Đầu tuần này, tôi đã đăng một phần tiếp theo cho bài đăng gần đây của tôi về STRING_SPLIT() trong SQL Server 2016, giải quyết một số nhận xét còn lại trên bài đăng và / hoặc gửi trực tiếp cho tôi:
-
STRING_SPLIT()trong SQL Server 2016:Tiếp theo # 1
Sau khi bài đăng đó được viết gần hết, có một câu hỏi muộn từ Doug Ellner:
Làm thế nào để các hàm này so sánh với các tham số có giá trị bảng?
Bây giờ, thử nghiệm TVP đã nằm trong danh sách các dự án tương lai của tôi, sau cuộc trao đổi trên twitter gần đây với @Nick_Craver tại Stack Overflow. Anh ấy nói rằng họ rất vui vì STRING_SPLIT() hoạt động tốt, bởi vì họ không hài lòng với hiệu suất gửi ~ 7.000 giá trị thông qua một tham số có giá trị bảng.
Kiểm tra của tôi
Đối với các bài kiểm tra này, tôi đã sử dụng SQL Server 2016 RC3 (13.0.1400.361) trên máy ảo Windows 10 8 lõi, với bộ nhớ PCIe và 32 GB RAM.
Tôi đã tạo một bảng đơn giản bắt chước những gì họ đang làm (chọn khoảng 10.000 giá trị từ bảng hơn 3 triệu bài đăng hàng), nhưng đối với các thử nghiệm của tôi, nó có ít cột hơn và ít chỉ mục hơn:
TẠO BẢNG dbo.Posts_Regular (PostID int PRIMARY KEY, HitCount int NOT NULL DEFAULT 0); CHÈN dbo.Posts_Regular (PostID) CHỌN ĐẦU (3000000) ROW_NUMBER () HẾT (ĐẶT HÀNG THEO s1. [Object_id]) TỪ sys.all_objects AS s1 CROSS THAM GIA sys.all_objects AS s2;
Tôi cũng đã tạo phiên bản Trong bộ nhớ, vì tôi tò mò không biết có cách tiếp cận nào hoạt động khác ở đó không:
TẠO BẢNG dbo.Posts_InMemory (PostID int PRIMARY KEY KHÔNG ĐƯỢC ĐIỀU CHỈNH HASH VỚI (BUCKET_COUNT =4000000), HitCount int NOT NULL DEFAULT 0) WITH (MEMORY_OPTIMIZED =ON);
Bây giờ, tôi muốn tạo một ứng dụng C # sẽ chuyển 10.000 giá trị duy nhất, dưới dạng một chuỗi được phân tách bằng dấu phẩy (được tạo bằng StringBuilder) hoặc dưới dạng TVP (được chuyển từ DataTable). Vấn đề sẽ là truy xuất hoặc cập nhật lựa chọn các hàng dựa trên kết quả khớp, hoặc với một phần tử được tạo ra bằng cách tách danh sách hoặc một giá trị rõ ràng trong TVP. Vì vậy, mã được viết để nối mỗi giá trị thứ 300 vào chuỗi hoặc DataTable (Mã C # nằm trong phụ lục bên dưới). Tôi đã sử dụng các hàm mà tôi đã tạo trong bài đăng gốc, thay đổi chúng để xử lý varchar(max) , và sau đó thêm hai chức năng chấp nhận TVP - một trong số chúng được tối ưu hóa bộ nhớ. Dưới đây là các loại bảng (các chức năng có trong phụ lục bên dưới):
TẠO LOẠI dbo.PostIDs_Regular AS BẢNG (PostID int PRIMARY KEY); ĐI TẠO LOẠI dbo.PostIDs_InMemory AS TABLE (PostID int NOT NULL PRIMARY KEY NONCLUSTERED HASH WITH (BUCKET_COUNT =1000000)) VỚI (MEMORY_OPTIMIZED) / pre>Tôi cũng phải làm cho bảng Numbers lớn hơn để xử lý các chuỗi> 8K và với> 8K phần tử (tôi đã đặt nó là hàng 1MM). Sau đó, tôi tạo bảy thủ tục được lưu trữ:năm trong số chúng sử dụng
varchar(max)và kết hợp với đầu ra chức năng để cập nhật bảng cơ sở, sau đó hai để chấp nhận TVP và tham gia trực tiếp vào đó. Mã C # gọi từng quy trình trong số bảy quy trình này, với danh sách 10.000 bài đăng để chọn hoặc cập nhật, 1.000 lần. Các thủ tục này cũng có trong phụ lục bên dưới. Vì vậy, chỉ để tóm tắt, các phương pháp đang được thử nghiệm là:
- Gốc (
STRING_SPLIT()) - XML
- CLR
- Bảng số
- JSON (với
intrõ ràng đầu ra) - Tham số có giá trị trong bảng
- Tham số có giá trị trong bảng được tối ưu hóa bộ nhớ
Chúng tôi sẽ kiểm tra việc truy xuất 10.000 giá trị, 1.000 lần, bằng cách sử dụng DataReader - nhưng không lặp lại qua DataReader, vì điều đó sẽ chỉ làm cho quá trình kiểm tra mất nhiều thời gian hơn và sẽ là số lượng công việc tương tự đối với ứng dụng C # bất kể cơ sở dữ liệu như thế nào. sản xuất bộ. Chúng tôi cũng sẽ thử nghiệm cập nhật 10.000 hàng, mỗi hàng 1.000 lần, sử dụng ExecuteNonQuery() . Và chúng tôi sẽ kiểm tra cả phiên bản thông thường và phiên bản được tối ưu hóa bộ nhớ của bảng Bài đăng, chúng tôi có thể chuyển đổi rất dễ dàng mà không cần phải thay đổi bất kỳ hàm hoặc thủ tục nào, sử dụng từ đồng nghĩa:
TẠO SYNONYM dbo.Posts CHO dbo.Posts_Regular; - để kiểm tra phiên bản tối ưu hóa bộ nhớ:DROP SYNONYM dbo.Posts; TẠO SYNONYM dbo.Posts CHO dbo.Posts_InMemory; - để kiểm tra lại phiên bản dựa trên đĩa:DROP SYNONYM dbo.Posts; CREATE SYNONYM dbo.Posts FOR dbo.Posts_Regular;
Tôi khởi động ứng dụng, chạy nó nhiều lần cho mỗi tổ hợp để đảm bảo biên dịch, bộ nhớ đệm và các yếu tố khác không gây bất công cho lô được thực thi đầu tiên, sau đó phân tích kết quả từ bảng ghi nhật ký (tôi cũng đã kiểm tra tại chỗ các hệ thống được kiểm tra). dm_exec_procedure_stats để đảm bảo không có phương pháp nào có chi phí đáng kể dựa trên ứng dụng và chúng thì không).
Kết quả - Bảng Dựa trên Đĩa
Đôi khi tôi gặp khó khăn với việc trực quan hóa dữ liệu - tôi thực sự đã cố gắng tìm ra cách để biểu diễn các chỉ số này trên một biểu đồ duy nhất, nhưng tôi nghĩ rằng có quá nhiều điểm dữ liệu để làm cho những điểm nổi bật này trở nên nổi bật.
Bạn có thể nhấp để phóng to bất kỳ mục nào trong số này trong tab / cửa sổ mới, nhưng ngay cả khi bạn có một cửa sổ nhỏ, tôi đã cố gắng làm rõ người chiến thắng thông qua việc sử dụng màu sắc (và người chiến thắng là như nhau trong mọi trường hợp). Và nói rõ hơn, theo "Thời lượng trung bình", ý tôi là lượng thời gian trung bình cần để ứng dụng hoàn thành một vòng lặp 1.000 thao tác.
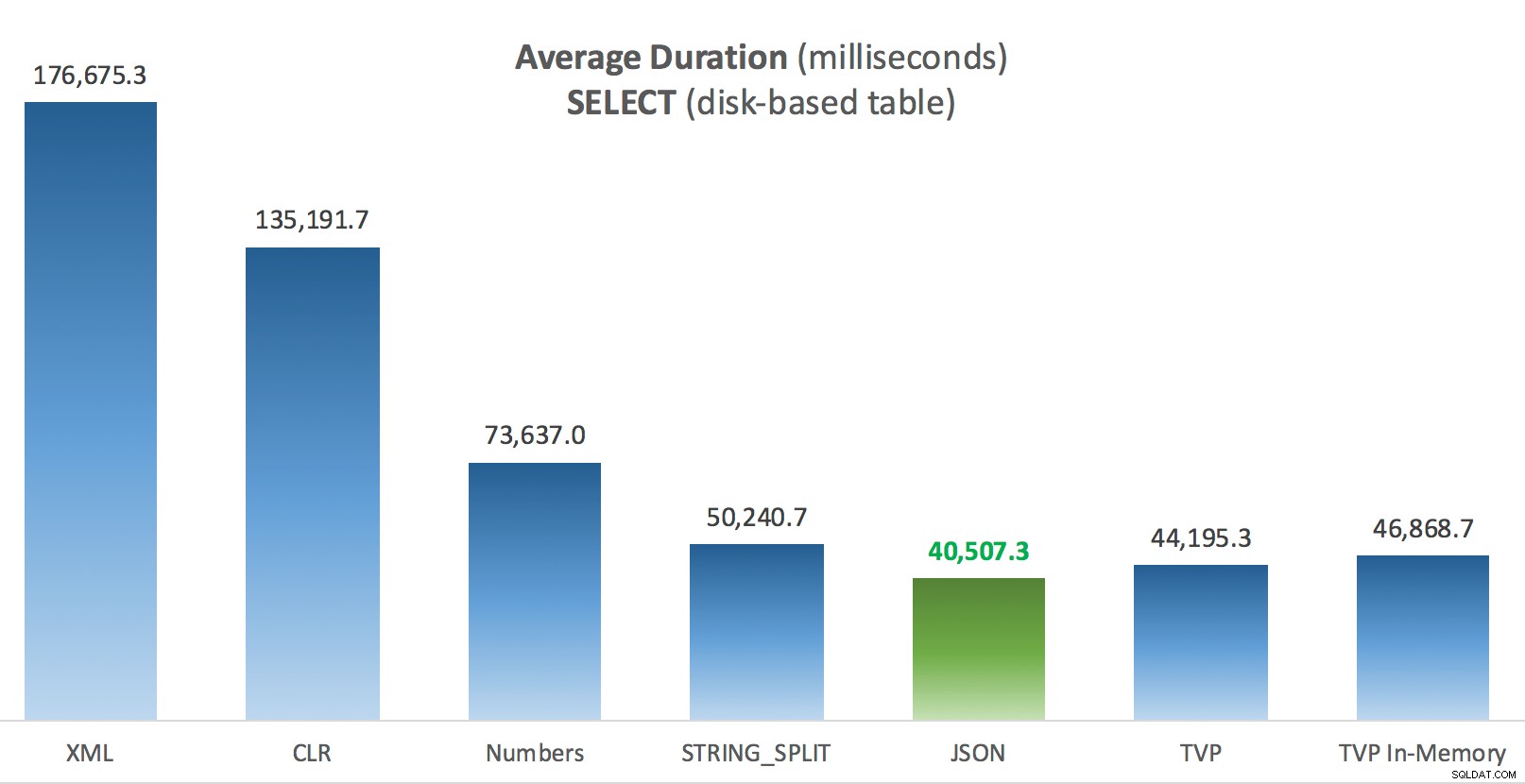 Thời lượng trung bình (mili giây) cho các lệnh CHỌN so với bảng Bài đăng dựa trên đĩa
Thời lượng trung bình (mili giây) cho các lệnh CHỌN so với bảng Bài đăng dựa trên đĩa
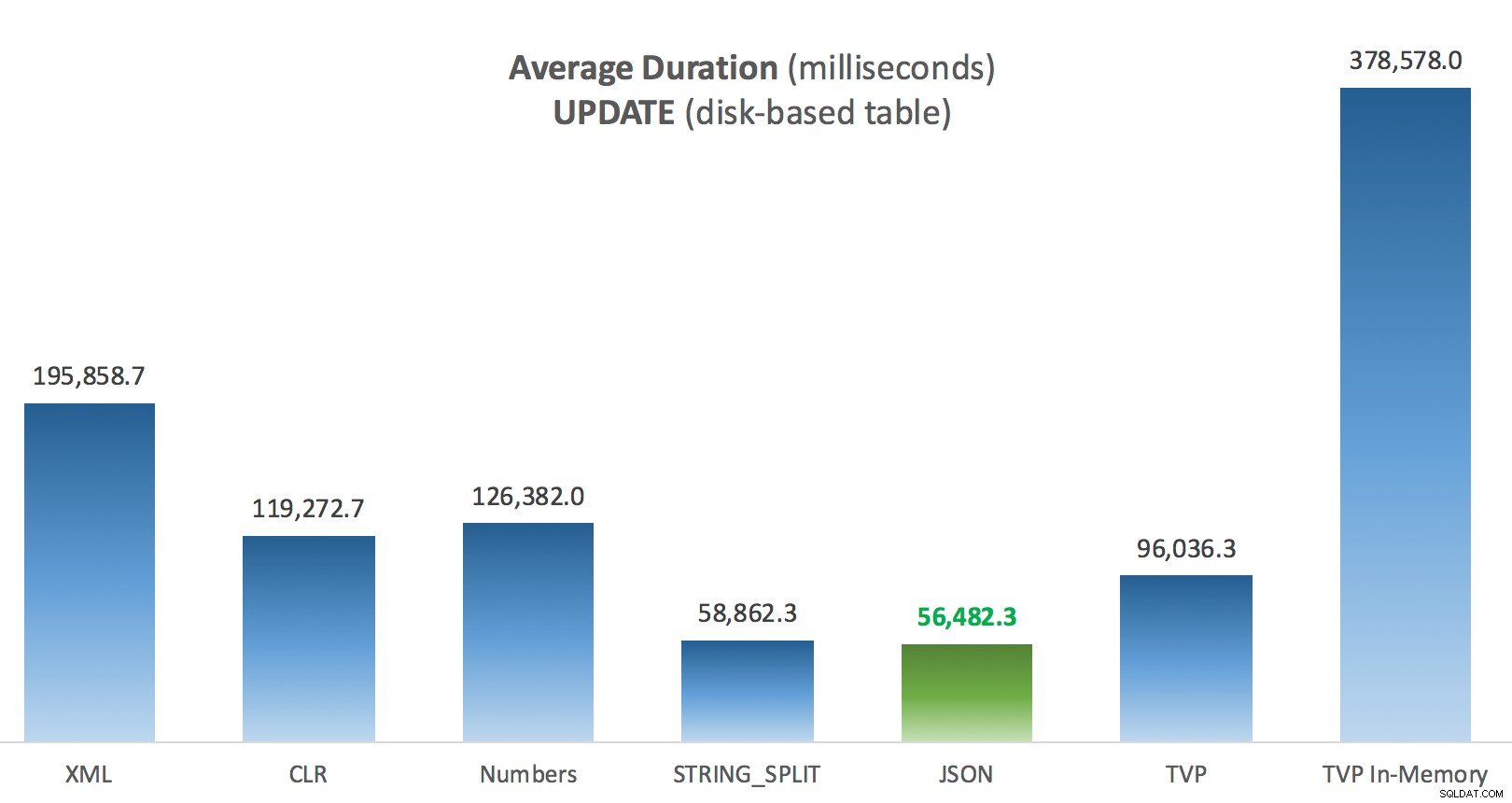 Thời lượng trung bình (mili giây) cho các CẬP NHẬT so với bảng Bài đăng dựa trên đĩa
Thời lượng trung bình (mili giây) cho các CẬP NHẬT so với bảng Bài đăng dựa trên đĩa
Điều thú vị nhất ở đây, đối với tôi, là TVP được tối ưu hóa bộ nhớ kém như thế nào khi hỗ trợ UPDATE . Nó chỉ ra rằng quét song song hiện đang bị chặn quá mạnh khi DML có liên quan; Microsoft đã nhận ra đây là một lỗ hổng về tính năng và họ hy vọng sẽ sớm giải quyết nó. Lưu ý rằng hiện có thể quét song song với SELECT nhưng nó bị chặn đối với DML ngay bây giờ. (Nó sẽ không được giải quyết trong SQL Server 2014, vì các hoạt động quét song song cụ thể này không khả dụng ở đó cho bất kỳ hoạt động nào.) Khi điều đó được khắc phục hoặc khi TVP của bạn nhỏ hơn và / hoặc song song không có lợi, bạn nên xem rằng các TVP được tối ưu hóa bộ nhớ sẽ hoạt động tốt hơn (mô hình này không hoạt động tốt cho trường hợp sử dụng cụ thể này của TVP tương đối lớn).
Đối với trường hợp cụ thể này, đây là các kế hoạch cho SELECT (mà tôi có thể buộc phải thực hiện song song) và UPDATE (mà tôi không thể):
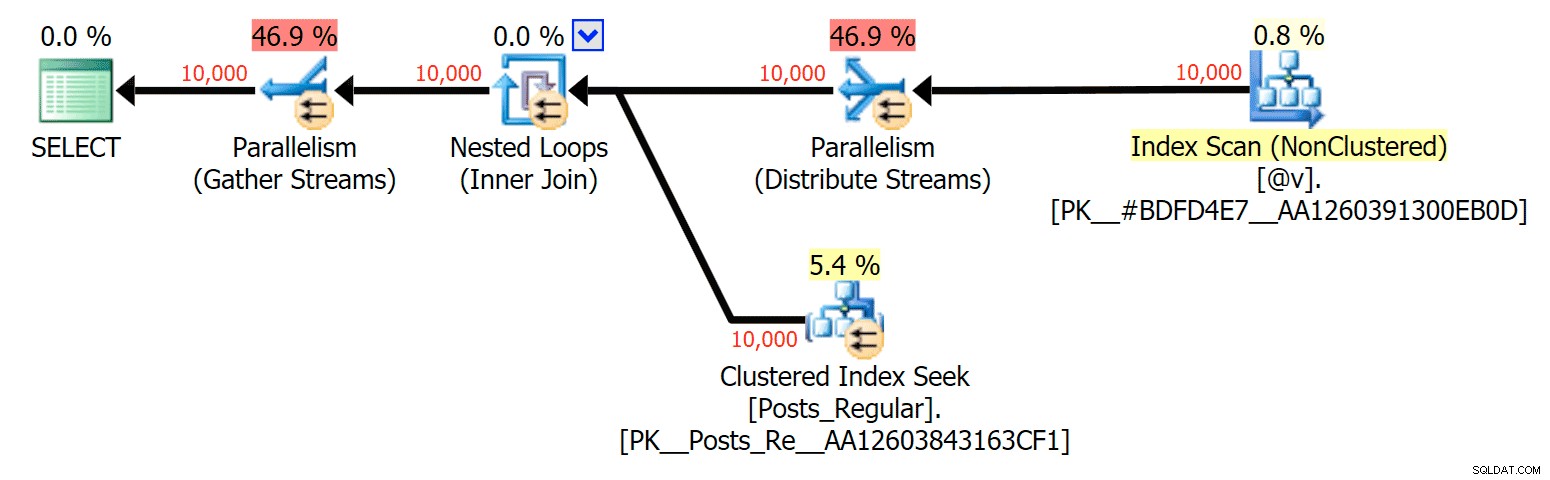 Song song trong kế hoạch CHỌN tham gia bảng dựa trên đĩa vào TVP trong bộ nhớ
Song song trong kế hoạch CHỌN tham gia bảng dựa trên đĩa vào TVP trong bộ nhớ
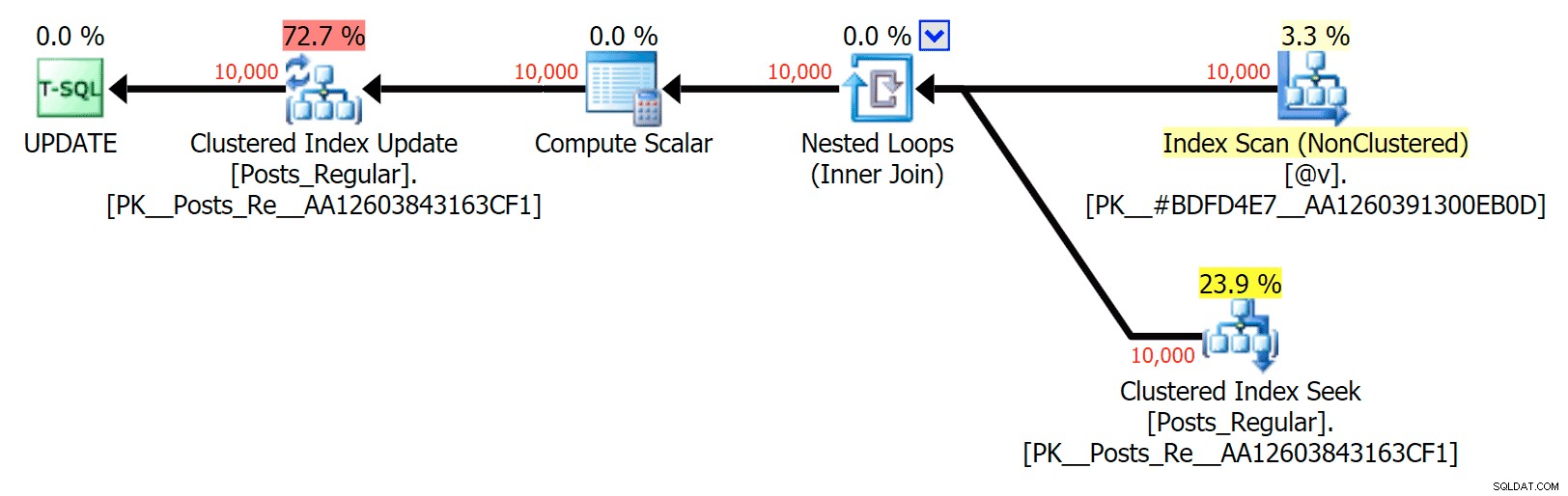 Không có sự song song nào trong gói CẬP NHẬT khi tham gia bảng dựa trên đĩa vào bộ nhớ trong TVP
Không có sự song song nào trong gói CẬP NHẬT khi tham gia bảng dựa trên đĩa vào bộ nhớ trong TVP
Kết quả - Bảng Tối ưu hóa Bộ nhớ
Ở đây nhất quán hơn một chút - bốn phương pháp ở bên phải tương đối đồng đều, trong khi ba phương pháp ở bên trái có vẻ rất không mong muốn ngược lại. Cũng đặc biệt chú ý đến tỷ lệ tuyệt đối so với các bảng dựa trên đĩa - phần lớn, sử dụng các phương pháp giống nhau và thậm chí không song song, bạn sẽ thực hiện các thao tác nhanh hơn nhiều so với các bảng được tối ưu hóa bộ nhớ, dẫn đến mức sử dụng CPU tổng thể thấp hơn.
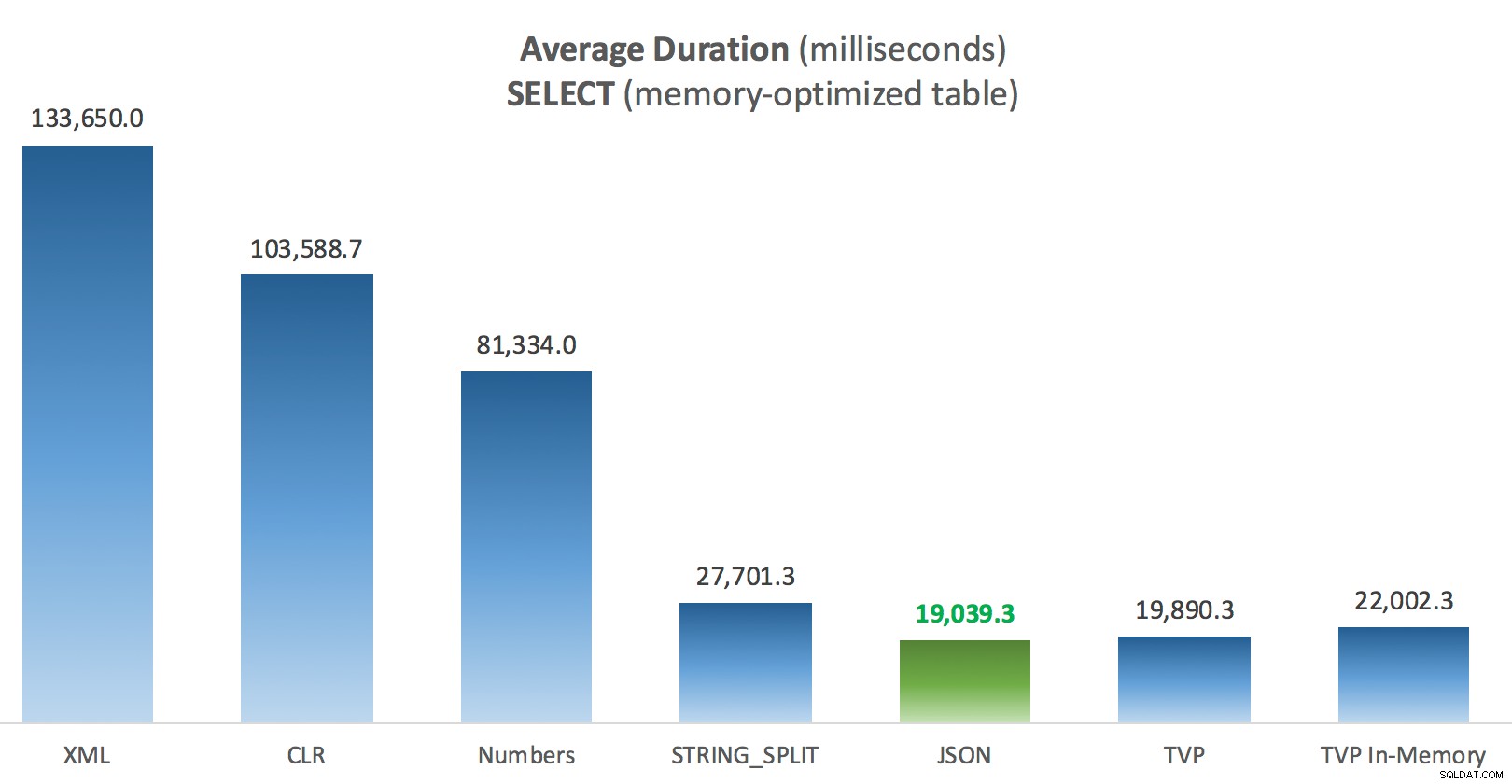 Thời lượng trung bình (mili giây) cho các lệnh CHỌN so với bảng Bài đăng được tối ưu hóa bộ nhớ
Thời lượng trung bình (mili giây) cho các lệnh CHỌN so với bảng Bài đăng được tối ưu hóa bộ nhớ
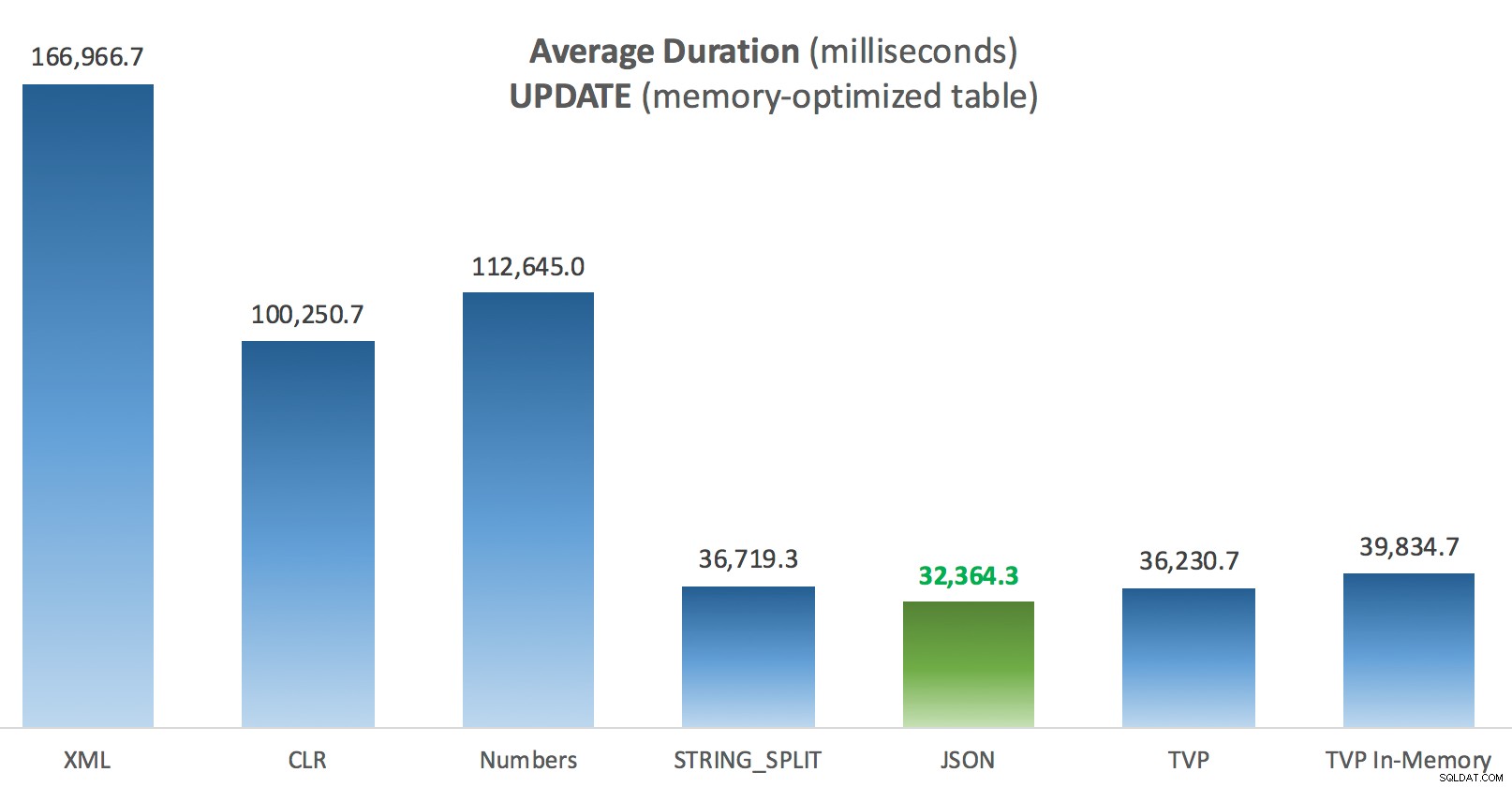 Thời lượng trung bình (mili giây) để CẬP NHẬT so với bảng Bài đăng được tối ưu hóa bộ nhớ
Thời lượng trung bình (mili giây) để CẬP NHẬT so với bảng Bài đăng được tối ưu hóa bộ nhớ
Kết luận
Đối với thử nghiệm cụ thể này, với kích thước dữ liệu, phân phối và số lượng thông số cụ thể và trên phần cứng cụ thể của tôi, JSON là người chiến thắng nhất quán (mặc dù vậy). Tuy nhiên, đối với một số thử nghiệm khác trong các bài viết trước, các cách tiếp cận khác hoạt động tốt hơn. Chỉ là một ví dụ về cách bạn đang làm và nơi bạn đang làm nó có thể có tác động đáng kể đến hiệu quả tương đối của các kỹ thuật khác nhau, đây là những điều tôi đã thử nghiệm trong loạt bài ngắn này, với bản tóm tắt của tôi về kỹ thuật nào để sử dụng trong trường hợp đó và sử dụng làm lựa chọn thứ 2 hoặc thứ 3 (ví dụ:nếu bạn không thể triển khai CLR do chính sách của công ty hoặc do bạn đang sử dụng Cơ sở dữ liệu Azure SQL hoặc bạn không thể sử dụng JSON hoặc STRING_SPLIT() vì bạn chưa sử dụng SQL Server 2016). Lưu ý rằng tôi đã không quay lại và kiểm tra lại phép gán biến và SELECT INTO tập lệnh sử dụng TVP - những thử nghiệm này được thiết lập với giả định rằng bạn đã có dữ liệu hiện có ở định dạng CSV mà trước tiên bạn sẽ phải chia nhỏ dữ liệu này. Nói chung, nếu bạn có thể tránh được điều đó, ngay từ đầu đừng trộn bộ của bạn thành các chuỗi được phân tách bằng dấu phẩy, IMHO.
| Mục tiêu | Lựa chọn đầu tiên | Lựa chọn thứ 2 (và thứ 3, nếu thích hợp) |
|---|---|---|
| Phép gán biến đơn giản | STRING_SPLIT () | CLR nếu <2016 XML nếu không có CLR và <2016 |
| CHỌN VÀO | CLR | XML nếu không có CLR |
| CHỌN VÀO (không có ống) | CLR | Bảng số nếu không có CLR |
| CHỌN VÀO (không có ống + MAXDOP 1) | STRING_SPLIT () | CLR nếu <2016 Bảng số nếu không có CLR và <2016 |
| CHỌN tham gia danh sách lớn (dựa trên đĩa) | JSON (int) | TVP nếu <2016 |
| CHỌN tham gia danh sách lớn (tối ưu hóa bộ nhớ) | JSON (int) | TVP nếu <2016 |
| CẬP NHẬT tham gia danh sách lớn (dựa trên đĩa) | JSON (int) | TVP nếu <2016 |
| CẬP NHẬT tham gia danh sách lớn (tối ưu hóa bộ nhớ) | JSON (int) | TVP nếu <2016 |
Đối với câu hỏi cụ thể của Doug:JSON, STRING_SPLIT() và các TVP thực hiện trung bình khá giống nhau trong các bài kiểm tra này - đủ gần để TVP là lựa chọn hiển nhiên nếu bạn không sử dụng SQL Server 2016. Nếu bạn có các trường hợp sử dụng khác nhau, các kết quả này có thể khác nhau. Rất tuyệt vời .
Điều này đưa chúng ta đến đạo đức của điều này câu chuyện:Tôi và những người khác có thể thực hiện các bài kiểm tra hiệu suất rất cụ thể, xoay quanh bất kỳ tính năng hoặc cách tiếp cận nào và đưa ra kết luận về cách tiếp cận nào là nhanh nhất. Nhưng có rất nhiều biến số, tôi sẽ không bao giờ có đủ tự tin để nói rằng "cách tiếp cận này luôn luôn nhanh nhất. "Trong trường hợp này, tôi đã cố gắng rất nhiều để kiểm soát hầu hết các yếu tố góp phần và mặc dù JSON đã thắng trong cả bốn trường hợp, nhưng bạn có thể thấy các yếu tố khác nhau đó ảnh hưởng như thế nào đến thời gian thực hiện (và mạnh mẽ như vậy đối với một số cách tiếp cận). Vì vậy, nó luôn đáng để bạn xây dựng các bài kiểm tra của riêng bạn và tôi hy vọng tôi đã giúp minh họa cách tôi làm về vấn đề đó.
Phụ lục A:Mã ứng dụng bảng điều khiển
Xin vui lòng, không có ý kiến gì về mã này; nó thực sự được kết hợp với nhau như một cách rất đơn giản để chạy các thủ tục được lưu trữ này 1.000 lần với danh sách true và Bảng dữ liệu được tập hợp trong C # và để ghi lại thời gian mỗi vòng lặp đến một bảng (để đảm bảo bao gồm mọi chi phí liên quan đến ứng dụng với việc xử lý hoặc một chuỗi lớn hoặc một tập hợp). Tôi có thể thêm xử lý lỗi, vòng lặp khác nhau (ví dụ:tạo danh sách bên trong vòng lặp thay vì sử dụng lại một đơn vị công việc), v.v.
using System; using System.Text; using System.Configuration; using System.Data; using System.Data.SqlClient; không gian tên SplitTesting {class Program {static void Main (string [] args) {string operation ="Cập nhật"; if (args [0] .ToString () =="-Select") {operation ="Chọn"; } var csv =new StringBuilder (); Các phần tử DataTable =new DataTable (); Elements.Columns.Add ("giá trị", typeof (int)); for (int i =1; i <=10000; i ++) {csv.Append ((i * 300) .ToString ()); if (i <10000) {csv.Append (","); } element.Rows.Add (i * 300); } string [] method ={"Native", "CLR", "XML", "Numbers", "JSON", "TVP", "TVP_InMemory"}; using (SqlConnection con =new SqlConnection ()) {con.ConnectionString =ConfigurationManager.ConnectionStrings ["primary"]. toString (); con.Open (); SqlParameter p; foreach (string method trong các method) {SqlCommand cmd =new SqlCommand ("dbo." + operation + "Posts_" + method, con); cmd.CommandType =CommandType.StoredProcedure; if (method =="TVP" || method =="TVP_InMemory") {cmd.Parameters.Add ("@ PostList", SqlDbType.Structured) .Value =element; } else {cmd.Parameters.Add ("@ PostList", SqlDbType.VarChar, -1) .Value =csv.ToString (); } var timer =System.Diagnostics.Stopwatch.StartNew (); for (int x =1; x <=1000; x ++) {if (operation =="Cập nhật") {cmd.ExecuteNonQuery (); } else {SqlDataReader rdr =cmd.ExecuteReader (); rdr.Close (); }} timer.Stop (); long this_time =timer.ElapsedMilliseconds; // thời gian ghi nhật ký - thủ tục ghi nhật ký thêm thời gian đồng hồ và // ghi lại bộ nhớ / dựa trên đĩa (được xác định thông qua từ đồng nghĩa) SqlCommand log =new SqlCommand ("dbo.LogBatchTime", con); log.CommandType =CommandType.StoredProcedure; log.Parameters.Add ("@ Hoạt động", SqlDbType.VarChar, 32) .Value =hoạt động; log.Parameters.Add ("@ Phương pháp", SqlDbType.VarChar, 32) .Value =phương thức; log.Parameters.Add ("@ Thời gian", SqlDbType.Int) .Value =this_time; log.ExecuteNonQuery (); Console.WriteLine (method + ":" + this_time.ToString ()); }}}}} Cách sử dụng mẫu:
SplitTesting.exe -ChọnSplitTesting.exe -Cập nhật
Phụ lục B:Chức năng, Thủ tục và Bảng ghi nhật ký
Đây là các hàm được chỉnh sửa để hỗ trợ varchar(max) (hàm CLR đã được chấp nhận nvarchar(max) và tôi vẫn miễn cưỡng cố gắng thay đổi nó):
TẠO CHỨC NĂNG dbo.SplitStrings_Native (@List varchar (max), @Delimiter char (1)) BẢNG TRỞ LẠI VỚI SCHEMABINDINGAS RETURN (CHỌN [giá trị] TỪ STRING_SPLIT (@List, @Delimiter)); ĐI TẠO CHỨC NĂNG dbo.SplitStrings_X (@List varchar (max), @Delimiter char (1)) BẢNG QUAY LẠI VỚI SCHEMABINDINGAS RETURN (SELECT [value] =y.i.value ('(./ text ()) [1]', 'varchar (max)') TỪ (CHỌN x =CHUYỂN ĐỔI (XML, '' + REPLACE (@List, @Delimiter, ' ') + '') .query ('.')) NHƯ a ÁP DỤNG CROSS x.nodes ('i') AS y (i)); ĐI TẠO CHỨC NĂNG dbo.SplitStrings_Numbers (@List varchar (max), @Delimiter char (1)) BẢNG QUAY LẠI VỚI SCHEMABINDINGAS RETURN (SELECT [value] =SUBSTRING (@List, Number, CHARINDEX (@Delimiter, @List + @Delimiter, Number) - Number) TỪ dbo.Numbers WHERE Number <=CONVERT (INT, LEN (@List)) AND SUBSTRING (@Delimiter + @List, Number , LEN (@Delimiter)) =@Delimiter); ĐI TẠO CHỨC NĂNG dbo.SplitStrings_JSON (@List varchar (max), @Delimiter char (1)) BẢNG QUAY LẠI VỚI SCH EMABINDINGAS RETURN (CHỌN [giá trị] TỪ OPENJSON (CHAR (91) + @List + CHAR (93)) VỚI (giá trị int '$')); ĐI Và các thủ tục được lưu trữ trông như thế này:
TẠO THỦ TỤC dbo.UpdatePosts_Native @PostList varchar (max) ASBEGIN UPDATE p SET HitCount + =1 FROM dbo.Posts AS p INNER JOIN dbo.SplitStrings_Native (@PostList, ',') AS s ON p.PostID =s. [value]; ENDGOCREATE PROCEDURE dbo.SelectPosts_Native @PostList varchar (max) ASBEGIN SELECT p.PostID, p.HitCount FROM dbo.Posts AS p INNER JOIN dbo.SplitStrings_Native (@PostList, ',') AS s ON p.PostID =s. [value]; ENDGO-- lặp lại cho 4 phương thức khác dựa trên varchar (max) TẠO QUY TRÌNH Dbo.UpdatePosts_TVP @PostList dbo.PostIDs_Regular READONLY - chuyển _Regular thành _InMemoryASBEGIN ĐẶT SỐ TÀI KHOẢN BẬT; CẬP NHẬT p SET HitCount + =1 FROM dbo.Posts AS p INNER JOIN @PostList AS s ON p.PostID =s.PostID; ENDGOCREATE PROCEDURE dbo.SelectPosts_TVP @PostList dbo.PostIDs_Regular READONLY - switch _Regular to _InMemory ASBEGIN ON; CHỌN p.PostID, p.HitCount TỪ dbo.Posts AS p INNER JOIN @PostList AS s ON p.PostID =s.PostID; ENDGO-- lặp lại cho trong bộ nhớ
Và cuối cùng, bảng ghi nhật ký và quy trình:
CREATE TABLE dbo.SplitLog (LogID int IDENTITY (1,1) PRIMARY KEY, ClockTime datetime NOT NULL DEFAULT GETDATE (), OperatingTable nvarchar (513) NOT NULL, - Posts_InMemory hoặc Posts_Regular Operation varchar (32) NOT NULL DEFAULT 'Cập nhật', - hoặc chọn Phương thức varchar (32) NOT NULL DEFAULT 'Native', - hoặc TVP, JSON, v.v. Định thời int NOT NULL DEFAULT 0); ĐI TẠO QUY TRÌNH dbo.LogBatchTime @Operation varchar (32), @Method varchar (32), @Timing intASBEGIN ĐẶT SỐ TÀI KHOẢN BẬT; INSERT dbo.SplitLog (OperatingTable, Operation, Method, Timing) SELECT base_object_name, @Operation, @Method, @Timing FROM sys.synonyms WHERE name =N'Posts '; ENDGO - và truy vấn để tạo các biểu đồ:; VỚI x AS (SELECT OperatingTable, Operation, Method, Timing, Recency =ROW_NUMBER () OVER (PARTITION BY OperatingTable, Operation, Method ORDER BY ClockTime DESC) FROM dbo.SplitLog) SELECT OperatingTable, Operation, Method, AverageDuration =AVG (1,0 * Timing) FROM x WHERE Lần truy cập gần đây <=3GROUP THEO bảng điều hành, hoạt động, phương pháp;