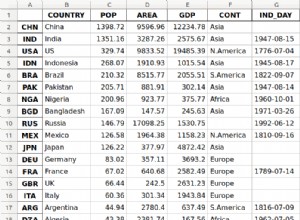
Không có một hệ thống, phần cứng hoặc cấu trúc liên kết hoàn hảo để tránh tất cả các sự cố có thể xảy ra trong môi trường sản xuất. Vượt qua những thách thức này đòi hỏi phải có DRP (Kế hoạch khôi phục sau thảm họa) hiệu quả, được định cấu hình theo ứng dụng, cơ sở hạ tầng và yêu cầu kinh doanh của bạn. Chìa khóa để thành công trong những loại tình huống này luôn là tốc độ chúng tôi có thể khắc phục hoặc phục hồi sau sự cố.
Trong blog này, chúng tôi sẽ xem xét các trường hợp lỗi PostgreSQL phổ biến nhất và chỉ cho bạn cách bạn có thể giải quyết hoặc đối phó với các vấn đề. Chúng tôi cũng sẽ xem xét cách ClusterControl có thể giúp chúng tôi trực tuyến trở lại
Cấu trúc liên kết PostgreSQL phổ biến
Để hiểu các trường hợp lỗi phổ biến, trước tiên bạn phải bắt đầu với cấu trúc liên kết PostgreSQL phổ biến. Đây có thể là bất kỳ ứng dụng nào được kết nối với Nút chính PostgreSQL có bản sao được kết nối với nó.
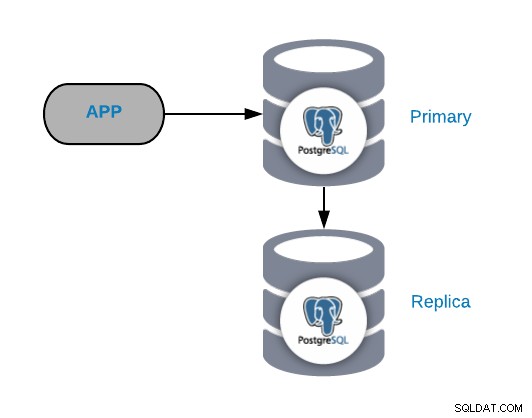
Bạn luôn có thể cải thiện hoặc mở rộng cấu trúc liên kết này bằng cách thêm nhiều nút hoặc bộ cân bằng tải , nhưng đây là cấu trúc liên kết cơ bản mà chúng tôi sẽ bắt đầu làm việc với.
Lỗi Nút PostgreSQL Chính
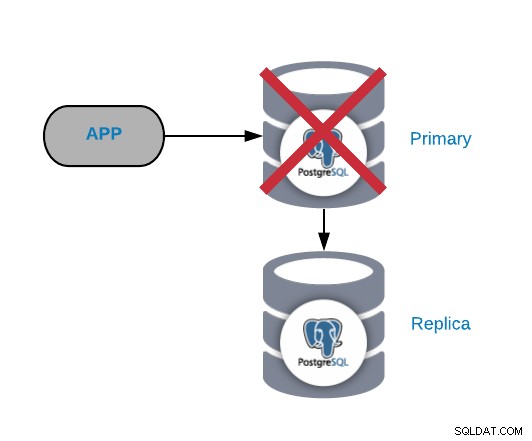
Đây là một trong những lỗi nghiêm trọng nhất vì chúng ta nên khắc phục nó càng sớm càng tốt nếu chúng tôi muốn giữ cho hệ thống của chúng tôi trực tuyến. Đối với loại lỗi này, điều quan trọng là phải có một số loại cơ chế chuyển đổi dự phòng tự động tại chỗ. Sau khi thất bại, bạn có thể xem xét lý do của các vấn đề. Sau quá trình chuyển đổi dự phòng, chúng tôi đảm bảo rằng nút chính bị lỗi sẽ không vẫn nghĩ rằng đó là nút chính. Điều này là để tránh sự mâu thuẫn dữ liệu khi ghi vào nó.
Nguyên nhân phổ biến nhất của loại sự cố này là lỗi hệ điều hành, lỗi phần cứng hoặc lỗi đĩa. Trong mọi trường hợp, chúng tôi nên kiểm tra cơ sở dữ liệu và nhật ký hệ điều hành để tìm lý do.
Giải pháp nhanh nhất cho vấn đề này là thực hiện tác vụ chuyển đổi dự phòng để giảm thời gian chết Để thúc đẩy một bản sao, chúng ta có thể sử dụng lệnh pg_ctl boost trên nút cơ sở dữ liệu nô lệ và sau đó, chúng ta phải gửi lưu lượng truy cập từ ứng dụng cho nút chính mới. Đối với tác vụ cuối cùng này, chúng tôi có thể triển khai bộ cân bằng tải giữa ứng dụng của chúng tôi và các nút cơ sở dữ liệu, để tránh bất kỳ thay đổi nào từ phía ứng dụng trong trường hợp không thành công. Chúng tôi cũng có thể định cấu hình bộ cân bằng tải để phát hiện lỗi của nút và thay vì gửi lưu lượng cho anh ta, hãy gửi lưu lượng đến nút chính mới.
Sau quá trình chuyển đổi dự phòng và đảm bảo hệ thống hoạt động trở lại, chúng tôi có thể xem xét vấn đề và chúng tôi khuyên bạn nên giữ cho ít nhất một nút phụ hoạt động luôn, vì vậy trong trường hợp có lỗi chính mới, chúng ta có thể thực hiện lại tác vụ chuyển đổi dự phòng.
Lỗi nút bản sao PostgreSQL
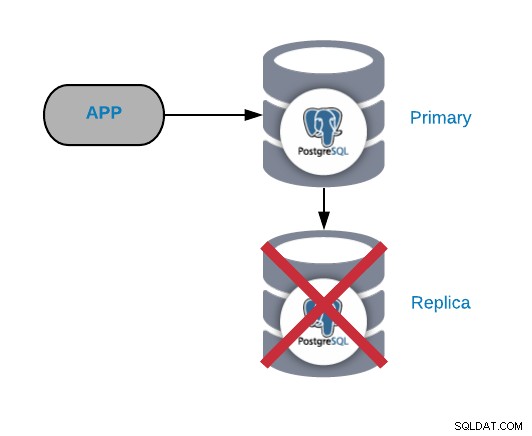
Đây thường không phải là vấn đề nghiêm trọng (miễn là bạn có nhiều hơn một bản sao và không sử dụng nó để gửi lưu lượng sản xuất đã đọc). Nếu bạn đang gặp sự cố trên nút chính và không cập nhật bản sao của mình, bạn sẽ gặp sự cố thực sự nghiêm trọng. Nếu bạn đang sử dụng bản sao của chúng tôi cho mục đích báo cáo hoặc dữ liệu lớn, bạn có thể sẽ muốn nhanh chóng sửa lỗi này.
Nguyên nhân phổ biến nhất của loại sự cố này giống như chúng ta đã thấy đối với nút chính, lỗi hệ điều hành, lỗi phần cứng hoặc lỗi đĩa. Bạn nên kiểm tra cơ sở dữ liệu và nhật ký hệ điều hành để tìm lý do.
Bạn không nên giữ cho hệ thống hoạt động mà không có bất kỳ bản sao nào vì trong trường hợp bị lỗi, bạn không có cách nào nhanh chóng để trực tuyến trở lại. Nếu bạn chỉ có một nô lệ, bạn nên giải quyết vấn đề càng sớm càng tốt; cách nhanh nhất là tạo một bản sao mới từ đầu. Đối với điều này, bạn sẽ cần tạo một bản sao lưu nhất quán và khôi phục nó vào nút phụ, sau đó định cấu hình bản sao giữa nút phụ này và nút chính.
Nếu bạn muốn biết lý do lỗi, bạn nên sử dụng một máy chủ khác để tạo bản sao mới, sau đó xem xét bản sao cũ để khám phá. Khi hoàn thành tác vụ này, bạn cũng có thể định cấu hình lại bản sao cũ và tiếp tục hoạt động như một tùy chọn chuyển đổi dự phòng trong tương lai.
Nếu bạn đang sử dụng bản sao để báo cáo hoặc cho mục đích dữ liệu lớn, bạn phải thay đổi địa chỉ IP để kết nối với địa chỉ mới. Như trong trường hợp trước, một cách để tránh thay đổi này là sử dụng bộ cân bằng tải sẽ biết trạng thái của từng máy chủ, cho phép bạn thêm / xóa các bản sao theo ý muốn.
Lỗi sao chép PostgreSQL
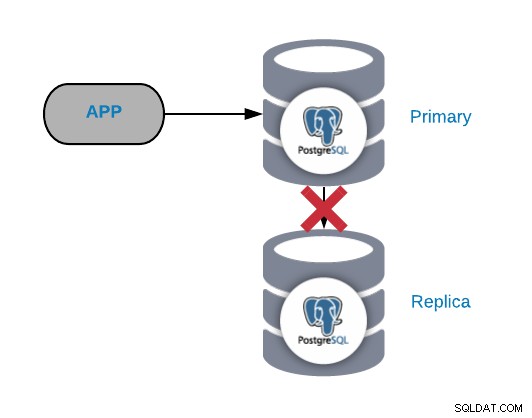
Nói chung, loại sự cố này được tạo ra do mạng hoặc cấu hình phát hành. Nó liên quan đến mất WAL (Ghi-Ahead Logging) trong nút chính và cách PostgreSQL quản lý bản sao.
Nếu bạn có lưu lượng truy cập quan trọng, bạn đang thực hiện các trạm kiểm soát quá thường xuyên hoặc bạn đang lưu trữ WALS chỉ trong vài phút; nếu bạn gặp sự cố mạng, bạn sẽ có rất ít thời gian để giải quyết. WAL của bạn sẽ bị xóa trước khi bạn có thể gửi và áp dụng nó cho bản sao.
Nếu WAL mà bản sao cần để tiếp tục hoạt động đã bị xóa, bạn cần phải xây dựng lại nó, vì vậy để tránh tác vụ này, chúng ta nên kiểm tra cấu hình cơ sở dữ liệu của mình để tăng wal_keep_segment (lượng WALS cần giữ trong thư mục pg_xlog) hoặc tham số max_wal_senders (số lượng tối đa các quy trình người gửi WAL đang chạy đồng thời).
Một tùy chọn được đề xuất khác là định cấu hình archive_mode bật và gửi các tệp WAL đến một đường dẫn khác với tham số archive_command. Bằng cách này, nếu PostgreSQL đạt đến giới hạn và xóa tệp WAL, chúng tôi vẫn sẽ có tệp đó trong một đường dẫn khác.
Lỗi dữ liệu PostgreSQL / Dữ liệu không nhất quán / Xóa do tình cờ

Đây là một cơn ác mộng đối với bất kỳ DBA nào và có lẽ là vấn đề phức tạp nhất đã khắc phục, tùy thuộc vào mức độ phổ biến của vấn đề.
Khi dữ liệu của bạn bị ảnh hưởng bởi một số vấn đề này, cách phổ biến nhất để khắc phục (và có lẽ là duy nhất) là khôi phục bản sao lưu. Đó là lý do tại sao sao lưu là hình thức cơ bản của bất kỳ kế hoạch khôi phục thảm họa nào và bạn nên có ít nhất ba bản sao lưu được lưu trữ ở những nơi thực tế khác nhau. Phương pháp hay nhất yêu cầu các tệp sao lưu phải có một tệp được lưu trữ cục bộ trên máy chủ cơ sở dữ liệu (để khôi phục nhanh hơn), một tệp khác trong máy chủ sao lưu tập trung và tệp cuối cùng trên đám mây.
Chúng tôi cũng có thể tạo kết hợp các bản sao lưu tương thích PITR đầy đủ / gia tăng / khác biệt để giảm Mục tiêu Điểm khôi phục của chúng tôi.
Quản lý lỗi PostgreSQL bằng ClusterControl
Bây giờ chúng ta đã xem xét các trường hợp lỗi PostgreSQL phổ biến này, hãy xem điều gì sẽ xảy ra nếu chúng tôi quản lý cơ sở dữ liệu PostgreSQL của bạn từ hệ thống quản lý cơ sở dữ liệu tập trung. Một điều tuyệt vời là đạt được cách nhanh chóng và dễ dàng để khắc phục sự cố, càng sớm càng tốt, trong trường hợp không thành công.
ClusterControl cung cấp tự động hóa cho hầu hết các tác vụ PostgreSQL được mô tả ở trên; tất cả theo cách tập trung và thân thiện với người dùng. Với hệ thống này, bạn sẽ có thể dễ dàng cấu hình những thứ mà theo cách thủ công sẽ tốn nhiều thời gian và công sức. Bây giờ chúng ta sẽ xem xét một số tính năng chính của nó liên quan đến các trường hợp lỗi PostgreSQL.
Triển khai / Nhập một Cụm PostgreSQL
Khi chúng ta vào giao diện ClusterControl, điều đầu tiên cần làm là triển khai một cụm mới hoặc nhập một cụm hiện có. Để thực hiện triển khai, chỉ cần chọn tùy chọn Triển khai Cụm cơ sở dữ liệu và làm theo hướng dẫn xuất hiện.
Nhân rộng Cụm PostgreSQL của bạn
Nếu bạn đi tới Cluster Actions và chọn Add Replication Slave, bạn có thể tạo một bản sao mới từ đầu hoặc thêm một cơ sở dữ liệu PostgreSQL hiện có làm bản sao. Bằng cách này, bạn có thể chạy bản sao mới của mình trong vài phút và chúng tôi có thể thêm bao nhiêu bản sao tùy ý; lan truyền lưu lượng đọc giữa chúng bằng cách sử dụng bộ cân bằng tải (mà chúng tôi cũng có thể triển khai với ClusterControl).
Chuyển đổi dự phòng tự động PostgreSQL
ClusterControl quản lý chuyển đổi dự phòng trên thiết lập sao chép của bạn. Nó phát hiện lỗi chính và thúc đẩy một nô lệ có dữ liệu mới nhất làm chủ mới. Nó cũng tự động không thành công phần còn lại của các nô lệ để sao chép từ chủ mới. Đối với các kết nối máy khách, nó sử dụng hai công cụ cho nhiệm vụ:HAProxy và Keepalived.
HAProxy là bộ cân bằng tải phân phối lưu lượng truy cập từ một điểm gốc đến một hoặc nhiều điểm đến và có thể xác định các quy tắc và / hoặc giao thức cụ thể cho tác vụ. Nếu bất kỳ điểm đến nào ngừng phản hồi, nó được đánh dấu là ngoại tuyến và lưu lượng truy cập được gửi đến một trong các điểm đến có sẵn. Điều này ngăn không cho lưu lượng truy cập được gửi đến một điểm đến không thể truy cập được và việc mất thông tin này bằng cách chuyển hướng nó đến một điểm đến hợp lệ.
Keepalived cho phép bạn định cấu hình IP ảo trong một nhóm máy chủ hoạt động / thụ động. IP ảo này được gán cho một máy chủ “Chính” đang hoạt động. Nếu máy chủ này bị lỗi, IP sẽ tự động được di chuyển sang máy chủ "Phụ" được phát hiện là bị động, cho phép nó tiếp tục hoạt động với cùng một IP một cách minh bạch cho hệ thống của chúng tôi.
Thêm Bộ cân bằng tải PostgreSQL
Nếu bạn đi tới Tác vụ cụm và chọn Thêm Bộ cân bằng tải (hoặc từ chế độ xem cụm - chuyển đến Quản lý -> Bộ cân bằng tải), bạn có thể thêm bộ cân bằng tải vào cấu trúc liên kết cơ sở dữ liệu của chúng tôi.
Cấu hình cần thiết để tạo bộ cân bằng tải mới của bạn khá đơn giản. Bạn chỉ cần thêm IP / Tên máy chủ, cổng, chính sách và các nút mà chúng tôi sẽ sử dụng. Bạn có thể thêm hai bộ cân bằng tải bằng Keepalived giữa chúng, điều này cho phép chúng tôi tự động chuyển đổi dự phòng cho bộ cân bằng tải của mình trong trường hợp bị lỗi. Keepalived sử dụng địa chỉ IP ảo và di chuyển nó từ bộ cân bằng tải này sang bộ cân bằng tải khác trong trường hợp không thành công, vì vậy thiết lập của chúng tôi có thể tiếp tục hoạt động bình thường.
Bản sao lưu PostgreSQL
Chúng ta đã thảo luận về tầm quan trọng của việc sao lưu. ClusterControl cung cấp chức năng tạo bản sao lưu ngay lập tức hoặc lên lịch cho một bản sao lưu.
Bạn có thể chọn giữa ba phương pháp sao lưu khác nhau, pgdump, pg_basebackup hoặc pgBackRest. Bạn cũng có thể chỉ định nơi lưu trữ các bản sao lưu (trên máy chủ cơ sở dữ liệu, trên máy chủ ClusterControl hoặc trong đám mây), mức nén, yêu cầu mã hóa và khoảng thời gian lưu giữ.
Giám sát &Cảnh báo PostgreSQL
Trước khi có thể thực hiện hành động, bạn cần biết điều gì đang xảy ra, vì vậy bạn cần theo dõi cụm cơ sở dữ liệu của mình. ClusterControl cho phép bạn giám sát các máy chủ của chúng tôi trong thời gian thực. Có các biểu đồ với dữ liệu cơ bản như CPU, Mạng, Đĩa, RAM, IOPS, cũng như các số liệu dành riêng cho cơ sở dữ liệu được thu thập từ các phiên bản PostgreSQL. Các truy vấn cơ sở dữ liệu cũng có thể được xem từ Trình giám sát truy vấn.
Theo cách tương tự khi bạn kích hoạt tính năng giám sát từ ClusterControl, bạn cũng có thể thiết lập các cảnh báo thông báo cho bạn về các sự kiện trong cụm của bạn. Các cảnh báo này có thể định cấu hình và có thể được cá nhân hóa nếu cần.
Kết luận
Mọi người cuối cùng sẽ cần phải đối phó với các sự cố và lỗi của PostgreSQL. Và vì bạn không thể tránh được sự cố, bạn cần có thể khắc phục sự cố càng sớm càng tốt và giữ cho hệ thống hoạt động. Chúng tôi cũng đã biết việc sử dụng ClusterControl có thể giúp giải quyết những vấn đề này như thế nào; tất cả từ một nền tảng duy nhất và thân thiện với người dùng.
Đây là những gì chúng tôi nghĩ là một số trường hợp lỗi phổ biến nhất cho PostgreSQL. Chúng tôi rất muốn nghe về trải nghiệm của chính bạn và cách bạn đã khắc phục điều đó.