Mặc dù trong tương lai, hầu hết các máy chủ cơ sở dữ liệu (đặc biệt là những máy chủ xử lý khối lượng công việc giống như OLTP) sẽ sử dụng bộ lưu trữ dựa trên flash, chúng tôi vẫn chưa có - bộ nhớ flash vẫn đắt hơn đáng kể so với ổ cứng truyền thống và vì vậy nhiều hệ thống sử dụng hỗn hợp ổ cứng SSD và HDD. Tuy nhiên, điều đó có nghĩa là chúng ta cần quyết định cách phân chia cơ sở dữ liệu - điều gì sẽ xảy ra với ổ cứng (HDD) và đâu là ứng cử viên sáng giá cho bộ lưu trữ flash đắt hơn nhưng tốt hơn nhiều trong việc xử lý I / O ngẫu nhiên.
Có các giải pháp cố gắng xử lý điều này tự động ở cấp lưu trữ bằng cách tự động sử dụng SSD làm bộ nhớ đệm, tự động giữ phần dữ liệu đang hoạt động trên SSD. Các thiết bị lưu trữ / SAN thường thực hiện điều này bên trong, có các ổ SATA / SAS kết hợp với ổ cứng HDD lớn và SSD nhỏ trong một gói duy nhất và tất nhiên là các giải pháp để thực hiện điều này trực tiếp tại máy chủ - ví dụ:có dm-cache trong Linux, LVM cũng có khả năng như vậy (được xây dựng trên dm-cache) vào năm 2014 và tất nhiên ZFS có L2ARC.
Nhưng chúng ta hãy bỏ qua tất cả các tùy chọn tự động đó và giả sử chúng ta có hai thiết bị được gắn trực tiếp vào hệ thống - một thiết bị dựa trên ổ cứng HDD, thiết bị còn lại dựa trên flash. Bạn nên chia cơ sở dữ liệu như thế nào để có được nhiều lợi ích nhất từ đèn flash đắt tiền? Một mẫu thường được sử dụng là thực hiện điều này theo loại đối tượng, đặc biệt là bảng so với chỉ mục. Nhìn chung, điều này có ý nghĩa, nhưng chúng ta thường thấy mọi người đặt các chỉ mục trên bộ lưu trữ SSD, vì các chỉ mục được liên kết với I / O ngẫu nhiên. Mặc dù điều này có vẻ hợp lý, nhưng hóa ra điều này hoàn toàn ngược lại với những gì bạn nên làm.
Để tôi cho bạn xem điểm chuẩn…
Hãy để tôi chứng minh điều này trên hệ thống có cả ổ lưu trữ HDD (RAID10 được xây dựng từ ổ 4x 10k SAS) và một thiết bị SSD duy nhất (Intel S3700). Hệ thống có 16GB RAM, vì vậy hãy sử dụng pgbench với thang đo 300 (=4,5GB) và 3000 (=45GB), tức là một pgbench dễ dàng vừa với RAM và nhiều RAM. Sau đó, hãy đặt các bảng và chỉ mục trên các hệ thống lưu trữ khác nhau (bằng cách sử dụng không gian bảng) và đo lường hiệu suất. Cụm cơ sở dữ liệu đã được cấu hình hợp lý (bộ đệm chia sẻ, giới hạn WAL, v.v.) liên quan đến tài nguyên phần cứng. WAL được đặt trên một thiết bị SSD riêng biệt, được gắn với bộ điều khiển RAID dùng chung với các ổ đĩa SAS.
Trên tập dữ liệu nhỏ (4,5GB), kết quả trông như thế này (lưu ý trục y bắt đầu ở 3000 tps):
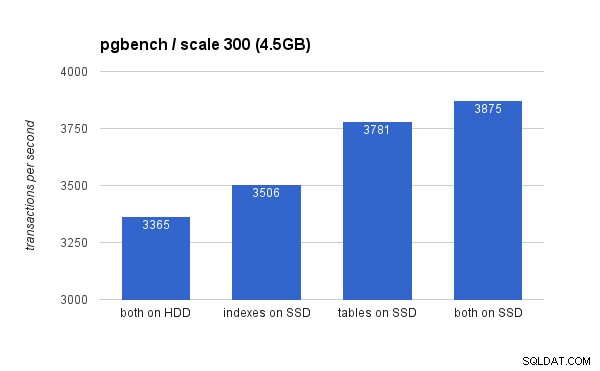
Rõ ràng, việc đặt các chỉ mục trên SSD mang lại lợi ích thấp hơn so với việc sử dụng SSD cho bảng. Mặc dù tập dữ liệu dễ dàng phù hợp với RAM, nhưng các thay đổi cuối cùng cần phải được ghi vào đĩa cuối cùng và trong khi bộ điều khiển RAID có bộ nhớ đệm ghi, nó không thực sự có thể cạnh tranh với bộ nhớ flash. Bộ điều khiển RAID mới có thể sẽ hoạt động tốt hơn một chút, nhưng các ổ SSD mới cũng vậy.
Trên tập dữ liệu lớn, sự khác biệt đáng kể hơn nhiều (lúc này trục y bắt đầu từ 0):
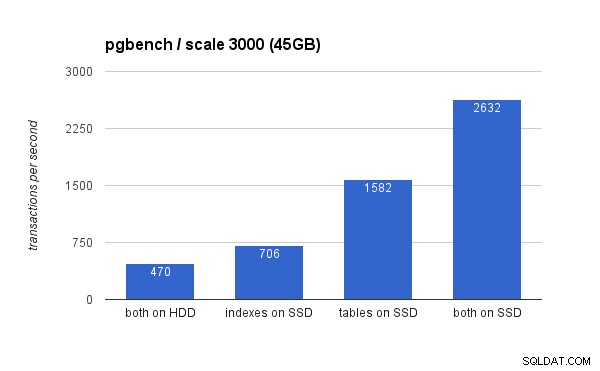
Đặt các chỉ mục trên SSD dẫn đến hiệu suất tăng đáng kể (gần 50%, lấy ổ lưu trữ HDD làm cơ sở), nhưng việc di chuyển bảng sang SSD dễ dàng đánh bại điều đó bằng cách tăng hơn 200%. Tất nhiên, nếu bạn đặt cả bảng và lập chỉ mục trên SSD, bạn sẽ cải thiện hiệu suất hơn nữa - nhưng nếu bạn có thể làm được điều đó, bạn không cần phải lo lắng về các trường hợp khác.
Nhưng tại sao?
Đạt được hiệu suất tốt hơn từ việc đặt bảng trên SSD có vẻ hơi phản trực quan, vậy tại sao nó lại hoạt động như vậy? Chà, nó có thể là sự kết hợp của một số yếu tố:
- các chỉ mục thường nhỏ hơn nhiều so với các bảng và do đó, dễ dàng đưa vào bộ nhớ hơn
- các trang ở các mức chỉ mục (trong cây) thường khá nóng và do đó vẫn còn trong bộ nhớ
- khi quét và lập chỉ mục, rất nhiều I / O thực tế có tính chất tuần tự (đặc biệt đối với các trang lá)
Hệ quả của điều này là số lượng I / O đáng ngạc nhiên so với các chỉ mục hoặc không xảy ra (nhờ vào bộ nhớ đệm) hoặc là tuần tự. Mặt khác, các chỉ mục là một nguồn I / O ngẫu nhiên tuyệt vời so với các bảng.
Tuy nhiên, nó phức tạp hơn…
Tất nhiên, đây chỉ là một ví dụ đơn giản và các kết luận có thể khác nhau đối với các khối lượng công việc về cơ bản khác nhau. Tương tự như vậy, vì SSD đắt hơn, các hệ thống có xu hướng có nhiều không gian đĩa trên ổ HDD hơn trên ổ SSD, do đó, các bảng có thể không vừa với SSD trong khi các chỉ mục sẽ có. Trong những trường hợp đó, một vị trí phức tạp hơn là cần thiết - chẳng hạn như xem xét không chỉ loại đối tượng mà còn xem xét tần suất nó được sử dụng (và chỉ di chuyển các bảng được sử dụng nhiều sang SSD) hoặc thậm chí các tập hợp con của bảng (ví dụ:bằng cách chuyển dần dữ liệu từ SSD sang HDD).