Khám phá kiến trúc của Hadoop, đây là khuôn khổ được chấp nhận nhiều nhất để lưu trữ và xử lý dữ liệu lớn.
Trong bài này, chúng ta cùng tìm hiểu về Kiến trúc Hadoop. Bài viết giải thích kiến trúc Hadoop và các thành phần của kiến trúc Hadoop là HDFS, MapReduce và YARN. Trong bài viết, chúng ta sẽ khám phá kiến trúc Hadoop một cách chi tiết, cùng với sơ đồ Kiến trúc Hadoop.
Bây giờ chúng ta hãy bắt đầu với Kiến trúc Hadoop.
Kiến trúc Hadoop
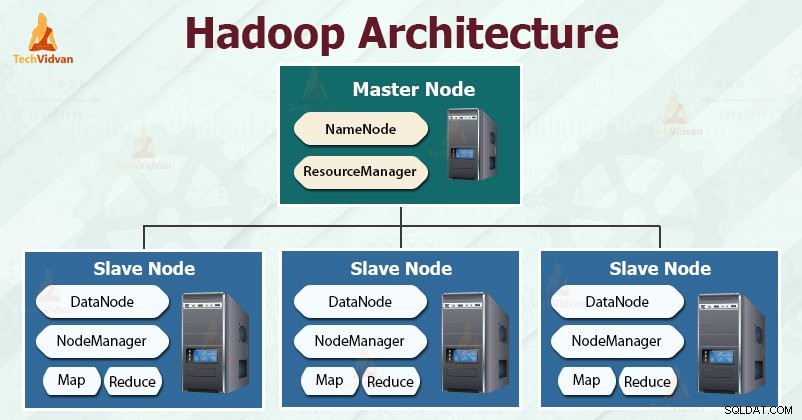
Mục tiêu của việc thiết kế Hadoop là phát triển một khuôn khổ rẻ tiền, đáng tin cậy và có thể mở rộng để lưu trữ và phân tích dữ liệu lớn đang tăng lên.
Apache Hadoop là một khung phần mềm được Apache Software Foundation thiết kế để lưu trữ và xử lý các tập dữ liệu lớn với nhiều kích thước và định dạng khác nhau.
Hadoop tuân theo master-slave kiến trúc để lưu trữ và xử lý một cách hiệu quả lượng lớn dữ liệu. Các nút chính chỉ định nhiệm vụ cho các nút phụ.
Các nút phụ có trách nhiệm lưu trữ dữ liệu thực tế và thực hiện tính toán / xử lý thực tế. Các nút chính chịu trách nhiệm lưu trữ siêu dữ liệu và quản lý tài nguyên trên toàn cụm.
Các nút nô lệ lưu trữ dữ liệu kinh doanh thực tế, trong khi nút chính lưu trữ siêu dữ liệu.
Kiến trúc Hadoop bao gồm ba lớp. Đó là:
- Lớp lưu trữ (HDFS)
- Lớp quản lý tài nguyên (YARN)
- Lớp xử lý (MapReduce)
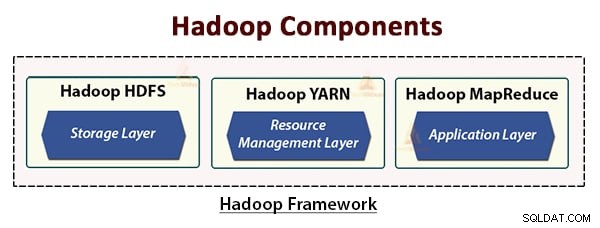
HDFS, YARN và MapReduce là các thành phần cốt lõi của Khung Hadoop.
Bây giờ chúng ta hãy nghiên cứu chi tiết ba thành phần cốt lõi này.
1. HDFS
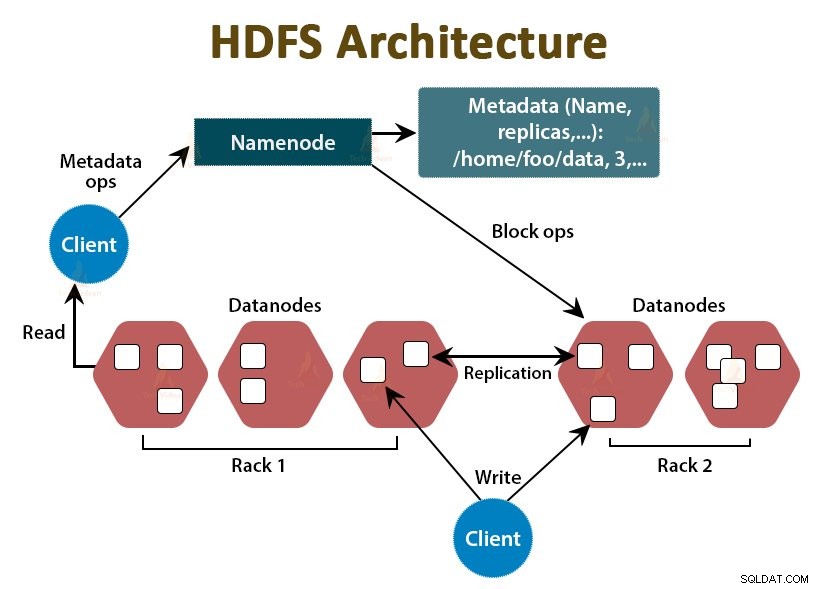
HDFS là Hệ thống tệp phân tán Hadoop , chạy trên phần cứng hàng hóa rẻ tiền. Nó là lớp lưu trữ cho Hadoop. Các tệp trong HDFS được chia thành các khối có kích thước khối được gọi là khối dữ liệu.
Các khối này sau đó được lưu trữ trên các nút nô lệ trong cụm. Kích thước khối là 128 MB theo mặc định, chúng tôi có thể định cấu hình theo yêu cầu của mình.
Giống như Hadoop, HDFS cũng tuân theo kiến trúc chủ-tớ. Nó bao gồm hai daemon- NameNode và DataNode. NameNode là trình nền chính chạy trên nút chính. Các DataNodes là daemon nô lệ chạy trên các nút phụ.
Mã tên
NameNode lưu trữ siêu dữ liệu hệ thống tệp, nghĩa là tên tệp, thông tin về các khối của tệp, vị trí chặn, quyền, v.v. Nó quản lý các Datanodes.
Mã dữ liệu
DataNodes là các nút phụ lưu trữ dữ liệu kinh doanh thực tế. Nó phục vụ các yêu cầu đọc / ghi của khách hàng dựa trên hướng dẫn NameNode.
DataNodes lưu trữ các khối của tệp và NameNode lưu trữ siêu dữ liệu như vị trí khối, quyền, v.v.
2. MapReduce
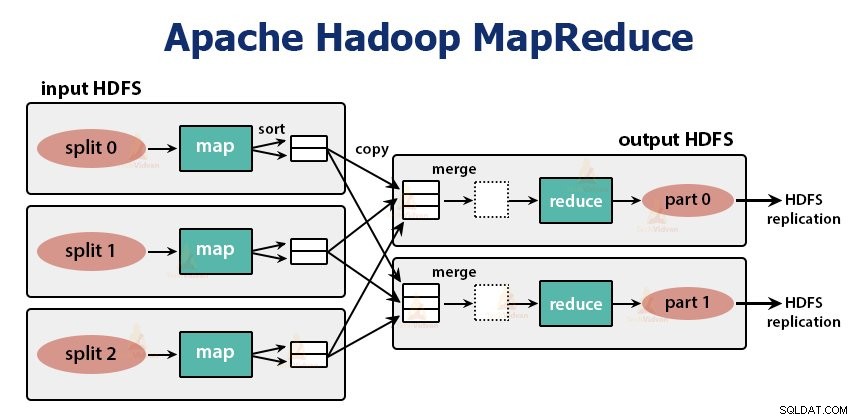
Nó là lớp xử lý dữ liệu của Hadoop. Nó là một khung phần mềm để viết các ứng dụng xử lý một lượng lớn dữ liệu (trong phạm vi từ terabyte đến petabyte) song song trên cụm phần cứng hàng hóa.
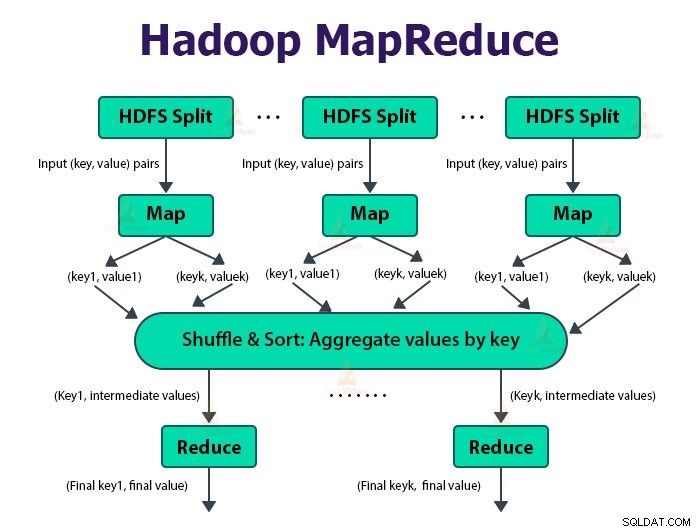
Khung MapReduce hoạt động trên các cặp
Công việc MapReduce là đơn vị công việc mà khách hàng muốn thực hiện. Công việc MapReduce chủ yếu bao gồm dữ liệu đầu vào, chương trình MapReduce và thông tin cấu hình. Hadoop chạy các công việc MapReduce bằng cách chia chúng thành hai loại tác vụ là tác vụ bản đồ và giảm bớt nhiệm vụ . Hadoop YARN đã lên lịch các tác vụ này và được chạy trên các nút trong cụm.
Do một số điều kiện không thuận lợi, nếu nhiệm vụ không thành công, chúng sẽ tự động được lên lịch lại trên một nút khác.
Người dùng xác định chức năng bản đồ và chức năng giảm để thực hiện công việc MapReduce.
Đầu vào cho hàm bản đồ và đầu ra từ hàm giảm là cặp khóa, giá trị.
Chức năng của các tác vụ bản đồ là tải, phân tích cú pháp, lọc và chuyển đổi dữ liệu. Đầu ra của tác vụ bản đồ là đầu vào của tác vụ thu gọn. Giảm tác vụ sau đó thực hiện nhóm và tổng hợp trên đầu ra của tác vụ bản đồ.
Nhiệm vụ MapReduce được thực hiện trong hai giai đoạn-
1. Giai đoạn lập bản đồ
a. RecordReader
Hadoop chia các đầu vào cho công việc MapReduce thành các phần có kích thước cố định được gọi là phần tách đầu vào hoặc chia nhỏ. RecordReader chuyển các phần tách này thành các bản ghi và phân tích cú pháp dữ liệu thành các bản ghi nhưng nó không phân tích cú pháp chính các bản ghi. RecordReader cung cấp dữ liệu cho hàm ánh xạ trong các cặp khóa-giá trị.
b. Bản đồ
Trong giai đoạn bản đồ, Hadoop tạo một tác vụ bản đồ chạy một chức năng do người dùng xác định được gọi là chức năng bản đồ cho mỗi bản ghi trong phần tách đầu vào. Nó tạo ra 0 hoặc nhiều cặp khóa-giá trị trung gian dưới dạng đầu ra tác vụ bản đồ.
Tác vụ bản đồ ghi đầu ra của nó vào đĩa cục bộ. Đầu ra trung gian này sau đó được xử lý bởi các tác vụ giảm chạy chức năng giảm do người dùng xác định để tạo ra đầu ra cuối cùng. Sau khi hoàn thành công việc, đầu ra bản đồ sẽ được xóa.
c á c. Bộ kết hợp
Đầu vào cho tác vụ thu gọn duy nhất là đầu ra từ tất cả các Trình lập bản đồ là đầu ra từ tất cả các tác vụ bản đồ. Hadoop cho phép người dùng xác định một hàm kết hợp chạy trên đầu ra bản đồ.
Bộ kết hợp nhóm dữ liệu trong giai đoạn bản đồ trước khi chuyển dữ liệu đó đến Hộp giảm tốc. Nó kết hợp đầu ra của hàm bản đồ, sau đó được chuyển làm đầu vào cho hàm giảm.
d. Người phân vùng
Khi có nhiều bộ giảm bớt thì các tác vụ bản đồ sẽ phân vùng đầu ra của chúng, mỗi tác vụ sẽ tạo một phân vùng cho mỗi tác vụ giảm. Trong mỗi phân vùng, có thể có nhiều khóa và các giá trị liên quan của chúng nhưng các bản ghi cho bất kỳ khóa nhất định nào đều nằm trong một phân vùng duy nhất.
Hadoop cho phép người dùng kiểm soát việc phân vùng bằng cách chỉ định một chức năng phân vùng do người dùng xác định. Nói chung, có một Trình phân vùng mặc định để sắp xếp các khóa bằng cách sử dụng hàm băm.
2. Giảm giai đoạn:
Các giai đoạn khác nhau của nhiệm vụ giảm như sau:
a. Sắp xếp và trộn:
Nhiệm vụ Hộp giảm tốc bắt đầu với bước xáo trộn và sắp xếp. Mục đích chính của giai đoạn này là thu thập các khóa tương đương với nhau. Giai đoạn Sắp xếp và Ngẫu nhiên tải dữ liệu được trình phân vùng ghi vào nút nơi Công cụ giảm đang chạy.
Nó sắp xếp từng phần dữ liệu thành một danh sách dữ liệu lớn. Khung công tác MapReduce thực hiện sắp xếp này và xáo trộn để chúng ta có thể lặp lại nó một cách dễ dàng trong tác vụ thu gọn.
Sắp xếp và xáo trộn được thực hiện bởi khuôn khổ tự động. Nhà phát triển thông qua đối tượng so sánh có thể có quyền kiểm soát cách các khóa được sắp xếp và nhóm lại.
b. Giảm:
Bộ giảm tốc là chức năng giảm do người dùng xác định thực hiện một lần cho mỗi nhóm phím. Bộ lọc giảm thiểu, tổng hợp và kết hợp dữ liệu theo nhiều cách khác nhau. Sau khi hoàn thành tác vụ rút gọn, nó sẽ cung cấp không hoặc nhiều cặp khóa-giá trị cho OutputFormat. Đầu ra tác vụ giảm được lưu trữ trong Hadoop HDFS.
c á c. Định dạng đầu ra
Nó nhận đầu ra của bộ giảm tốc và ghi nó vào tệp HDFS bằng RecordWriter. Theo mặc định, nó phân tách khóa, giá trị theo tab và mỗi bản ghi bằng một ký tự dòng mới.
3. SỢI
YARN là viết tắt của Yet Another Resource Negotiator . Nó là lớp quản lý tài nguyên của Hadoop. Nó đã được giới thiệu trong Hadoop 2.
YARN được thiết kế với ý tưởng chia tách các chức năng của lập lịch công việc và quản lý tài nguyên thành các daemon riêng biệt. Ý tưởng cơ bản là có một ResourceManager toàn cầu và Ứng dụng Master cho mỗi ứng dụng trong đó ứng dụng có thể là một công việc hoặc DAG của các công việc.
YARN bao gồm ResourceManager, NodeManager và ApplicationMaster cho mỗi ứng dụng.
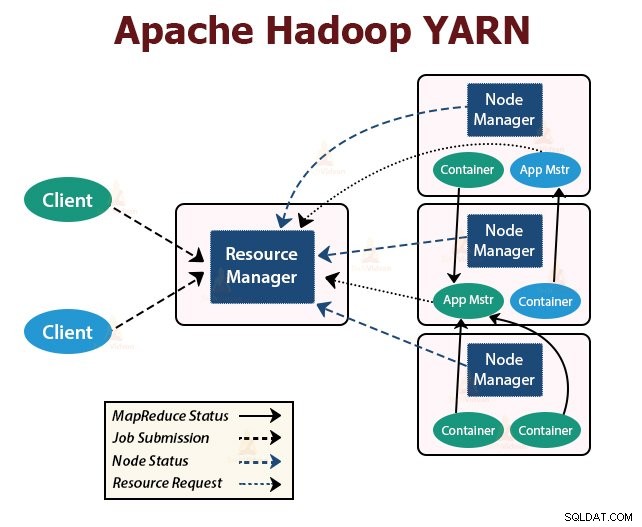
1. ResourceManager
Nó phân xử tài nguyên giữa tất cả các ứng dụng trong cụm.
Nó có hai thành phần chính là Trình lập lịch và Trình quản lý ứng dụng.
a. Người lập lịch
- Bộ lập lịch phân bổ tài nguyên cho các ứng dụng khác nhau đang chạy trong cụm, xem xét dung lượng, hàng đợi, v.v.
- Đây là một Trình lập lịch thuần túy. Nó không giám sát hoặc theo dõi trạng thái của ứng dụng.
- Bộ lập lịch không đảm bảo khởi động lại các tác vụ không thành công do lỗi ứng dụng hoặc lỗi phần cứng.
- Nó thực hiện lập lịch dựa trên các yêu cầu tài nguyên của ứng dụng.
b. ApplicationManager
- Họ có trách nhiệm chấp nhận các công việc được giao.
- ApplicationManager thương lượng vùng chứa đầu tiên để thực thi ApplicationMaster dành riêng cho ứng dụng.
- Họ cung cấp dịch vụ khởi động lại vùng chứa ApplicationMaster nếu không thành công.
- ApplicationMaster cho mỗi ứng dụng chịu trách nhiệm thương lượng các vùng chứa từ Người lập lịch. Nó theo dõi và giám sát trạng thái cũng như tiến trình của họ.
2. NodeManager:
NodeManager chạy trên các nút nô lệ. Nó chịu trách nhiệm về bộ chứa, giám sát việc sử dụng tài nguyên máy là CPU, bộ nhớ, đĩa, việc sử dụng mạng và báo cáo việc sử dụng tương tự cho ResourceManager hoặc Scheduler.
3. ApplicationMaster:
ApplicationMaster cho mỗi ứng dụng là một thư viện dành riêng cho khung. Nó chịu trách nhiệm thương lượng tài nguyên từ ResourceManager. Nó hoạt động với (các) NodeManager để thực thi và giám sát các tác vụ.
Tóm tắt
Trong bài viết này, chúng ta đã cùng nhau tìm hiểu về Kiến trúc Hadoop. Hadoop tuân theo cấu trúc liên kết chủ-tớ. Các nút chủ chỉ định nhiệm vụ cho các nút phụ. Kiến trúc bao gồm ba lớp là HDFS, YARN và MapReduce.
HDFS là hệ thống tệp phân tán trong Hadoop để lưu trữ dữ liệu lớn. MapReduce là khung xử lý để xử lý dữ liệu lớn trong cụm Hadoop theo cách phân tán. YARN chịu trách nhiệm quản lý tài nguyên giữa các ứng dụng trong cụm.
TênNode daemon HDFS và ResourceManager daemon YARN chạy trên nút chính trong cụm Hadoop. HDFS daemon DataNode và YARN NodeManager chạy trên các nút phụ.
Khung HDFS và MapReduce chạy trên cùng một tập hợp các nút, dẫn đến băng thông tổng hợp rất cao trên toàn bộ cụm.
Tiếp tục học tập !!



