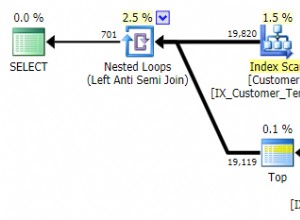
Trong blog trước của tôi, chúng ta đã thảo luận về nhiều cách khác nhau để chọn hoặc quét, dữ liệu từ một bảng. Nhưng trong thực tế, tìm nạp dữ liệu từ một bảng là không đủ. Nó yêu cầu chọn dữ liệu từ nhiều bảng và sau đó tương quan giữa chúng. Mối tương quan của dữ liệu này giữa các bảng được gọi là nối bảng và nó có thể được thực hiện theo nhiều cách khác nhau. Vì việc kết hợp các bảng yêu cầu dữ liệu đầu vào (ví dụ:từ quá trình quét bảng), nó không bao giờ có thể là một nút lá trong kế hoạch được tạo.
Ví dụ:hãy xem xét một ví dụ truy vấn đơn giản như SELECT * FROM TBL1, TBL2 trong đó TBL1.ID> TBL2.ID; và giả sử kế hoạch được tạo như sau:
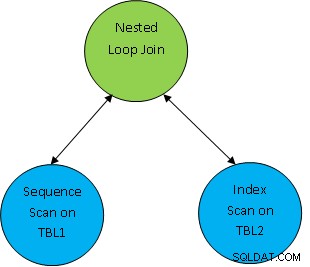
Vì vậy, đây là bảng đầu tiên được quét và sau đó chúng được nối với nhau như theo điều kiện tương quan như TBL.ID> TBL2.ID
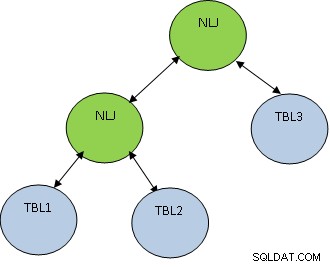
Ngoài phương thức nối, thứ tự nối cũng rất quan trọng. Hãy xem xét ví dụ dưới đây:
CHỌN * TỪ TBL1, TBL2, TBL3 TRONG ĐÓ TBL1.ID =TBL2.ID VÀ TBL2.ID =TBL3.ID;
Xét rằng TBL1, TBL2 VÀ TBL3 lần lượt có 10, 100 và 1000 bản ghi.
Điều kiện TBL1.ID =TBL2.ID chỉ trả về 5 bản ghi, trong khi TBL2.ID =TBL3.ID trả về 100 bản ghi, sau đó tốt hơn nên kết hợp TBL1 và TBL2 trước để số lượng bản ghi nhận được ít hơn đã tham gia với TBL3. Kế hoạch sẽ như hình dưới đây:
PostgreSQL hỗ trợ các loại liên kết dưới đây:
- Tham gia vòng lặp lồng nhau
- Tham gia băm
- Hợp nhất Tham gia
Mỗi phương thức Tham gia này đều hữu ích như nhau tùy thuộc vào truy vấn và các tham số khác, ví dụ:truy vấn, dữ liệu bảng, mệnh đề tham gia, tính chọn lọc, bộ nhớ, v.v. Các phương pháp kết hợp này được thực hiện bởi hầu hết các cơ sở dữ liệu quan hệ.
Hãy tạo một số bảng thiết lập trước và điền vào một số dữ liệu, dữ liệu này sẽ được sử dụng thường xuyên để giải thích rõ hơn về các phương pháp quét này.
postgres=# create table blogtable1(id1 int, id2 int);
CREATE TABLE
postgres=# create table blogtable2(id1 int, id2 int);
CREATE TABLE
postgres=# insert into blogtable1 values(generate_series(1,10000),3);
INSERT 0 10000
postgres=# insert into blogtable2 values(generate_series(1,1000),3);
INSERT 0 1000
postgres=# analyze;
ANALYZETrong tất cả các ví dụ tiếp theo, chúng tôi coi tham số cấu hình mặc định trừ khi được chỉ định cụ thể.
Tham gia vòng lặp lồng nhau
Nối vòng lặp lồng nhau (NLJ) là thuật toán nối đơn giản nhất trong đó mỗi bản ghi của quan hệ ngoài được so khớp với mỗi bản ghi của quan hệ bên trong. Kết nối giữa quan hệ A và B với điều kiện A.ID Nối vòng lặp lồng nhau (NLJ) là phương pháp nối phổ biến nhất và nó có thể được sử dụng hầu như trên bất kỳ tập dữ liệu nào với bất kỳ loại mệnh đề tham gia nào. Vì thuật toán này quét tất cả các bộ giá trị của mối quan hệ bên trong và bên ngoài, nó được coi là hoạt động kết hợp tốn kém nhất. Theo bảng và dữ liệu ở trên, truy vấn sau sẽ dẫn đến Kết nối vòng lặp lồng nhau như được hiển thị bên dưới: Vì mệnh đề tham gia là “<”, phương thức tham gia duy nhất có thể có ở đây là Tham gia vòng lặp lồng nhau. Lưu ý ở đây một loại nút mới là Materialize; nút này hoạt động như bộ nhớ đệm kết quả trung gian, tức là thay vì tìm nạp tất cả các bộ giá trị của một quan hệ nhiều lần, kết quả được tìm nạp lần đầu tiên được lưu trữ trong bộ nhớ và trong lần yêu cầu tiếp theo để lấy bộ mã sẽ được phục vụ từ bộ nhớ thay vì tìm nạp lại từ các trang quan hệ . Trong trường hợp nếu tất cả các bộ dữ liệu không thể vừa trong bộ nhớ thì các bộ giá trị tràn sẽ chuyển sang một tệp tạm thời. Nó chủ yếu hữu ích trong trường hợp Tham gia vòng lặp lồng nhau và ở một mức độ nào đó trong trường hợp Tham gia hợp nhất vì chúng dựa vào việc quét lại mối quan hệ bên trong. Materialize Node không chỉ giới hạn trong bộ nhớ đệm kết quả của mối quan hệ mà nó có thể lưu kết quả vào bộ nhớ đệm của bất kỳ nút nào bên dưới trong cây kế hoạch. MẸO:Trong trường hợp mệnh đề nối là “=” và phép nối vòng lặp lồng nhau được chọn giữa một quan hệ, thì điều thực sự quan trọng là phải điều tra xem phương pháp nối hiệu quả hơn như băm hoặc phép nối có thể được chọn bằng cách điều chỉnh cấu hình (ví dụ:work_mem nhưng không giới hạn) hoặc bằng cách thêm chỉ mục, v.v. Một số truy vấn có thể không có mệnh đề tham gia, trong trường hợp đó, lựa chọn duy nhất để tham gia là Tham gia vòng lặp lồng nhau. Ví dụ. xem xét các truy vấn dưới đây theo dữ liệu thiết lập trước: Phép nối trong ví dụ trên chỉ là tích số Descartes của cả hai bảng. Thuật toán này hoạt động theo hai giai đoạn: Nối giữa quan hệ A và B với điều kiện A.ID =B.ID có thể được biểu diễn như sau: Theo bảng và dữ liệu thiết lập trước ở trên, truy vấn sau sẽ dẫn đến Kết nối băm như được hiển thị bên dưới: Ở đây bảng băm được tạo trên bảng blogtable2 vì nó là bảng nhỏ hơn nên bộ nhớ tối thiểu cần thiết cho bảng băm và toàn bộ bảng băm có thể vừa trong bộ nhớ. Hợp nhất Tham gia là một thuật toán trong đó mỗi bản ghi của quan hệ ngoài được so khớp với từng bản ghi của quan hệ bên trong cho đến khi có khả năng khớp mệnh đề tham gia. Thuật toán nối này chỉ được sử dụng nếu cả hai quan hệ đều được sắp xếp và toán tử mệnh đề tham gia là “=”. Phép nối giữa quan hệ A và B với điều kiện A.ID =B.ID có thể được biểu diễn như sau: Truy vấn mẫu dẫn đến Kết hợp băm, như được hiển thị ở trên, có thể dẫn đến Kết hợp hợp nhất nếu chỉ mục được tạo trên cả hai bảng. Điều này là do dữ liệu bảng có thể được truy xuất theo thứ tự được sắp xếp nhờ chỉ mục, là một trong những tiêu chí chính cho phương pháp Kết hợp Hợp nhất: Vì vậy, như chúng ta thấy, cả hai bảng đang sử dụng quét chỉ mục thay vì quét tuần tự vì cả hai bảng sẽ phát ra các bản ghi đã được sắp xếp. PostgreSQL hỗ trợ các cấu hình liên quan đến trình lập kế hoạch khác nhau, có thể được sử dụng để gợi ý trình tối ưu hóa truy vấn không chọn một số loại phương thức kết hợp cụ thể. Nếu phương thức kết hợp do trình tối ưu hóa chọn không phải là tối ưu, thì các tham số cấu hình này có thể bị tắt để buộc trình tối ưu hóa truy vấn chọn một loại phương thức kết hợp khác. Tất cả các thông số cấu hình này được “bật” theo mặc định. Dưới đây là các thông số cấu hình trình lập kế hoạch cụ thể cho các phương thức kết hợp. Có nhiều tham số cấu hình liên quan đến kế hoạch được sử dụng cho các mục đích khác nhau. Trong blog này, việc giữ nó bị hạn chế chỉ để chỉ các phương thức tham gia. Các tham số này có thể được sửa đổi từ một phiên cụ thể. Vì vậy, trong trường hợp chúng tôi muốn thử nghiệm với kế hoạch từ một phiên cụ thể, thì các thông số cấu hình này có thể được thao tác và các phiên khác sẽ vẫn tiếp tục hoạt động như ban đầu. Bây giờ, hãy xem xét các ví dụ ở trên về phép nối hợp nhất và phép nối băm. Không có chỉ mục, trình tối ưu hóa truy vấn đã chọn một Nối băm cho truy vấn dưới đây như được hiển thị bên dưới nhưng sau khi sử dụng cấu hình, nó sẽ chuyển sang hợp nhất tham gia ngay cả khi không có chỉ mục: Ban đầu Hash Join được chọn vì dữ liệu từ các bảng không được sắp xếp. Để chọn Kế hoạch kết hợp hợp nhất, trước tiên nó cần phải sắp xếp tất cả các bản ghi được truy xuất từ cả hai bảng và sau đó áp dụng phép kết hợp. Vì vậy, chi phí phân loại sẽ được bổ sung và do đó chi phí tổng thể sẽ tăng lên. Vì vậy, có thể, trong trường hợp này, tổng chi phí (bao gồm cả tăng thêm) nhiều hơn tổng chi phí của Hash Join, vì vậy Hash Join được chọn. Sau khi thông số cấu hình enable_hashjoin được thay đổi thành "tắt", điều này có nghĩa là trình tối ưu hóa truy vấn chỉ định trực tiếp chi phí cho tham gia băm dưới dạng chi phí vô hiệu hóa (=1,0e10, tức là 10000000000,00). Chi phí của bất kỳ sự tham gia nào có thể sẽ thấp hơn mức này. Vì vậy, cùng một kết quả truy vấn trong Merge Join sau khi enable_hashjoin được thay đổi thành “off” vì ngay cả khi bao gồm chi phí sắp xếp, tổng chi phí của kết hợp hợp nhất nhỏ hơn chi phí vô hiệu hóa. Bây giờ hãy xem xét ví dụ dưới đây: Như chúng ta có thể thấy ở trên, mặc dù tham số cấu hình liên quan đến phép nối vòng lặp lồng nhau được thay đổi thành "tắt", nó vẫn chọn Tham gia vòng lặp lồng nhau vì không có khả năng thay thế bất kỳ loại Phương thức tham gia nào khác để lấy đã chọn. Nói một cách đơn giản hơn, vì Tham gia vòng lặp lồng nhau là cách tham gia duy nhất có thể xảy ra, nên bất kể chi phí là bao nhiêu thì người chiến thắng sẽ luôn là người chiến thắng (Giống như tôi đã từng là người chiến thắng trong cuộc đua 100m nếu tôi chạy một mình… :-)). Ngoài ra, hãy lưu ý sự khác biệt về chi phí trong kế hoạch thứ nhất và thứ hai. Kế hoạch đầu tiên hiển thị chi phí thực tế của Tham gia vòng lặp lồng nhau nhưng kế hoạch thứ hai hiển thị chi phí vô hiệu hóa của cùng một. Tất cả các loại phương thức nối PostgreSQL đều hữu ích và được lựa chọn dựa trên bản chất của truy vấn, dữ liệu, mệnh đề nối, v.v. Trong trường hợp truy vấn không hoạt động như mong đợi, tức là các phương thức nối không sau đó được chọn như mong đợi, người dùng có thể thử với các thông số cấu hình gói khác nhau có sẵn và xem liệu có điều gì bị thiếu không. For each tuple r in A
For each tuple s in B
If (r.ID < s.ID)
Emit output tuple (r,s)postgres=# explain select * from blogtable1 bt1, blogtable2 bt2 where bt1.id1 < bt2.id1;
QUERY PLAN
------------------------------------------------------------------------------
Nested Loop (cost=0.00..150162.50 rows=3333333 width=16)
Join Filter: (bt1.id1 < bt2.id1)
-> Seq Scan on blogtable1 bt1 (cost=0.00..145.00 rows=10000 width=8)
-> Materialize (cost=0.00..20.00 rows=1000 width=8)
-> Seq Scan on blogtable2 bt2 (cost=0.00..15.00 rows=1000 width=8)
(5 rows)
postgres=# explain select * from blogtable1, blogtable2;
QUERY PLAN
--------------------------------------------------------------------------
Nested Loop (cost=0.00..125162.50 rows=10000000 width=16)
-> Seq Scan on blogtable1 (cost=0.00..145.00 rows=10000 width=8)
-> Materialize (cost=0.00..20.00 rows=1000 width=8)
-> Seq Scan on blogtable2 (cost=0.00..15.00 rows=1000 width=8)
(4 rows) Hash Tham gia
postgres=# explain select * from blogtable1 bt1, blogtable2 bt2 where bt1.id1 = bt2.id1;
QUERY PLAN
------------------------------------------------------------------------------
Hash Join (cost=27.50..220.00 rows=1000 width=16)
Hash Cond: (bt1.id1 = bt2.id1)
-> Seq Scan on blogtable1 bt1 (cost=0.00..145.00 rows=10000 width=8)
-> Hash (cost=15.00..15.00 rows=1000 width=8)
-> Seq Scan on blogtable2 bt2 (cost=0.00..15.00 rows=1000 width=8)
(5 rows) Hợp nhất Tham gia
For each tuple r in A
For each tuple s in B
If (r.ID = s.ID)
Emit output tuple (r,s)
Break;
If (r.ID > s.ID)
Continue;
Else
Break;postgres=# create index idx1 on blogtable1(id1);
CREATE INDEX
postgres=# create index idx2 on blogtable2(id1);
CREATE INDEX
postgres=# explain select * from blogtable1 bt1, blogtable2 bt2 where bt1.id1 = bt2.id1;
QUERY PLAN
---------------------------------------------------------------------------------------
Merge Join (cost=0.56..90.36 rows=1000 width=16)
Merge Cond: (bt1.id1 = bt2.id1)
-> Index Scan using idx1 on blogtable1 bt1 (cost=0.29..318.29 rows=10000 width=8)
-> Index Scan using idx2 on blogtable2 bt2 (cost=0.28..43.27 rows=1000 width=8)
(4 rows) Cấu hình
postgres=# explain select * from blogtable1, blogtable2 where blogtable1.id1 = blogtable2.id1;
QUERY PLAN
--------------------------------------------------------------------------
Hash Join (cost=27.50..220.00 rows=1000 width=16)
Hash Cond: (blogtable1.id1 = blogtable2.id1)
-> Seq Scan on blogtable1 (cost=0.00..145.00 rows=10000 width=8)
-> Hash (cost=15.00..15.00 rows=1000 width=8)
-> Seq Scan on blogtable2 (cost=0.00..15.00 rows=1000 width=8)
(5 rows)
postgres=# set enable_hashjoin to off;
SET
postgres=# explain select * from blogtable1, blogtable2 where blogtable1.id1 = blogtable2.id1;
QUERY PLAN
----------------------------------------------------------------------------
Merge Join (cost=874.21..894.21 rows=1000 width=16)
Merge Cond: (blogtable1.id1 = blogtable2.id1)
-> Sort (cost=809.39..834.39 rows=10000 width=8)
Sort Key: blogtable1.id1
-> Seq Scan on blogtable1 (cost=0.00..145.00 rows=10000 width=8)
-> Sort (cost=64.83..67.33 rows=1000 width=8)
Sort Key: blogtable2.id1
-> Seq Scan on blogtable2 (cost=0.00..15.00 rows=1000 width=8)
(8 rows)postgres=# explain select * from blogtable1, blogtable2 where blogtable1.id1 < blogtable2.id1;
QUERY PLAN
--------------------------------------------------------------------------
Nested Loop (cost=0.00..150162.50 rows=3333333 width=16)
Join Filter: (blogtable1.id1 < blogtable2.id1)
-> Seq Scan on blogtable1 (cost=0.00..145.00 rows=10000 width=8)
-> Materialize (cost=0.00..20.00 rows=1000 width=8)
-> Seq Scan on blogtable2 (cost=0.00..15.00 rows=1000 width=8)
(5 rows)
postgres=# set enable_nestloop to off;
SET
postgres=# explain select * from blogtable1, blogtable2 where blogtable1.id1 < blogtable2.id1;
QUERY PLAN
--------------------------------------------------------------------------
Nested Loop (cost=10000000000.00..10000150162.50 rows=3333333 width=16)
Join Filter: (blogtable1.id1 < blogtable2.id1)
-> Seq Scan on blogtable1 (cost=0.00..145.00 rows=10000 width=8)
-> Materialize (cost=0.00..20.00 rows=1000 width=8)
-> Seq Scan on blogtable2 (cost=0.00..15.00 rows=1000 width=8)
(5 rows) Kết luận