Bạn háo hức muốn tìm hiểu từng và mọi thứ về Cụm Hadoop?
Hadoop là một khung phần mềm để phân tích và lưu trữ một lượng lớn dữ liệu trên các cụm phần cứng hàng hóa. Trong bài viết này, chúng ta sẽ nghiên cứu về Cụm Hadoop.
Đầu tiên chúng ta hãy bắt đầu với phần giới thiệu về Cluster.
Cụm là gì?
Một cụm là một tập hợp các nút. Các nút không là gì ngoài một điểm kết nối / giao điểm trong mạng.
Cụm máy tính là một tập hợp các máy tính được kết nối với mạng, có thể giao tiếp với nhau và hoạt động như một hệ thống duy nhất.
Hadoop Cluster là gì?
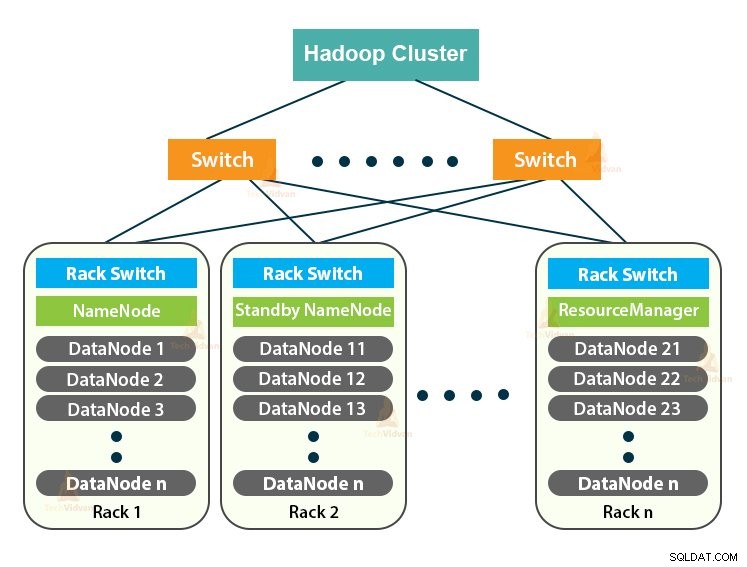
Hadoop Cluster chỉ là một cụm máy tính được sử dụng để xử lý một lượng lớn dữ liệu theo cách phân tán.
Nó là một cụm máy tính được thiết kế để lưu trữ cũng như phân tích một lượng lớn dữ liệu có cấu trúc hoặc phi cấu trúc trong môi trường máy tính phân tán.
Cụm Hadoop còn được gọi là Hệ thống không dùng chung bởi vì không có gì được chia sẻ giữa các nút trong cụm ngoại trừ băng thông mạng. Điều này làm giảm độ trễ xử lý.
Do đó, khi cần xử lý các truy vấn trên một lượng lớn dữ liệu, độ trễ trên toàn cụm sẽ được giảm thiểu.
Bây giờ chúng ta hãy nghiên cứu Kiến trúc của Cụm Hadoop.
Kiến trúc của Cụm Hadoop
Cụm Hadoop tuân theo kiến trúc chủ-tớ. Nó bao gồm nút chính, nút phụ và nút khách.
1. Thành thạo trong Cụm Hadoop
Master in the Hadoop Cluster là một cỗ máy công suất cao với cấu hình bộ nhớ và CPU cao. Hai daemon là NameNode và ResourceManager chạy trên nút chính.
a. Chức năng của NameNode
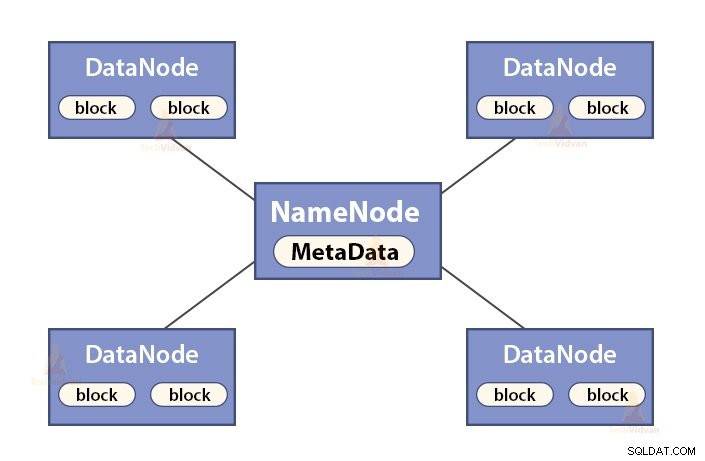
NameNode là một nút chính trong Hadoop HDFS . NameNode quản lý không gian tên hệ thống tệp. Nó lưu trữ siêu dữ liệu hệ thống tập tin trong bộ nhớ để truy xuất nhanh. Do đó, nó phải được định cấu hình trên các máy cao cấp.
Các chức năng của NameNode là:
- Quản lý không gian tên hệ thống tệp
- Lưu trữ siêu dữ liệu về các khối tệp, vị trí chặn, quyền, v.v.
- Nó thực thi các hoạt động của không gian tên hệ thống tệp như mở, đóng, đổi tên tệp và thư mục, v.v.
- Nó duy trì và quản lý DataNode.
b. Chức năng của Trình quản lý tài nguyên
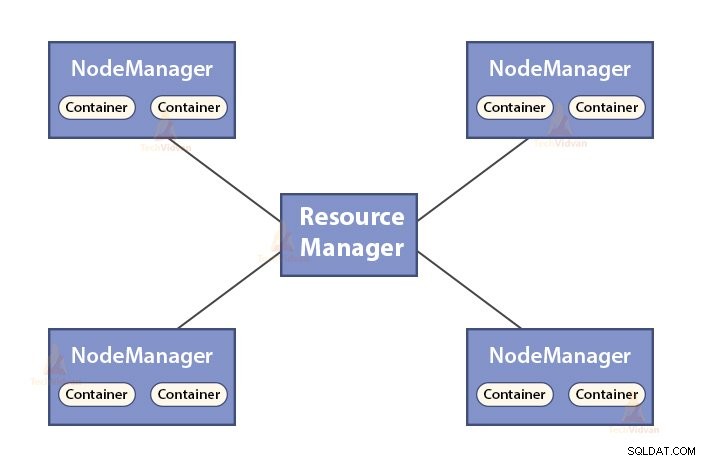
- ResourceManager là daemon chính của YARN.
- ResourceManager sẽ phân xử các tài nguyên giữa tất cả các ứng dụng trong hệ thống.
- Nó theo dõi các nút sống và nút chết trong cụm.
2. Nô lệ trong Cụm Hadoop
Các nô lệ trong Hadoop Cluster là phần cứng hàng hóa rẻ tiền. Hai daemon là DataNodes và YARN NodeManagers chạy trên các nút phụ.
a. Chức năng của DataNodes
- DataNodes lưu trữ dữ liệu kinh doanh thực tế. Nó lưu trữ các khối của một tệp.
- Nó thực hiện tạo khối, xóa, sao chép dựa trên các hướng dẫn từ NameNode.
- DataNode chịu trách nhiệm phục vụ các hoạt động đọc / ghi của ứng dụng khách.
b. Các chức năng của NodeManager
- NodeManager là daemon nô lệ của YARN.
- Nó chịu trách nhiệm về các vùng chứa, giám sát việc sử dụng tài nguyên của chúng (chẳng hạn như CPU, đĩa, bộ nhớ, mạng) và báo cáo điều tương tự cho ResourceManager.
- NodeManager cũng kiểm tra tình trạng của nút mà nó đang chạy.
3. Nút ứng dụng khách trong cụm Hadoop
Các nút máy khách trong Hadoop không phải là nút chính cũng không phải là nút phụ. Họ đã cài đặt Hadoop trên đó với tất cả các cài đặt cụm.
Chức năng của các nút Khách hàng
- Các nút ứng dụng khách tải dữ liệu vào Cụm Hadoop.
- Nó gửi các công việc MapReduce, mô tả cách dữ liệu đó sẽ được xử lý.
- Nhận kết quả của công việc sau khi xử lý xong.
Chúng ta có thể mở rộng Hadoop Cluster bằng cách thêm nhiều nút hơn. Điều này làm cho Hadoop có thể mở rộng tuyến tính . Với mỗi lần bổ sung nút, chúng tôi nhận được sự gia tăng tương ứng về thông lượng. Nếu chúng ta có ‘n’ nút, thì việc thêm 1 nút sẽ mang lại (1 / n) sức mạnh tính toán bổ sung.
Cụm Hadoop một nút VS Cụm Hadoop nhiều nút
1. Cụm Hadoop nút đơn
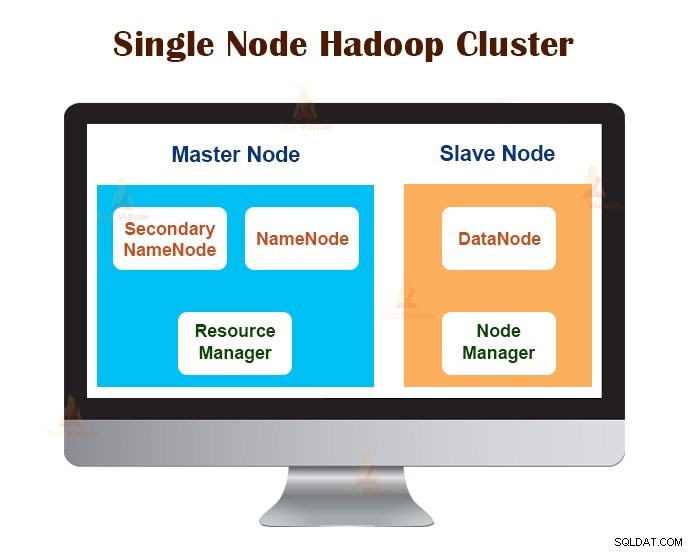
Cụm Hadoop nút đơn được triển khai trên một máy duy nhất. Tất cả các daemon như NameNode, DataNode, ResourceManager, NodeManager đều chạy trên cùng một máy / máy chủ.
Trong thiết lập cụm nút đơn, mọi thứ chạy trên một phiên bản JVM duy nhất. Người dùng Hadoop không phải thực hiện bất kỳ cài đặt cấu hình nào ngoại trừ việc đặt biến JAVA_HOME.
Yếu tố sao chép mặc định cho một cụm Hadoop nút luôn là 1.
2. Cụm Hadoop đa nút
Multi-Node Hadoop Cluster được triển khai trên nhiều máy. Tất cả các daemon trong cụm Hadoop nhiều nút được thiết lập và chạy trên các máy / máy chủ khác nhau.
Một cụm Hadoop nhiều nút tuân theo kiến trúc chủ-tớ. Các daemon Namenode và ResourceManager chạy trên các nút chính, là các máy tính cao cấp.
Các daemon DataNodes và NodeManagers chạy trên các nút phụ (nút công nhân), là phần cứng hàng hóa rẻ tiền.
Trong cụm Hadoop nhiều nút, các máy phụ có thể hiện diện ở bất kỳ vị trí nào bất kể vị trí của vị trí thực của máy chủ chính.
Giao thức Truyền thông được sử dụng trong Cụm Hadoop
Các giao thức truyền thông HDFS được xếp lớp trên cùng của giao thức TCP / IP. Máy khách thiết lập kết nối với NameNode thông qua cổng TCP có thể định cấu hình trên máy NameNode.
Hadoop Cluster thiết lập một kết nối với máy khách thông qua ClientProtocol. Hơn nữa, DataNode nói chuyện với NameNode bằng cách sử dụng DataNode Protocol.
Tóm tắt lệnh gọi thủ tục từ xa (RPC) bao bọc giao thức Client Protocol và DataNode. Theo thiết kế, NameNode không khởi tạo bất kỳ RPC nào. Nó chỉ phản hồi các yêu cầu RPC do máy khách hoặc DataNodes đưa ra.
Các phương pháp hay nhất để xây dựng Cụm Hadoop
Hiệu suất của Hadoop Cluster phụ thuộc vào nhiều yếu tố khác nhau dựa trên tài nguyên phần cứng có kích thước tốt sử dụng CPU, bộ nhớ, băng thông mạng, ổ cứng và các lớp phần mềm được cấu hình tốt khác.
Xây dựng một Hadoop Cluster là một công việc không hề nhỏ. Nó đòi hỏi phải xem xét các yếu tố khác nhau như chọn phần cứng phù hợp, định cỡ các Cụm Hadoop và định cấu hình Cụm Hadoop.
Bây giờ chúng ta hãy xem chi tiết từng cái một.
1. Chọn phần cứng phù hợp cho cụm Hadoop
Nhiều tổ chức, khi thiết lập cơ sở hạ tầng Hadoop, rơi vào tình trạng khó khăn vì họ không biết loại máy họ cần mua để thiết lập môi trường Hadoop được tối ưu hóa và cấu hình lý tưởng mà họ phải sử dụng.
Để chọn phần cứng phù hợp cho Hadoop Cluster, người ta phải xem xét các điểm sau:
- Khối lượng Dữ liệu mà cụm đó sẽ xử lý.
- Loại khối lượng công việc mà cụm sẽ xử lý (ràng buộc CPU, ràng buộc I / O).
- Phương pháp lưu trữ dữ liệu như vùng chứa dữ liệu, kỹ thuật nén dữ liệu được sử dụng, nếu có.
- Chính sách lưu giữ dữ liệu, nghĩa là chúng tôi muốn lưu giữ dữ liệu trong bao lâu trước khi loại bỏ dữ liệu đó.
2. Định kích thước Cụm Hadoop
Để xác định kích thước của Cụm Hadoop, khối lượng dữ liệu mà người dùng Hadoop sẽ xử lý trên Cụm Hadoop phải là một yếu tố quan trọng cần cân nhắc.
Bằng cách biết khối lượng dữ liệu được xử lý, giúp quyết định số lượng nút sẽ được yêu cầu để xử lý dữ liệu hiệu quả và dung lượng bộ nhớ cần thiết cho mỗi nút. Cần có sự cân bằng giữa hiệu suất và chi phí của phần cứng đã được phê duyệt.
3. Định cấu hình Cụm Hadoop
Tìm kiếm cấu hình lý tưởng cho Hadoop Cluster không phải là một công việc dễ dàng. Khung Hadoop phải được điều chỉnh cho phù hợp với cụm nó đang chạy và cả công việc.
Cách tốt nhất để quyết định cấu hình lý tưởng cho Hadoop Cluster là chạy các công việc Hadoop với cấu hình mặc định có sẵn để có được đường cơ sở. Sau đó, chúng tôi có thể phân tích các tệp nhật ký lịch sử công việc để xem liệu có bất kỳ điểm yếu nào về tài nguyên hoặc thời gian thực hiện công việc cao hơn dự kiến hay không.
Nếu đúng như vậy, thì hãy thay đổi cấu hình. Việc lặp lại cùng một quy trình có thể điều chỉnh cấu hình Hadoop Cluster phù hợp nhất với các yêu cầu kinh doanh.
Hiệu suất của Hadoop Cluster phụ thuộc rất nhiều vào tài nguyên được phân bổ cho các daemon. Đối với ngữ cảnh dữ liệu vừa và nhỏ, Hadoop dự trữ một lõi CPU trên mỗi DataNode, trong khi đối với tập dữ liệu dài, nó phân bổ 2 lõi CPU trên mỗi DataNode cho các daemon HDFS và MapReduce.
Quản lý cụm Hadoop
Khi triển khai Cụm Hadoop trong sản xuất, rõ ràng là nó phải mở rộng quy mô theo tất cả các thứ nguyên như khối lượng, sự đa dạng và tốc độ.
Các tính năng khác nhau mà nó nên có để sẵn sàng sản xuất là - tính khả dụng của đồng hồ, mạnh mẽ, khả năng quản lý và hiệu suất. Quản lý cụm Hadoop là khía cạnh chính của sáng kiến dữ liệu lớn.
Công cụ tốt nhất để quản lý Hadoop Cluster phải có các tính năng sau:-
- Nó phải đảm bảo tính khả dụng cao 24 × 7, cung cấp tài nguyên, bảo mật đa dạng, quản lý tải công việc, theo dõi sức khỏe, tối ưu hóa hiệu suất. Ngoài ra, nó cần cung cấp tính năng lập lịch công việc, quản lý chính sách, sao lưu và khôi phục trên một hoặc nhiều nút.
- Triển khai tính khả dụng cao của Mã tên HDFS dự phòng với cân bằng tải, dự phòng nóng, đồng bộ hóa lại và tự động chuyển đổi dự phòng.
- Thực thi các biện pháp kiểm soát dựa trên chính sách để ngăn bất kỳ ứng dụng nào chiếm được phần tài nguyên không cân xứng trên một Cụm Hadoop đã tối đa.
- Thực hiện kiểm tra hồi quy để quản lý việc triển khai bất kỳ lớp phần mềm nào trên các cụm Hadoop. Điều này nhằm đảm bảo rằng mọi công việc hoặc dữ liệu sẽ không gặp sự cố hoặc gặp phải bất kỳ tắc nghẽn nào trong hoạt động hàng ngày.
Lợi ích của Hadoop Cluster
Các lợi ích khác nhau được cung cấp bởi Hadoop Cluster là:
1. Có thể mở rộng
Hadoop Cluster có thể mở rộng. Chúng tôi có thể thêm bất kỳ số lượng nút nào vào Cụm Hadoop mà không cần bất kỳ thời gian chết và không cần thêm bất kỳ nỗ lực nào. Với mỗi lần bổ sung nút, chúng tôi nhận được sự gia tăng tương ứng về thông lượng.
2. Độ bền
Hadoop Cluster được biết đến nhiều nhất với khả năng lưu trữ đáng tin cậy. Nó có thể lưu trữ dữ liệu một cách đáng tin cậy, ngay cả trong các trường hợp như lỗi DataNode, lỗi NameNode và phân vùng mạng. DataNode định kỳ gửi tín hiệu nhịp tim đến NameNode.
Trong phân vùng mạng, một tập hợp các Mã dữ liệu được tách ra khỏi Mã tên do đó Mã tên không nhận được bất kỳ nhịp tim nào từ các Mã dữ liệu này. Sau đó, NameNode coi các DataNode này là đã chết và không chuyển tiếp bất kỳ yêu cầu I / O nào đến chúng.
Ngoài ra, hệ số sao chép của các khối được lưu trữ trong các Mã dữ liệu này giảm xuống dưới giá trị được chỉ định của chúng. Do đó, NameNode sau đó bắt đầu sao chép các khối này và khôi phục sau lỗi.
3. Tái cân bằng cụm
Kiến trúc Hadoop HDFS tự động thực hiện tái cân bằng cụm. Nếu dung lượng trống trong DataNode giảm xuống dưới mức ngưỡng, thì kiến trúc HDFS sẽ tự động di chuyển một số dữ liệu sang DataNode khác khi có đủ dung lượng.
4. Tiết kiệm chi phí
Thiết lập Hadoop Cluster tiết kiệm chi phí vì nó bao gồm phần cứng hàng hóa rẻ tiền. Bất kỳ tổ chức nào cũng có thể dễ dàng thiết lập một Cụm Hadoop mạnh mẽ mà không cần tốn nhiều chi phí cho phần cứng máy chủ đắt tiền.
Ngoài ra, Hadoop Clusters với cấu trúc liên kết lưu trữ phân tán đã khắc phục được những hạn chế của hệ thống truyền thống. Bộ nhớ giới hạn có thể được mở rộng chỉ bằng cách thêm các đơn vị lưu trữ rẻ tiền bổ sung vào hệ thống.
5. Linh hoạt
Hadoop Cluster rất linh hoạt vì chúng có thể xử lý dữ liệu thuộc bất kỳ loại nào, có cấu trúc, bán cấu trúc hoặc không có cấu trúc và có bất kỳ kích thước nào khác nhau, từ Gigabyte đến Petabyte.
6. Xử lý nhanh
Trong Hadoop Cluster, dữ liệu có thể được xử lý song song trong môi trường phân tán. Điều này cung cấp khả năng xử lý dữ liệu nhanh chóng cho Hadoop. Hadoop Cluster có thể xử lý Terabyte hoặc Petabyte dữ liệu trong vòng một phần nhỏ giây.
7. Tính toàn vẹn của dữ liệu
Để kiểm tra bất kỳ lỗi nào trong các khối dữ liệu do phần mềm bị lỗi, lỗi trong thiết bị lưu trữ, v.v. Hadoop Cluster thực hiện tổng kiểm tra trên mỗi khối của tệp. Nếu nó tìm thấy bất kỳ khối nào bị hỏng, nó sẽ tìm kiếm nó tạo thành một Mã dữ liệu khác có chứa bản sao của cùng một khối. Do đó, Cụm Hadoop duy trì tính toàn vẹn của dữ liệu.
Tóm tắt
Sau khi đọc bài viết này, chúng ta có thể nói rằng Hadoop Cluster là một cụm tính toán đặc biệt được thiết kế để phân tích và lưu trữ dữ liệu lớn. Hadoop Cluster tuân theo kiến trúc master-slave.
Nút chính là máy tính cao cấp và các nút phụ là máy có cấu hình CPU và bộ nhớ bình thường. Chúng tôi cũng đã thấy rằng Cụm Hadoop có thể được thiết lập trên một máy duy nhất được gọi là Cụm Hadoop một nút hoặc trên nhiều máy được gọi là Cụm Hadoop nhiều nút.
Trong bài viết này, chúng tôi cũng đã đề cập đến các phương pháp hay nhất cần tuân theo khi xây dựng Cụm Hadoop. Chúng tôi cũng đã thấy nhiều ưu điểm của Hadoop Cluster, bao gồm khả năng mở rộng, tính linh hoạt, hiệu quả về chi phí, v.v.



