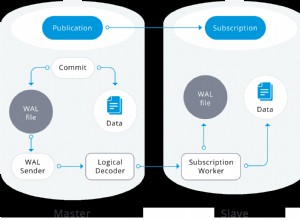
Mã hóa ký tự, chẳng hạn như múi giờ, là một nguồn thường xuyên của các vấn đề.
Những gì bạn có thể làm là tìm kiếm bất kỳ ký tự "ASCII cao" nào vì đây là ký tự hoặc ký hiệu có dấu LATIN1 hoặc ký tự đầu tiên của ký tự nhiều byte UTF-8. Nói ra sự khác biệt sẽ không dễ dàng trừ khi bạn gian lận một chút.
Để tìm ra cách mã hóa nào là chính xác, bạn chỉ cần SELECT hai phiên bản khác nhau và so sánh trực quan. Đây là một ví dụ:
SELECT CONVERT(CONVERT(name USING BINARY) USING latin1) AS latin1,
CONVERT(CONVERT(name USING BINARY) USING utf8) AS utf8
FROM users
WHERE CONVERT(name USING BINARY) RLIKE CONCAT('[', UNHEX('80'), '-', UNHEX('FF'), ']')
Điều này được thực hiện phức tạp bất thường bởi vì MySQL regexp engine dường như bỏ qua những thứ như \x80 và làm cho nó cần thiết để sử dụng UNHEX() thay vào đó.
Điều này tạo ra kết quả như sau:
latin1 utf8
----------------------------------------
Björn Björn