ yếu là một tính mới không phù hợp với quy mô hợp lý.
Hiện thực hóa đầu ra
Jonathan Magnan đã đưa ra nhận định sắc sảo này trong bài viết trước của tôi:
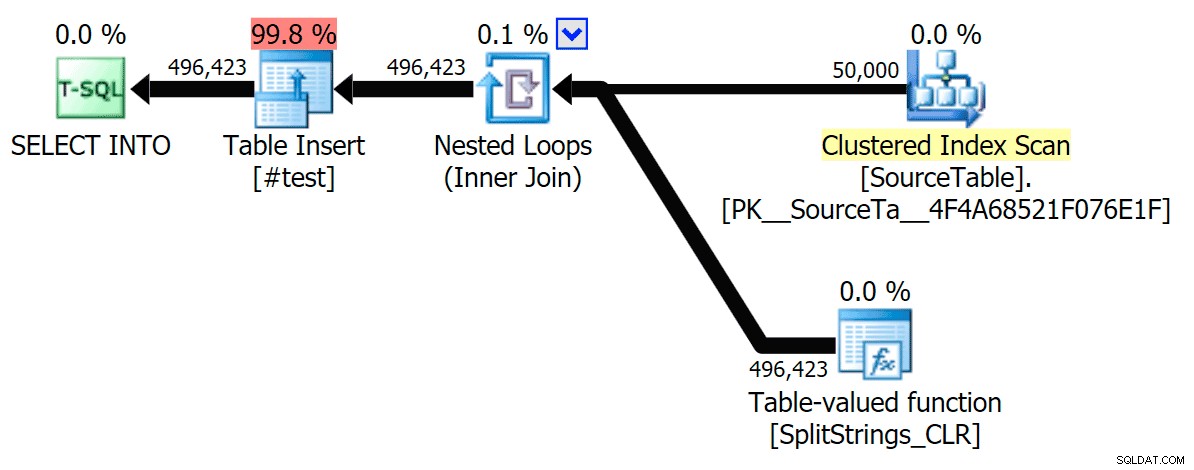
STRING_SPLIT thực sự là rất nhanh, tuy nhiên cũng chậm như địa ngục khi làm việc với bảng tạm thời (trừ khi nó được sửa trong bản dựng trong tương lai). SELECT f.value INTO #test FROM dbo.SourceTable AS s CROSS APPLY string_split(s.StringValue, ',') AS f
Sẽ chậm hơn WAY so với giải pháp SQL CLR (15x và hơn thế nữa!).
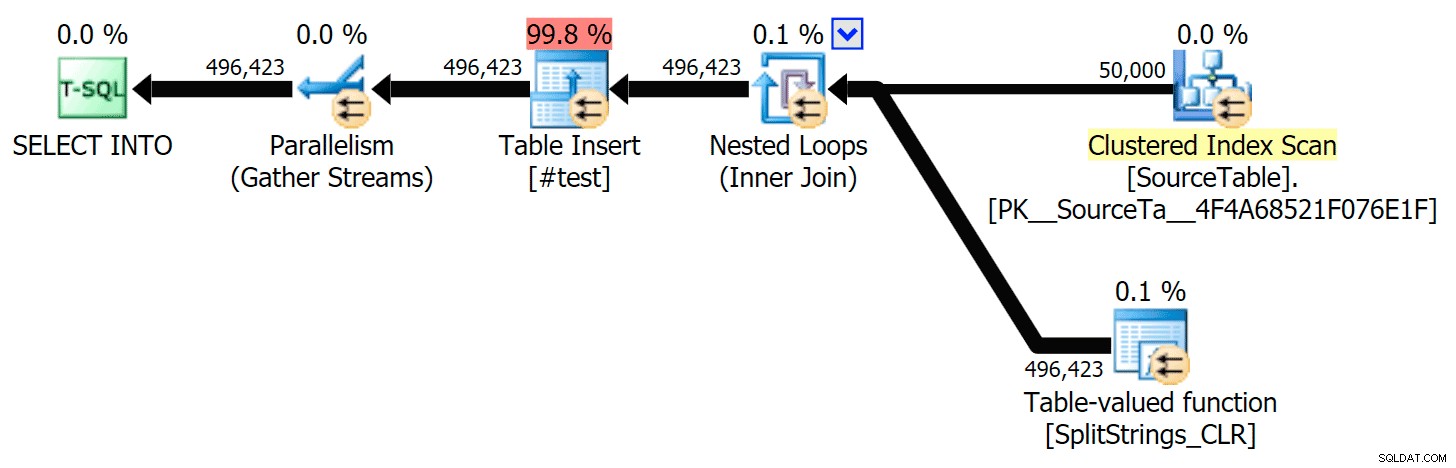
Vì vậy, tôi đã tìm hiểu kỹ. Tôi đã tạo mã sẽ gọi từng hàm của mình và kết xuất kết quả vào bảng #temp và định thời gian cho chúng:
SET NOCOUNT ON; SELECT N'SET NOCOUNT ON; TRUNCATE TABLE dbo.Timings; GO '; SELECT N'DECLARE @d DATETIME = SYSDATETIME(); INSERT dbo.Timings(dt, test, point, wait_type, wait_time_ms) SELECT @d, test = ''' + name + ''', point = ''Start'', wait_type, wait_time_ms FROM sys.dm_exec_session_wait_stats WHERE session_id = @@SPID; GO SELECT f.value INTO #test FROM dbo.SourceTable AS s CROSS APPLY dbo.'+name+'(s.StringValue, '','') AS f; GO DECLARE @d DATETIME = SYSDATETIME(); INSERT dbo.Timings(dt, test, point, wait_type, wait_time_ms) SELECT @d, '''+name+''', ''End'', wait_type, wait_time_ms FROM sys.dm_exec_session_wait_stats WHERE session_id = @@SPID; DROP TABLE #test; GO' FROM sys.objects WHERE name LIKE '%split%';
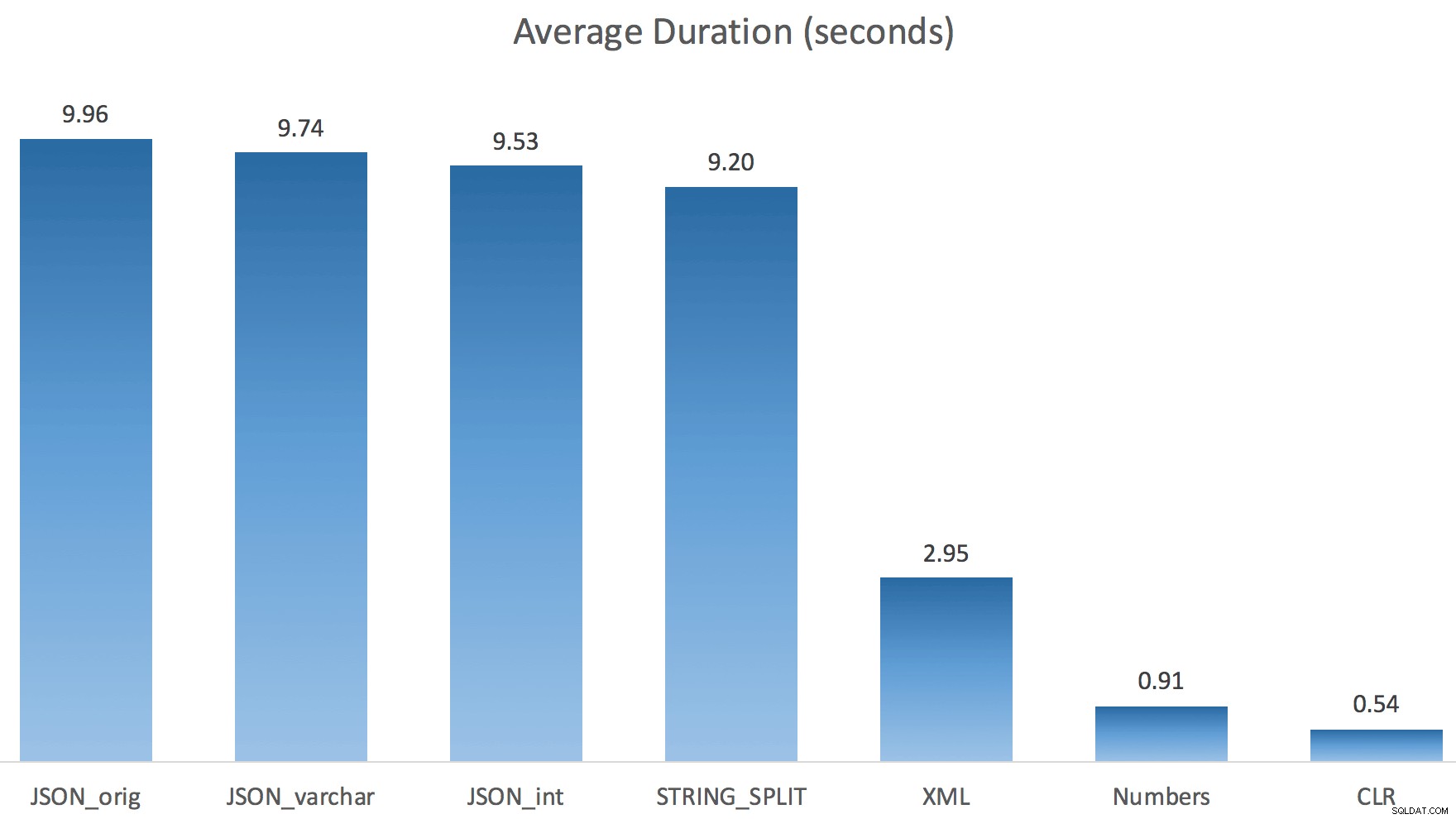
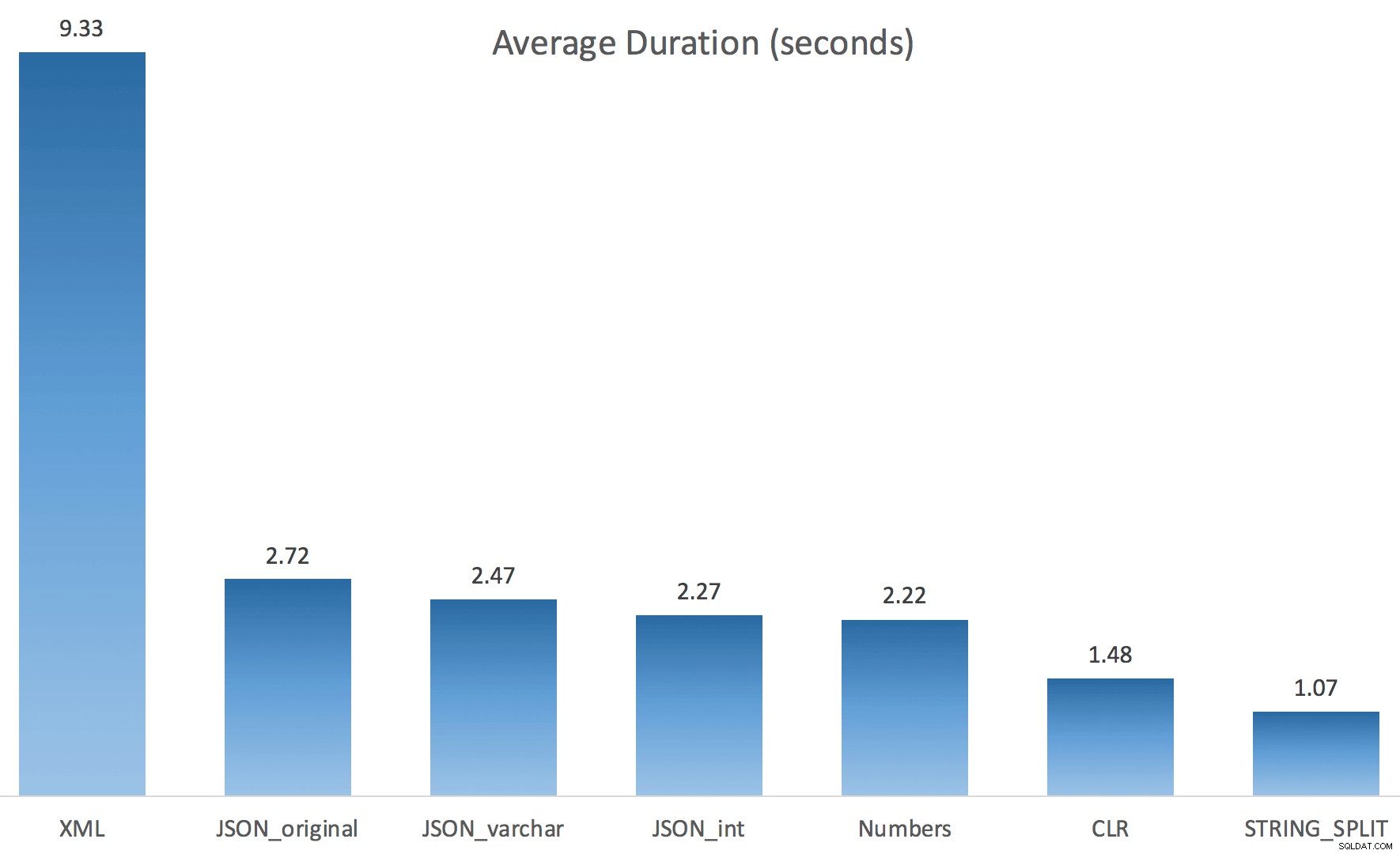
Tôi chỉ chạy mỗi bài kiểm tra một lần (thay vì lặp lại 100 lần), vì tôi không muốn hủy bỏ hoàn toàn I / O trên hệ thống của mình. Tuy nhiên, sau trung bình ba lần chạy thử nghiệm, Jonathan hoàn toàn đúng 100%. Dưới đây là khoảng thời gian điền một bảng #temp có ~ 500.000 hàng bằng cách sử dụng mỗi phương pháp:
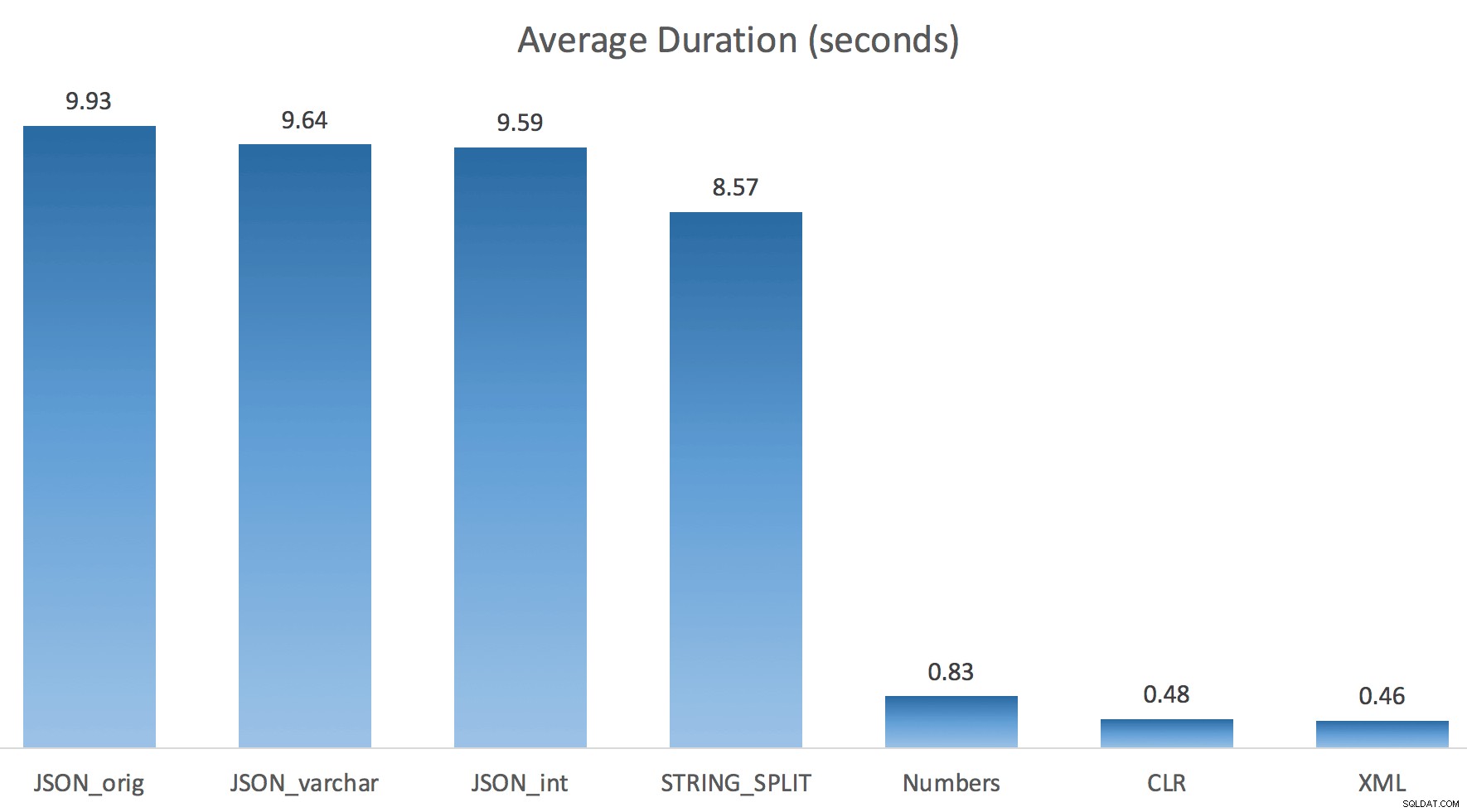
Vì vậy, đây là JSON và STRING_SPLIT mỗi phương thức mất khoảng 10 giây, trong khi các phương pháp tiếp cận bảng Numbers, CLR và XML mất chưa đến một giây. Thật bối rối, tôi đã điều tra những lần chờ đợi, và chắc chắn, bốn phương pháp ở bên trái tạo ra LATCH_EX đáng kể số lần chờ (khoảng 25 giây) không được thấy trong ba phần còn lại và không có lần chờ quan trọng nào khác để nói đến.
Và vì thời gian chờ chốt lớn hơn tổng thời gian, nó cho tôi manh mối rằng điều này phải làm với tính năng song song (máy cụ thể này có 4 lõi). Vì vậy, tôi đã tạo lại mã thử nghiệm, chỉ thay đổi một dòng để xem điều gì sẽ xảy ra mà không có tính năng song song:
CROSS APPLY dbo.'+name+'(s.StringValue, '','') AS f OPTION (MAXDOP 1);
Hiện tại STRING_SPLIT tốt hơn rất nhiều (cũng như các phương thức JSON), nhưng ít nhất vẫn gấp đôi thời gian thực hiện bởi CLR:
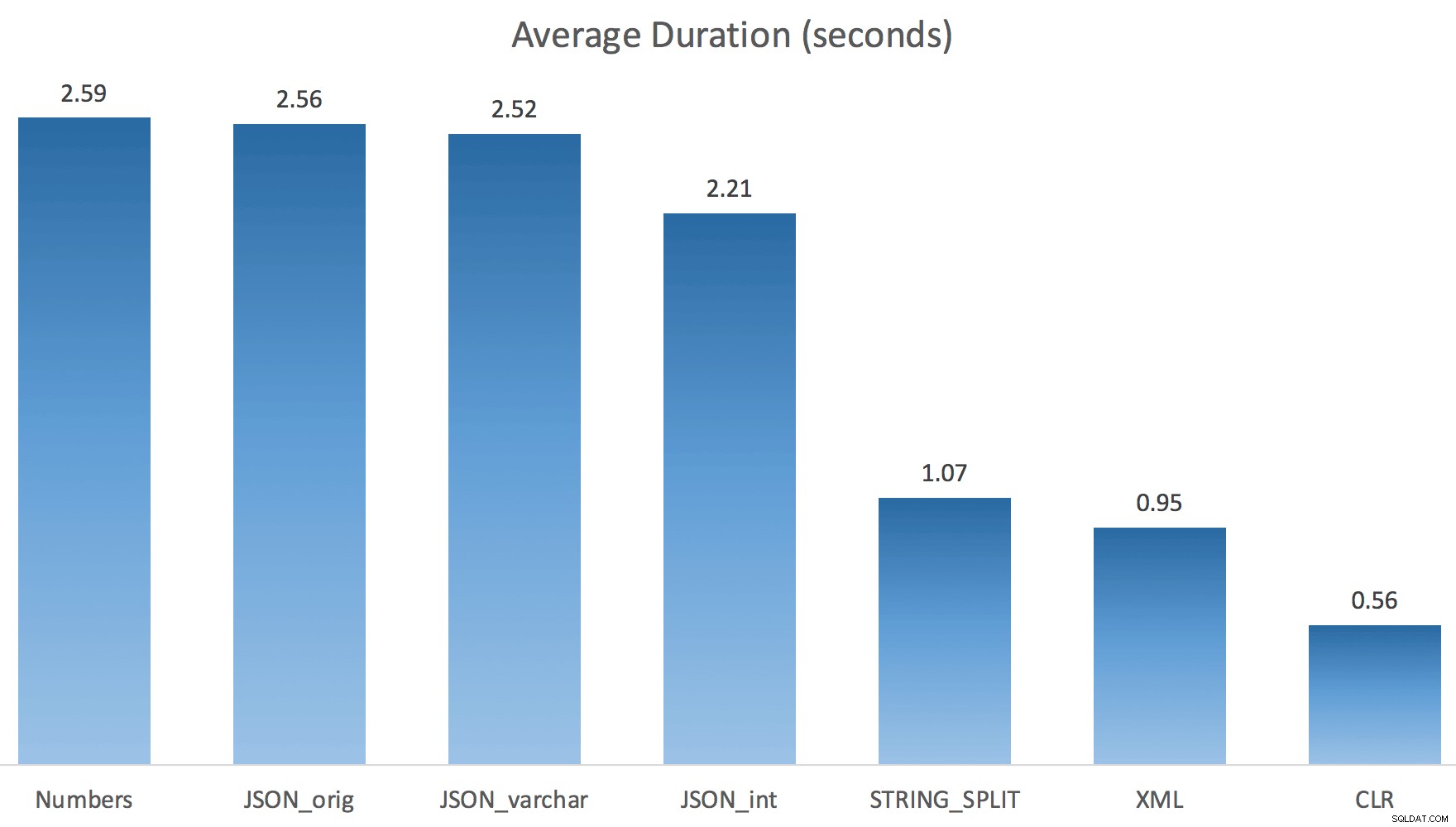
Vì vậy, có thể có một vấn đề còn lại trong các phương pháp mới này khi liên quan đến song song. Đó không phải là vấn đề phân phối luồng (tôi đã kiểm tra điều đó) và CLR thực sự có ước tính tồi hơn (100 lần thực tế so với chỉ 5 lần cho STRING_SPLIT ); chỉ là một số vấn đề cơ bản với việc phối hợp các chốt giữa các chủ đề mà tôi cho là. Hiện tại, có thể đáng giá khi sử dụng MAXDOP 1 nếu bạn biết mình đang viết kết quả lên các trang mới.
Tôi đã bao gồm các kế hoạch đồ họa so sánh phương pháp tiếp cận CLR với phương pháp gốc, cho cả thực thi song song và nối tiếp (tôi cũng đã tải lên tệp Phân tích truy vấn mà bạn có thể mở trong SQL Sentry Plan Explorer để tự dò tìm):
STRING_SPLIT
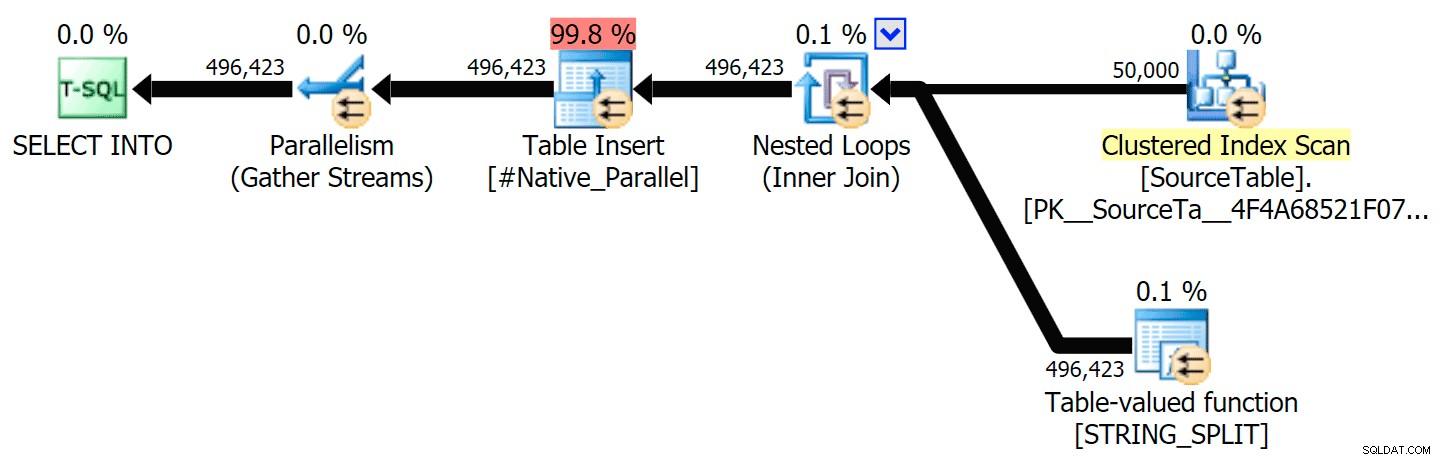
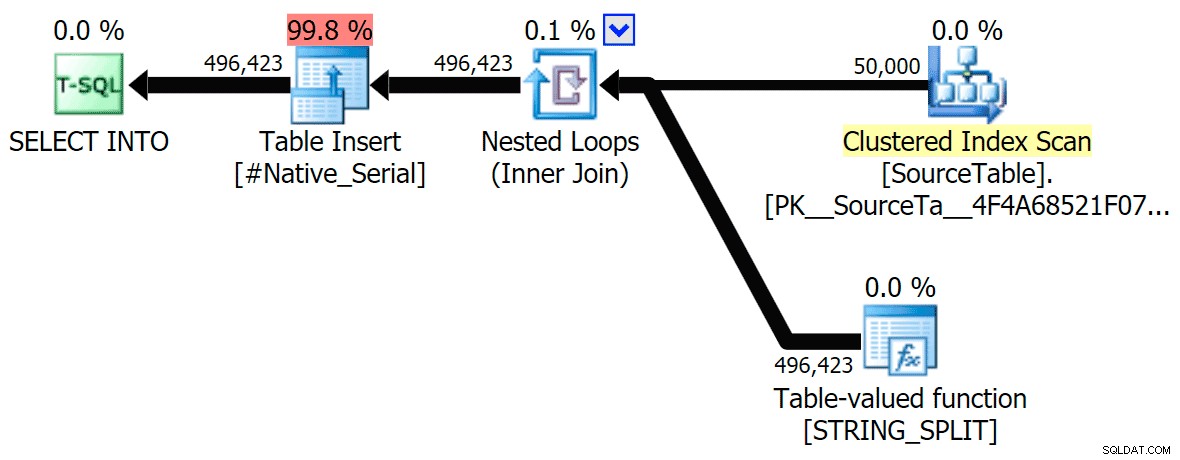
CLR
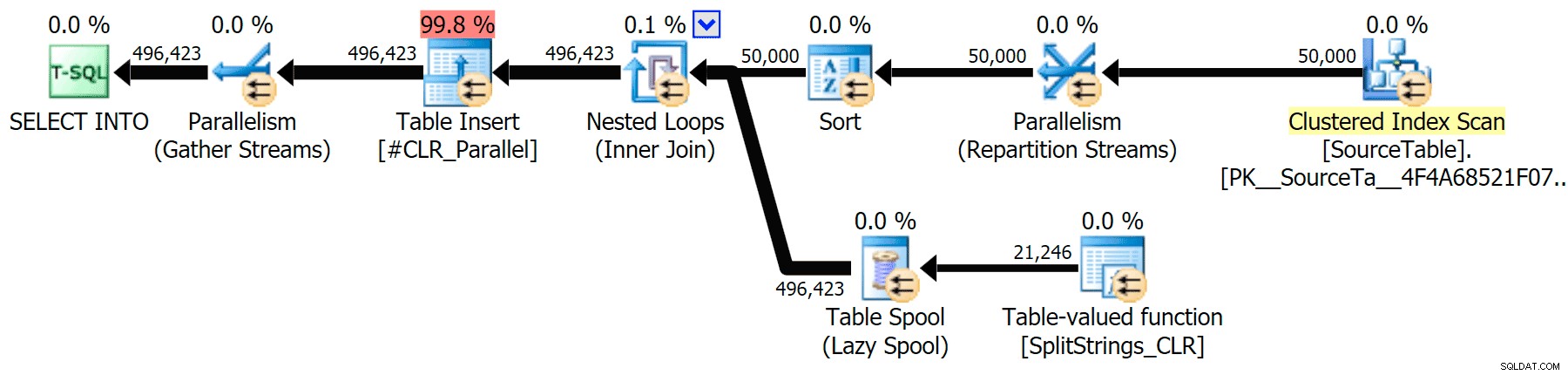
Cảnh báo sắp xếp, FYI, không có gì quá sốc và rõ ràng là không có nhiều ảnh hưởng rõ ràng đến thời lượng truy vấn:

- StringSplit.queryanalysis.zip (25kb)
Đi chơi mùa hè
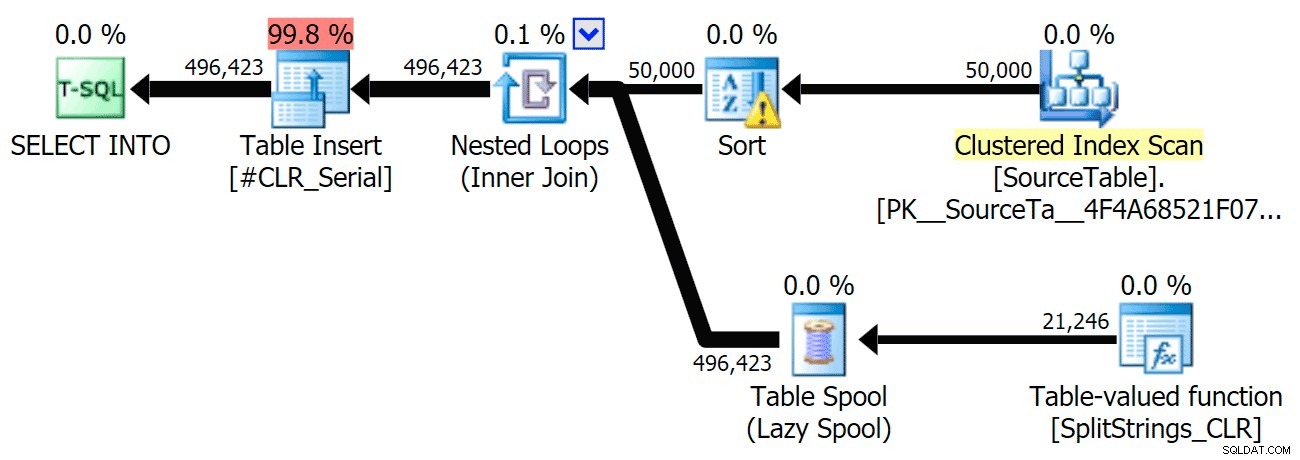
Khi tôi xem xét kỹ hơn một chút về các kế hoạch đó, tôi nhận thấy rằng trong kế hoạch CLR, có một ống lười. Điều này được giới thiệu để đảm bảo rằng các bản sao được xử lý cùng nhau (để tiết kiệm công việc bằng cách thực hiện ít chia tách thực tế hơn), nhưng ống cuộn này không phải lúc nào cũng có thể thực hiện được ở tất cả các hình dạng mặt bằng và nó có thể mang lại một chút lợi thế cho những người có thể sử dụng nó ( ví dụ:kế hoạch CLR), tùy thuộc vào ước tính. Để so sánh mà không có trục quay, tôi đã bật cờ theo dõi 8690 và chạy lại các bài kiểm tra. Đầu tiên, đây là kế hoạch CLR song song không có ống:
Và đây là thời lượng mới cho tất cả các truy vấn song song với TF 8690 được bật:
Bây giờ, đây là kế hoạch CLR nối tiếp không có ống đệm:
Và đây là kết quả thời gian cho các truy vấn sử dụng cả TF 8690 và MAXDOP 1 :
(Lưu ý rằng, ngoài kế hoạch XML, hầu hết các kế hoạch khác không thay đổi chút nào, có hoặc không có cờ theo dõi.)
So sánh số lượng hàng ước tính
Dan Holmes đã hỏi câu sau:
Nó ước tính kích thước dữ liệu như thế nào khi được kết hợp với một (hoặc nhiều) chức năng phân tách khác? Liên kết dưới đây là bản viết về triển khai phân tách Dựa trên CLR. Năm 2016 có thực hiện công việc 'tốt hơn' với các ước tính dữ liệu không? (rất tiếc là tôi chưa có khả năng cài đặt RC).https://sql.dnhlms.com/2016/02/sql-clr-based-string-splitting-and. html
Vì vậy, tôi đã vuốt mã từ bài đăng của Dan, thay đổi nó để sử dụng các chức năng của tôi và chạy nó thông qua Plan Explorer:
DECLARE @s VARCHAR(MAX); SELECT * FROM dbo.SplitStrings_CLR(@s, ',') s CROSS APPLY dbo.SplitStrings_CLR(s.value, ';') s1 CROSS APPLY dbo.SplitStrings_CLR(s1.value, '!') s2 CROSS APPLY dbo.SplitStrings_CLR(s2.value, '#') s3; SELECT * FROM dbo.SplitStrings_Numbers(@s, ',') s CROSS APPLY dbo.SplitStrings_Numbers(s.value, ';') s1 CROSS APPLY dbo.SplitStrings_Numbers(s1.value, '!') s2 CROSS APPLY dbo.SplitStrings_Numbers(s2.value, '#') s3; SELECT * FROM dbo.SplitStrings_Native(@s, ',') s CROSS APPLY dbo.SplitStrings_Native(s.value, ';') s1 CROSS APPLY dbo.SplitStrings_Native(s1.value, '!') s2 CROSS APPLY dbo.SplitStrings_Native(s2.value, '#') s3;
SPLIT_STRING phương pháp tiếp cận chắc chắn đưa ra các ước tính * tốt hơn * so với CLR, nhưng vẫn vượt quá (trong trường hợp này, khi chuỗi trống; điều này có thể không phải lúc nào cũng đúng). Hàm có một mặc định cài sẵn ước tính chuỗi đến sẽ có 50 phần tử, vì vậy khi bạn lồng chúng vào nhau, bạn sẽ nhận được 50 x 50 (2.500); nếu bạn lồng chúng lại, 50 x 2.500 (125.000); và cuối cùng là 50 x 125.000 (6.250.000):
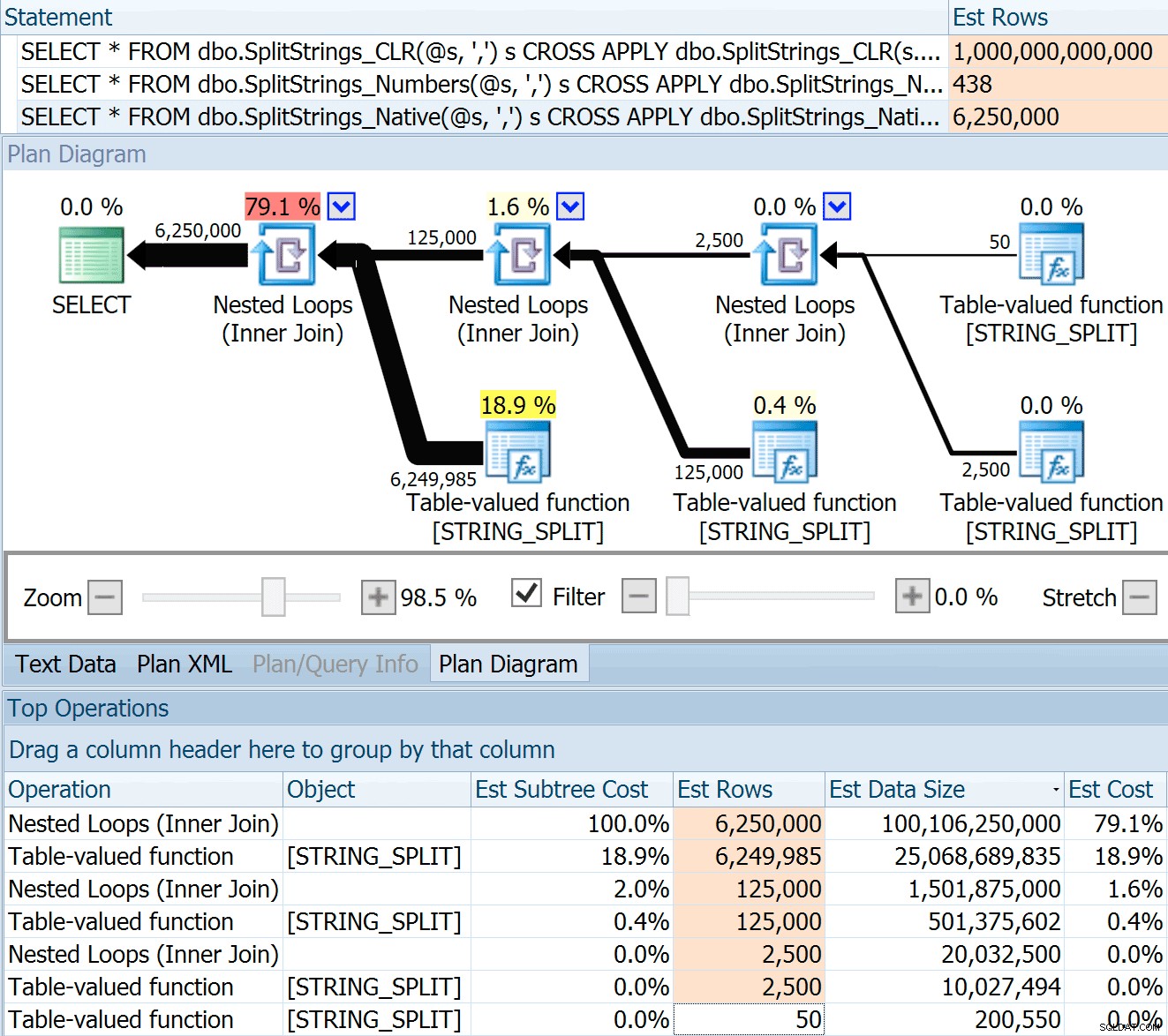
Lưu ý:OPENJSON() hoạt động giống hệt như STRING_SPLIT - nó cũng vậy, giả sử 50 hàng sẽ xuất hiện từ bất kỳ hoạt động phân tách nhất định nào. Tôi nghĩ rằng có thể hữu ích nếu có một cách để gợi ý về bản số cho các hàm như thế này, ngoài các cờ theo dõi như 4137 (trước năm 2014), 9471 &9472 (2014+) và tất nhiên là 9481…
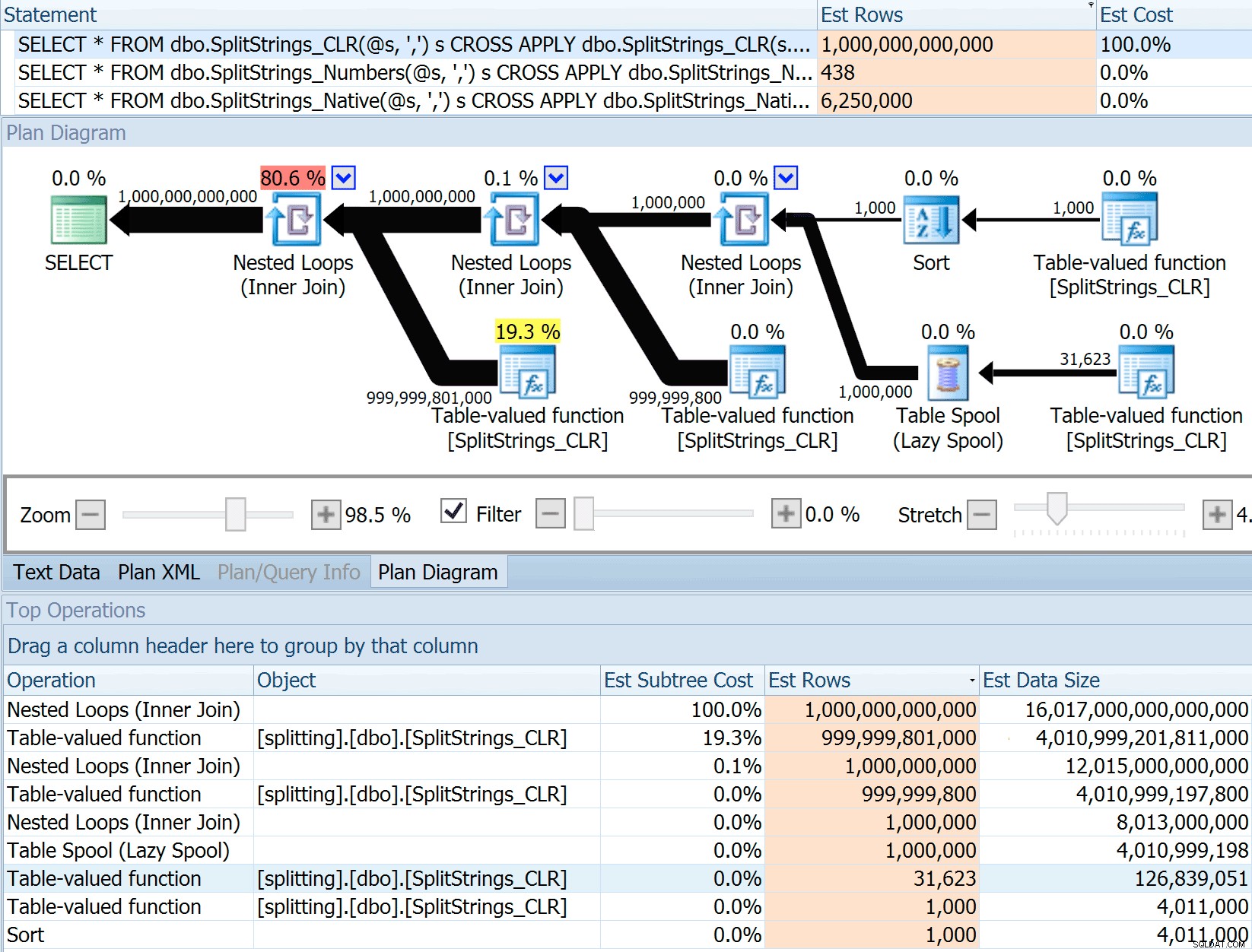
Ước tính 6,25 triệu hàng này không phải là tuyệt vời, nhưng nó tốt hơn nhiều so với cách tiếp cận CLR mà Dan đã đề cập, ước tính MỘT TRIỆU ROWS và tôi bị mất số dấu phẩy để xác định kích thước dữ liệu - 16 petabyte? exabyte?
Một số cách tiếp cận khác rõ ràng có giá tốt hơn về mặt ước tính. Ví dụ, bảng Numbers ước tính 438 hàng hợp lý hơn nhiều (trong SQL Server 2016 RC2). Con số này đến từ đâu? Chà, có 8.000 hàng trong bảng và nếu bạn nhớ, hàm có cả một đẳng thức và một vị từ bất đẳng thức:
WHERE Number <= LEN(@List)
AND SUBSTRING(@Delimiter + @List, [Number], 1) = @Delimiter Vì vậy, SQL Server nhân số hàng trong bảng với 10% (như một phỏng đoán) cho bộ lọc đẳng thức, rồi đến căn bậc hai 30% (một lần nữa, một phỏng đoán) cho bộ lọc bất bình đẳng. Căn bậc hai là do lũy thừa hàm mũ, Paul White giải thích ở đây. Điều này mang lại cho chúng tôi:
8000 * 0,1 * SQRT (0,3) =438,178Biến thể XML ước tính hơn một tỷ hàng một chút (do một cuộn bảng ước tính được thực thi 5,8 triệu lần), nhưng kế hoạch của nó quá phức tạp để cố gắng minh họa ở đây. Trong mọi trường hợp, hãy nhớ rằng các ước tính rõ ràng không nói lên toàn bộ câu chuyện - chỉ vì truy vấn có ước tính chính xác hơn không có nghĩa là nó sẽ hoạt động tốt hơn.
Có một số cách khác để tôi có thể điều chỉnh ước tính một chút:cụ thể là buộc mô hình ước tính bản số cũ (ảnh hưởng đến cả biến thể bảng XML và bảng Numbers) và sử dụng TFs 9471 và 9472 (chỉ ảnh hưởng đến biến thể bảng Numbers, vì cả hai đều kiểm soát số lượng xung quanh nhiều vị từ). Đây là những cách tôi có thể thay đổi ước tính một chút (hoặc RẤT NHIỀU , trong trường hợp hoàn nguyên về mô hình CE cũ):

Mô hình CE cũ đã làm giảm các ước tính XML theo một thứ tự độ lớn, nhưng đối với bảng Numbers, hoàn toàn thổi bay nó. Các cờ vị từ đã thay đổi ước tính cho bảng Numbers, nhưng những thay đổi đó ít thú vị hơn nhiều.
Không có cờ theo dõi nào trong số này có bất kỳ ảnh hưởng nào đến các ước tính cho CLR, JSON hoặc STRING_SPLIT các biến thể.
Kết luận
Vậy tôi đã học được gì ở đây? Thực ra là cả một đống:
- Song song có thể hữu ích trong một số trường hợp, nhưng khi nó không hữu ích, nó thực sự không giúp ích gì. Các phương thức JSON nhanh hơn ~ 5 lần mà không có tính năng song song và
STRING_SPLITnhanh hơn gần 10 lần. - Ống đệm thực sự đã giúp cách tiếp cận CLR hoạt động tốt hơn trong trường hợp này, nhưng TF 8690 có thể hữu ích để thử nghiệm trong các trường hợp khác khi bạn nhìn thấy ống cuộn và đang cố gắng cải thiện hiệu suất. Tôi chắc chắn rằng có những tình huống mà việc loại bỏ ống chỉ dẫn về tổng thể sẽ tốt hơn.
- Việc loại bỏ ống đệm thực sự làm tổn hại đến phương pháp tiếp cận XML (nhưng chỉ gây hại nghiêm trọng khi nó bị buộc phải là một luồng).
- Rất nhiều điều thú vị có thể xảy ra với các ước tính tùy thuộc vào cách tiếp cận, cùng với các số liệu thống kê, phân phối và cờ theo dõi thông thường. Chà, tôi cho rằng tôi đã biết điều đó, nhưng chắc chắn có một vài ví dụ hay, hữu hình ở đây.
Cảm ơn những người đã đặt câu hỏi hoặc khuyến khích tôi cung cấp thêm thông tin. Và như bạn có thể đoán từ tiêu đề, tôi giải quyết một câu hỏi khác trong phần tiếp theo thứ hai, câu hỏi này về TVPs:
- STRING_SPLIT () trong SQL Server 2016:Tiếp theo # 2