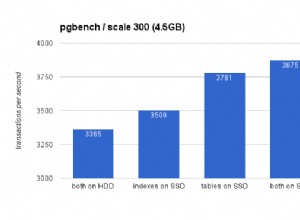
Bạn có thể sử dụng các kết nối đó và tránh SQLAlchemy. Điều này nghe có vẻ không trực quan, nhưng nó sẽ nhanh hơn nhiều so với chèn thông thường (ngay cả khi bạn bỏ ORM và thực hiện một truy vấn chung, ví dụ:với executemany ). Chèn chậm, ngay cả với các truy vấn thô, nhưng bạn sẽ thấy rằng COPY được đề cập nhiều lần trong Cách tăng tốc hiệu suất chèn trong PostgreSQL
. Trong trường hợp này, động lực của tôi cho cách tiếp cận dưới đây là:
- Sử dụng
COPYthay vìINSERT - Không tin tưởng Pandas tạo SQL chính xác cho thao tác này (mặc dù, như Ilja Everilä đã lưu ý, phương pháp này thực sự có được thêm vào Pandas trong V0.24 )
- Không ghi dữ liệu vào đĩa để tạo một đối tượng tệp thực sự; lưu giữ tất cả trong bộ nhớ
Phương pháp được đề xuất sử dụng cursor.copy_from()
:
import csv
import io
import psycopg2
df = "<your_df_here>"
# drop all the columns you don't want in the insert data here
# First take the headers
headers = df.columns
# Now get a nested list of values
data = df.values.tolist()
# Create an in-memory CSV file
string_buffer = io.StringIO()
csv_writer = csv.writer(string_buffer)
csv_writer.writerows(data)
# Reset the buffer back to the first line
string_buffer.seek(0)
# Open a connection to the db (which I think you already have available)
with psycopg2.connect(dbname=current_app.config['POSTGRES_DB'],
user=current_app.config['POSTGRES_USER'],
password=current_app.config['POSTGRES_PW'],
host=current_app.config['POSTGRES_URL']) as conn:
c = conn.cursor()
# Now upload the data as though it was a file
c.copy_from(string_buffer, 'the_table_name', sep=',', columns=headers)
conn.commit()
Đây sẽ là các đơn đặt hàng có quy mô nhanh hơn so với thực tế thực hiện các lần chèn.