Tôi cho rằng lý do là họ không coi đây là một tính năng ưu tiên đáng để triển khai. Có vẻ như Postgres does hỗ trợ cả hai
UNION và UNION ALL .
Nếu bạn có trường hợp mạnh mẽ cho tính năng này, bạn có thể cung cấp phản hồi tại Connect (hoặc bất kỳ URL thay thế của nó sẽ là gì).
Việc ngăn các bản sao được thêm vào có thể hữu ích vì một hàng trùng lặp được thêm vào ở bước sau vào bước trước đó gần như luôn luôn dẫn đến một vòng lặp vô hạn hoặc vượt quá giới hạn đệ quy tối đa.
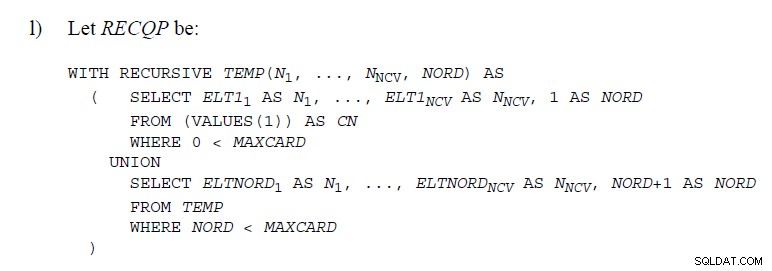
Có một số chỗ trong Tiêu chuẩn SQL
nơi mã được sử dụng thể hiện UNION chẳng hạn như dưới đây
Bài viết này giải thích cách chúng được triển khai trong SQL Server . Họ không làm bất cứ điều gì như thế "dưới mui xe". Bộ đệm ngăn xếp sẽ xóa các hàng khi nó di chuyển để không thể biết liệu hàng sau đó có phải là bản sao của hàng đã xóa hay không. Hỗ trợ UNION sẽ cần một cách tiếp cận hơi khác.
Trong thời gian chờ đợi, bạn có thể dễ dàng đạt được điều tương tự trong TVF nhiều câu lệnh.
Để lấy một ví dụ ngớ ngẩn bên dưới ( Postgres Fiddle )
WITH R
AS (SELECT 0 AS N
UNION
SELECT ( N + 1 )%10
FROM R)
SELECT N
FROM R
Thay đổi UNION tới UNION ALL và thêm DISTINCT cuối cùng sẽ không cứu bạn khỏi đệ quy vô hạn.
Nhưng bạn có thể triển khai điều này với tư cách là
CREATE FUNCTION dbo.F ()
RETURNS @R TABLE(n INT PRIMARY KEY WITH (IGNORE_DUP_KEY = ON))
AS
BEGIN
INSERT INTO @R
VALUES (0); --anchor
WHILE @@ROWCOUNT > 0
BEGIN
INSERT INTO @R
SELECT ( N + 1 )%10
FROM @R
END
RETURN
END
GO
SELECT *
FROM dbo.F ()
Ở trên sử dụng IGNORE_DUP_KEY để loại bỏ các bản sao. Nếu danh sách cột quá rộng để được lập chỉ mục, bạn sẽ cần DISTINCT và NOT EXISTS thay vì. Bạn cũng có thể muốn một tham số để đặt số lần đệ quy tối đa và tránh các vòng lặp vô hạn.