Xây dựng tính khả dụng cao, từng bước một
Khi nói đến cơ sở hạ tầng cơ sở dữ liệu, tất cả chúng ta đều muốn có nó. Tất cả chúng tôi đều cố gắng xây dựng một thiết lập có tính khả dụng cao. Dự phòng là chìa khóa. Chúng tôi bắt đầu triển khai dự phòng ở mức thấp nhất và tiếp tục tăng ngăn xếp. Nó bắt đầu với phần cứng - nguồn điện dự phòng, làm mát dự phòng, đĩa trao đổi nóng. Lớp mạng - nhiều NIC được liên kết với nhau và được kết nối với các thiết bị chuyển mạch khác nhau đang sử dụng các bộ định tuyến dự phòng. Để lưu trữ, chúng tôi sử dụng các đĩa được đặt trong RAID, mang lại hiệu suất tốt hơn nhưng cũng có khả năng dự phòng. Sau đó, ở cấp độ phần mềm, chúng tôi sử dụng công nghệ phân cụm:nhiều nút cơ sở dữ liệu làm việc cùng nhau để triển khai dự phòng:Cụm MySQL, Cụm Galera.
Tất cả những điều này đều không tốt nếu bạn có mọi thứ trong một trung tâm dữ liệu duy nhất:khi một trung tâm dữ liệu gặp sự cố hoặc một phần của các dịch vụ (nhưng những dịch vụ quan trọng) chuyển sang chế độ ngoại tuyến, hoặc ngay cả khi bạn mất kết nối với trung tâm dữ liệu, dịch vụ của bạn sẽ ngừng hoạt động - không có vấn đề số lượng dự phòng ở các cấp thấp hơn. Và vâng, những điều đó xảy ra.
- Sự cố gián đoạn dịch vụ S3 đã tàn phá ở khu vực US-East-1 vào tháng 2 năm 2017
- Gián đoạn dịch vụ EC2 và RDS ở khu vực Đông Hoa Kỳ vào tháng 4 năm 2011
- EC2, EBS và RDS đã bị gián đoạn ở khu vực Tây Âu vào tháng 8 năm 2011
- Sự cố mất điện đã dẫn đến sự cố Rackspace Texas DC vào tháng 6 năm 2009
- Sự cố của UPS khiến hàng trăm máy chủ ở trạng thái ngoại tuyến ở Rackspace London DC vào tháng 1 năm 2010
Đây hoàn toàn không phải là danh sách đầy đủ các lỗi, nó chỉ là kết quả của một tìm kiếm nhanh trên Google. Đây là những ví dụ cho thấy mọi thứ có thể và sẽ sai nếu bạn cho tất cả trứng vào cùng một giỏ. Thêm một ví dụ nữa là cơn bão Sandy, gây ra lượng dữ liệu khổng lồ từ miền Đông Hoa Kỳ sang miền Tây Hoa Kỳ - vào thời điểm đó, bạn khó có thể ghi lại các trường hợp ở miền Tây Hoa Kỳ khi mọi người đổ xô di chuyển cơ sở hạ tầng của họ sang bờ biển khác với mong đợi rằng Bắc Virginia DC sẽ bị ảnh hưởng nghiêm trọng bởi thời tiết.
Vì vậy, thiết lập nhiều trung tâm dữ liệu là điều bắt buộc nếu bạn muốn xây dựng một môi trường có tính khả dụng cao. Trong bài đăng trên blog này, chúng ta sẽ thảo luận về cách xây dựng cơ sở hạ tầng như vậy bằng Galera Cluster cho MySQL / MariaDB.
Các khái niệm về Galera
Trước khi xem xét các giải pháp cụ thể, chúng ta hãy dành thời gian giải thích hai khái niệm rất quan trọng trong các thiết lập Galera đa DC có tính khả dụng cao.
Số đại biểu
Tính khả dụng cao yêu cầu tài nguyên - cụ thể là bạn cần một số nút trong cụm để làm cho nó khả dụng cao. Một cụm có thể chịu đựng sự mất mát của một số thành viên của nó, nhưng chỉ ở một mức độ nhất định. Ngoài một tỷ lệ thất bại nhất định, bạn có thể đang nhìn vào một tình huống não tàn.
Hãy lấy một ví dụ với thiết lập 2 nút. Nếu một trong các nút gặp sự cố, làm thế nào nút còn lại có thể biết rằng nút mạng ngang hàng của nó đã bị lỗi và đó không phải là lỗi mạng? Trong trường hợp đó, nút khác cũng có thể đang hoạt động, phục vụ lưu lượng truy cập. Không có cách nào tốt để xử lý trường hợp như vậy… Đây là lý do tại sao khả năng chịu lỗi thường bắt đầu từ ba nút. Galera sử dụng phép tính số đại biểu để xác định xem cụm xử lý lưu lượng có an toàn hay không hoặc liệu cụm có nên ngừng hoạt động hay không. Sau khi bị lỗi, tất cả các nút còn lại cố gắng kết nối với nhau và xác định xem có bao nhiêu nút trong số chúng đang hoạt động. Sau đó, nó được so sánh với trạng thái trước đó của cụm và miễn là hơn 50% số nút hoạt động, cụm có thể tiếp tục hoạt động.
Điều này dẫn đến kết quả sau:
Cụm 2 nút - không có khả năng chịu lỗi
Cụm 3 nút - tối đa 1 sự cố
4 cụm nút - tối đa 1 sự cố (nếu hai nút cùng gặp sự cố, chỉ 50% của cụm sẽ khả dụng, bạn cần hơn 50% nút để tồn tại)
Cụm 5 nút - tối đa 2 sự cố
6 cụm nút - tối đa 2 sự cố
Bạn có thể thấy mô hình - bạn muốn cụm của mình có một số nút lẻ - xét về tính khả dụng cao, không có ích gì khi di chuyển từ 5 đến 6 nút trong cụm. Nếu bạn muốn khả năng chịu lỗi tốt hơn, bạn nên sử dụng 7 nút.
Phân đoạn
Thông thường, trong một cụm Galera, tất cả các giao tiếp đều tuân theo khuôn mẫu tất cả cho tất cả. Mỗi nút nói chuyện với tất cả các nút khác trong cụm.
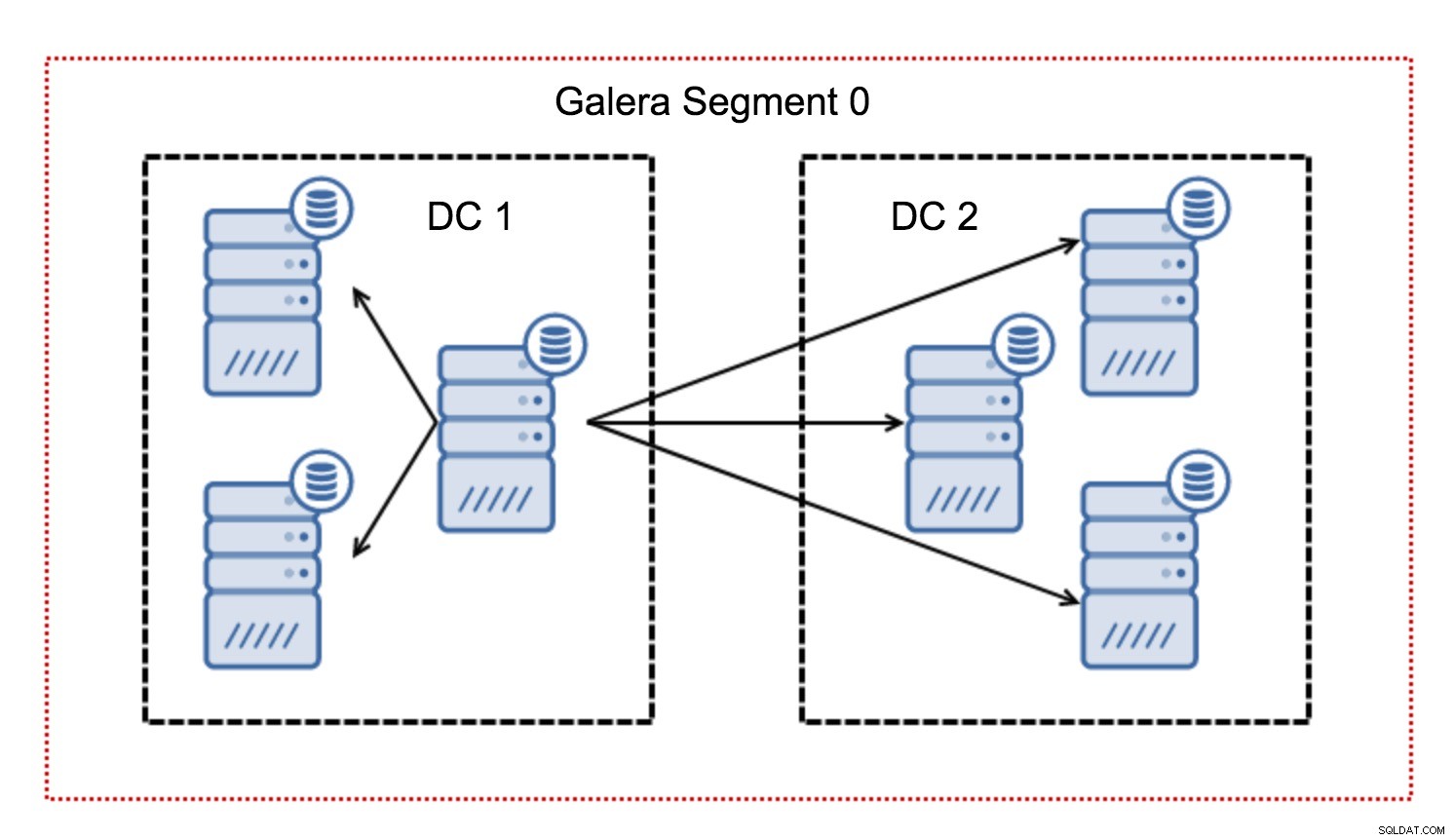
Như bạn có thể biết, mỗi bộ ghi trong Galera phải được chứng nhận bởi tất cả các nút trong cụm - do đó mọi ghi xảy ra trên một nút phải được chuyển đến tất cả các nút trong cụm. Điều này hoạt động tốt trong môi trường có độ trễ thấp. Nhưng nếu chúng ta đang nói về thiết lập đa DC, chúng ta cần xem xét độ trễ cao hơn nhiều so với trong mạng cục bộ. Để làm cho nó hoạt động dễ dàng hơn trong các cụm trải dài trên Mạng diện rộng, Galera đã giới thiệu các phân đoạn.
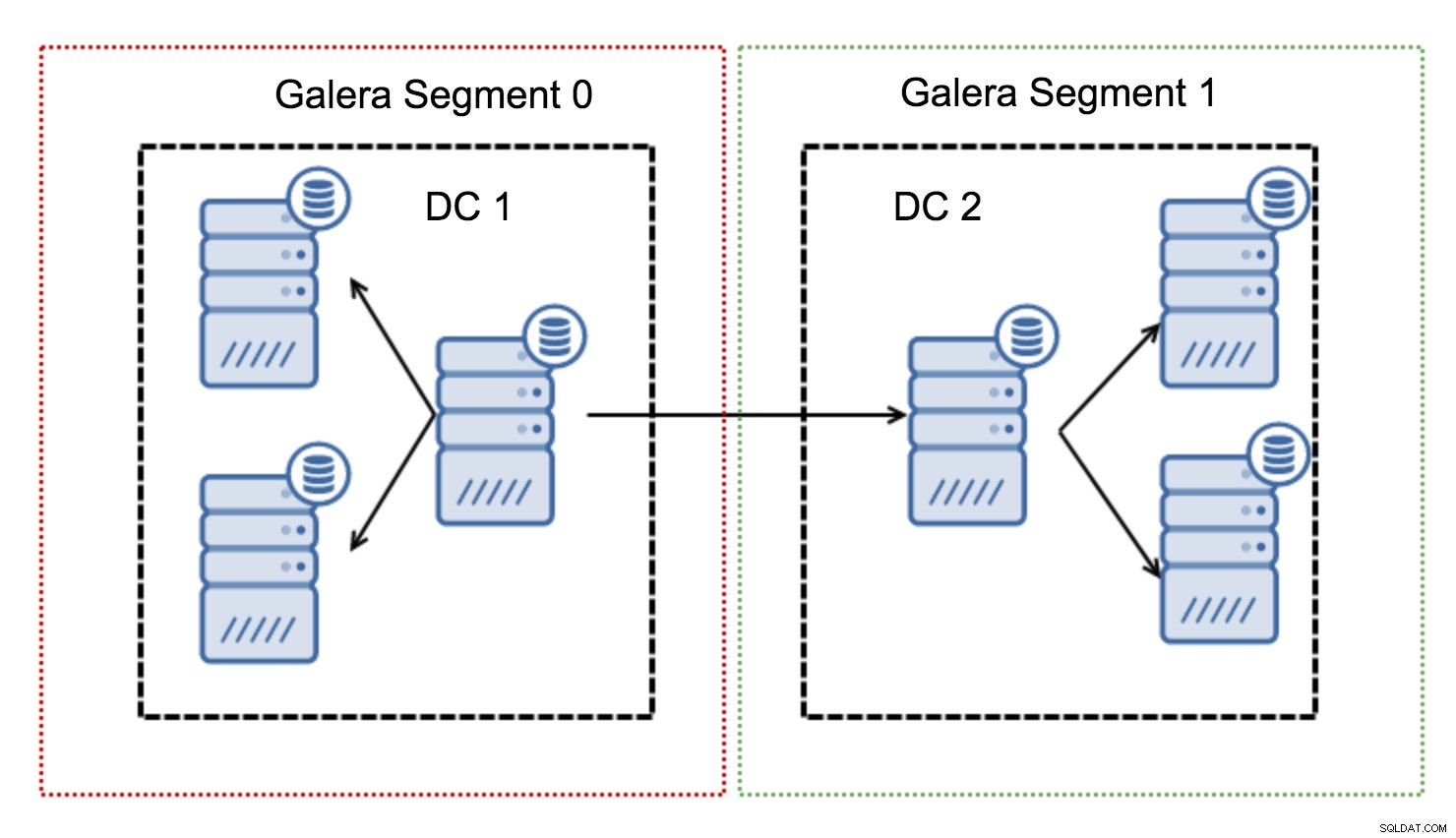
Chúng hoạt động bằng cách chứa lưu lượng Galera trong một nhóm các nút (phân đoạn). Tất cả các nút trong một phân đoạn duy nhất hoạt động như thể chúng nằm trong một mạng cục bộ - chúng giả định là một cho tất cả các giao tiếp. Đối với lưu lượng truy cập đoạn chéo, mọi thứ lại khác - trong mỗi đoạn, một nút “chuyển tiếp” được chọn, tất cả lưu lượng truy cập đoạn chéo đều đi qua các nút đó. Khi một nút chuyển tiếp gặp sự cố, một nút khác sẽ được bầu chọn. Điều này không làm giảm độ trễ nhiều - sau tất cả, độ trễ WAN sẽ không đổi cho dù bạn thực hiện kết nối với một máy chủ từ xa hay nhiều máy chủ từ xa, nhưng do các liên kết WAN có xu hướng bị giới hạn băng thông và có thể có tính phí cho lượng dữ liệu được truyền, cách tiếp cận như vậy cho phép bạn giới hạn lượng dữ liệu được trao đổi giữa các phân đoạn. Một lựa chọn tiết kiệm thời gian và chi phí khác là thực tế là các nút trong cùng một phân khúc được ưu tiên khi cần một nhà tài trợ - một lần nữa, điều này giới hạn lượng dữ liệu được truyền qua mạng WAN và rất có thể, tăng tốc SST như một mạng cục bộ hầu như luôn luôn sẽ nhanh hơn liên kết WAN.
Bây giờ chúng ta đã hiểu rõ một số khái niệm này, hãy cùng xem xét một số khía cạnh quan trọng khác của thiết lập đa DC cho cụm Galera.
Các vấn đề bạn sắp phải đối mặt
Khi làm việc trong các môi trường trải dài trên mạng WAN, có một số vấn đề bạn cần cân nhắc khi thiết kế môi trường của mình.
Tính toán số lượng
Trong phần trước, chúng tôi đã mô tả cách tính số đại biểu trông như thế nào trong cụm Galera - nói tóm lại, bạn muốn có một số nút lẻ để tối đa hóa khả năng sống sót. Tất cả những điều đó vẫn đúng trong thiết lập đa DC, nhưng một số yếu tố khác được thêm vào hỗn hợp. Trước hết, bạn cần quyết định xem bạn có muốn Galera tự động xử lý lỗi trung tâm dữ liệu hay không. Điều này sẽ xác định có bao nhiêu trung tâm dữ liệu bạn sẽ sử dụng. Hãy tưởng tượng hai DC - nếu bạn chia các nút của mình 50% - 50%, nếu một trung tâm dữ liệu gặp sự cố, trung tâm thứ hai không có 50% + 1 nút để duy trì trạng thái "chính" của nó. Nếu bạn phân chia các nút của mình theo cách không đồng đều, sử dụng phần lớn chúng trong trung tâm dữ liệu “chính”, khi trung tâm dữ liệu đó gặp sự cố, DC “dự phòng” sẽ không có 50% + 1 nút để tạo thành đại số. Bạn có thể chỉ định các trọng số khác nhau cho các nút nhưng kết quả sẽ hoàn toàn giống nhau - không có cách nào để tự động chuyển đổi dự phòng giữa hai DC mà không cần can thiệp thủ công. Để triển khai chuyển đổi dự phòng tự động, bạn cần nhiều hơn hai DC. Một lần nữa, lý tưởng là một số lẻ - ba trung tâm dữ liệu là một thiết lập hoàn toàn tốt. Tiếp theo, câu hỏi là - bạn cần có bao nhiêu nút? Bạn muốn chúng được phân bổ đồng đều trên các trung tâm dữ liệu. Phần còn lại chỉ là vấn đề có bao nhiêu nút bị lỗi mà thiết lập của bạn phải xử lý.
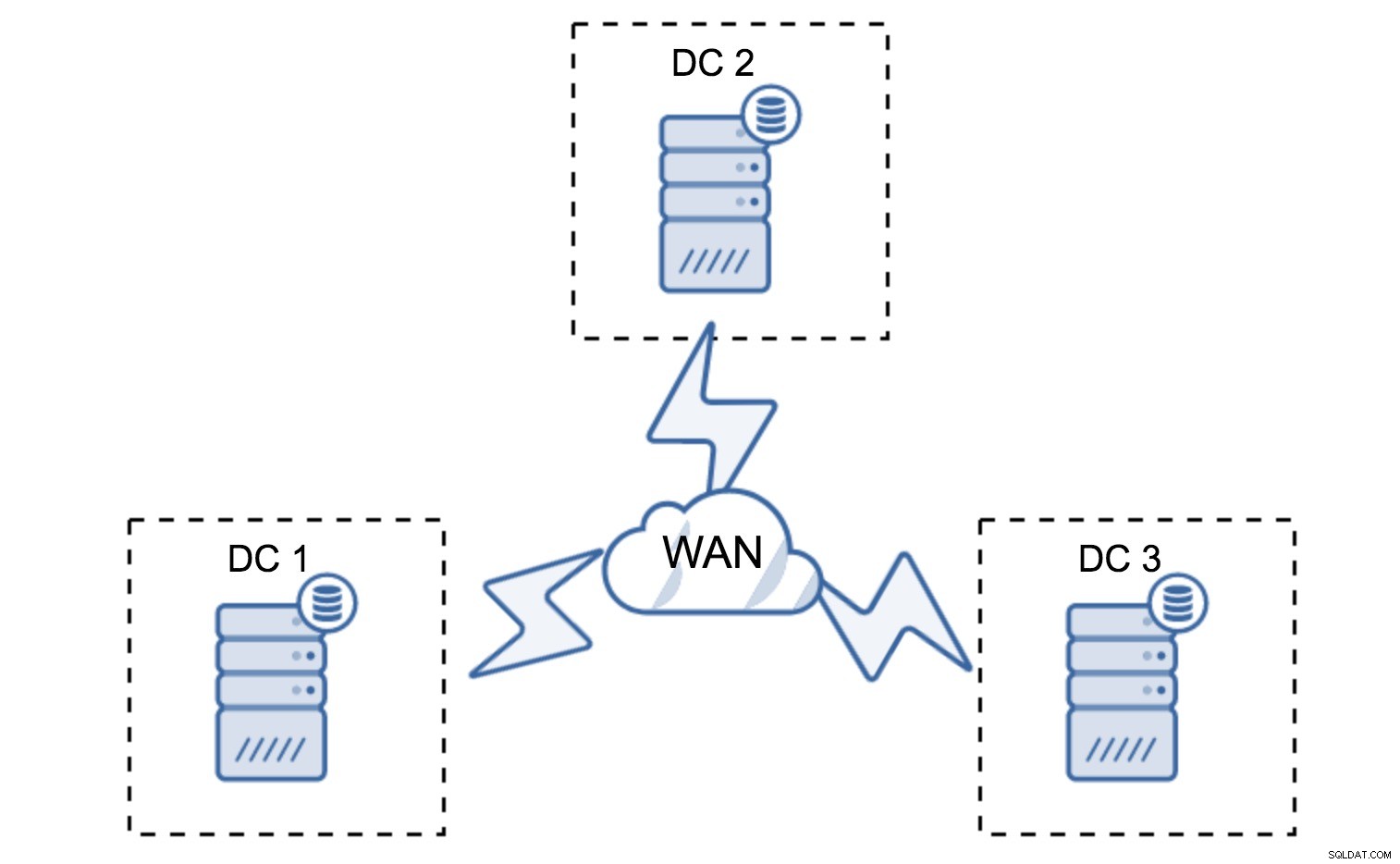
Thiết lập tối thiểu sẽ sử dụng một nút trên mỗi trung tâm dữ liệu - tuy nhiên, nó có những nhược điểm nghiêm trọng. Mọi chuyển trạng thái sẽ yêu cầu di chuyển dữ liệu qua mạng WAN và điều này dẫn đến thời gian cần thiết lâu hơn để hoàn thành SST hoặc chi phí cao hơn.
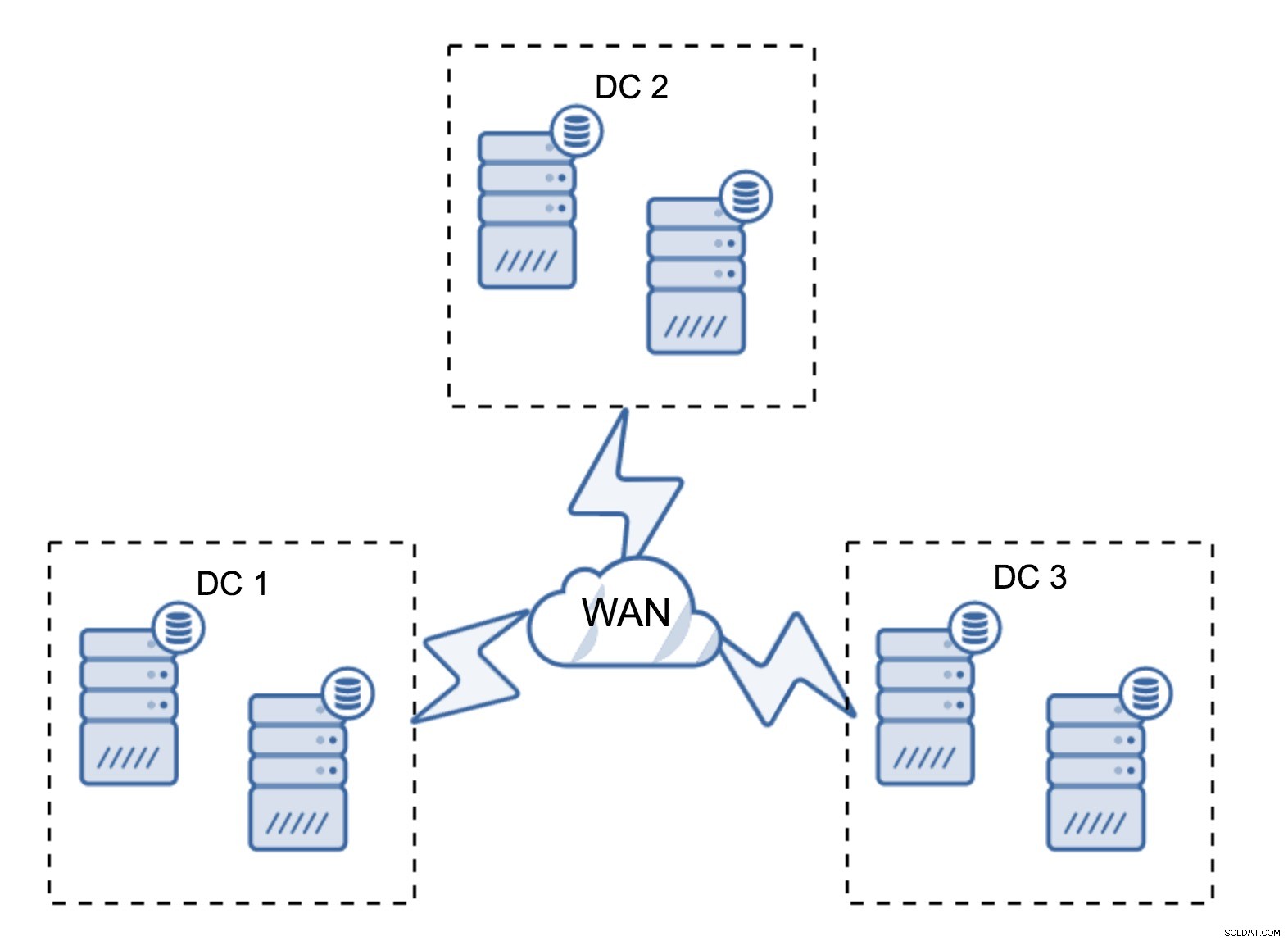
Thiết lập khá điển hình là có sáu nút, hai nút trên mỗi trung tâm dữ liệu. Thiết lập này có vẻ bất ngờ vì nó có số lượng nút chẵn. Tuy nhiên, khi bạn nghĩ về nó, nó có thể không phải là vấn đề quá lớn:rất ít khả năng ba nút sẽ hoạt động cùng một lúc và một thiết lập như vậy sẽ tồn tại khi xảy ra sự cố lên đến hai nút. Toàn bộ trung tâm dữ liệu có thể ngoại tuyến và hai DC còn lại sẽ tiếp tục hoạt động. Nó cũng có một lợi thế lớn so với thiết lập tối thiểu - khi một nút ngoại tuyến, luôn có một nút thứ hai trong trung tâm dữ liệu có thể đóng vai trò là nhà tài trợ. Hầu hết thời gian, mạng WAN sẽ không được sử dụng cho SST.
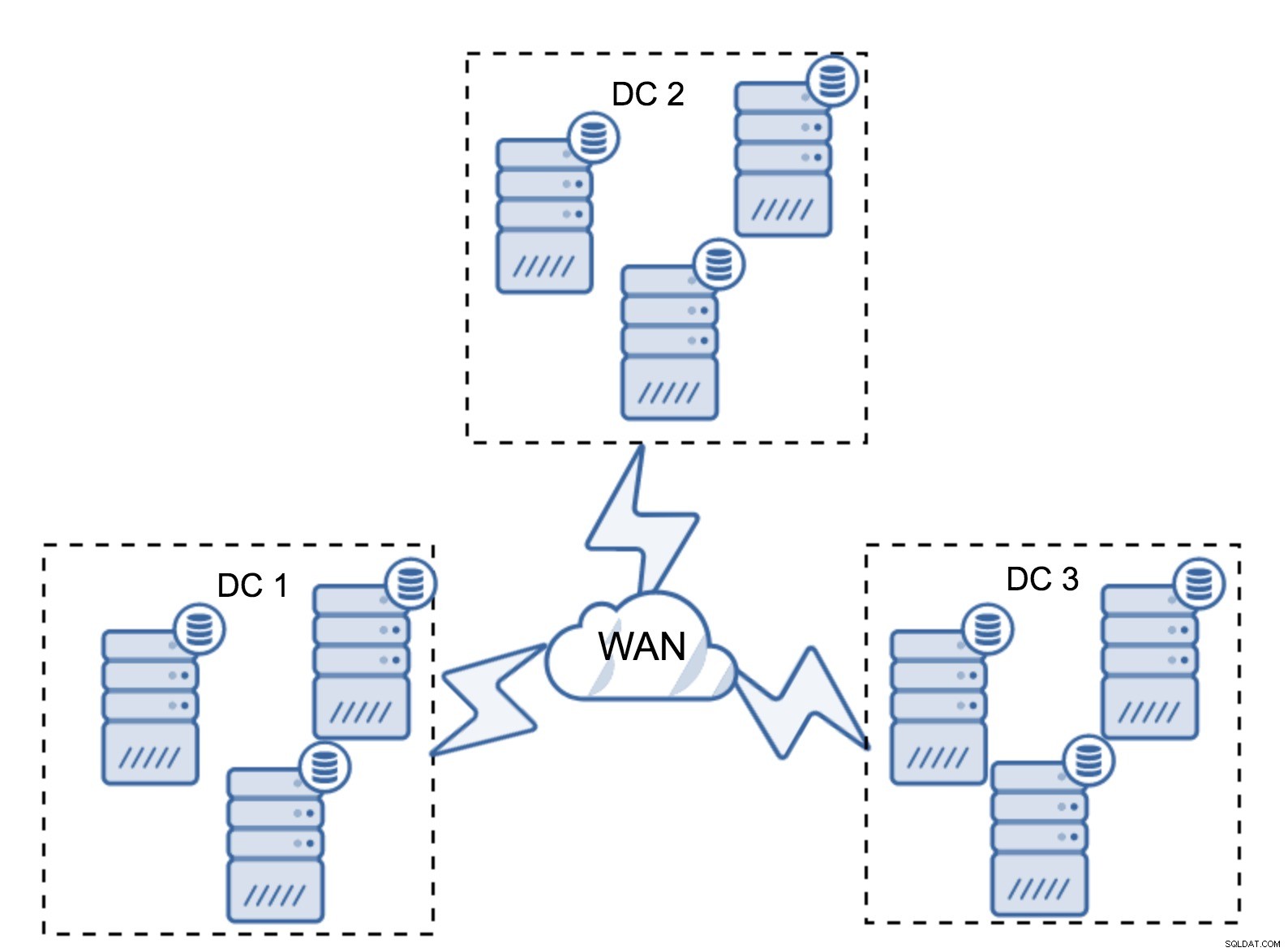
Tất nhiên, bạn có thể tăng số lượng nút lên ba nút trên mỗi cụm, tổng cộng là chín nút. Điều này mang lại cho bạn khả năng sống sót tốt hơn:tối đa bốn nút có thể gặp sự cố và cụm vẫn sẽ tồn tại. Mặt khác, bạn phải lưu ý rằng, ngay cả khi sử dụng các phân đoạn, nhiều nút hơn có nghĩa là chi phí hoạt động cao hơn và bạn chỉ có thể mở rộng cụm Galera ở một mức độ nhất định.
Có thể xảy ra trường hợp không cần trung tâm dữ liệu thứ ba bởi vì, giả sử, ứng dụng của bạn chỉ nằm ở hai trong số đó. Tất nhiên, yêu cầu về ba trung tâm dữ liệu vẫn còn hiệu lực, vì vậy bạn sẽ không đi vòng quanh nó, nhưng bạn hoàn toàn có thể sử dụng Galera Arbitrator (garbd) thay vì các máy chủ cơ sở dữ liệu được tải đầy đủ.
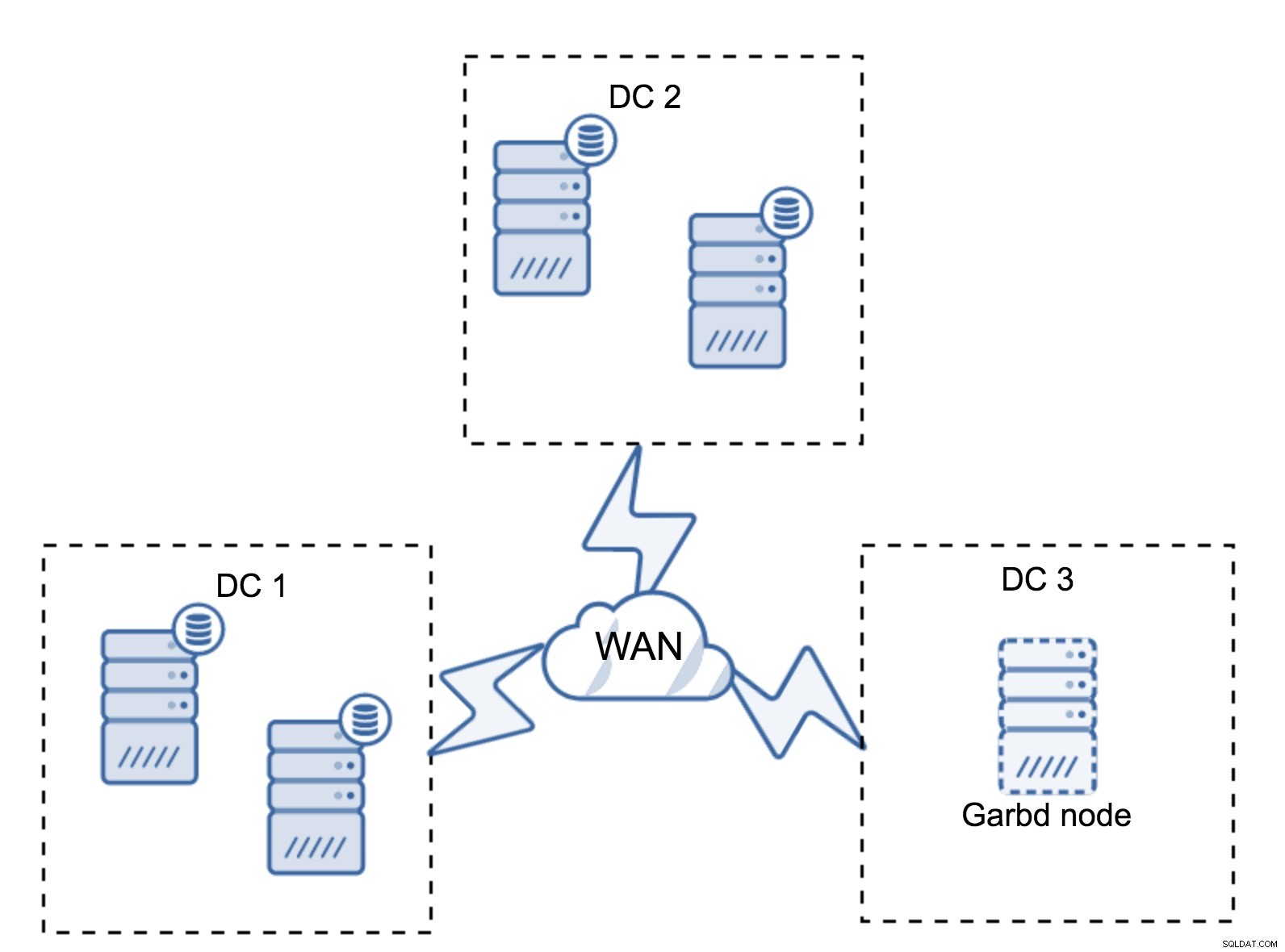
Garbd có thể được cài đặt trên các nút nhỏ hơn, thậm chí cả máy chủ ảo. Nó không yêu cầu phần cứng mạnh mẽ, nó không lưu trữ bất kỳ dữ liệu nào cũng như không áp dụng bất kỳ bộ ghi nào. Nhưng nó thấy tất cả lưu lượng sao chép và tham gia vào tính toán túc số. Nhờ nó, bạn có thể triển khai các thiết lập như bốn nút, hai nút cho mỗi DC + garbd ở nút thứ ba - bạn có tổng cộng năm nút và cụm như vậy có thể chấp nhận tối đa hai lỗi. Vì vậy, nó có nghĩa là nó có thể chấp nhận việc tắt hoàn toàn một trong các trung tâm dữ liệu.
Lựa chọn nào tốt hơn cho bạn? Không có giải pháp tốt nhất cho mọi trường hợp, tất cả phụ thuộc vào yêu cầu cơ sở hạ tầng của bạn. May mắn thay, có các tùy chọn khác nhau để chọn:nhiều hoặc ít nút, đầy đủ 3 DC hoặc 2 DC và chọn lựa chọn thứ ba - rất có thể bạn sẽ tìm thấy thứ gì đó phù hợp với mình.
Độ trễ mạng
Khi làm việc với thiết lập đa DC, bạn phải lưu ý rằng độ trễ mạng sẽ cao hơn đáng kể so với những gì bạn mong đợi từ môi trường mạng cục bộ. Điều này có thể làm giảm nghiêm trọng hiệu suất của cụm Galera khi bạn so sánh nó với phiên bản MySQL độc lập hoặc thiết lập sao chép MySQL. Yêu cầu tất cả các nút phải xác nhận một bộ ghi có nghĩa là tất cả các nút phải nhận nó, bất kể chúng ở xa bao nhiêu. Với sao chép không đồng bộ, không cần phải đợi trước khi thực hiện một cam kết. Tất nhiên, sao chép có những vấn đề và nhược điểm khác, nhưng độ trễ không phải là vấn đề chính. Vấn đề đặc biệt dễ thấy khi cơ sở dữ liệu của bạn có các điểm nóng - hàng, được cập nhật thường xuyên (bộ đếm, hàng đợi, v.v.). Những hàng đó không thể được cập nhật thường xuyên hơn một lần cho mỗi chuyến khứ hồi của mạng. Đối với các cụm trải dài trên toàn cầu, điều này có thể dễ dàng có nghĩa là bạn sẽ không thể cập nhật một hàng thường xuyên hơn 2 - 3 lần mỗi giây. Nếu điều này trở thành hạn chế đối với bạn, điều đó có thể có nghĩa là cụm Galera không phù hợp với khối lượng công việc cụ thể của bạn.
Lớp proxy trong Cụm Galera Đa DC
Không đủ để có cụm Galera trải dài trên nhiều trung tâm dữ liệu, bạn vẫn cần ứng dụng của mình để truy cập chúng. Một trong những phương pháp phổ biến để che giấu sự phức tạp của lớp cơ sở dữ liệu khỏi ứng dụng là sử dụng proxy. Proxy được sử dụng như một điểm vào cơ sở dữ liệu, chúng theo dõi trạng thái của các nút cơ sở dữ liệu và luôn hướng lưu lượng truy cập đến chỉ các nút có sẵn. Trong phần này, chúng tôi sẽ cố gắng đề xuất một thiết kế lớp proxy có thể được sử dụng cho một cụm Galera đa DC. Chúng tôi sẽ sử dụng ProxySQL, mang lại cho bạn sự linh hoạt trong việc xử lý các nút cơ sở dữ liệu, nhưng bạn có thể sử dụng một proxy khác, miễn là nó có thể theo dõi trạng thái của các nút Galera.
Định vị proxy ở đâu?
Tóm lại, có hai mẫu phổ biến ở đây:bạn có thể triển khai ProxySQL trên các nút riêng biệt hoặc bạn có thể triển khai chúng trên máy chủ ứng dụng. Hãy xem xét ưu và nhược điểm của từng cách thiết lập này.
Lớp proxy như một tập hợp Máy chủ riêng biệt
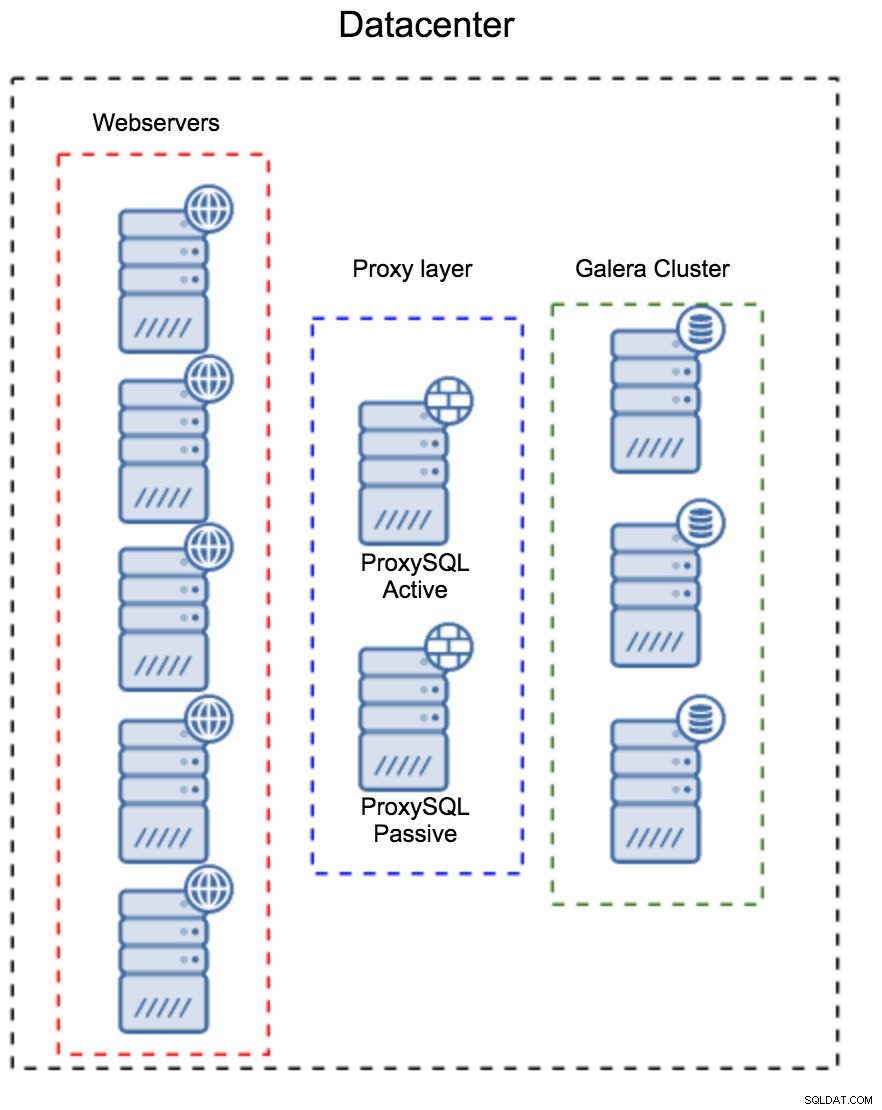
Mô hình đầu tiên là xây dựng một lớp proxy bằng cách sử dụng các máy chủ chuyên dụng, riêng biệt. Bạn có thể triển khai ProxySQL trên một vài máy chủ và sử dụng IP ảo và đủ điều kiện để duy trì tính khả dụng cao. Một ứng dụng sẽ sử dụng VIP để kết nối với cơ sở dữ liệu và VIP sẽ đảm bảo rằng các yêu cầu sẽ luôn được chuyển đến một ProxySQL có sẵn. Vấn đề chính với thiết lập này là bạn sử dụng nhiều nhất một trong các phiên bản ProxySQL - tất cả các nút dự phòng không được sử dụng để định tuyến lưu lượng. Điều này có thể buộc bạn phải sử dụng phần cứng mạnh hơn mức bạn thường sử dụng. Mặt khác, việc duy trì thiết lập sẽ dễ dàng hơn - bạn sẽ phải áp dụng các thay đổi cấu hình trên tất cả các nút ProxySQL, nhưng sẽ chỉ có một số ít trong số đó. Bạn cũng có thể sử dụng tùy chọn của ClusterControl để đồng bộ hóa các nút. Thiết lập như vậy sẽ phải được sao chép trên mọi trung tâm dữ liệu mà bạn sử dụng.
Proxy được cài đặt trên các phiên bản ứng dụng
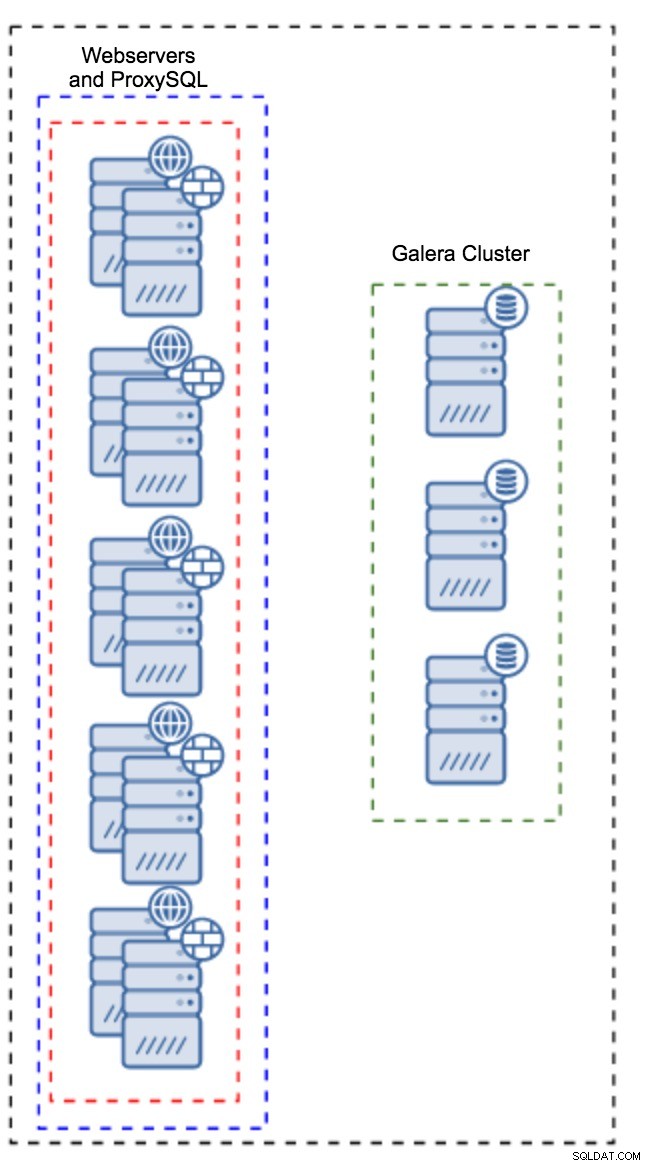
Thay vì có một tập hợp các máy chủ riêng biệt, ProxySQL cũng có thể được cài đặt trên các máy chủ ứng dụng. Ứng dụng sẽ kết nối trực tiếp với ProxySQL trên localhost, thậm chí nó có thể sử dụng unix socket để giảm thiểu chi phí của kết nối TCP. Ưu điểm chính của thiết lập như vậy là bạn có một số lượng lớn các phiên bản ProxySQL và tải được phân bổ đồng đều trên chúng. Nếu một sự cố, chỉ máy chủ ứng dụng đó sẽ bị ảnh hưởng. Các nút còn lại sẽ tiếp tục hoạt động. Vấn đề nghiêm trọng nhất phải đối mặt là quản lý cấu hình. Với một số lượng lớn các nút ProxySQL, điều quan trọng là phải đưa ra một phương pháp tự động để giữ cho cấu hình của chúng được đồng bộ hóa. Bạn có thể sử dụng ClusterControl hoặc một công cụ quản lý cấu hình như Puppet.
Điều chỉnh Galera trong môi trường WAN
Giá trị mặc định của Galera được thiết kế cho mạng cục bộ và nếu bạn muốn sử dụng nó trong môi trường WAN, cần phải điều chỉnh một số. Hãy thảo luận về một số chỉnh sửa cơ bản mà bạn có thể thực hiện. Xin lưu ý rằng việc điều chỉnh chính xác yêu cầu dữ liệu sản xuất và lưu lượng truy cập - bạn không thể chỉ thực hiện một số thay đổi và cho rằng chúng tốt, bạn nên thực hiện đo điểm chuẩn thích hợp.
Cấu hình hệ điều hành
Hãy bắt đầu với cấu hình hệ điều hành. Không phải tất cả các sửa đổi được đề xuất ở đây đều liên quan đến mạng WAN, nhưng bạn nên tự nhắc mình đâu là điểm khởi đầu tốt cho bất kỳ cài đặt MySQL nào.
vm.swappiness = 1Swappiness kiểm soát mức độ tích cực của hệ điều hành sẽ sử dụng hoán đổi. Nó không nên được đặt thành 0 vì trong các hạt nhân gần đây hơn, nó ngăn không cho HĐH sử dụng hoán đổi và nó có thể gây ra các vấn đề nghiêm trọng về hiệu suất.
/sys/block/*/queue/scheduler = deadline/noopBộ lập lịch cho thiết bị khối, mà MySQL sử dụng, nên được đặt thành hạn chót hoặc không. Lựa chọn chính xác phụ thuộc vào điểm chuẩn nhưng cả hai cài đặt sẽ mang lại hiệu suất tương tự, tốt hơn so với công cụ lập lịch mặc định, CFQ.
Đối với MySQL, bạn nên cân nhắc sử dụng EXT4 hoặc XFS, tùy thuộc vào hạt nhân (hiệu suất của các hệ thống tệp đó thay đổi từ phiên bản hạt nhân này sang phiên bản hạt nhân khác). Thực hiện một số điểm chuẩn để tìm tùy chọn tốt hơn cho bạn.
Ngoài ra, bạn có thể muốn xem xét cài đặt mạng sysctl. Chúng tôi sẽ không thảo luận chi tiết về chúng (bạn có thể tìm tài liệu tại đây) nhưng ý tưởng chung là tăng bộ đệm, tồn đọng và thời gian chờ, để giúp dễ dàng cung cấp cho các gian hàng và liên kết WAN không ổn định.
net.core.optmem_max = 40960
net.core.rmem_max = 16777216
net.core.wmem_max = 16777216
net.core.rmem_default = 16777216
net.core.wmem_default = 16777216
net.ipv4.tcp_rmem = 4096 87380 16777216
net.ipv4.tcp_wmem = 4096 87380 16777216
net.core.netdev_max_backlog = 50000
net.ipv4.tcp_max_syn_backlog = 30000
net.ipv4.tcp_congestion_control = htcp
net.ipv4.tcp_mtu_probing = 1
net.ipv4.tcp_max_tw_buckets = 2000000
net.ipv4.tcp_tw_reuse = 1
net.ipv4.tcp_fin_timeout = 30
net.ipv4.tcp_slow_start_after_idle = 0Ngoài việc điều chỉnh hệ điều hành, bạn nên cân nhắc điều chỉnh các cài đặt liên quan đến mạng Galera.
evs.suspect_timeout
evs.inactive_timeoutBạn có thể muốn xem xét việc thay đổi các giá trị mặc định của các biến này. Cả hai thời gian chờ chi phối cách cụm loại bỏ các nút bị lỗi. Thời gian chờ nghi ngờ diễn ra khi tất cả các nút không thể tiếp cận thành viên không hoạt động. Thời gian chờ không hoạt động xác định giới hạn cố định về thời gian một nút có thể ở lại trong cụm nếu nó không phản hồi. Thông thường, bạn sẽ thấy rằng các giá trị mặc định hoạt động tốt. Nhưng trong một số trường hợp, đặc biệt nếu bạn chạy cụm Galera của mình qua WAN (ví dụ:giữa các vùng AWS), việc tăng các biến đó có thể dẫn đến hiệu suất ổn định hơn. Chúng tôi khuyên bạn nên đặt cả hai thành PT1M để giảm khả năng mất ổn định liên kết WAN sẽ ném một nút ra khỏi cụm.
evs.send_window
evs.user_send_windowCác biến này, evs.send_window và evs.user_send_window , xác định số lượng gói có thể được gửi qua nhân rộng cùng một lúc ( evs.send_window ) và bao nhiêu trong số chúng có thể chứa dữ liệu ( evs.user_send_window ). Đối với các kết nối có độ trễ cao, có thể nên tăng các giá trị đó lên đáng kể (ví dụ:512 hoặc 1024).
evs.inactive_check_periodBiến trên cũng có thể được thay đổi. evs.inactive_check_period , theo mặc định, được đặt thành một giây, có thể quá thường xuyên đối với thiết lập mạng WAN. Chúng tôi khuyên bạn nên đặt nó thành PT30S.
gcs.fc_factor
gcs.fc_limitỞ đây, chúng tôi muốn giảm thiểu khả năng kiểm soát luồng phát sinh, do đó, chúng tôi khuyên bạn nên đặt gcs.fc_factor lên 1 và tăng gcs.fc_limit ví dụ:260.
gcs.max_packet_sizeKhi chúng tôi đang làm việc với liên kết WAN, nơi độ trễ cao hơn đáng kể, chúng tôi muốn tăng kích thước của các gói. Điểm khởi đầu tốt sẽ là 2097152.
Như chúng tôi đã đề cập trước đó, hầu như không thể đưa ra một công thức đơn giản về cách đặt các thông số này vì nó phụ thuộc vào quá nhiều yếu tố - bạn sẽ phải thực hiện các điểm chuẩn của riêng mình, sử dụng dữ liệu càng gần với dữ liệu sản xuất càng tốt, trước khi bạn có thể nói hệ thống của bạn đã được điều chỉnh. Phải nói rằng, những cài đặt đó sẽ cung cấp cho bạn điểm bắt đầu để điều chỉnh chính xác hơn.
Đó là nó cho bây giờ. Galera hoạt động khá tốt trong môi trường WAN, vì vậy hãy dùng thử và cho chúng tôi biết cách bạn tiếp tục.