Tất cả hệ thống cơ sở dữ liệu hiện đại đều hỗ trợ mô-đun Trình tối ưu hóa Truy vấn để tự động xác định chiến lược hiệu quả nhất để thực hiện các truy vấn SQL. Chiến lược hiệu quả được gọi là "Kế hoạch" và nó được đo lường bằng chi phí tỷ lệ thuận với "Thời gian thực hiện truy vấn / phản hồi". Kế hoạch được biểu diễn dưới dạng đầu ra dạng cây từ Trình tối ưu hóa truy vấn. Các nút của cây kế hoạch có thể được chia chủ yếu thành 3 loại sau:
- Nút quét :Như đã giải thích trong blog trước đây của tôi “Tổng quan về các phương pháp quét khác nhau trong PostgreSQL”, nó chỉ ra cách dữ liệu bảng cơ sở cần được tìm nạp.
- Các nút tham gia :Như đã giải thích trong blog trước đây của tôi “Tổng quan về các phương thức JOIN trong PostgreSQL”, nó cho biết cách hai bảng cần được kết hợp với nhau để có được kết quả của hai bảng.
- Nút Vật chất hóa :Còn được gọi là các nút phụ. Hai loại nút trước đó liên quan đến cách tìm nạp dữ liệu từ bảng cơ sở và cách nối dữ liệu được truy xuất từ hai bảng. Các nút trong danh mục này được áp dụng trên đầu dữ liệu được truy xuất để phân tích thêm hoặc chuẩn bị báo cáo, v.v. Sắp xếp dữ liệu, tổng hợp dữ liệu, v.v.
Hãy xem xét một ví dụ truy vấn đơn giản như ...
SELECT * FROM TBL1, TBL2 where TBL1.ID > TBL2.ID order by TBL.ID;Giả sử một kế hoạch được tạo tương ứng với truy vấn như sau:
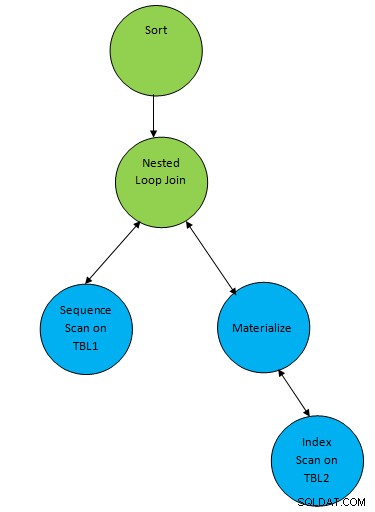
Vì vậy, ở đây một nút phụ “Sắp xếp” được thêm vào đầu kết quả của phép nối để sắp xếp dữ liệu theo thứ tự bắt buộc.
Một số nút phụ được tạo bởi trình tối ưu hóa truy vấn PostgreSQL như sau:
- Sắp xếp
- Tổng hợp
- Nhóm Theo Tổng hợp
- Giới hạn
- Độc đáo
- LockRows
- SetOp
Hãy hiểu từng nút trong số này.
Sắp xếp
Như tên cho thấy, nút này được thêm vào như một phần của cây kế hoạch bất cứ khi nào có nhu cầu về dữ liệu được sắp xếp. Dữ liệu được sắp xếp có thể được yêu cầu một cách rõ ràng hoặc ẩn ý như hai trường hợp dưới đây:
Kịch bản người dùng yêu cầu dữ liệu được sắp xếp làm đầu ra. Trong trường hợp này, nút Sắp xếp có thể nằm trên toàn bộ quá trình truy xuất dữ liệu bao gồm tất cả các quá trình xử lý khác.
postgres=# CREATE TABLE demotable (num numeric, id int);
CREATE TABLE
postgres=# INSERT INTO demotable SELECT random() * 1000, generate_series(1, 10000);
INSERT 0 10000
postgres=# analyze;
ANALYZE
postgres=# explain select * from demotable order by num;
QUERY PLAN
----------------------------------------------------------------------
Sort (cost=819.39..844.39 rows=10000 width=15)
Sort Key: num
-> Seq Scan on demotable (cost=0.00..155.00 rows=10000 width=15)
(3 rows)Lưu ý: Mặc dù người dùng yêu cầu đầu ra cuối cùng theo thứ tự đã sắp xếp, nhưng nút Sắp xếp có thể không được thêm vào kế hoạch cuối cùng nếu có một chỉ mục trên bảng và cột sắp xếp tương ứng. Trong trường hợp này, nó có thể chọn quét chỉ mục dẫn đến thứ tự dữ liệu được sắp xếp ngầm. Ví dụ:hãy tạo một chỉ mục trong ví dụ trên và xem kết quả:
postgres=# CREATE INDEX demoidx ON demotable(num);
CREATE INDEX
postgres=# explain select * from demotable order by num;
QUERY PLAN
--------------------------------------------------------------------------------
Index Scan using demoidx on demotable (cost=0.29..534.28 rows=10000 width=15)
(1 row)Như đã giải thích trong blog trước đây của tôi Tổng quan về các phương thức JOIN trong PostgreSQL, Merge Join yêu cầu cả hai dữ liệu bảng phải được sắp xếp trước khi kết hợp. Vì vậy, có thể xảy ra rằng Merge Join được tìm thấy là rẻ hơn bất kỳ phương pháp nối nào khác ngay cả khi có thêm chi phí sắp xếp. Vì vậy, trong trường hợp này, nút Sắp xếp sẽ được thêm vào giữa phương thức nối và phương thức quét của bảng để các bản ghi đã sắp xếp có thể được chuyển cho phương thức nối.
postgres=# create table demo1(id int, id2 int);
CREATE TABLE
postgres=# insert into demo1 values(generate_series(1,1000), generate_series(1,1000));
INSERT 0 1000
postgres=# create table demo2(id int, id2 int);
CREATE TABLE
postgres=# create index demoidx2 on demo2(id);
CREATE INDEX
postgres=# insert into demo2 values(generate_series(1,100000), generate_series(1,100000));
INSERT 0 100000
postgres=# analyze;
ANALYZE
postgres=# explain select * from demo1, demo2 where demo1.id=demo2.id;
QUERY PLAN
------------------------------------------------------------------------------------
Merge Join (cost=65.18..109.82 rows=1000 width=16)
Merge Cond: (demo2.id = demo1.id)
-> Index Scan using demoidx2 on demo2 (cost=0.29..3050.29 rows=100000 width=8)
-> Sort (cost=64.83..67.33 rows=1000 width=8)
Sort Key: demo1.id
-> Seq Scan on demo1 (cost=0.00..15.00 rows=1000 width=8)
(6 rows)Tổng hợp
Nút tổng hợp được thêm vào như một phần của cây kế hoạch nếu có một hàm tổng hợp được sử dụng để tính toán các kết quả đơn lẻ từ nhiều hàng đầu vào. Một số hàm tổng hợp được sử dụng là COUNT, SUM, AVG (AVERAGE), MAX (MAXIMUM) và MIN (MINIMUM).
Một nút tổng hợp có thể xuất hiện trên cùng của quá trình quét quan hệ cơ sở hoặc (và) khi kết hợp các quan hệ. Ví dụ:
postgres=# explain select count(*) from demo1;
QUERY PLAN
---------------------------------------------------------------
Aggregate (cost=17.50..17.51 rows=1 width=8)
-> Seq Scan on demo1 (cost=0.00..15.00 rows=1000 width=0)
(2 rows)
postgres=# explain select sum(demo1.id) from demo1, demo2 where demo1.id=demo2.id;
QUERY PLAN
-----------------------------------------------------------------------------------------------
Aggregate (cost=112.32..112.33 rows=1 width=8)
-> Merge Join (cost=65.18..109.82 rows=1000 width=4)
Merge Cond: (demo2.id = demo1.id)
-> Index Only Scan using demoidx2 on demo2 (cost=0.29..3050.29 rows=100000 width=4)
-> Sort (cost=64.83..67.33 rows=1000 width=4)
Sort Key: demo1.id
-> Seq Scan on demo1 (cost=0.00..15.00 rows=1000 width=4)HashAggregate / GroupAggregate
Các loại nút này là phần mở rộng của nút "Tổng hợp". Nếu các hàm tổng hợp được sử dụng để kết hợp nhiều hàng đầu vào theo nhóm của chúng, thì các loại nút này sẽ được thêm vào một cây kế hoạch. Vì vậy, nếu truy vấn có bất kỳ hàm tổng hợp nào được sử dụng và cùng với đó có mệnh đề GROUP BY trong truy vấn, thì nút HashAggregate hoặc GroupAggregate sẽ được thêm vào cây kế hoạch.
Vì PostgreSQL sử dụng Trình tối ưu hóa dựa trên chi phí để tạo cây kế hoạch tối ưu, nên hầu như không thể đoán được nút nào trong số các nút này sẽ được sử dụng. Nhưng hãy hiểu khi nào và cách nó được sử dụng.
HashAggregate
HashAggregate hoạt động bằng cách xây dựng bảng băm dữ liệu để nhóm chúng lại. Vì vậy, HashAggregate có thể được sử dụng bởi tổng hợp cấp nhóm nếu tổng hợp đang diễn ra trên tập dữ liệu chưa được sắp xếp.
postgres=# explain select count(*) from demo1 group by id2;
QUERY PLAN
---------------------------------------------------------------
HashAggregate (cost=20.00..30.00 rows=1000 width=12)
Group Key: id2
-> Seq Scan on demo1 (cost=0.00..15.00 rows=1000 width=4)
(3 rows)Đây là dữ liệu lược đồ bảng demo1 theo ví dụ được hiển thị trong phần trước. Vì chỉ có 1000 hàng để nhóm, nên tài nguyên cần thiết để xây dựng bảng băm sẽ ít hơn chi phí sắp xếp. Người lập kế hoạch truy vấn quyết định chọn HashAggregate.
GroupAggregate
GroupAggregate hoạt động trên dữ liệu được sắp xếp nên không yêu cầu bất kỳ cấu trúc dữ liệu bổ sung nào. GroupAggregate có thể được sử dụng bởi tổng hợp cấp nhóm nếu tập hợp nằm trên tập dữ liệu đã sắp xếp. Để nhóm trên dữ liệu được sắp xếp, nó có thể sắp xếp rõ ràng (bằng cách thêm nút Sắp xếp) hoặc nó có thể hoạt động trên dữ liệu được tìm nạp theo chỉ mục, trong trường hợp đó nó được sắp xếp ngầm.
postgres=# explain select count(*) from demo2 group by id2;
QUERY PLAN
-------------------------------------------------------------------------
GroupAggregate (cost=9747.82..11497.82 rows=100000 width=12)
Group Key: id2
-> Sort (cost=9747.82..9997.82 rows=100000 width=4)
Sort Key: id2
-> Seq Scan on demo2 (cost=0.00..1443.00 rows=100000 width=4)
(5 rows) Đây là dữ liệu lược đồ bảng demo2 theo ví dụ được hiển thị trong phần trước. Vì ở đây có 100000 hàng để nhóm, vì vậy tài nguyên cần thiết để xây dựng bảng băm có thể đắt hơn chi phí sắp xếp. Vì vậy, người lập kế hoạch truy vấn quyết định chọn GroupAggregate. Hãy quan sát ở đây, các bản ghi được chọn từ bảng “demo2” được sắp xếp rõ ràng và có một nút được thêm vào cây kế hoạch.
Xem bên dưới một ví dụ khác, trong đó dữ liệu đã được truy xuất được sắp xếp do quét chỉ mục:
postgres=# create index idx1 on demo1(id);
CREATE INDEX
postgres=# explain select sum(id2), id from demo1 where id=1 group by id;
QUERY PLAN
------------------------------------------------------------------------
GroupAggregate (cost=0.28..8.31 rows=1 width=12)
Group Key: id
-> Index Scan using idx1 on demo1 (cost=0.28..8.29 rows=1 width=8)
Index Cond: (id = 1)
(4 rows) Xem thêm một ví dụ dưới đây, mặc dù có Quét chỉ mục, nó vẫn cần phải sắp xếp rõ ràng vì cột có chỉ mục ở đó và cột nhóm không giống nhau. Vì vậy, nó vẫn cần phải sắp xếp theo cột nhóm.
postgres=# explain select sum(id), id2 from demo1 where id=1 group by id2;
QUERY PLAN
------------------------------------------------------------------------------
GroupAggregate (cost=8.30..8.32 rows=1 width=12)
Group Key: id2
-> Sort (cost=8.30..8.31 rows=1 width=8)
Sort Key: id2
-> Index Scan using idx1 on demo1 (cost=0.28..8.29 rows=1 width=8)
Index Cond: (id = 1)
(6 rows)Lưu ý: GroupAggregate / HashAggregate có thể được sử dụng cho nhiều truy vấn gián tiếp khác mặc dù tổng hợp với nhóm bởi không có trong truy vấn. Nó phụ thuộc vào cách người lập kế hoạch diễn giải truy vấn. Ví dụ. Giả sử chúng ta cần nhận giá trị riêng biệt từ bảng, sau đó nó có thể được xem như một nhóm theo cột tương ứng và sau đó lấy một giá trị từ mỗi nhóm.
postgres=# explain select distinct(id) from demo1;
QUERY PLAN
---------------------------------------------------------------
HashAggregate (cost=17.50..27.50 rows=1000 width=4)
Group Key: id
-> Seq Scan on demo1 (cost=0.00..15.00 rows=1000 width=4)
(3 rows)Vì vậy, ở đây HashAggregate được sử dụng ngay cả khi không có tập hợp và nhóm nào có liên quan.
Giới hạn
Các nút giới hạn được thêm vào cây kế hoạch nếu mệnh đề "giới hạn / bù đắp" được sử dụng trong truy vấn SELECT. Mệnh đề này được sử dụng để giới hạn số hàng và tùy chọn cung cấp một khoảng bù để bắt đầu đọc dữ liệu. Ví dụ bên dưới:
postgres=# explain select * from demo1 offset 10;
QUERY PLAN
---------------------------------------------------------------
Limit (cost=0.15..15.00 rows=990 width=8)
-> Seq Scan on demo1 (cost=0.00..15.00 rows=1000 width=8)
(2 rows)
postgres=# explain select * from demo1 limit 10;
QUERY PLAN
---------------------------------------------------------------
Limit (cost=0.00..0.15 rows=10 width=8)
-> Seq Scan on demo1 (cost=0.00..15.00 rows=1000 width=8)
(2 rows)
postgres=# explain select * from demo1 offset 5 limit 10;
QUERY PLAN
---------------------------------------------------------------
Limit (cost=0.07..0.22 rows=10 width=8)
-> Seq Scan on demo1 (cost=0.00..15.00 rows=1000 width=8)
(2 rows)Duy nhất
Nút này được chọn để nhận một giá trị khác biệt với kết quả cơ bản. Lưu ý rằng tùy thuộc vào truy vấn, tính chọn lọc và thông tin tài nguyên khác, giá trị khác biệt có thể được truy xuất bằng HashAggregate / GroupAggregate mà không cần sử dụng nút Unique. Ví dụ:
postgres=# explain select distinct(id) from demo2 where id<100;
QUERY PLAN
-----------------------------------------------------------------------------------
Unique (cost=0.29..10.27 rows=99 width=4)
-> Index Only Scan using demoidx2 on demo2 (cost=0.29..10.03 rows=99 width=4)
Index Cond: (id < 100)
(3 rows)LockRows
PostgreSQL cung cấp chức năng khóa tất cả các hàng đã chọn. Hàng có thể được chọn ở chế độ “Chia sẻ” hoặc chế độ “Độc quyền” tùy thuộc vào mệnh đề “ĐỂ CHIA SẺ” và “CẬP NHẬT” tương ứng. Một nút mới “LockRows” được thêm vào cây kế hoạch để đạt được hoạt động này.
postgres=# explain select * from demo1 for update;
QUERY PLAN
----------------------------------------------------------------
LockRows (cost=0.00..25.00 rows=1000 width=14)
-> Seq Scan on demo1 (cost=0.00..15.00 rows=1000 width=14)
(2 rows)
postgres=# explain select * from demo1 for share;
QUERY PLAN
----------------------------------------------------------------
LockRows (cost=0.00..25.00 rows=1000 width=14)
-> Seq Scan on demo1 (cost=0.00..15.00 rows=1000 width=14)
(2 rows)SetOp
PostgreSQL cung cấp chức năng kết hợp các kết quả của hai hoặc nhiều truy vấn. Vì vậy, khi loại nút Tham gia được chọn để nối hai bảng, một loại nút SetOp tương tự sẽ được chọn để kết hợp kết quả của hai hoặc nhiều truy vấn. Ví dụ:hãy xem xét một bảng có các nhân viên với id, tên, tuổi và mức lương của họ như bên dưới:
postgres=# create table emp(id int, name char(20), age int, salary int);
CREATE TABLE
postgres=# insert into emp values(1,'a', 30,100);
INSERT 0 1
postgres=# insert into emp values(2,'b', 31,90);
INSERT 0 1
postgres=# insert into emp values(3,'c', 40,105);
INSERT 0 1
postgres=# insert into emp values(4,'d', 20,80);
INSERT 0 1 Bây giờ, hãy tìm nhân viên trên 25 tuổi:
postgres=# select * from emp where age > 25;
id | name | age | salary
----+----------------------+-----+--------
1 | a | 30 | 100
2 | b | 31 | 90
3 | c | 40 | 105
(3 rows) Bây giờ, hãy kiếm nhân viên có mức lương trên 95 triệu:
postgres=# select * from emp where salary > 95;
id | name | age | salary
----+----------------------+-----+--------
1 | a | 30 | 100
3 | c | 40 | 105
(2 rows)Bây giờ để có được những nhân viên trên 25 tuổi và mức lương trên 95 triệu, chúng tôi có thể viết câu truy vấn giao nhau dưới đây:
postgres=# explain select * from emp where age>25 intersect select * from emp where salary > 95;
QUERY PLAN
---------------------------------------------------------------------------------
HashSetOp Intersect (cost=0.00..72.90 rows=185 width=40)
-> Append (cost=0.00..64.44 rows=846 width=40)
-> Subquery Scan on "*SELECT* 1" (cost=0.00..30.11 rows=423 width=40)
-> Seq Scan on emp (cost=0.00..25.88 rows=423 width=36)
Filter: (age > 25)
-> Subquery Scan on "*SELECT* 2" (cost=0.00..30.11 rows=423 width=40)
-> Seq Scan on emp emp_1 (cost=0.00..25.88 rows=423 width=36)
Filter: (salary > 95)
(8 rows) Vì vậy, ở đây, một loại nút HashSetOp mới được thêm vào để đánh giá giao điểm của hai truy vấn riêng lẻ này.
Lưu ý rằng có hai loại nút mới khác được thêm vào đây:
Nối
Nút này được thêm vào để kết hợp nhiều kết quả được đặt thành một.
Quét Truy vấn Con
Nút này được thêm vào để đánh giá bất kỳ truy vấn con nào. Trong kế hoạch trên, truy vấn con được thêm vào để đánh giá một giá trị cột không đổi bổ sung cho biết bộ đầu vào nào đã đóng góp một hàng cụ thể.
HashedSetop hoạt động bằng cách sử dụng hàm băm của kết quả cơ bản nhưng có thể tạo hoạt động SetOp dựa trên Sắp xếp bằng trình tối ưu hóa truy vấn. Nút Setop dựa trên sắp xếp được ký hiệu là “Setop”.
Lưu ý:Có thể đạt được kết quả tương tự như được hiển thị trong kết quả ở trên với một truy vấn duy nhất nhưng ở đây nó được hiển thị bằng cách sử dụng giao nhau chỉ để minh họa dễ dàng.
Kết luận
Tất cả các nút của PostgreSQL đều hữu ích và được lựa chọn dựa trên bản chất của truy vấn, dữ liệu, v.v. Nhiều mệnh đề được ánh xạ một đến một với các nút. Đối với một số điều khoản, có nhiều tùy chọn cho các nút, được quyết định dựa trên các tính toán chi phí dữ liệu cơ bản.



