Việc quản lý lưu lượng truy cập vào cơ sở dữ liệu có thể ngày càng khó hơn khi nó tăng về số lượng và cơ sở dữ liệu thực sự được phân phối trên nhiều máy chủ. Máy khách PostgreSQL thường nói chuyện với một điểm cuối duy nhất. Khi một nút chính bị lỗi, các máy khách cơ sở dữ liệu sẽ tiếp tục thử lại cùng một IP. Trong trường hợp bạn không truy cập được vào nút phụ, ứng dụng cần được cập nhật với điểm cuối mới. Đây là nơi bạn muốn đặt một bộ cân bằng tải giữa các ứng dụng và các cá thể cơ sở dữ liệu. Nó có thể hướng các ứng dụng đến các nút cơ sở dữ liệu có sẵn / lành mạnh và chuyển đổi dự phòng khi được yêu cầu. Một lợi ích khác là tăng hiệu suất đọc bằng cách sử dụng các bản sao một cách hiệu quả. Có thể tạo một cổng chỉ đọc để cân bằng số lần đọc trên các bản sao. Trong blog này, chúng tôi sẽ đề cập đến HAProxy. Chúng ta sẽ xem nó là gì, nó hoạt động như thế nào và cách triển khai nó cho PostgreSQL.
HAProxy là gì?
HAProxy là một proxy nguồn mở có thể được sử dụng để triển khai tính khả dụng cao, cân bằng tải và ủy quyền cho các ứng dụng dựa trên TCP và HTTP.
Là một bộ cân bằng tải, HAProxy phân phối lưu lượng truy cập từ một điểm gốc đến một hoặc nhiều điểm đến và có thể xác định các quy tắc và / hoặc giao thức cụ thể cho tác vụ này. Nếu bất kỳ điểm đến nào ngừng phản hồi, nó được đánh dấu là ngoại tuyến và lưu lượng truy cập được gửi đến phần còn lại của các điểm đến khả dụng.
Cách cài đặt và định cấu hình HAProxy theo cách thủ công
Để cài đặt HAProxy trên Linux, bạn có thể sử dụng các lệnh sau:
Trên hệ điều hành Ubuntu / Debian:
$ apt-get install haproxy -yTrên hệ điều hành CentOS / RedHat:
$ yum install haproxy -yVà sau đó, chúng tôi cần chỉnh sửa tệp cấu hình sau để quản lý cấu hình HAProxy của chúng tôi:
$ /etc/haproxy/haproxy.cfgĐịnh cấu hình HAProxy của chúng tôi không phức tạp, nhưng chúng tôi cần biết những gì chúng tôi đang làm. Chúng tôi có một số tham số để cấu hình, tùy thuộc vào cách chúng tôi muốn HAProxy hoạt động. Để biết thêm thông tin, chúng tôi có thể làm theo tài liệu về cấu hình HAProxy.
Hãy xem một ví dụ cấu hình cơ bản. Giả sử rằng bạn có cấu trúc liên kết cơ sở dữ liệu sau:
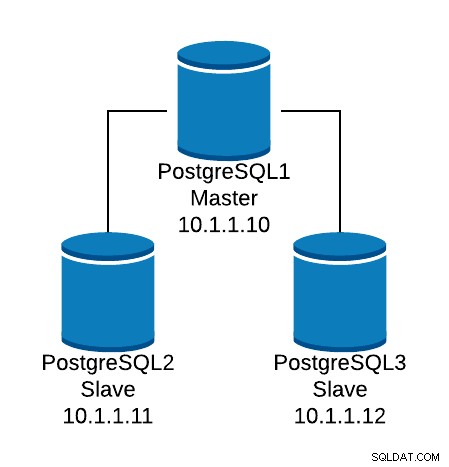 Ví dụ về cấu trúc liên kết cơ sở dữ liệu
Ví dụ về cấu trúc liên kết cơ sở dữ liệu Chúng tôi muốn tạo một trình nghe HAProxy để cân bằng lưu lượng đọc giữa ba nút.
listen haproxy_read
bind *:5434
balance roundrobin
server postgres1 10.1.1.10:5432 check
server postgres2 10.1.1.11:5432 check
server postgres3 10.1.1.12:5432 checkNhư chúng tôi đã đề cập trước đây, có một số tham số để cấu hình ở đây và cấu hình này phụ thuộc vào những gì chúng tôi muốn làm. Ví dụ:
listen haproxy_read
bind *:5434
mode tcp
timeout client 10800s
timeout server 10800s
tcp-check expect string is\ running
balance leastconn
option tcp-check
default-server port 9201 inter 2s downinter 5s rise 3 fall 2 slowstart 60s maxconn 64 maxqueue 128 weight 100
server postgres1 10.1.1.10:5432 check
server postgres2 10.1.1.11:5432 check
server postgres3 10.1.1.12:5432 checkCách HAProxy hoạt động trên ClusterControl
Đối với PostgreSQL, HAProxy được ClusterControl định cấu hình với hai cổng khác nhau theo mặc định, một cổng đọc-ghi và một cổng chỉ đọc.
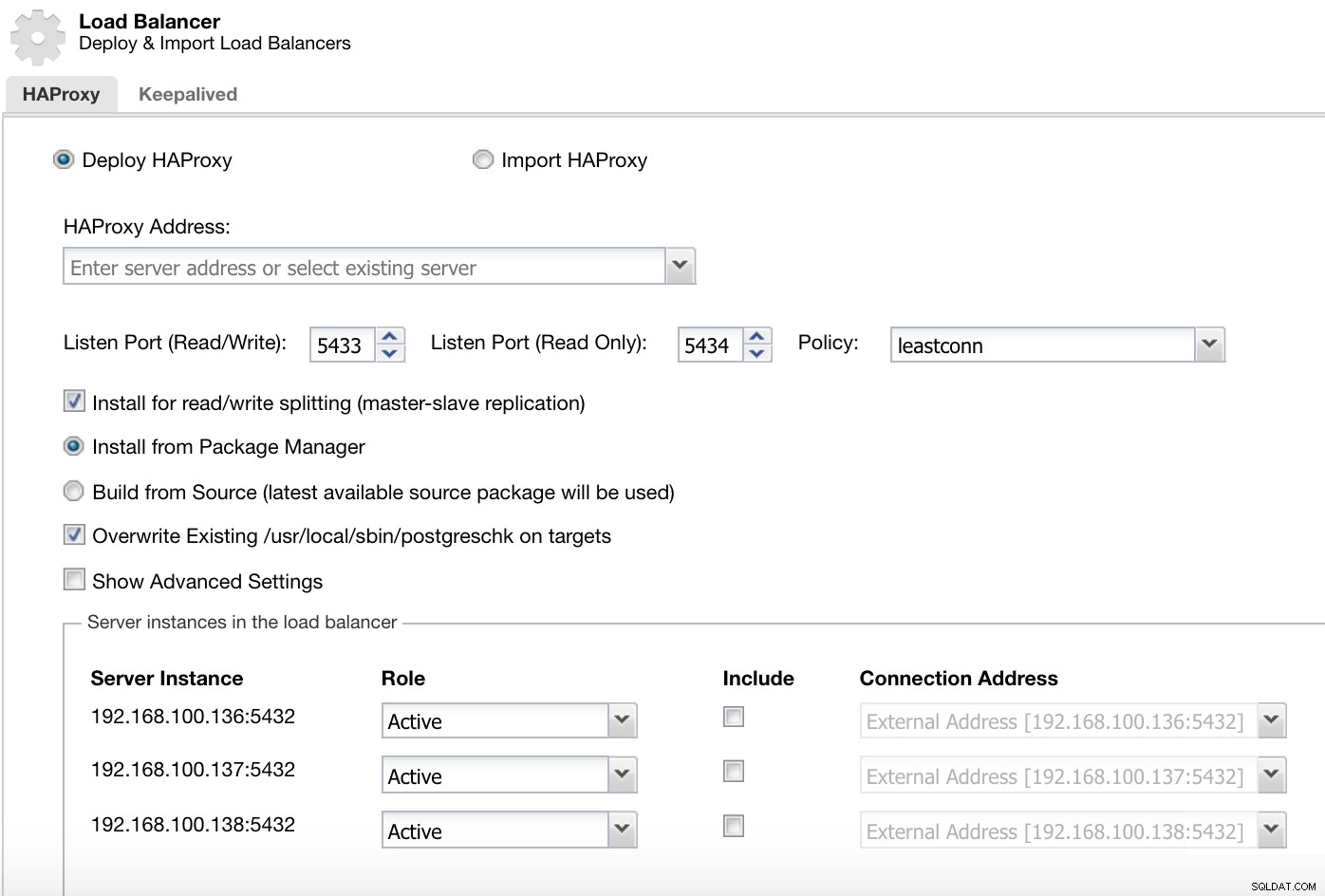 Thông tin triển khai ClusterControl Load Balancer 1
Thông tin triển khai ClusterControl Load Balancer 1 Trong cổng đọc-ghi của chúng tôi, chúng tôi có máy chủ chính của chúng tôi trực tuyến và các nút còn lại của chúng tôi là ngoại tuyến và trong cổng chỉ đọc, chúng tôi có cả máy chủ và nô lệ trực tuyến.
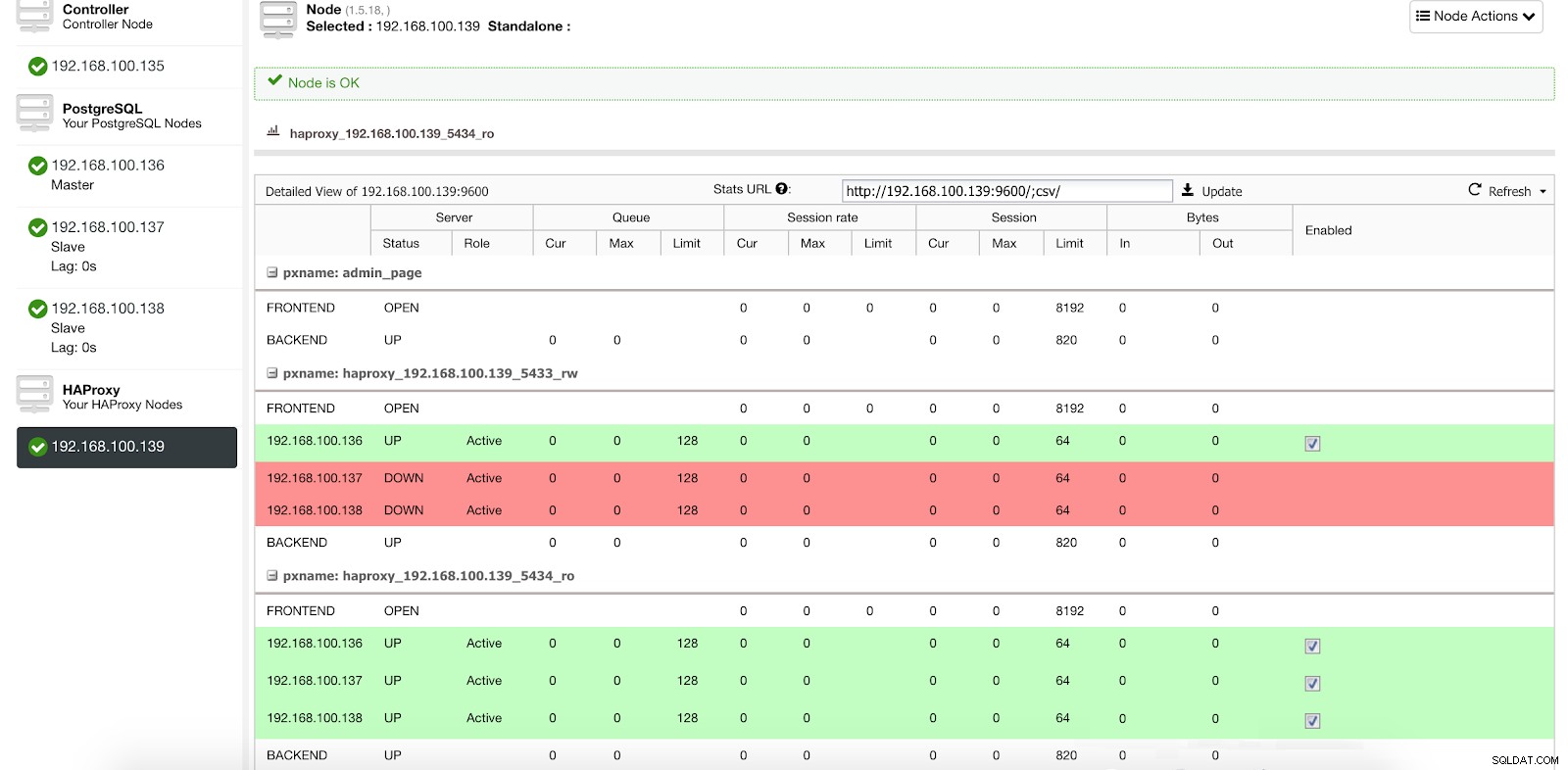 Số liệu thống kê về bộ cân bằng tải ClusterControl 1
Số liệu thống kê về bộ cân bằng tải ClusterControl 1 Khi HAProxy phát hiện không thể truy cập được một trong các nút của chúng ta, cả nút chính hoặc nút phụ, nó sẽ tự động đánh dấu nút đó là ngoại tuyến và không tính đến nút đó khi gửi lưu lượng truy cập. Việc phát hiện được thực hiện bởi các tập lệnh kiểm tra sức khỏe được cấu hình bởi ClusterControl tại thời điểm triển khai. Những điều này sẽ kiểm tra xem các phiên bản đã hoạt động chưa, chúng đang trong quá trình khôi phục hay ở chế độ chỉ đọc.
Khi ClusterControl thúc đẩy một nô lệ để làm chủ, HAProxy của chúng tôi đánh dấu trang chủ cũ là ngoại tuyến (cho cả hai cổng) và đặt nút được quảng bá trực tuyến (trong cổng đọc-ghi).
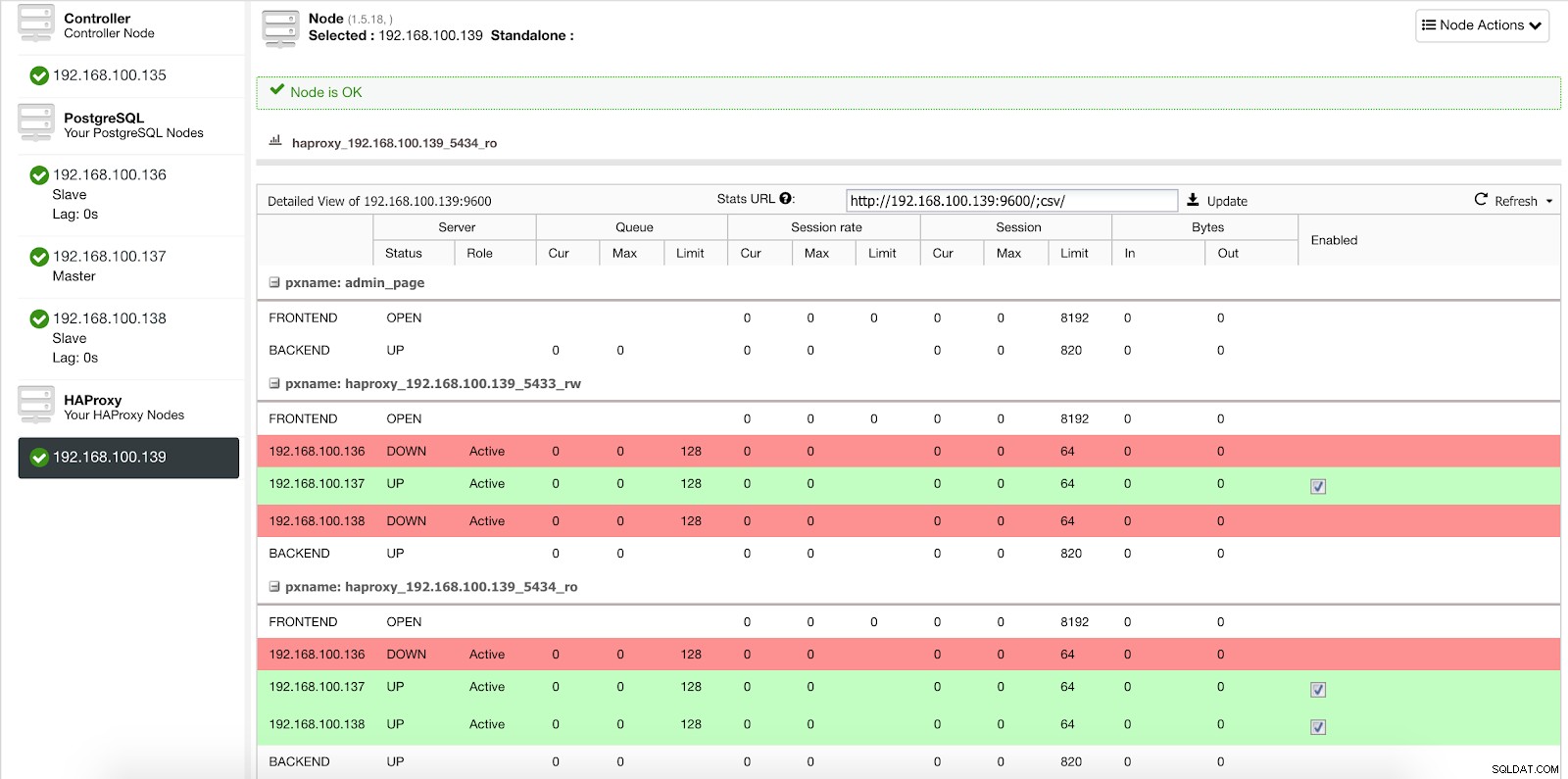 Số liệu thống kê về bộ cân bằng tải ClusterControl 2
Số liệu thống kê về bộ cân bằng tải ClusterControl 2 Bằng cách này, hệ thống của chúng tôi tiếp tục hoạt động bình thường và không có sự can thiệp của chúng tôi.
Cách triển khai HAProxy với ClusterControl
Trong ví dụ của chúng tôi, chúng tôi đã tạo một môi trường với 1 chủ và 2 nô lệ - hãy xem ảnh chụp màn hình của Chế độ xem cấu trúc liên kết trong ClusterControl. Bây giờ chúng tôi sẽ thêm bộ cân bằng tải HAProxy của chúng tôi.
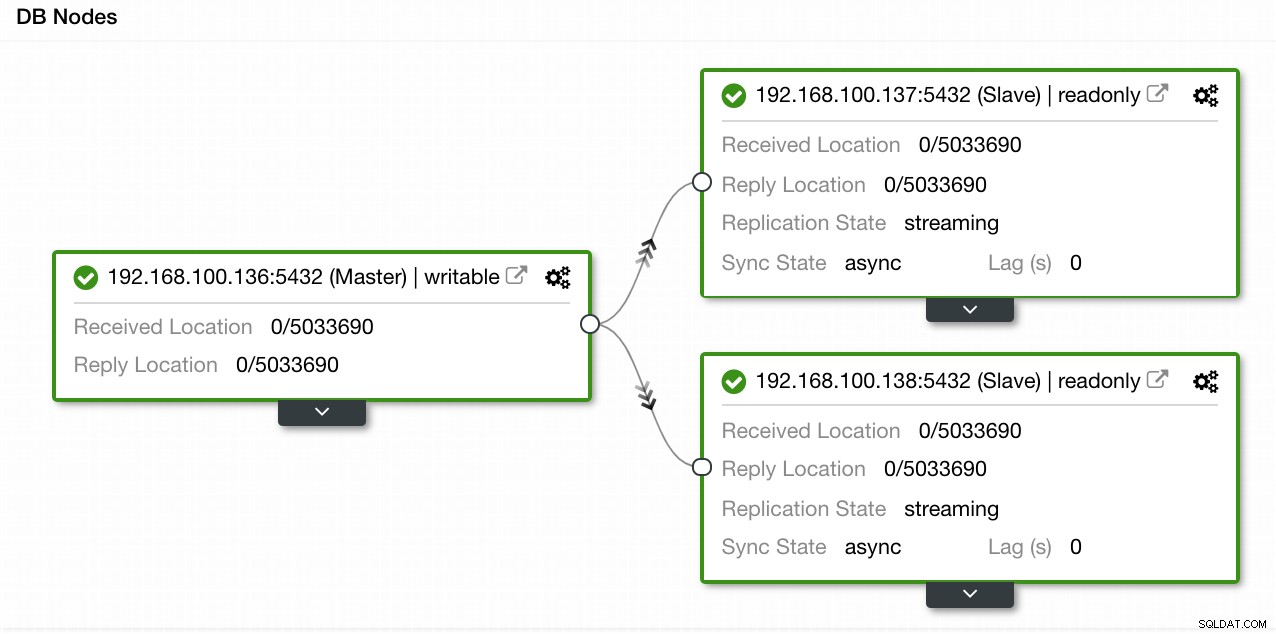 Chế độ xem cấu trúc liên kết ClusterControl 1
Chế độ xem cấu trúc liên kết ClusterControl 1 Đối với tác vụ này, chúng ta cần đi tới ClusterControl -> PostgreSQL Cluster Actions -> Thêm Load Balancer
 Trình đơn tác vụ cụm ClusterControl
Trình đơn tác vụ cụm ClusterControl Tại đây, chúng tôi phải thêm thông tin mà ClusterControl sẽ sử dụng để cài đặt và định cấu hình bộ cân bằng tải HAProxy của chúng tôi.
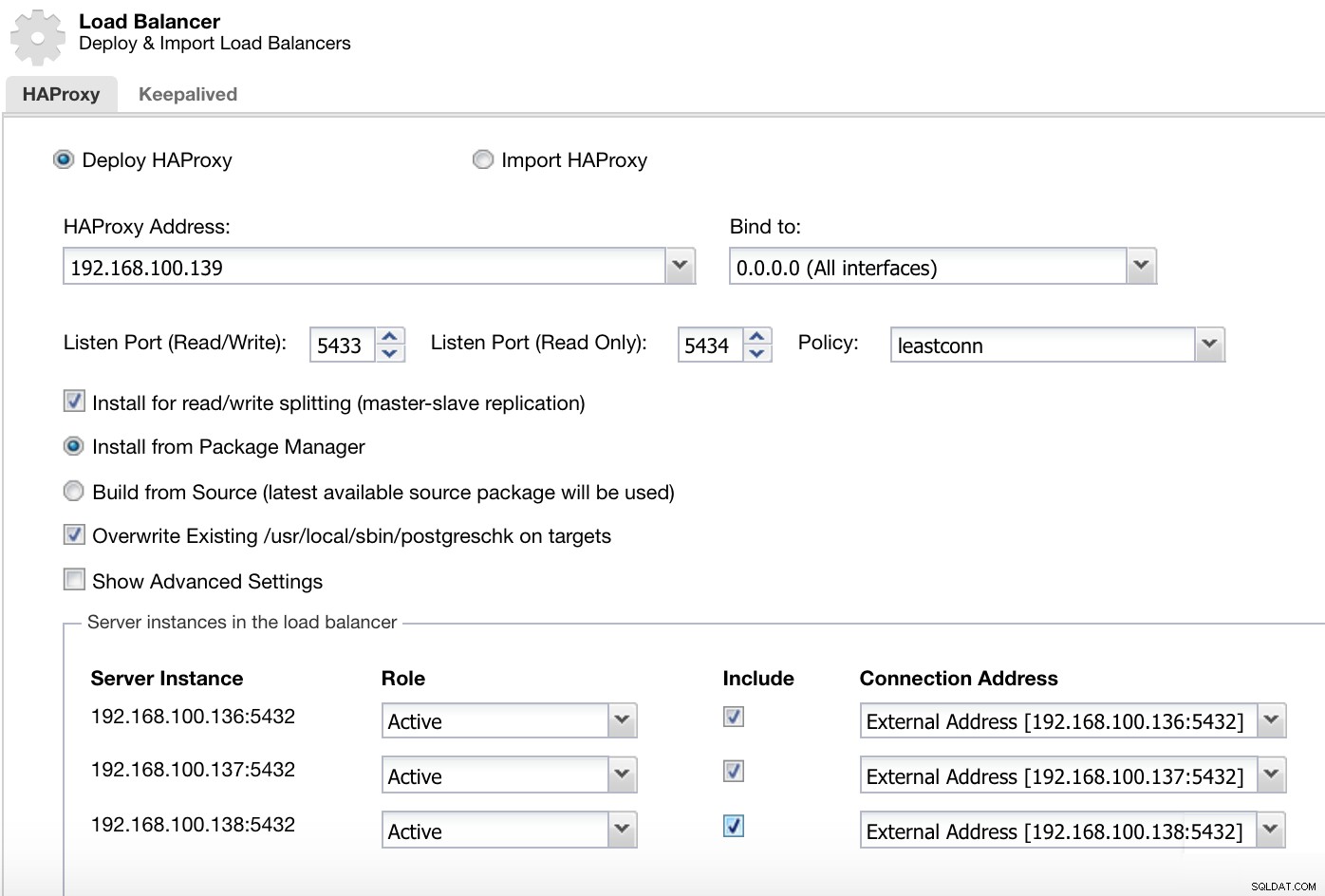 Thông tin triển khai ClusterControl Load Balancer 2
Thông tin triển khai ClusterControl Load Balancer 2 Thông tin mà chúng tôi cần giới thiệu là:
Hành động:Triển khai hoặc Nhập.
Địa chỉ HAProxy:Địa chỉ IP cho máy chủ HAProxy của chúng tôi.
Liên kết với:Giao diện hoặc Địa chỉ IP nơi HAProxy sẽ lắng nghe.
Cổng Nghe (Đọc / Ghi):Cổng dành cho chế độ đọc / ghi.
Cổng nghe (Chỉ đọc):Cổng dành cho chế độ chỉ đọc.
Chính sách:Có thể là:
- lessconn:Máy chủ có số lượng kết nối thấp nhất nhận được kết nối.
- roundrobin:Mỗi máy chủ được sử dụng lần lượt tùy theo trọng lượng của chúng.
- source:Địa chỉ IP nguồn được băm và chia cho tổng trọng lượng của các máy chủ đang chạy để chỉ định máy chủ nào sẽ nhận được yêu cầu.
Cài đặt để tách đọc / ghi:Để sao chép master-slave.
Nguồn:Chúng tôi có thể chọn Cài đặt từ trình quản lý gói hoặc xây dựng từ nguồn.
Ghi đè postgreschk hiện có lên các mục tiêu.
Và chúng tôi cần chọn máy chủ nào bạn muốn thêm vào cấu hình HAProxy và một số thông tin bổ sung như:
Vai trò:Nó có thể Hoạt động hoặc Dự phòng.
Bao gồm:Có hoặc Không.
Thông tin địa chỉ kết nối.
Ngoài ra, chúng tôi có thể định cấu hình Cài đặt nâng cao như Người dùng quản trị, Tên phụ trợ, Thời gian chờ và hơn thế nữa.
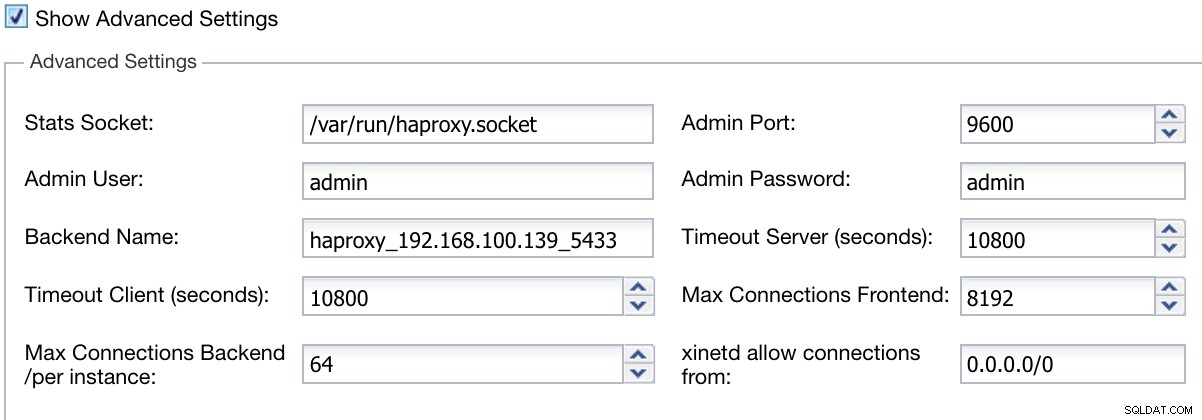 Thông tin triển khai ClusterControl Load Balancer Nâng cao
Thông tin triển khai ClusterControl Load Balancer Nâng cao Khi bạn hoàn tất cấu hình và xác nhận việc triển khai, chúng tôi có thể theo dõi tiến trình trong phần Hoạt động trên giao diện người dùng ClusterControl.
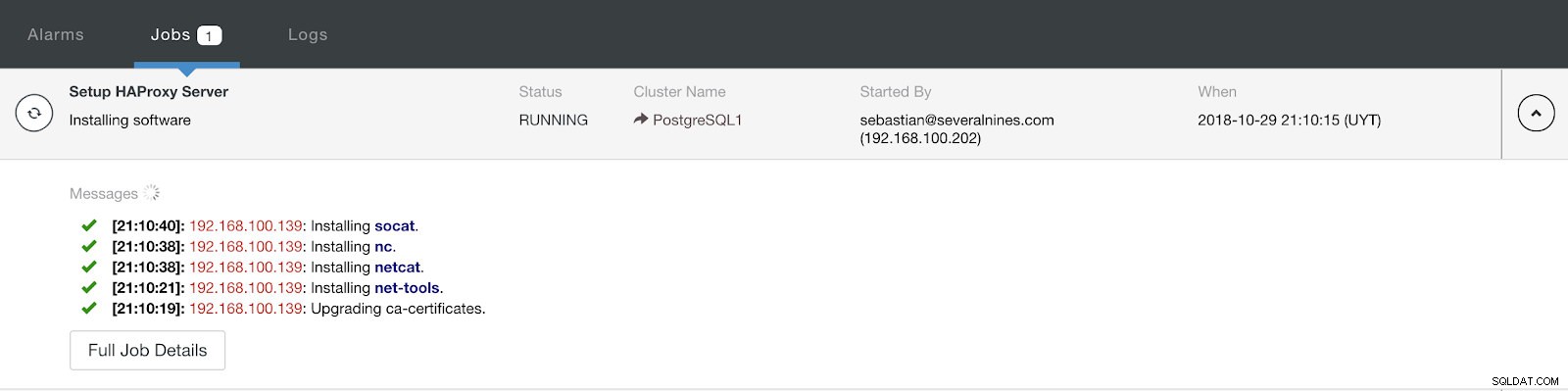 Phần hoạt động ClusterControl
Phần hoạt động ClusterControl Khi hoàn tất, chúng ta sẽ có cấu trúc liên kết sau:
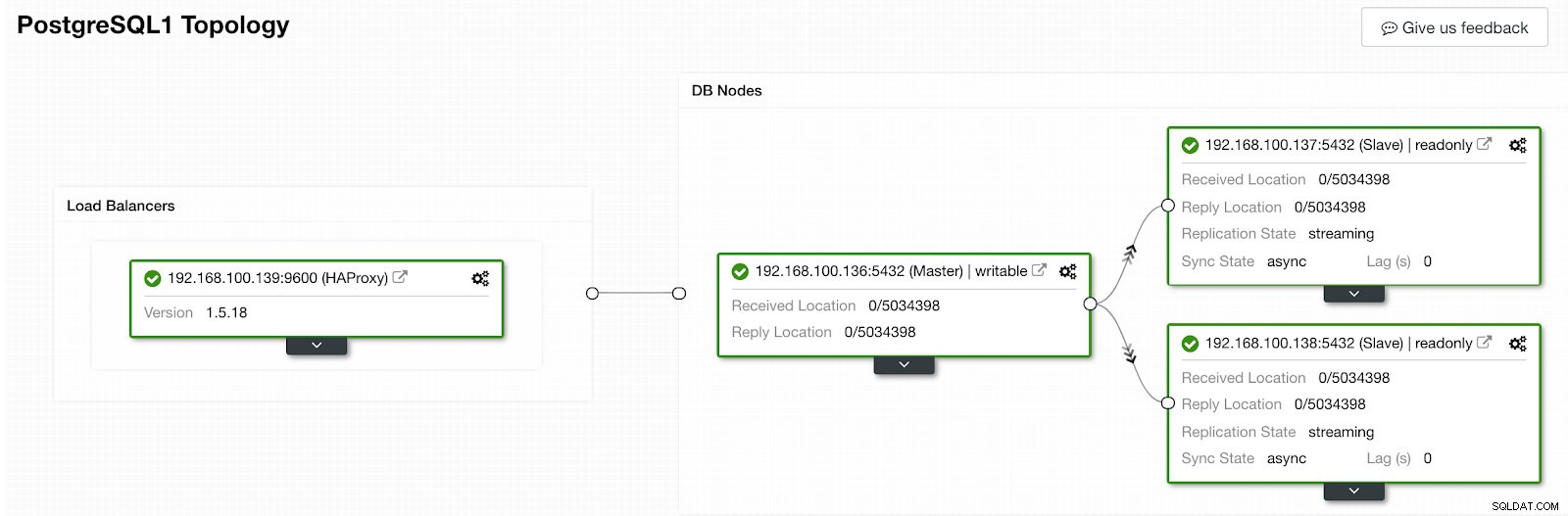 Chế độ xem cấu trúc liên kết ClusterControl 2
Chế độ xem cấu trúc liên kết ClusterControl 2 Chúng tôi có thể cải thiện thiết kế HA của mình bằng cách thêm một nút HAProxy mới và định cấu hình dịch vụ Keepalived giữa chúng. Tất cả điều này có thể được thực hiện bởi ClusterControl. Để biết thêm thông tin, bạn có thể kiểm tra blog trước đây của chúng tôi về PostgreSQL và HA.
Sử dụng ClusterControl CLI để thêm Bộ cân bằng tải HAProxy
Còn được gọi là s9s-tools, gói tùy chọn này đã được giới thiệu trong ClusterControl phiên bản 1.4.1, chứa một tệp nhị phân được gọi là s9s. Nó là một công cụ dòng lệnh để tương tác, kiểm soát và quản lý cơ sở hạ tầng cơ sở dữ liệu của bạn bằng cách sử dụng ClusterControl. Dự án dòng lệnh s9s là mã nguồn mở và có thể được tìm thấy trên GitHub.
Bắt đầu từ phiên bản 1.4.1, tập lệnh trình cài đặt sẽ tự động cài đặt gói (s9s-tools) trên nút ClusterControl.
ClusterControl CLI mở ra một cánh cửa mới cho tự động hóa cụm, nơi bạn có thể dễ dàng tích hợp nó với các công cụ tự động hóa triển khai hiện có như Ansible, Puppet, Chef hoặc Salt.
Hãy xem ví dụ về cách tạo bộ cân bằng tải HAProxy với Địa chỉ IP 192.168.100.142 trên ID cụm 1:
[example@sqldat.com ~]# s9s cluster --add-node --cluster-id=1 --nodes="haproxy://192.168.100.142" --wait
Add HaProxy to Cluster
/ Job 7 FINISHED [██████████] 100% Job finished.Và sau đó, chúng tôi có thể kiểm tra tất cả các nút của mình từ dòng lệnh:
[example@sqldat.com ~]# s9s node --cluster-id=1 --list --long
STAT VERSION CID CLUSTER HOST PORT COMMENT
coC- 1.7.0.2832 1 PostgreSQL1 192.168.100.135 9500 Up and running.
poS- 10.5 1 PostgreSQL1 192.168.100.136 5432 Up and running.
poM- 10.5 1 PostgreSQL1 192.168.100.137 5432 Up and running.
poS- 10.5 1 PostgreSQL1 192.168.100.138 5432 Up and running.
ho-- 1.5.18 1 PostgreSQL1 192.168.100.142 9600 Process 'haproxy' is running.
Total: 5Để biết thêm thông tin về s9s và cách sử dụng nó, bạn có thể xem tài liệu chính thức hoặc cách viết blog về chủ đề này.
Kết luận
Trong blog này, chúng tôi đã xem xét cách HAProxy có thể giúp chúng tôi quản lý lưu lượng truy cập từ ứng dụng vào cơ sở dữ liệu PostgreSQL của chúng tôi. Chúng tôi đã kiểm tra cách nó có thể được triển khai và định cấu hình theo cách thủ công, sau đó xem cách nó có thể được tự động hóa với ClusterControl. Để tránh HAProxy trở thành một điểm lỗi duy nhất (SPOF), hãy đảm bảo rằng bạn triển khai ít nhất hai phiên bản HAProxy và triển khai một cái gì đó như Keepalived và Virtual IP trên chúng.



