Trong bài đăng trên blog trước, tôi đã giải thích ngắn gọn cách chúng tôi nhận được các con số hiệu suất được công bố trong thông báo bệnh học. Trong bài đăng blog này, tôi muốn thảo luận về các giới hạn hiệu suất của các giải pháp sao chép hợp lý nói chung và cũng như cách chúng áp dụng cho pglogical.
sao chép vật lý
Trước tiên, hãy xem cách hoạt động của sao chép vật lý (được tích hợp trong PostgreSQL kể từ phiên bản 9.0). Một hình đơn giản hơn một chút về chỉ có hai nút trông như thế này:
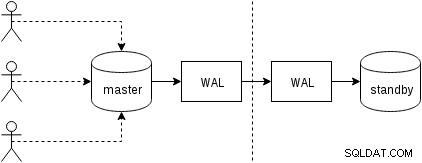
Máy khách thực hiện các truy vấn trên nút chính, các thay đổi được ghi vào nhật ký giao dịch (WAL) và được sao chép qua mạng sang WAL trên nút chờ. Quá trình khôi phục trong quá trình chờ ở chế độ chờ sau đó đọc các thay đổi từ WAL và áp dụng chúng vào các tệp dữ liệu giống như trong quá trình khôi phục. Nếu chế độ chờ ở chế độ “hot_standby”, ứng dụng khách có thể đưa ra các truy vấn chỉ đọc trên nút khi điều này đang diễn ra.
Điều này rất hiệu quả vì có rất ít quá trình xử lý bổ sung - các thay đổi được chuyển và ghi vào chế độ chờ dưới dạng một đốm nhị phân mờ đục. Tất nhiên, quá trình khôi phục không miễn phí (cả về CPU và I / O), nhưng rất khó để đạt được hiệu quả hơn điều này.
Các điểm nghẽn tiềm ẩn rõ ràng khi tái tạo vật lý là băng thông mạng (chuyển WAL từ chính sang chế độ chờ) và cả I / O ở chế độ chờ, có thể bị bão hòa bởi quá trình khôi phục thường đưa ra nhiều yêu cầu I / O ngẫu nhiên ( trong một số trường hợp còn hơn cả bậc thầy, nhưng chúng ta đừng đi sâu vào vấn đề đó).
sao chép lôgic
Việc sao chép lôgic phức tạp hơn một chút, vì nó không xử lý luồng WAL nhị phân không rõ ràng, mà là một luồng thay đổi "lôgic" (hãy tưởng tượng các câu lệnh INSERT, UPDATE hoặc DELETE, mặc dù điều đó không hoàn toàn chính xác vì chúng ta đang xử lý biểu diễn có cấu trúc của dữ liệu). Có những thay đổi hợp lý cho phép thực hiện những việc thú vị như giải quyết xung đột, chỉ sao chép các bảng đã chọn, sang một lược đồ khác hoặc giữa các phiên bản khác nhau (hoặc thậm chí là các cơ sở dữ liệu khác nhau).
Có nhiều cách khác nhau để nhận các thay đổi - cách tiếp cận truyền thống là sử dụng trình kích hoạt ghi lại các thay đổi vào một bảng và để một quy trình tùy chỉnh liên tục đọc các thay đổi đó và áp dụng chúng ở chế độ chờ bằng cách chạy các truy vấn SQL. Và tất cả điều này được thúc đẩy bởi một quy trình daemon bên ngoài (hoặc có thể nhiều quy trình, chạy trên cả hai nút), như được minh họa trên hình tiếp theo

Đó là những gì slony hoặc londiste làm, và mặc dù nó hoạt động khá tốt, nó có nghĩa là rất nhiều chi phí - ví dụ:nó yêu cầu nắm bắt các thay đổi dữ liệu và ghi dữ liệu nhiều lần (vào bảng gốc và bảng "nhật ký", và cũng thành WAL cho cả hai bảng đó). Chúng ta sẽ thảo luận về các nguồn chi phí khác sau. Mặc dù pglogical cần đạt được các mục tiêu giống nhau, nhưng nó đạt được chúng theo cách khác nhau, nhờ một số tính năng được thêm vào các phiên bản PostgreSQL gần đây (do đó không khả dụng trở lại khi các công cụ khác được triển khai):

Nghĩa là, thay vì duy trì một nhật ký thay đổi riêng biệt, pglogical dựa vào WAL - điều này có thể thực hiện được nhờ giải mã logic có sẵn trong PostgreSQL 9.4, cho phép trích xuất các thay đổi logic từ nhật ký WAL. Nhờ đó, pglogical không cần bất kỳ trình kích hoạt đắt tiền nào và thường có thể tránh ghi dữ liệu hai lần trên bản chính (ngoại trừ các giao dịch lớn có thể tràn ra đĩa).
Sau khi giải mã mỗi giao dịch, nó được chuyển sang chế độ chờ và quy trình áp dụng áp dụng các thay đổi của nó vào cơ sở dữ liệu dự phòng. pglogical không áp dụng các thay đổi bằng cách chạy các truy vấn SQL thông thường, nhưng ở cấp độ thấp hơn, bỏ qua chi phí liên quan đến phân tích cú pháp và lập kế hoạch truy vấn SQL. Điều này mang lại cho pglogical một lợi thế đáng kể so với các giải pháp hiện có mà tất cả đều đi qua lớp SQL (do đó trả phí phân tích cú pháp và lập kế hoạch).
nút thắt cổ chai tiềm ẩn
Rõ ràng, sao chép logic dễ bị tắc nghẽn giống như sao chép vật lý, tức là có thể làm bão hòa mạng khi chuyển các thay đổi và I / O ở chế độ chờ khi áp dụng chúng ở chế độ chờ. Ngoài ra còn có một lượng chi phí hợp lý do các bước bổ sung không có trong bản sao thực.
Chúng ta cần phải thu thập bằng cách nào đó những thay đổi hợp lý, trong khi sao chép vật lý chỉ đơn giản là chuyển tiếp WAL dưới dạng dòng byte. Như đã đề cập, các giải pháp hiện tại thường dựa vào trình kích hoạt ghi các thay đổi vào bảng “nhật ký”. pglogical thay vào đó dựa vào nhật ký ghi trước (WAL) và giải mã logic để đạt được điều tương tự, rẻ hơn so với trình kích hoạt và cũng không cần phải ghi dữ liệu hai lần trong hầu hết các trường hợp (với phần thưởng bổ sung mà chúng tôi tự động áp dụng các thay đổi theo thứ tự cam kết).
Điều đó không có nghĩa là không có cơ hội để cải thiện thêm - ví dụ:việc giải mã hiện chỉ xảy ra khi giao dịch được cam kết, vì vậy với các giao dịch lớn, điều này có thể làm tăng độ trễ sao chép. Sao chép vật lý chỉ đơn giản là truyền các thay đổi WAL tới nút khác và do đó không có giới hạn này. Các giao dịch lớn cũng có thể tràn vào đĩa, gây ra các lần ghi trùng lặp, bởi vì phần thượng nguồn phải lưu trữ chúng cho đến khi chúng cam kết và chúng có thể được gửi đến phần hạ lưu.
Công việc trong tương lai được lên kế hoạch để cho phép pglogical bắt đầu phát trực tuyến các giao dịch lớn trong khi chúng vẫn đang trong quá trình ngược dòng, giảm độ trễ giữa cam kết ngược dòng và cam kết xuôi dòng và giảm khuếch đại ghi ngược dòng.
Sau khi các thay đổi được chuyển sang chế độ chờ, quá trình áp dụng cần phải thực sự áp dụng chúng bằng cách nào đó. Như đã đề cập trong phần trước, các giải pháp hiện có đã thực hiện điều đó bằng cách xây dựng và thực thi các lệnh SQL, trong khi pglogical bỏ qua hoàn toàn lớp SQL và chi phí liên quan.
Tuy nhiên, điều đó không làm cho việc áp dụng hoàn toàn miễn phí vì nó vẫn cần thực hiện những việc như tra cứu khóa chính, cập nhật chỉ mục, thực thi trình kích hoạt và thực hiện nhiều kiểm tra khác. Nhưng nó rẻ hơn đáng kể so với phương pháp dựa trên SQL. Theo một nghĩa nào đó, nó hoạt động giống như SAO CHÉP và đặc biệt nhanh trên các bảng đơn giản không có trình kích hoạt, khóa ngoại, v.v.
Trong tất cả các giải pháp sao chép hợp lý, mỗi bước trong số đó (giải mã và áp dụng) xảy ra trong một quy trình duy nhất, do đó, có một lượng thời gian CPU khá hạn chế. Đây có lẽ là nút thắt cổ chai cấp bách nhất trong tất cả các giải pháp hiện có, bởi vì bạn có thể có một cỗ máy khá mạnh mẽ với hàng chục hoặc thậm chí hàng trăm khách hàng đang chạy truy vấn song song, nhưng tất cả điều đó cần phải trải qua một quy trình duy nhất để giải mã những thay đổi đó (trên chính) và một quy trình áp dụng những thay đổi đó (ở chế độ chờ).
Giới hạn "quy trình đơn" có thể được nới lỏng phần nào bằng cách sử dụng các cơ sở dữ liệu riêng biệt, vì mỗi cơ sở dữ liệu được xử lý bởi một quy trình riêng biệt. Khi nói đến một cơ sở dữ liệu duy nhất, công việc trong tương lai được lên kế hoạch song song áp dụng thông qua một nhóm nhân viên nền tảng để giảm bớt nút thắt cổ chai này.