Tính sẵn có, khả năng truy cập và hiệu suất của dữ liệu là yếu tố quan trọng đối với sự thành công của doanh nghiệp. Điều chỉnh hiệu suất và tối ưu hóa truy vấn SQL là những phương pháp phức tạp, nhưng cần thiết cho các chuyên gia cơ sở dữ liệu. Chúng yêu cầu xem xét các bộ sưu tập dữ liệu khác nhau bằng cách sử dụng các sự kiện mở rộng, hiệu suất, kế hoạch thực thi, thống kê và chỉ mục để đặt tên cho một số. Đôi khi, chủ sở hữu ứng dụng yêu cầu tăng tài nguyên hệ thống (CPU và bộ nhớ) để cải thiện hiệu suất hệ thống. Tuy nhiên, bạn có thể không yêu cầu các tài nguyên bổ sung này và chúng có thể có chi phí liên quan. Đôi khi, tất cả những gì cần thiết là thực hiện các cải tiến nhỏ để thay đổi hành vi truy vấn.
Trong bài viết này, chúng ta sẽ thảo luận một số phương pháp hay nhất về tối ưu hóa truy vấn SQL để áp dụng khi viết truy vấn SQL.
CHỌN * so với CHỌN danh sách cột
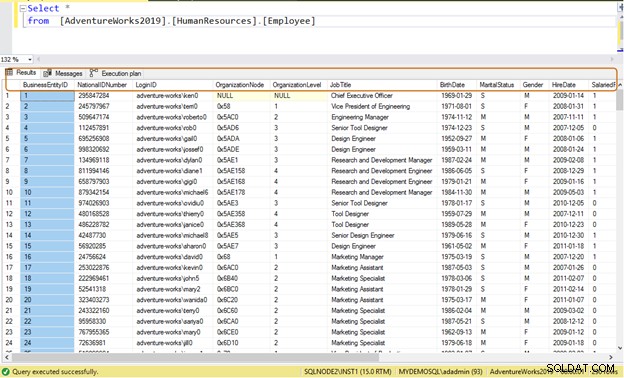
Thông thường, các nhà phát triển sử dụng câu lệnh SELECT * để đọc dữ liệu từ một bảng. Nó đọc tất cả dữ liệu có sẵn của cột trong bảng. Giả sử một bảng [AdventureWorks2019]. [HumanResources]. [Employee] lưu trữ dữ liệu của 290 nhân viên và bạn có yêu cầu truy xuất thông tin sau:
- Số ID quốc gia của nhân viên
- DOB
- Giới tính
- Ngày thuê
Truy vấn không hiệu quả: Nếu bạn sử dụng câu lệnh SELECT *, câu lệnh này sẽ trả về tất cả dữ liệu của cột cho tất cả 290 nhân viên.
Select * from [AdventureWorks2019].[HumanResources].[Employee]
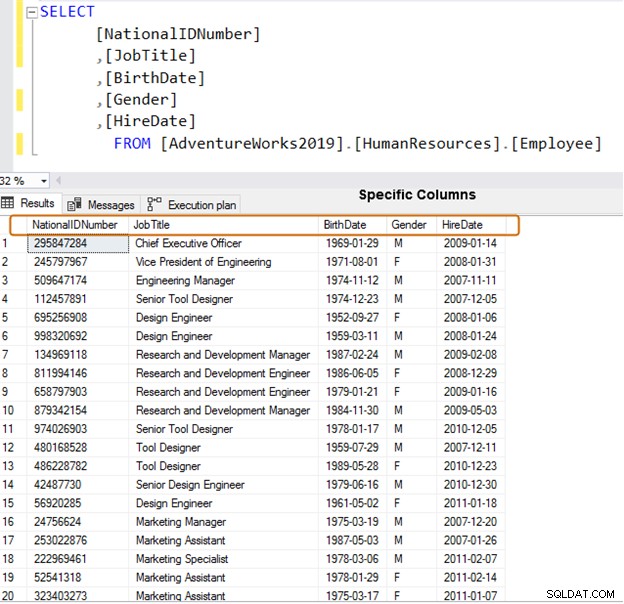
Thay vào đó, hãy sử dụng các tên cột cụ thể để truy xuất dữ liệu.
SELECT [NationalIDNumber] ,[JobTitle] ,[BirthDate] ,[Gender] ,[HireDate] FROM [AdventureWorks2019].[HumanResources].[Employee]
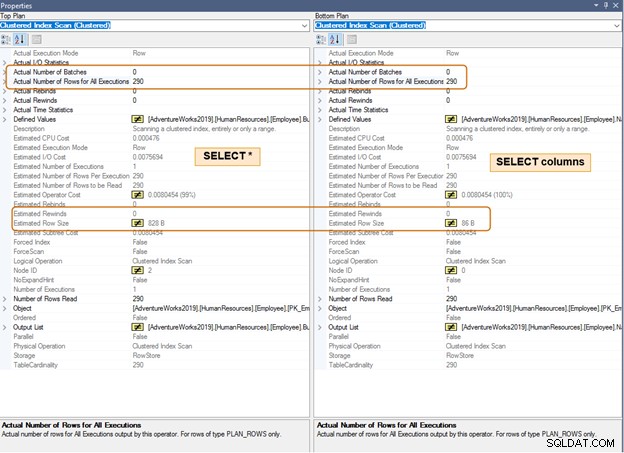
Trong kế hoạch thực thi bên dưới, hãy lưu ý sự khác biệt về kích thước hàng ước tính cho cùng một số hàng. Bạn cũng sẽ nhận thấy sự khác biệt về CPU và IO đối với một số lượng lớn các hàng.
Sử dụng COUNT () so với EXISTS
Giả sử bạn muốn kiểm tra xem một bản ghi cụ thể có tồn tại trong bảng SQL hay không. Thông thường, chúng tôi sử dụng COUNT (*) để kiểm tra bản ghi và nó trả về số lượng bản ghi trong đầu ra.
Tuy nhiên, chúng ta có thể sử dụng hàm IF EXISTS () cho mục đích này. Để so sánh, tôi đã bật thống kê trước khi thực hiện các truy vấn.
Truy vấn cho COUNT ()
SET STATISTICS IO ON Select count(*) from [AdventureWorks2019].[Sales].[SalesOrderDetail] where [SalesOrderDetailID]=44824 SET STATISTICS IO OFF
Truy vấn cho IF EXISTS ()
SET STATISTICS IO ON IF EXISTS(Select [CarrierTrackingNumber] from [AdventureWorks2019].[Sales].[SalesOrderDetail] where [SalesOrderDetailID]=44824) PRINT 'YES' ELSE PRINT 'NO' SET STATISTICS IO OFF
Tôi đã sử dụng phân tích thống kê để phân tích kết quả thống kê của cả hai truy vấn. Nhìn vào kết quả bên dưới. Truy vấn với COUNT (*) có 276 lần đọc logic trong khi IF EXISTS () có 83 lần đọc logic. Bạn thậm chí có thể giảm đáng kể số lần đọc logic với IF EXISTS (). Do đó, bạn nên sử dụng nó để tối ưu hóa các truy vấn SQL để có hiệu suất tốt hơn.

Tránh sử dụng SQL DISTINCT
Bất cứ khi nào chúng ta muốn các bản ghi duy nhất từ truy vấn, chúng ta thường sử dụng mệnh đề SQL DISTINCT. Giả sử bạn đã nối hai bảng với nhau và trong đầu ra, nó trả về các hàng trùng lặp. Cách khắc phục nhanh là chỉ định toán tử DISTINCT loại bỏ hàng trùng lặp.
Hãy xem xét các câu lệnh SELECT đơn giản và so sánh các kế hoạch thực thi. Sự khác biệt duy nhất giữa cả hai truy vấn là toán tử DISTINCT.
SELECT SalesOrderID FROM Sales.SalesOrderDetail Go SELECT DISTINCT SalesOrderID FROM Sales.SalesOrderDetail Go
Với toán tử DISTINCT, chi phí truy vấn là 77%, trong khi truy vấn trước đó (không có DISTINCT) chỉ có chi phí hàng loạt là 23%.
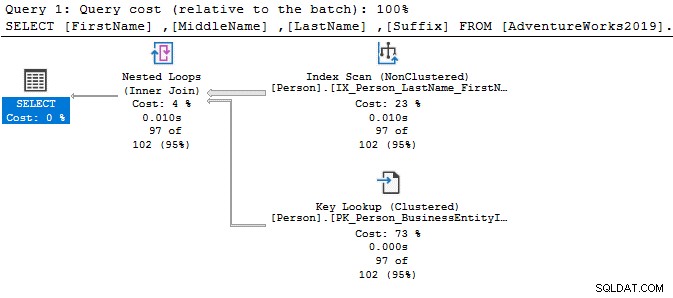
Bạn có thể sử dụng GROUP BY, CTE hoặc truy vấn con để viết mã SQL hiệu quả thay vì sử dụng DISTINCT để nhận các giá trị khác biệt từ tập kết quả. Ngoài ra, bạn có thể truy xuất các cột bổ sung cho một tập kết quả riêng biệt.
SELECT SalesOrderID FROM Sales.SalesOrderDetail Group by SalesOrderID
Cách sử dụng ký tự đại diện trong truy vấn SQL
Giả sử bạn muốn tìm kiếm các bản ghi cụ thể có chứa tên bắt đầu bằng chuỗi được chỉ định. Các nhà phát triển sử dụng ký tự đại diện để tìm kiếm các bản ghi phù hợp.
Trong truy vấn dưới đây, nó tìm kiếm chuỗi Ken trong cột tên. Truy vấn này truy xuất kết quả mong đợi của Ken dra và Ken neth. Tuy nhiên, nó cũng cung cấp kết quả không mong đợi, chẳng hạn như Mac ken zie và N ken ge.
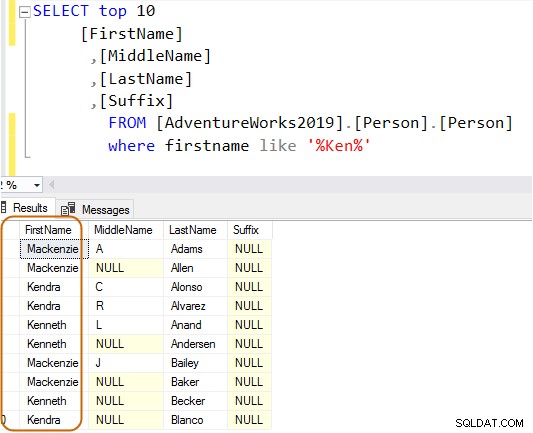
Trong kế hoạch thực thi, bạn sẽ thấy quét chỉ mục và tra cứu khóa cho truy vấn trên.
Bạn có thể tránh kết quả không mong muốn bằng cách sử dụng ký tự đại diện ở cuối chuỗi.
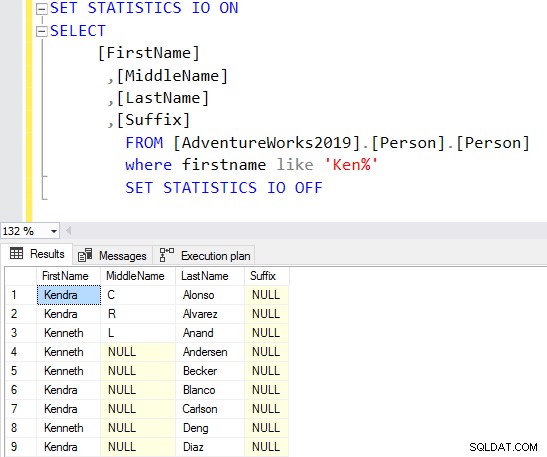
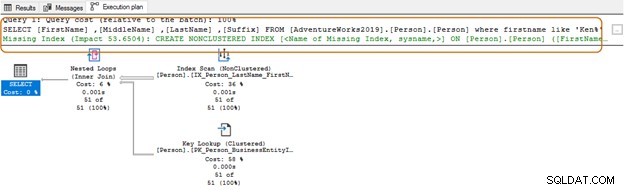
SELECT Top 10 [FirstName] ,[MiddleName] ,[LastName] ,[Suffix] FROM [AdventureWorks2019].[Person].[Person] Where firstname like 'Ken%'
Bây giờ, bạn nhận được kết quả được lọc dựa trên yêu cầu của bạn.
Khi sử dụng ký tự đại diện ở đầu, trình tối ưu hóa truy vấn có thể không sử dụng được chỉ mục phù hợp. Như được hiển thị trong ảnh chụp màn hình bên dưới, với một ký tự đại diện ở cuối, trình tối ưu hóa truy vấn cũng đề xuất một chỉ mục bị thiếu.
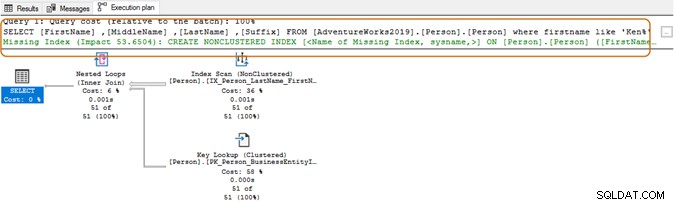
Tại đây, bạn sẽ muốn đánh giá các yêu cầu ứng dụng của mình. Bạn nên cố gắng tránh sử dụng ký tự đại diện trong các chuỗi tìm kiếm, vì nó có thể buộc trình tối ưu hóa truy vấn sử dụng tính năng quét bảng. Nếu bảng quá lớn, nó sẽ yêu cầu tài nguyên hệ thống cao hơn cho IO, CPU và bộ nhớ và có thể gây ra các vấn đề về hiệu suất cho truy vấn SQL của bạn.
Sử dụng mệnh đề WHERE và HAVING
Mệnh đề WHERE và HAVING được sử dụng làm bộ lọc hàng dữ liệu. Mệnh đề WHERE lọc dữ liệu trước khi áp dụng logic nhóm, trong khi mệnh đề HAVING lọc các hàng sau khi tính toán tổng hợp.
Ví dụ:trong truy vấn dưới đây, chúng tôi sử dụng bộ lọc dữ liệu trong mệnh đề HAVING mà không sử dụng mệnh đề WHERE.
Select SalesOrderID, SUM(UnitPrice* OrderQty) as OrderTotal From Sales.salesOrderDetail GROUP BY SalesOrderID HAVING SalesOrderID>30000 and SalesOrderID<55555 and SUM(UnitPrice* OrderQty)>1 Go
Truy vấn sau lọc dữ liệu trước trong mệnh đề WHERE và sau đó sử dụng mệnh đề HAVING cho bộ lọc dữ liệu tổng hợp.
Select SalesOrderID, SUM(UnitPrice* OrderQty) as OrderTotal From Sales.salesOrderDetail where SalesOrderID>30000 and SalesOrderID<55555 GROUP BY SalesOrderID HAVING SUM(UnitPrice* OrderQty)>1000 Go
Tôi khuyên bạn nên sử dụng mệnh đề WHERE để lọc dữ liệu và mệnh đề HAVING cho bộ lọc dữ liệu tổng hợp của bạn như một phương pháp hay nhất.
Cách sử dụng mệnh đề IN và EXISTS
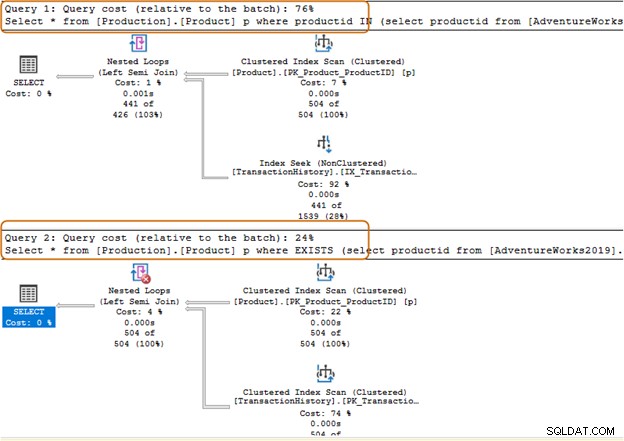
Bạn nên tránh sử dụng mệnh đề IN-operator cho các truy vấn SQL của mình. Ví dụ:trong truy vấn dưới đây, trước tiên, chúng tôi tìm thấy id sản phẩm từ bảng [Sản xuất]. [Giao dịch]) và sau đó tìm kiếm các bản ghi tương ứng trong bảng [Sản xuất]. [Sản phẩm].
Select * from [Production].[Product] p where productid IN (select productid from [AdventureWorks2019].[Production].[TransactionHistory]); Go
Trong truy vấn dưới đây, chúng tôi đã thay thế mệnh đề IN bằng mệnh đề TỒN TẠI.
Select * from [Production].[Product] p where EXISTS (select productid from [AdventureWorks2019].[Production].[TransactionHistory])
Bây giờ, hãy so sánh các thống kê sau khi thực hiện cả hai truy vấn.
Mệnh đề IN sử dụng 504 lần quét, trong khi mệnh đề EXISTS sử dụng 1 lần quét cho bảng [Sản xuất]. [TransactionHistory])].
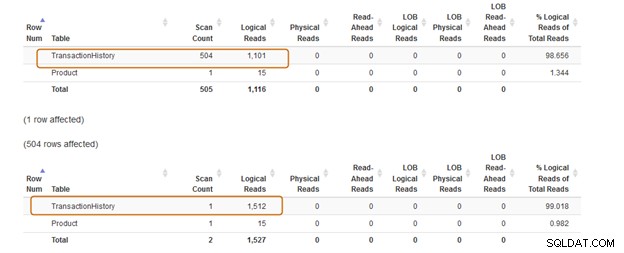
Chi phí lô truy vấn mệnh đề IN là 74%, trong khi chi phí mệnh đề EXISTS là 24%. Do đó, bạn nên tránh mệnh đề IN, đặc biệt nếu truy vấn con trả về một tập dữ liệu lớn.
Thiếu chỉ mục
Đôi khi, khi chúng tôi thực thi một truy vấn SQL và tìm kiếm kế hoạch thực thi thực tế trong SSMS, bạn sẽ nhận được đề xuất về một chỉ mục có thể cải thiện truy vấn SQL của bạn.
Ngoài ra, bạn có thể sử dụng chế độ xem quản lý động để kiểm tra chi tiết về các chỉ mục bị thiếu trong môi trường của bạn.
- sys.dm_db_missing_index_details
- sys.dm_db_missing_index_group_stats
- sys.dm_db_missing_index_groups
- sys.dm_db_missing_index_columns
Thông thường, các DBA làm theo lời khuyên từ SSMS và tạo các chỉ mục. Nó có thể cải thiện hiệu suất truy vấn vào lúc này. Tuy nhiên, bạn không nên tạo chỉ mục trực tiếp dựa trên các khuyến nghị đó. Nó có thể ảnh hưởng đến các hiệu suất truy vấn khác và làm chậm các câu lệnh INSERT và UPDATE của bạn.
- Trước tiên, hãy xem lại các chỉ mục hiện có cho bảng SQL của bạn.
- Lưu ý, lập chỉ mục quá mức và lập chỉ mục thấp đều không tốt cho hiệu suất truy vấn.
- Áp dụng các đề xuất chỉ mục còn thiếu có tác động cao nhất sau khi xem xét các chỉ mục hiện có của bạn và triển khai nó trên môi trường thấp hơn của bạn. Nếu khối lượng công việc của bạn hoạt động tốt sau khi triển khai chỉ mục bị thiếu mới, thì bạn nên thêm i t.
Tôi khuyên bạn nên tham khảo bài viết này để biết các phương pháp hay nhất về lập chỉ mục chi tiết:11 Phương pháp Tốt nhất về Chỉ mục Máy chủ SQL để Điều chỉnh Hiệu suất được Cải thiện.
Gợi ý truy vấn
Các nhà phát triển chỉ định các gợi ý truy vấn một cách rõ ràng trong các câu lệnh t-SQL của họ. Các truy vấn này gợi ý ghi đè hành vi của trình tối ưu hóa truy vấn và buộc nó phải chuẩn bị một kế hoạch thực thi dựa trên gợi ý truy vấn của bạn. Các gợi ý truy vấn thường được sử dụng là NOLOCK, Optimize For và Recompile Merge / Hash / Loop. Chúng là các bản sửa lỗi ngắn hạn cho các truy vấn của bạn. Tuy nhiên, bạn nên phân tích truy vấn, chỉ mục, thống kê và kế hoạch thực thi của mình để có giải pháp lâu dài.
Theo các phương pháp hay nhất, bạn nên giảm thiểu việc sử dụng bất kỳ gợi ý truy vấn nào. Bạn muốn sử dụng gợi ý truy vấn trong truy vấn SQL sau khi lần đầu tiên hiểu ý nghĩa của nó và không sử dụng nó một cách không cần thiết.
Lời nhắc tối ưu hóa truy vấn SQL
Như chúng ta đã thảo luận, tối ưu hóa truy vấn SQL là một con đường mở. Bạn có thể áp dụng các phương pháp hay nhất và các bản sửa lỗi nhỏ có thể cải thiện đáng kể hiệu suất. Hãy xem xét các mẹo sau để phát triển truy vấn tốt hơn:
- Luôn xem xét việc phân bổ tài nguyên hệ thống (đĩa, CPU, bộ nhớ)
- Xem lại cờ theo dõi khởi động, chỉ mục và nhiệm vụ bảo trì cơ sở dữ liệu của bạn
- Phân tích khối lượng công việc của bạn bằng cách sử dụng các sự kiện mở rộng, trình biên dịch hoặc các công cụ giám sát cơ sở dữ liệu của bên thứ ba
- Luôn triển khai bất kỳ giải pháp nào (ngay cả khi bạn tin tưởng 100%) trên môi trường thử nghiệm trước và phân tích tác động của nó; khi bạn hài lòng, hãy lập kế hoạch triển khai sản xuất