Nếu tôi đang đọc đầu ra của đầu ra của bạn một cách chính xác, nó sẽ không được thực hiện tại một thời điểm khi bạn hết bộ nhớ.
Lỗi thực tế có vẻ ổn - nó không yêu cầu dung lượng bộ nhớ lớn nên có thể máy đã hết bộ nhớ vào thời điểm đó.
Hãy xem nhanh cài đặt của bạn:
max_connections = 1000 # (change requires restart)
work_mem = 40MB # min 64kB
Vì vậy - bạn có ý kiến rằng bạn có thể hỗ trợ 1000 truy vấn đồng thời, mỗi truy vấn sử dụng 10 + 40MB giả sử (một số có thể sử dụng bội số của 40MB nhưng hãy hợp lý). Vì vậy - điều này gợi ý cho tôi rằng máy của bạn có> 500 lõi và có 100GB RAM. Đó không phải là trường hợp.
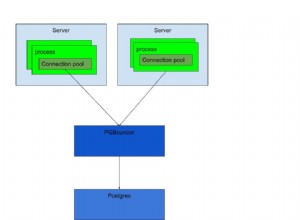
Vì vậy - lấy số lõi của bạn và tăng gấp đôi - đó là một giá trị hợp lý cho số lượng kết nối tối đa. Điều đó sẽ cho phép bạn một truy vấn trên mỗi lõi trong khi một lõi khác đang đợi I / O. Sau đó, đặt một bộ gộp kết nối trước DB nếu bạn cần (bộ gộp kết nối của pgbouncer / Java).
Sau đó, bạn thậm chí có thể cân nhắc tăng work_mem nếu cần.
Ồ - hoàn toàn hợp lý để chạy mà không bật hoán đổi. Khi bạn bắt đầu hoán đổi, bạn vẫn đang ở trong một thế giới đau đớn về việc sử dụng cơ sở dữ liệu.
Chỉnh sửa:mở rộng trên work_mem so với shared
Nếu nghi ngờ, hãy luôn tham khảo tài liệu .
shared_buffers giá trị, như tên cho thấy được chia sẻ giữa các phần phụ trợ. work_mem không chỉ cho mỗi chương trình phụ trợ, nó thực sự theo từng loại. Vì vậy - một truy vấn có thể sử dụng gấp ba hoặc bốn lần số tiền đó nếu nó đang thực hiện sắp xếp trên ba truy vấn con.