Giới thiệu
Không sớm thì muộn, bất kỳ hệ thống thông tin nào cũng có một cơ sở dữ liệu, thường - nhiều hơn một cơ sở dữ liệu. Cùng với thời gian, cơ sở dữ liệu đó tập hợp rất nhiều dữ liệu, từ vài GB đến hàng chục TB. Để hiểu các chức năng sẽ hoạt động như thế nào với khối lượng dữ liệu ngày càng tăng, chúng tôi cần tạo dữ liệu để lấp đầy cơ sở dữ liệu đó.

Tất cả các tập lệnh được trình bày và triển khai sẽ thực thi trên JobEmplDB cơ sở dữ liệu của một dịch vụ tuyển dụng. Hiện thực hóa cơ sở dữ liệu có sẵn ở đây.
Phương pháp tiếp cận việc điền dữ liệu vào cơ sở dữ liệu để thử nghiệm và phát triển
Việc phát triển và kiểm tra cơ sở dữ liệu liên quan đến hai cách tiếp cận chính để điền dữ liệu:
- Để sao chép toàn bộ cơ sở dữ liệu từ môi trường sản xuất với dữ liệu cá nhân và dữ liệu nhạy cảm khác đã thay đổi. Bằng cách này, bạn đảm bảo dữ liệu và xóa dữ liệu bí mật.
- Để tạo dữ liệu tổng hợp. Điều đó có nghĩa là tạo dữ liệu thử nghiệm tương tự như dữ liệu thực về giao diện, thuộc tính và kết nối.
Ưu điểm của Phương pháp 1 là nó ước tính dữ liệu và sự phân bổ của chúng theo các tiêu chí khác nhau đối với cơ sở dữ liệu sản xuất. Nó cho phép chúng tôi phân tích mọi thứ một cách chính xác và do đó, đưa ra kết luận và tiên lượng phù hợp.
Tuy nhiên, cách làm này không cho phép bạn tự tăng cơ sở dữ liệu lên nhiều lần. Việc dự đoán những thay đổi trong toàn bộ chức năng của hệ thống thông tin trong tương lai trở nên khó khăn.
Mặt khác, bạn có thể phân tích dữ liệu được làm sạch mạo danh được lấy từ cơ sở dữ liệu sản xuất. Dựa trên chúng, bạn có thể xác định cách tạo dữ liệu thử nghiệm giống như dữ liệu thực theo diện mạo, thuộc tính và mối tương quan của chúng. Bằng cách này, Phương pháp 1 tạo ra Phương pháp tiếp cận 2.
Bây giờ, hãy xem xét chi tiết cả hai cách tiếp cận để điền dữ liệu vào cơ sở dữ liệu để thử nghiệm và phát triển.
Sao chép và thay đổi dữ liệu trong cơ sở dữ liệu sản xuất
Trước tiên, hãy xác định thuật toán chung của việc sao chép và thay đổi dữ liệu từ môi trường sản xuất.
Thuật toán chung
Thuật toán chung như sau:
- Tạo một cơ sở dữ liệu trống mới.
- Tạo một lược đồ trong cơ sở dữ liệu mới tạo đó - cùng một hệ thống với hệ thống từ cơ sở dữ liệu sản xuất.
- Sao chép dữ liệu cần thiết từ cơ sở dữ liệu sản xuất vào cơ sở dữ liệu mới được tạo.
- Vệ sinh và thay đổi dữ liệu bí mật trong cơ sở dữ liệu mới.
- Tạo một bản sao lưu của cơ sở dữ liệu mới được tạo.
- Phân phối và khôi phục bản sao lưu trong môi trường cần thiết.
Tuy nhiên, thuật toán trở nên phức tạp hơn sau bước 5. Ví dụ:bước 6 yêu cầu một môi trường cụ thể, được bảo vệ để thử nghiệm sơ bộ. Giai đoạn đó phải đảm bảo rằng tất cả dữ liệu là ẩn và dữ liệu bí mật được thay đổi.
Sau giai đoạn đó, bạn có thể quay lại bước 5 một lần nữa cho cơ sở dữ liệu đã thử nghiệm trong môi trường phi sản xuất được bảo vệ. Sau đó, bạn chuyển tiếp bản sao lưu đã thử nghiệm đến các môi trường cần thiết để khôi phục nó và sử dụng nó để phát triển và thử nghiệm.
Chúng tôi đã trình bày thuật toán chung về việc sao chép và thay đổi dữ liệu của cơ sở dữ liệu sản xuất. Hãy mô tả cách triển khai nó.
Thực hiện thuật toán chung
Tạo cơ sở dữ liệu trống mới
Bạn có thể tạo một cơ sở dữ liệu trống với sự trợ giúp của việc xây dựng TẠO CƠ SỞ DỮ LIỆU như ở đây.
Cơ sở dữ liệu có tên JobEmplDB_Test . Nó có ba nhóm tệp:
- CHÍNH TẢ - nó là nhóm tệp chính theo mặc định. Nó xác định hai tệp: JobEmplDB_Test1 (đường dẫn D:\ DBData \ JobEmplDB_Test1.mdf) và JobEmplDB_Test2 (đường dẫn D:\ DBData \ JobEmplDB_Test2.ndf) . Kích thước ban đầu của mỗi tệp là 64 Mb và bước tăng trưởng là 8 Mb cho mỗi tệp.
- Nhóm DBTable - nhóm tệp tùy chỉnh xác định hai tệp: JobEmplDB_TestTableGroup1 (đường dẫn D:\ DBData \ JobEmplDB_TestTableGroup1.ndf) và JobEmplDB_TestTableGroup2 (đường dẫn D:\ DBData \ JobEmplDB_TestTableGroup2.ndf) . Kích thước ban đầu của mỗi tệp là 8 Gb và bước tăng trưởng là 1 Gb cho mỗi tệp.
- DBIndexGroup - nhóm tệp tùy chỉnh xác định hai tệp: JobEmplDB_TestIndexGroup1 (đường dẫn D:\ DBData \ JobEmplDB_TestIndexGroup1.ndf) và JobEmplDB_TestIndexGroup2 (đường dẫn D:\ DBData \ JobEmplDB_TestIndexGroup2.ndf) . Kích thước ban đầu là 16 Gb cho mỗi tệp và bước tăng trưởng là 1 Gb cho mỗi tệp.
Ngoài ra, cơ sở dữ liệu này bao gồm một tạp chí giao dịch: JobEmplDB_Testlog , đường dẫn E:\ DBLog \ JobEmplDB_Testlog.ldf . Kích thước ban đầu của tệp là 8 Gb và bước tăng trưởng là 1 Gb.
Sao chép sơ đồ và dữ liệu cần thiết từ cơ sở dữ liệu sản xuất vào cơ sở dữ liệu mới được tạo
Để sao chép sơ đồ và dữ liệu cần thiết từ cơ sở dữ liệu sản xuất sang cơ sở dữ liệu mới, bạn có thể sử dụng một số công cụ. Đầu tiên, đó là Visual Studio (SSDT). Hoặc, bạn có thể sử dụng các tiện ích của bên thứ ba như:
- So sánh lược đồ DbForge và So sánh dữ liệu DbForge
- ApexSQL Diff và Apex Data Diff
- Công cụ so sánh SQL và Công cụ so sánh dữ liệu SQL
Tạo tập lệnh để thay đổi dữ liệu
Yêu cầu thiết yếu đối với tập lệnh của thay đổi dữ liệu
1. Không thể khôi phục dữ liệu thực bằng cách sử dụng tập lệnh đó.
ví dụ:đảo ngược của các đường sẽ không phù hợp, vì nó cho phép chúng tôi khôi phục dữ liệu thực. Thông thường, phương pháp là thay thế từng ký tự hoặc byte bằng ký tự hoặc byte giả ngẫu nhiên. Ngày và giờ cũng vậy.
2. Việc thay đổi dữ liệu không được làm thay đổi tính chọn lọc của các giá trị của chúng.
Sẽ không hiệu quả nếu chỉ định NULL cho trường của bảng. Thay vào đó, bạn phải đảm bảo rằng các giá trị giống nhau trong dữ liệu thực sẽ được giữ nguyên trong dữ liệu đã thay đổi. Ví dụ:trong dữ liệu thực, bạn có giá trị 103785 được tìm thấy 12 lần trong bảng. Khi bạn thay đổi giá trị này trong dữ liệu đã thay đổi, giá trị mới phải duy trì 12 lần trong cùng các trường của bảng.
3. Kích thước và độ dài của các giá trị không được khác biệt đáng kể trong dữ liệu đã thay đổi. Ví dụ:bạn thay thế từng byte hoặc ký tự bằng byte hoặc ký tự giả ngẫu nhiên. Chuỗi ban đầu vẫn giữ nguyên kích thước và độ dài.
4. Các mối tương quan trong dữ liệu không được phá vỡ sau các thay đổi. Nó liên quan đến các khóa bên ngoài và tất cả các trường hợp khác mà bạn tham chiếu đến dữ liệu đã thay đổi. Dữ liệu đã thay đổi phải giữ nguyên quan hệ với dữ liệu thực.
Triển khai tập lệnh thay đổi dữ liệu
Bây giờ, hãy xem xét trường hợp cụ thể của dữ liệu thay đổi thành phi cá nhân hóa và ẩn thông tin bí mật. Mẫu là cơ sở dữ liệu tuyển dụng.
Cơ sở dữ liệu mẫu bao gồm các dữ liệu cá nhân sau đây mà bạn cần cá nhân hóa:
- Họ và tên;
- Ngày sinh;
- Ngày cấp thẻ ID;
- Chứng chỉ truy cập từ xa dưới dạng chuỗi byte;
- Phí dịch vụ để tiếp tục quảng cáo.
Trước tiên, chúng tôi sẽ kiểm tra các ví dụ đơn giản cho từng loại dữ liệu được thay đổi:
- Thay đổi ngày và giờ;
- Thay đổi giá trị số;
- Thay đổi trình tự byte;
- Thay đổi dữ liệu ký tự.
Thay đổi ngày và giờ
Bạn có thể lấy một ngày và giờ ngẫu nhiên bằng cách sử dụng tập lệnh sau:
DECLARE @dt DATETIME;
SET @dt = CAST(CAST(@StartDate AS FLOAT) + (CAST(@FinishDate AS FLOAT) - CAST(@StartDate AS FLOAT)) * RAND(CHECKSUM(NEWID())) AS DATETIME);
Đây, @StartDate và @FinishDate là giá trị bắt đầu và giá trị kết thúc của phạm vi. Chúng tương ứng tương ứng với ngày và giờ giả ngẫu nhiên.
Để tạo những dữ liệu này, bạn sử dụng các chức năng hệ thống RAND, CHECKSUM và NEWID.
UPDATE [dbo].[Employee]
SET [DocDate] = CAST(CAST(CAST(CAST([BirthDate] AS DATETIME) AS FLOAT) + (CAST(GETDATE() AS FLOAT) - CAST(CAST([BirthDate] AS DATETIME) AS FLOAT)) * RAND(CHECKSUM(NEWID())) AS DATETIME) AS DATE);
Trường [DocDate] là viết tắt của ngày phát hành tài liệu. Chúng tôi thay thế nó bằng một ngày giả danh, lưu ý các phạm vi của ngày và các giới hạn của chúng.
Giới hạn "dưới cùng" là ngày sinh của ứng viên. Cạnh "trên" là ngày hiện tại. Chúng tôi không cần thời gian ở đây, vì vậy cuối cùng thì việc chuyển đổi định dạng ngày và giờ thành ngày cần thiết. Bạn có thể nhận các giá trị giả ngẫu nhiên cho bất kỳ phần nào của ngày và giờ theo cùng một cách.
Thay đổi giá trị số
Bạn có thể nhận được một số nguyên ngẫu nhiên với sự trợ giúp của tập lệnh sau:
DECLARE @Int INT;
SET @Int = CAST(((@MaxVal + 1) - @MinVal) *
RAND(CHECKSUM(NEWID())) + @MinVal AS INT);
@MinVal и @MaxVal là giá trị của dải ô bắt đầu và kết thúc cho việc tạo số giả ngẫu nhiên. Chúng tôi tạo nó bằng cách sử dụng các chức năng hệ thống RAND, CHECKSUM và NEWID.
UPDATE [dbo].[Employee]
SET [CountRequest] = CAST(((@MaxVal + 1) - @MinVal) *
RAND(CHECKSUM(NEWID())) + @MinVal AS INT);
Trường [CountRequest] là viết tắt của số lượng yêu cầu mà các công ty đưa ra đối với sơ yếu lý lịch của ứng viên này.
Tương tự, bạn có thể nhận các giá trị giả ngẫu nhiên cho bất kỳ giá trị số nào. Ví dụ:xem số ngẫu nhiên của kiểu thập phân (18,2) thế hệ:
DECLARE @Dec DECIMAL(18,2);
SET @Dec=CAST(((@MaxVal + 1) - @MinVal) *
RAND(CHECKSUM(NEWID())) + @MinVal AS DECIMAL(18,2));
Do đó, bạn có thể cập nhật phí dịch vụ khuyến mãi hồ sơ theo cách sau:
UPDATE [dbo].[Employee]
SET [PaymentAmount] = CAST(((@MaxVal + 1) - @MinVal) *
RAND(CHECKSUM(NEWID())) + @MinVal AS DECIMAL(18,2));
Thay đổi chuỗi byte
Bạn có thể nhận một chuỗi byte ngẫu nhiên bằng cách sử dụng tập lệnh sau:
DECLARE @res VARBINARY(MAX);
SET @res = CRYPT_GEN_RANDOM(@Length, CAST(NEWID() AS VARBINARY(16)));
@Length là viết tắt của độ dài của trình tự. Nó xác định số byte được trả về. Ở đây, @Length không được lớn hơn 16.
Quá trình tạo được thực hiện với sự trợ giúp của các chức năng hệ thống CRYPT_GEN_RANDOM và NEWID.
Ví dụ:bạn có thể cập nhật chứng chỉ truy cập từ xa cho từng ứng viên theo cách sau:
UPDATE [dbo].[Employee]
SET [RemoteAccessCertificate] = CRYPT_GEN_RANDOM(CAST(LEN([RemoteAccessCertificate]) AS INT), CAST(NEWID() AS VARBINARY(16)));
Chúng tôi tạo chuỗi byte giả ngẫu nhiên có cùng độ dài có trong trường [RemoteAccessCertificate] tại thời điểm thay đổi. Chúng tôi giả sử rằng độ dài chuỗi byte không vượt quá 16.
Tương tự, chúng ta có thể tạo hàm của mình để trả về chuỗi byte giả ngẫu nhiên có độ dài bất kỳ. Nó sẽ đặt các kết quả của hàm hệ thống CRYPT_GEN_RANDOM cùng hoạt động bằng cách sử dụng toán tử cộng “+” đơn giản. Nhưng 16 byte thường là đủ trong thực tế.
Hãy tạo một hàm mẫu trả về chuỗi byte giả ngẫu nhiên có độ dài xác định, trong đó bạn có thể đặt độ dài hơn 16 byte. Đối với điều này, hãy trình bày sau:
CREATE VIEW [test].[GetNewID]
AS
SELECT NEWID() AS [NewID];
GO
Chúng tôi cần nó để tránh giới hạn cấm chúng tôi sử dụng NEWID trong hàm.
Theo cách tương tự, hãy tạo bản trình bày tiếp theo cho cùng mục đích:
CREATE VIEW [test].[GetRand]
AS
SELECT RAND(CHECKSUM((SELECT TOP(1) [NewID] FROM [test].[GetNewID]))) AS [Value];
GO
Tạo thêm một bản trình bày:
CREATE VIEW [test].[GetRandVarbinary16]
AS
SELECT CRYPT_GEN_RANDOM(16, CAST((SELECT TOP(1) [NewID] FROM [test].[GetNewID]) AS VARBINARY(16))) AS [Value];
GO
Tất cả các định nghĩa của ba chức năng đều có ở đây. Và đây là việc triển khai hàm trả về một chuỗi byte giả ngẫu nhiên có độ dài xác định.
Đầu tiên, chúng tôi xác định xem chức năng cần thiết có xuất hiện hay không. Nếu không - chúng tôi tạo một stud trước. Trong mọi trường hợp, mã liên quan đến việc thay đổi định nghĩa của hàm một cách thích hợp. Cuối cùng, chúng tôi thêm mô tả của hàm thông qua các thuộc tính mở rộng. Thông tin chi tiết về tài liệu của cơ sở dữ liệu có trong bài viết này.
Để cập nhật chứng chỉ truy cập từ xa cho từng ứng viên, bạn có thể làm như sau:
UPDATE [dbo].[Employee]
SET [RemoteAccessCertificate] = [test].[GetRandVarbinary](CAST(LEN([RemoteAccessCertificate]) AS INT));
Như bạn thấy, không có giới hạn nào đối với độ dài chuỗi byte ở đây.
Thay đổi dữ liệu - Thay đổi dữ liệu ký tự
Ở đây, chúng tôi lấy một ví dụ cho bảng chữ cái tiếng Anh và tiếng Nga, nhưng bạn có thể làm điều đó cho bất kỳ bảng chữ cái nào khác. Điều kiện duy nhất là các ký tự của nó phải có trong các kiểu NCHAR.
Chúng ta cần tạo một hàm chấp nhận dòng, thay thế mọi ký tự bằng một ký tự giả ngẫu nhiên, sau đó ghép kết quả lại với nhau và trả về.
Tuy nhiên, trước tiên chúng ta cần hiểu chúng ta cần những ký tự nào. Để làm được điều đó, chúng ta có thể thực thi tập lệnh sau:
DECLARE @tbl TABLE ([ValueInt] INT, [ValueNChar] NCHAR(1), [ValueChar] CHAR(1));
DECLARE @ind int=0;
DECLARE @count INT=65535;
WHILE(@count>=0)
BEGIN
INSERT INTO @tbl ([ValueInt], [ValueNChar], [ValueChar])
SELECT @ind, NCHAR(@ind), CHAR(@ind)
SET @ind+=1;
SET @count-=1;
END
SELECT *
INTO [test].[TblCharactersCode]
FROM @tbl;
Chúng tôi đang tạo bảng [test]. [TblCharacterCode] bao gồm các trường sau:
- ValueInt - giá trị số của ký tự;
- ValueNChar - ký tự kiểu NCHAR;
- ValueChar - ký tự kiểu CHAR.
Hãy xem lại nội dung của bảng này. Chúng tôi cần yêu cầu sau:
SELECT [ValueInt]
,[ValueNChar]
,[ValueChar]
FROM [test].[TblCharactersCode];
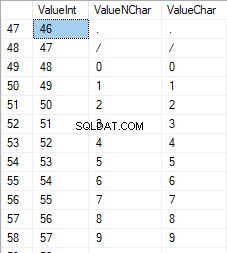
Các số nằm trong khoảng từ 48 đến 57:
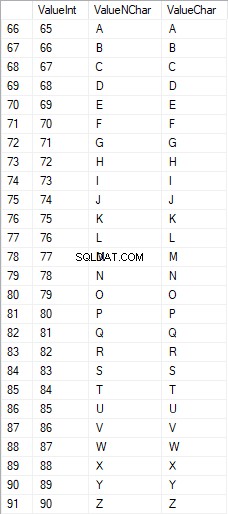
Các ký tự Latinh viết hoa nằm trong khoảng từ 65 đến 90:
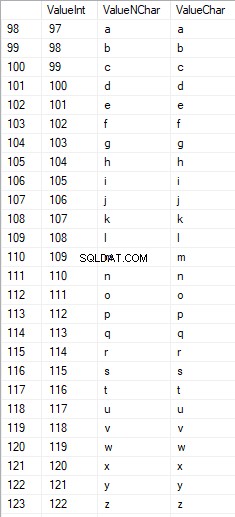
Các ký tự Latinh ở phần cẩn thận thấp hơn nằm trong khoảng từ 97 đến 122:
Các ký tự viết hoa trong tiếng Nga nằm trong khoảng từ 1040 đến 1071:

Các ký tự tiếng Nga ở dạng chữ thường nằm trong khoảng từ 1072 đến 1103:


Và, các ký tự trong phạm vi từ 58 đến 64:

Chúng tôi chọn các ký tự cần thiết và đưa chúng vào bảng [test]. [SelectCharactersCode] theo cách sau:
SELECT
[ValueInt]
,[ValueNChar]
,[ValueChar]
,CASE
WHEN ([ValueInt] BETWEEN 48 AND 57) THEN 1
ELSE 0
END AS [IsNumeral]
,CASE
WHEN (([ValueInt] BETWEEN 65 AND 90) OR
([ValueInt] BETWEEN 1040 AND 1071)) THEN 1
ELSE 0
END AS [IsUpperCase]
,CASE
WHEN (([ValueInt] BETWEEN 65 AND 90) OR
([ValueInt] BETWEEN 97 AND 122)) THEN 1
ELSE 0
END AS [IsLatin]
,CASE
WHEN (([ValueInt] BETWEEN 1040 AND 1071) OR
([ValueInt] BETWEEN 1072 AND 1103)) THEN 1
ELSE 0
END AS [IsRus]
,CASE
WHEN (([ValueInt] BETWEEN 33 AND 47) OR
([ValueInt] BETWEEN 58 AND 64)) THEN 1
ELSE 0
END AS [IsExtra]
INTO [test].[SelectCharactersCode]
FROM [test].[TblCharactersCode]
WHERE ([ValueInt] BETWEEN 48 AND 57)
OR ([ValueInt] BETWEEN 65 AND 90)
OR ([ValueInt] BETWEEN 97 AND 122)
OR ([ValueInt] BETWEEN 1040 AND 1071)
OR ([ValueInt] BETWEEN 1072 AND 1103)
OR ([ValueInt] BETWEEN 33 AND 47)
OR ([ValueInt] BETWEEN 58 AND 64);
Bây giờ, hãy kiểm tra nội dung của bảng này bằng cách sử dụng tập lệnh sau:
SELECT [ValueInt]
,[ValueNChar]
,[ValueChar]
,[IsNumeral]
,[IsUpperCase]
,[IsLatin]
,[IsRus]
,[IsExtra]
FROM [test].[SelectCharactersCode];
Chúng tôi nhận được kết quả sau:

Bằng cách này, chúng tôi có [test]. [SelectCharactersCode] bảng, trong đó:
- ValueInt - giá trị số của ký tự
- ValueNChar - ký tự kiểu NCHAR
- ValueChar - ký tự kiểu CHAR
- IsNumeral - tiêu chí của một ký tự là một chữ số
- IsUpperCase - tiêu chí của một ký tự viết hoa
- IsLatin - tiêu chí của một ký tự là một ký tự Latinh;
- IsRus - tiêu chí của một nhân vật là một nhân vật Nga
- IsExtra - tiêu chí của một nhân vật là một nhân vật bổ sung
Bây giờ, chúng ta có thể lấy mã để chèn các ký tự cần thiết. Ví dụ:đây là cách thực hiện đối với các ký tự Latinh trong chữ thường:
SELECT 'SELECT '+CAST([ValueInt] AS NVARCHAR(255))+' AS [ValueInt], '+''''+[ValueNChar]+''''+' AS [ValueNChar], '+''''+[ValueChar]+''''+' AS [ValueChar] UNION ALL'
FROM [test].[SelectCharactersCode]
WHERE [IsUpperCase]=0
AND [IsLatin]=1;
Chúng tôi nhận được kết quả sau:

Các ký tự tiếng Nga ở dạng chữ thường cũng vậy:
SELECT 'SELECT '+CAST([ValueInt] AS NVARCHAR(255))+' AS [ValueInt], '+''''+[ValueNChar]+''''+' AS [ValueNChar], '+COALESCE(''''+[ValueChar]+'''', 'NULL')+' AS [ValueChar] UNION ALL'
FROM [test].[SelectCharactersCode]
WHERE [IsUpperCase]=0
AND [IsRus]=1;
Chúng tôi nhận được kết quả sau:

Nó cũng giống như vậy đối với các ký tự:
SELECT 'SELECT '+CAST([ValueInt] AS NVARCHAR(255))+' AS [ValueInt], '+''''+[ValueNChar]+''''+' AS [ValueNChar], '+''''+[ValueChar]+''''+' AS [ValueChar] UNION ALL'
FROM [test].[SelectCharactersCode]
WHERE [IsNumeral]=1;
Kết quả như sau:

Vì vậy, chúng tôi có các mã để chèn dữ liệu sau một cách riêng biệt:
- Các ký tự Latinh ở dạng viết thường.
- Các ký tự tiếng Nga ở dạng viết thường.
- Các chữ số.
Nó hoạt động cho cả kiểu NCHAR và CHAR.
Tương tự, chúng ta có thể chuẩn bị một tập lệnh chèn cho bất kỳ bộ ký tự nào. Bên cạnh đó, mỗi bộ sẽ có chức năng lập bảng riêng.
Để đơn giản, chúng tôi triển khai hàm lập bảng chung sẽ trả về tập dữ liệu cần thiết cho dữ liệu đã chọn trước đó theo cách sau:
SELECT
'SELECT ' + CAST([ValueInt] AS NVARCHAR(255)) + ' AS [ValueInt], '
+ '''' + [ValueNChar] + '''' + ' AS [ValueNChar], '
+ COALESCE('''' + [ValueChar] + '''', ‘NULL’) + ' AS [ValueChar], '
+ CAST([IsNumeral] AS NCHAR(1)) + ' AS [IsNumeral], ' +
+CAST([IsUpperCase] AS NCHAR(1)) + ' AS [IsUpperCase], ' +
+CAST([IsLatin] AS NCHAR(1)) + ' AS [IsLatin], ' +
+CAST([IsRus] AS NCHAR(1)) + ' AS [IsRus], ' +
+CAST([IsExtra] AS NCHAR(1)) + ' AS [IsExtra]' +
+' UNION ALL'
FROM [test].[SelectCharactersCode];
Kết quả cuối cùng như sau:

Tập lệnh sẵn sàng được gói gọn trong hàm lập bảng [test]. [GetSelectCharacters].
Điều quan trọng là phải xóa thêm UNION ALL ở cuối tập lệnh được tạo và trong [ValueInt] =39, chúng tôi cần thay đổi ”’ thành ””:
SELECT 39 AS [ValueInt], '''' AS [ValueNChar], '''' AS [ValueChar], 0 AS [IsNumeral], 0 AS [IsUpperCase], 0 AS [IsLatin], 0 AS [IsRus], 1 AS [IsExtra] UNION ALLHàm lập bảng này trả về tập hợp các trường sau:
- Không - số dòng trong tập dữ liệu được trả về;
- ValueInt - giá trị số của ký tự;
- ValueNChar - ký tự kiểu NCHAR;
- ValueChar - ký tự kiểu CHAR;
- IsNumeral - tiêu chí của ký tự là một chữ số;
- IsUpperCase - tiêu chí xác định rằng ký tự được viết hoa;
- IsLatin - tiêu chí xác định rằng ký tự đó là ký tự Latinh;
- IsRus - tiêu chí xác định rằng nhân vật đó là một nhân vật Nga;
- IsExtra - tiêu chí xác định rằng nhân vật là một nhân vật phụ.
Đối với đầu vào, bạn có các tham số sau:
- @IsNumeral - nếu nó phải trả về các số;
- @IsUpperCase :
- 0 - nó chỉ phải trả về chữ thường cho các chữ cái;
- 1 - nó chỉ được trả về các chữ cái viết hoa;
- NULL - nó phải trả về các chữ cái trong mọi trường hợp.
- @IsLatin - nó phải trả về các ký tự Latinh
- @IsRus - nó phải trả về các ký tự tiếng Nga
- @IsExtra - nó phải trả về các ký tự bổ sung.
Tất cả các cờ được sử dụng theo OR logic. Ví dụ:nếu bạn cần trả lại các chữ số và ký tự Latinh ở dạng chữ thường, bạn gọi hàm lập bảng theo cách sau:
Chúng tôi nhận được kết quả sau:
declare
@IsNumeral BIT=1
,@IsUpperCase BIT=0
,@IsLatin BIT=1
,@IsRus BIT=0
,@IsExtra BIT=0;
SELECT *
FROM [test].[GetSelectCharacters](@IsNumeral, @IsUpperCase, @IsLatin, @IsRus, @IsExtra);
Chúng tôi nhận được kết quả sau:

Chúng tôi triển khai hàm [test]. [GetRandString] sẽ thay thế dòng bằng các ký tự giả ngẫu nhiên, giữ nguyên độ dài chuỗi ban đầu. Chức năng này phải bao gồm khả năng chỉ hoạt động những ký tự là chữ số. Ví dụ:nó có thể hữu ích khi bạn thay đổi số và sê-ri của thẻ ID.
Khi chúng tôi triển khai hàm [test]. [GetRandString], trước tiên, chúng tôi nhận được tập hợp các ký tự cần thiết để tạo một dòng giả ngẫu nhiên có độ dài được chỉ định trong tham số đầu vào @Length. Phần còn lại của các tham số hoạt động như mô tả ở trên.
Sau đó, chúng tôi đặt tập dữ liệu đã nhận vào biến lập bảng @tbl . Bảng này lưu các trường [ID] - số thứ tự trong bảng ký tự kết quả và [Giá trị] - bản trình bày của ký tự trong kiểu NCHAR.
Sau đó, trong một chu kỳ, nó tạo ra một số giả ngẫu nhiên trong phạm vi từ 1 đến số lượng ký tự @tbl đã nhận trước đó. Chúng tôi đặt số này vào [ID] của biến lập bảng @tbl để tìm kiếm. Khi tìm kiếm trả về dòng, chúng tôi lấy ký tự [Giá trị] và "gắn" nó vào dòng kết quả @res.
Khi công việc của chu kỳ kết thúc, dòng đã nhận được quay trở lại thông qua biến @res.
Bạn có thể thay đổi cả họ và tên của ứng viên theo cách sau:
UPDATE [dbo].[Employee]
SET [FirstName] = [test].[GetRandString](LEN([FirstName])),
[LastName] = [test].[GetRandString](LEN([LastName]));
Do đó, chúng tôi đã kiểm tra việc triển khai chức năng và việc sử dụng nó cho các loại NCHAR và NVARCHAR. Chúng ta có thể làm điều tương tự một cách dễ dàng đối với các loại CHAR và VARCHAR.
Tuy nhiên, đôi khi chúng ta cần tạo một dòng theo các ký tự đã đặt, không phải các ký tự chữ cái hoặc số. Theo cách này, trước tiên chúng ta cần sử dụng hàm đa toán tử sau [test]. [GetListCharacters].
Hàm [test]. [GetListCharacters] nhận hai tham số sau cho đầu vào:
- @str - dòng ký tự của chính nó;
- @IsGroupUnique - nó xác định xem nó có cần nhóm các ký tự duy nhất trong dòng hay không.
Với CTE đệ quy, dòng nhập @str được chuyển thành bảng ký tự - @ListCharacters. Bảng đó chứa các trường sau:
- ID - số thứ tự của dòng trong bảng ký tự kết quả;
- Nhân vật - sự trình bày của nhân vật trong NCHAR (1)
- Đếm - số lần lặp lại của ký tự trong dòng (luôn là 1 nếu tham số @ IsGroupUnique =0)
Hãy lấy hai ví dụ về cách sử dụng của chức năng này để hiểu rõ hơn về công việc của nó:
- Chuyển đổi dòng thành danh sách các ký tự không phải là duy nhất:
SELECT *
FROM [test].[GetListCharacters]('123456888 789 0000', 0);
Chúng tôi nhận được kết quả:

Ví dụ này cho thấy rằng dòng được chuyển đổi thành danh sách các ký tự “nguyên trạng” mà không nhóm nó theo tính duy nhất của các ký tự (trường [Count] luôn chứa 1).
- Sự chuyển đổi dòng thành danh sách các ký tự duy nhất
SELECT *
FROM [test].[GetListCharacters]('123456888 789 0000', 1);
Kết quả như sau:
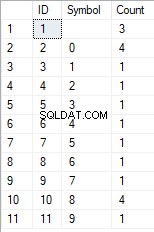
Ví dụ này cho thấy rằng dòng được chuyển thành danh sách các ký tự được nhóm theo tính duy nhất của chúng. Trường [Đếm] hiển thị số lượng kết quả của mỗi ký tự trong dòng nhập.
Dựa trên hàm đa toán tử [test]. [GetListCharacters], chúng tôi tạo một hàm vô hướng [test]. [GetRandString2].
Định nghĩa của hàm vô hướng mới cho thấy sự giống nhau của nó với hàm vô hướng [test]. [GetRandString]. Điểm khác biệt duy nhất là nó sử dụng hàm đa toán tử [test]. [GetListCharacters] thay vì [test]. Hàm lập bảng [GetSelectCharacters].
Sau đây, hãy xem lại hai ví dụ về cách sử dụng hàm vô hướng được triển khai :
Chúng tôi tạo một dòng giả ngẫu nhiên có độ dài 12 ký tự từ dòng đầu vào của các ký tự không được nhóm theo tính duy nhất:
SELECT [test].[GetRandString2](12, '123456789!!!!!!!!0!!!', DEFAULT);Kết quả là:
64017 !! 5 !!! 7
Từ khóa là DEFAULT. Nó nói rằng giá trị mặc định đặt tham số. Đây, nó là số không (0).
Hoặc
Chúng tôi tạo một dòng giả ngẫu nhiên có độ dài 12 ký tự từ dòng đầu vào của các ký tự được nhóm theo tính duy nhất:
SELECT [test].[GetRandString2](12, '123456789!!!!!!!!0!!!', 1);Kết quả là:
35792! 428273
Triển khai tập lệnh chung để làm sạch dữ liệu và thay đổi dữ liệu bí mật
Chúng tôi đã xem xét các ví dụ đơn giản cho từng loại dữ liệu được thay đổi:
- Thay đổi ngày và giờ;
- Thay đổi giá trị số;
- Thay đổi chuỗi byte;
- Thay đổi dữ liệu của các ký tự.
Tuy nhiên, những ví dụ này không đáp ứng tiêu chí 2 và 3 cho các tập lệnh thay đổi dữ liệu:
- Tiêu chí 2 :tính chọn lọc của các giá trị sẽ không thay đổi đáng kể trong dữ liệu đã thay đổi. Bạn không thể sử dụng NULL cho trường của bảng. Thay vào đó, bạn phải đảm bảo rằng các giá trị dữ liệu thực giống nhau được giữ nguyên trong dữ liệu đã thay đổi. Ví dụ:nếu dữ liệu thực chứa giá trị 103785 12 lần trong trường của bảng có thể thay đổi, thì dữ liệu đã sửa đổi phải bao gồm một giá trị (đã thay đổi) khác được tìm thấy 12 lần trong cùng một trường của bảng.
- Tiêu chí 3 :độ dài và kích thước của các giá trị không được thay đổi đáng kể trong dữ liệu đã thay đổi. Ví dụ:bạn thay thế mỗi ký tự / byte bằng một ký tự / byte giả ngẫu nhiên.
Do đó, chúng tôi cần tạo một tập lệnh xem xét tính chọn lọc của các giá trị trong các trường của bảng.
Hãy xem cơ sở dữ liệu của chúng tôi về dịch vụ tuyển dụng. Như chúng ta thấy, dữ liệu cá nhân chỉ hiển thị trong bảng của ứng viên [dbo]. [Nhân viên].
Giả sử rằng bảng bao gồm các trường sau:
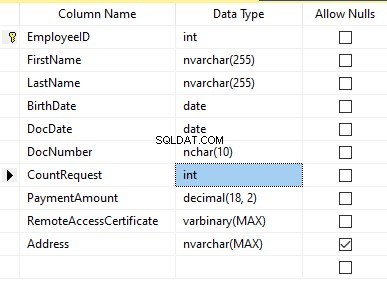
Mô tả:
- FirstName - tên, dòng NVARCHAR (255)
- LastName - họ, dòng NVARCHAR (255)
- Ngày sinh - ngày sinh, DATE
- DocNumber - số thẻ căn cước có hai chữ số ở đầu cho sê-ri hộ chiếu và bảy chữ số tiếp theo là số của tài liệu. Giữa chúng, chúng ta có một dấu gạch nối là dòng NCHAR (10).
- DocDate - ngày cấp thẻ ID, DATE
- Yêu cầu đếm - số lượng yêu cầu cho ứng viên đó trong quá trình tìm kiếm sơ yếu lý lịch, số nguyên INT
- PaymentAmount - phí dịch vụ quảng cáo tiếp tục nhận được, số thập phân (18,2)
- RemoteAccessCertificate - chứng chỉ truy cập từ xa, chuỗi byte VARBINARY
- Địa chỉ - địa chỉ cư trú hoặc địa chỉ đăng ký, dòng NVARCHAR (MAX)
Sau đó, để giữ tính chọn lọc ban đầu, chúng ta cần triển khai thuật toán sau:
- Trích xuất tất cả các giá trị duy nhất cho từng trường và giữ kết quả trong các bảng tạm thời hoặc các biến lập bảng;
- Tạo một giá trị giả ngẫu nhiên cho mỗi giá trị duy nhất. Giá trị giả ngẫu nhiên này không được khác biệt đáng kể về độ dài và kích thước so với giá trị ban đầu. Lưu kết quả vào cùng một nơi mà chúng tôi đã lưu kết quả điểm 1. Mỗi giá trị mới được tạo phải có một giá trị hiện tại duy nhất tương quan.
- Thay thế tất cả các giá trị trong bảng bằng các giá trị mới từ điểm 2.
Ban đầu, chúng tôi nhân cách hóa họ và tên của các ứng cử viên. Chúng tôi giả định rằng họ và tên luôn xuất hiện và chúng có độ dài không ít hơn hai ký tự trong mỗi trường.
Đầu tiên, chúng tôi chọn tên duy nhất. Sau đó, nó tạo ra một dòng giả ngẫu nhiên cho mỗi tên. Độ dài của tên vẫn giữ nguyên; ký tự đầu tiên là chữ hoa và các ký tự khác là chữ thường. Chúng tôi sử dụng hàm vô hướng [test]. [GetRandString] đã tạo trước đó để tạo một dòng giả ngẫu nhiên có độ dài cụ thể theo tiêu chí của ký tự được xác định.
Sau đó, chúng tôi cập nhật tên trong bảng ứng cử viên theo giá trị duy nhất của chúng. Họ cũng vậy.
Chúng tôi phi cá nhân hóa trường DocNumber. Đó là số thẻ căn cước (hộ chiếu). Hai ký tự đầu tiên tượng trưng cho chuỗi của tài liệu và bảy chữ số cuối cùng là số của tài liệu. Dấu gạch nối nằm giữa chúng. Sau đó, chúng tôi thực hiện thao tác vệ sinh.
Chúng tôi thu thập tất cả các số của tài liệu duy nhất và tạo một dòng giả ngẫu nhiên cho mỗi tài liệu. Định dạng của dòng là 'XX-XXXXXXX', trong đó X là chữ số trong phạm vi từ 0 đến 9. Ở đây, chúng tôi sử dụng hàm vô hướng [test] đã tạo trước đó. [GetRandString] để tạo một dòng giả ngẫu nhiên có độ dài được chỉ định theo các tham số của ký tự được đặt.
Sau đó, trường [DocNumber] được cập nhật trong bảng [dbo] của ứng viên. [Nhân viên].
Chúng tôi cá nhân hóa trường DocDate (ngày cấp thẻ ID) và trường BirthDate (ngày sinh của ứng viên).
First, we select all the unique pairs made of “date of birth &date of the ID-card issue.” For each such pair, we create a pseudorandom date for the date of birth. The pseudorandom date of the ID-card issue is made according to that “date of birth” – the date of the document’s issue must not be earlier than the date of birth.
After that, these data are updated in the respective fields of the candidates’ table [dbo].[Employee].
And, we update the remaining fields of the table.
The CountRequest value stands for the number of requests made for that candidate by companies during the resume search.
The PaymentAmount is the final amount of the resume promotion service fee paid. We calculate these numbers similarly to the previous fields.
Note that it generates a pseudorandom integer for the first case and a pseudorandom decimal for the second case. In both cases, the pseudorandom number generation occurs in the range of “two times less than original” to “two times more than original.” The selectivity of values in the fields is not changed too much.
After that, it writes the values into the fields of the candidates’ table [dbo].[Employee].
Further, we collect unique values of the RemoteAccessCertificate field for the remote access certificate. We generate a pseudorandom byte sequence for each such value. The length of the sequence must be the same as the original. Here, we use the previously created [test].[GetRandVarbinary] scalar function to generate the pseudorandom byte sequence of the specified length.
Then recording into the respective field [RemoteAccessCertificate] of the [dbo].[Employee] candidates’ table takes place.
The last step is the collection of the unique addresses from the [Address] field. For each value, we generate a pseudorandom line of the same length as the original. Note that if it was NULL originally, it must be NULL in the generated field. It allows you to keep NULL and don’t replace it with an empty line. It minimizes the selectivity values’ mismatch in this field between the production database and the altered data.
We use the previously created [test].[GetRandString] scalar function to generate the pseudorandom line of the specified length according to the characters’ parameters defined.
It then records the data into the respective [Address] field of the candidates’ table [dbo].[Employee].
This way, we get the full script for depersonalization and altering of the confidential data.
Finally, we get the database with altered personal and confidential data. The algorithms we used make it impossible to restore the original data from the altered data. Also, the values’ selectivity, length, and size aren’t changed significantly. So, the three criteria for the personal and secret data altering scripts are ensured.
We won’t review the criterion 4 separately here. Our database contains all the data subject to change in one candidates’ table [dbo].[Employee]. The data conformity is needed within this table only. Thus, criterion 4 is also here. However, we need to remember this criterion 4 claiming that all interrelations must remain the same in the altered data.
We often see other conditions for personal and confidential data altering algorithms, but we won’t review them here. Besides, the four criteria described above are always present. In many cases, it is enough to estimate the functionality of the algorithm suitable to use it.
Now, we need to make a backup of the created database, check it by restoring on another instance, and transfer that copy into the necessary environment for development and testing. For this, we examine the full database backup creation.
Full database backup creation
We can make a database backup with construction BACKUP DATABASE as in our example.
Make a compressed full backup of the database JobEmplDB_Test. The checksum calculation takes place in the file E:\Backup\JobEmplDB_Test.bak. Further, we check the backup created.
Then, we check the backup created by restoring the database for it. Let’s examine the database restoring.
Restoring the database
You can restore the database with the help of RESTORE DATABASE construction in the following way:
USE [master]
RESTORE DATABASE [JobEmplDB_Test]
FROM DISK = N'E:\Backup\JobEmplDB_Test.bak' WITH FILE = 1,
MOVE N'JobEmplDB' TO N'E:\DBData\JobEmplDB.mdf',
MOVE N'JobEmplDB_log' TO N'F:\DBLog\JobEmplDB_log.ldf',
NOUNLOAD,
REPLACE,
STATS = 5;
GO
We restore the JobEmplDB_Test database of the E:\Backup\JobEmplDB_Test.bak backup. The files will be overwritten, and the data file will be transferred into the file E:\DBData\JobEmplDB.mdf , while the transactions log file will be moved into F:\DBLog\JobEmplDB_log.ldf .
After we successfully check how the database is restored from the backup, we forward the backup to the development and testing environments. It will be restored again with the same method as described above.
We’ve examined the first approach to the data populating into the database for testing and development. This approach implies copying and altering the data from the production database. Now, we’ll examine the second approach – the synthetic data generation.
Synthetic data generation
The General algorithm for the synthetic data generation is following:
- Make a new empty database or clear a previously created database by purging all data.
- Create or renew a scheme in the newly created database – the same as that of the production databases.
- Copy of renew guidelines and regulations from the production database and transfer them into the new database.
- Generate synthetic data into the necessary tables of the new database.
- Make a backup of a new database.
- Deliver and restore the new backup in the necessary environment.
We already have the JobEmplDB_Test database to practice, and we have reviewed the means of creating a schema in the new database. Let’s focus on the tasks that are specific to this approach.
Clean up the database with the data purge
To clear the database off all its data, we need to do the following:
- Keep the definitions of all external keys.
- Disable all limitations and triggers.
- Delete all external keys.
- Clear the tables using the TRUNCATE construction.
- Restore all the external keys deleted in point 3.
- Enable all the limitations disabled in point 2.
You can save the definitions of all external keys with the following script:
1. The external keys’ definitions are saved in the tabulation variable @tbl_create_FK
2. You can disable the limitations and triggers with the following script:
EXEC sp_MSforeachtable "ALTER TABLE ? NOCHECK CONSTRAINT ALL";
EXEC sp_MSforeachtable "ALTER TABLE ? DISABLE TRIGGER ALL";
To enable the limitations and triggers, you can use the following script:
EXEC sp_MSforeachtable "ALTER TABLE ? WITH CHECK CHECK CONSTRAINT ALL";
EXEC sp_MSforeachtable "ALTER TABLE ? ENABLE TRIGGER ALL";
Here, we use the saved procedure sp_MSforeachtable that applies the construction to all the database’s tables.
3. To delete external keys, use the special script. Here, we receive the information about the external keys through the INFORMATION_SCHEMA.TABLE_CONSTRAINTS system presentation. We delete external keys through the cursor, one by one, using the formed dynamic script T-SQL, transferring the request into the system saved procedure sp_executesql .
4. To clear the tables with the TRUNCATE construction, use the dedicated script. The script works in the same way as above, but it receives the data for tables, and then it clears the tables one by one through the cursor, using the TRUNCATE construction.
5. Restoring the external keys is possible with the below script (earlier, we saved the external keys’ definitions in the tabulation variable @tbl_create_FK):
DECLARE @tsql NVARCHAR(4000);
DECLARE FK_Create CURSOR LOCAL FOR SELECT
[Script]
FROM @tbl_create_FK;
OPEN FK_Create;
FETCH NEXT FROM FK_Create INTO @tsql;
WHILE (@@fetch_status = 0)
BEGIN
EXEC sp_executesql @tsql = @tsql;
FETCH NEXT FROM FK_Create INTO @tsql;
END
CLOSE FK_Create;
DEALLOCATE FK_Create;
The script works in the same way as the two other scripts we mentioned above. But it restores the external keys’ definitions through the cursor, one for each iteration.
A particular case of data purging in the database is the current script. To get this output, we need the below construction in the scripts:
EXEC sp_executesql @tsql = @tsql;Before this construction, or instead of it, we need to write the generated construction output. It is necessary to call it manually or via the dynamic T-SQL query. We do it via the system saved procedure sp_executesql.
Instead of the below code fragment in all cases:
WHILE (@@fetch_status = 0)
BEGIN
EXEC sp_executesql @tsql = @tsql;
...
We write:
WHILE (@@fetch_status = 0)
BEGIN
PRINT @tsql;
EXEC sp_executesql @tsql = @tsql;
...
Or:
WHILE (@@fetch_status = 0)
BEGIN
PRINT @tsql;
...
The first case implies both the output of constructions and their execution. The second case if for the output only – it is helpful for the scripts’ debugging.
Thus, we get the general database cleaning script.
Copy guidelines and references from the production database to the new one
Here you can use the T-SQL scripts. Our example database of the recruitment service includes 5 guidelines:
- [dbo].[Company] – companies
- [dbo].[Skill] – skills
- [dbo].[Position] – positions (occupation)
- [dbo].[Project] – projects
- [dbo].[ProjectSkill] – project and skills’ correlations
The “skills” table [dbo].[Skill] serves to show how to make a script for the data insertion from the production database into the test database.
We form the following script:
SELECT 'SELECT '+CAST([SkillID] AS NVARCHAR(255))+' AS [SkillID], '+''''+[SkillName]+''''+' AS [SkillName] UNION ALL'
FROM [dbo].[Skill]
ORDER BY [SkillID];
We execute it in a copy of the production database that is usually available in read-only mode. It is a replica of the production database.
Kết quả là:
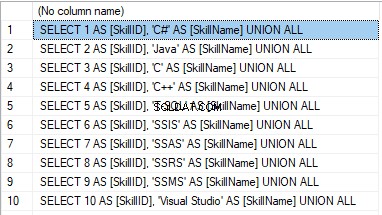
Now, wrap the result up into the script for the data adding as here. We have a script for the skills’ guideline compilation. The scripts for other guidelines are made in the same way.
However, it is much easier to copy the guidelines’ data through the data export and import in SSMS. Or, you can use the data import and export wizard.
Generate synthetic data
We’ve determined the pseudorandom values’ generation for lines, numbers, and byte sequences. It took place when we examined the implementation of the data sanitization and the confidential data altering algorithms for approach 1. Those implemented functions and scripts are also used for the synthetic data generation.
The recruitment service database requires us to fill the synthetic data in two tables only:
- [dbo].[Employee] – candidates
- [dbo].[JobHistory] – a candidate’s work history (experience), the resume itself
We can fill the candidates’ table [dbo].[Employee] with synthetic data using this script.
At the beginning of the script, we set the following parameters:
- @count – the number of lines to be generated
- @LengthFirstName – the name’s length
- @LengthLastName – the last name’s length
- @StartBirthDate – the lower limit of the date for the date of birth
- @FinishBirthDate – the upper limit of the date for the date of birth
- @StartCountRequest – the lower limit for the field [CountRequest]
- @FinishCountRequest – the upper limit for the field [CountRequest]
- @StartPaymentAmount – the lower limit for the field [PaymentAmount]
- @FinishPaymentAmount – the upper limit for the field [PaymentAmount]
- @LengthRemoteAccessCertificate – the byte sequence’s length for the certificate
- @LengthAddress – the length for the field [Address]
- @count_get_unique_DocNumber – the number of attempts to generate the unique document’s number [DocNumber]
The script complies with the uniqueness of the [DocNumber] field’s value.
Now, let’s fill the [dbo].[JobHistory] table with synthetic data as follows.
The start date of work [StartDate] is later than the issuing date of the candidate’s document [DocDate]. The end date of work [FinishDate] is later than the start date of work [StartDate].
It is important to note that the current script is simplified, as it does not deal with parameters of the generated data selectivity configuration.
Make a full database backup
We can make a database backup with the construction BACKUP DATABASE, using our script.
We create a full compressed backup of the database JobEmplDB_Test. The checksum is calculated into the file E:\Backup\JobEmplDB_Test.bak. It also ensures further testing of the backup.
Let’s check the backup by restoring the database from it. We need to examine the database restoring then.
Restore the database
You can restore the database with the help of the RESTORE DATABASE construction, as shown below:
USE [master]
RESTORE DATABASE [JobEmplDB_Test]
FROM DISK = N'E:\Backup\JobEmplDB_Test.bak' WITH FILE = 1,
MOVE N'JobEmplDB' TO N'E:\DBData\JobEmplDB.mdf',
MOVE N'JobEmplDB_log' TO N'F:\DBLog\JobEmplDB_log.ldf',
NOUNLOAD,
REPLACE,
STATS = 5;
GO
We restore the database JobEmplDB_Test from the backup E:\Backup\JobEmplDB_Test.bak. The files are overwritten, and the data file is transferred to the file E:\DBData\JobEmplDB.mdf. The transaction log file is transferred to file F:\DBLog\JobEmplDB_log.ldf.
After checking the database restoring from the backup successfully, we transfer the backup to the necessary environments. It will be used for testing and development, and further deployment through the database restoring, as described above.
This way, we’ve examined the second approach to filling the database in with data for testing and development purposes. It is the synthetic data generation approach.
Data generation tools (for external resources)
When we have a job to fill in the database with data for testing and development purposes, it can be much faster and easier with the help of specialized tools. Let’s review the most popular and powerful data generation tools and explore their practical usage.
Full list of tools
DATPROF
IRI RowGen
Data Generator for SQL Server
Redgate SQL Data Generator
DTM Data Generator
Datanamic Data Generator MultiDB
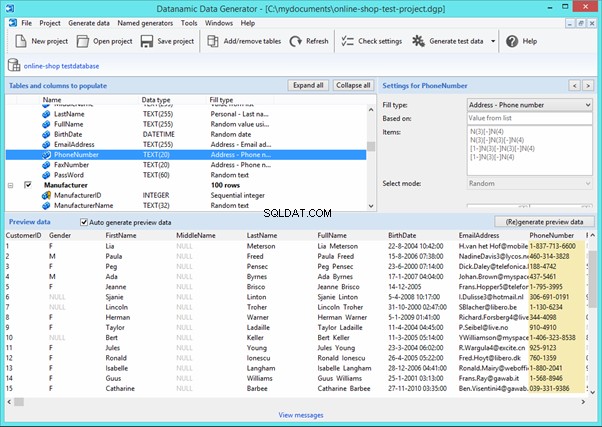
Now, let’s examine one of these tools more precisely.
An overview of the employees’ generation by the Data Generator for SQL Server
The Data Generator for SQL Server utility is embedded in SSMS, and also it is a part of dbForge Studio. We reviewed this utility here. Let’s now examine how it works for synthetic data generation. As examples, we use the [dbo].[Employee] and the [dbo].[JobHistory] tables.
This generator can quickly generate first and last names of candidates for the [FirstName] and [LastName] fields respectively:
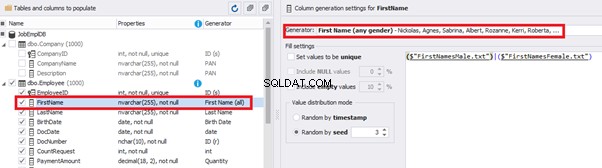
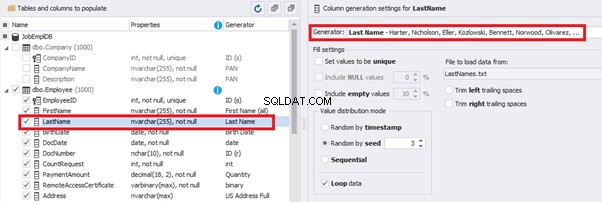
Note that FirstName requires choosing the “First Name” value in the “Generator” section. For LastName, you need to select the “Last Name” value from the “Generator” section.
It is important to note that the generator automatically determines which generation type it needs to apply to every field. The settings above were set by the generator itself, without manual correction.
You can configure distribution of values for the date of birth [BirthDate]:
Set the distribution for the document’s date of issue [DocDate] through the Phyton generator using the below script:
import random
from System import DateTime
# receive the value from the Birthday field
bd = DateTime.Parse(str(BirthDate))
# receive the current date
current = DateTime.Now
# calculate the age in years
timeSpan = current - bd
age = (int)(timeSpan.TotalDays / 365);
# passport’s date of issue
releaseDate = 0
if age >= 45:
releaseDate = bd.AddDays(45 * 365 + random.randint(1, 30))
# randomize the issue during the month
elif age >= 20:
releaseDate = bd.AddDays(20 * 365 + random.randint(1, 30))
# randomize the issue during the month
else:
releaseDate = bd.AddDays(14 * 365 + random.randint(1, 30))
# randomize the issue during the month
releaseDateThis way, the [DocDate] configuration will look as follows:
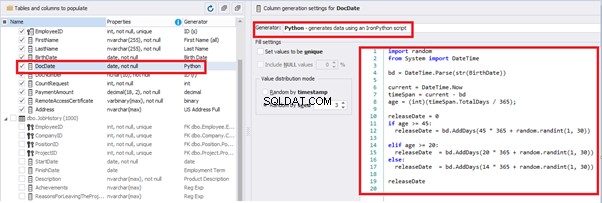
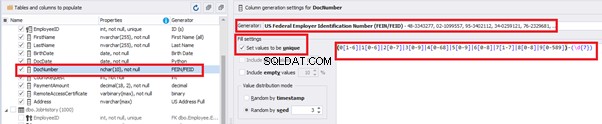
For the document’s number [DocNumber], we can select the necessary type of unique data generation, and edit the generated data format, if needed:
E.g., instead of the format
(0[1-6]|1[0-6]|2[0-7]|3[0-9]|4[0-68]|5[0-9]|6[0-8]|7[1-7]|8[0-8]|9[0-589])-(\d{7})We can set the following format:
(\d{2})-(\d{7})This format means that the line will be generated in format XX-XXXXXXX (X – is a digit in the range of 0 to 9).
We set up the generator for [CountRequest] and [PaymentAmount] fields in the same way, according to the generated data type:
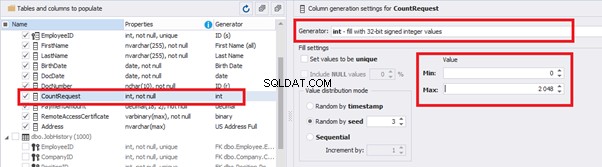
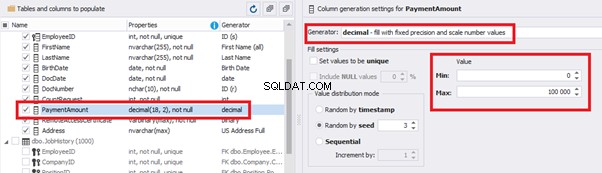
In the first case, we set the values’ range of 0 to 2048 for [CountRequest]. In the second case, it is the range of 0 to 100000 for [PaymentAmount].
We configure generation for [RemoteAccessCertificate] and [Address] fields in the same way:
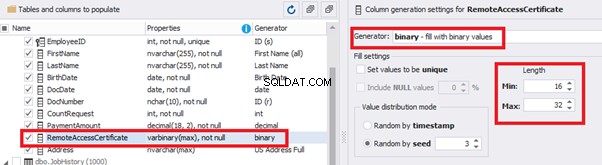
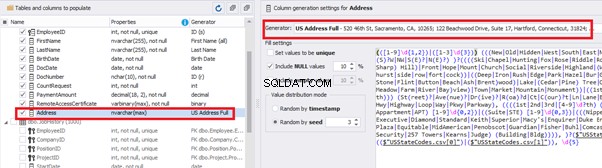
In the first case, we limit the byte sequence [RemoteAccessCertificate] with the range of lengths of 16 to 32. In the second case, we select values for [Address] as real addresses. It makes the generated values looking like the real ones.
This way, we’ve configured the synthetic data generation settings for the candidates’ table [dbo].[Employee]. Let’s now set up the synthetic data generation for the [dbo].[JobHistory] table.
We set it to take the data for the [EmployeeID] field from the candidates’ table [dbo].[Employee] in the following way:
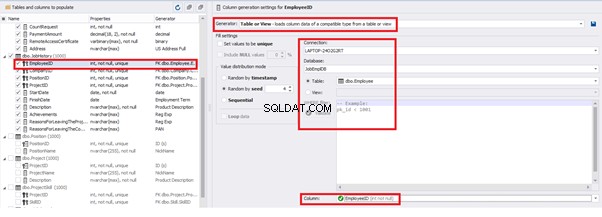
We select the generator’s type from the table or presentation. We then define the sample of MS SQL Server, the database, and the table to take the data from. We can also configure filters in the “WHERE filter” section, and select the [EmployeeID] field.
Here we suppose that we generate the “employees” first, and then we generate the data for the [dbo].[JobHistory] table, basing on the filled [dbo].[Employee] reference.
However, if we need to generate the data for both [dbo].[Employee] and [dbo].[JobHistory] at the same time, we need to select “Foreign Key (manually assigned) – references a column from the parent table,” referring to the [dbo].[Employee].[EmployeeID] column:
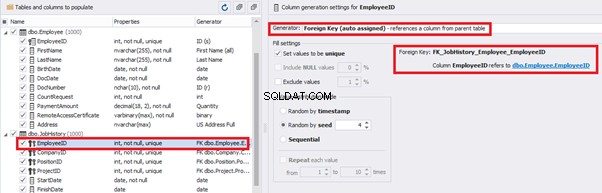
Similarly, we set up the data generation for the following fields.
[CompanyID] – from [dbo].[Company], the “companies” table:
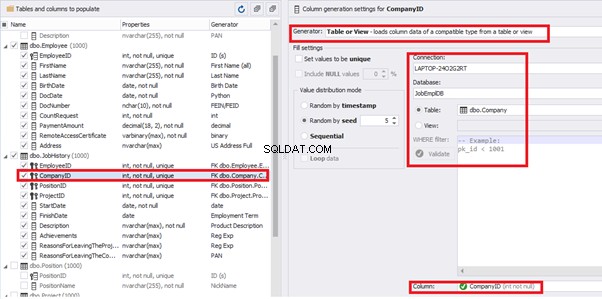
[PositionID] – from the table of positions [dbo].[Position]:
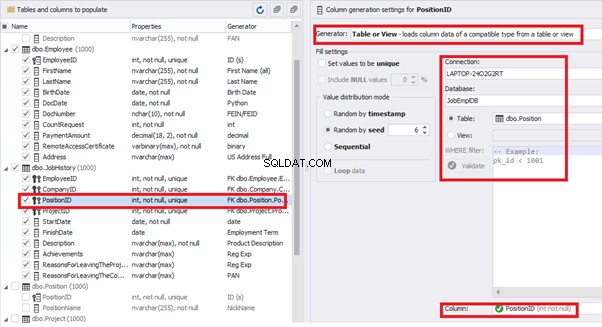
[ProjectID] – from the table of projects [dbo].[Project]:
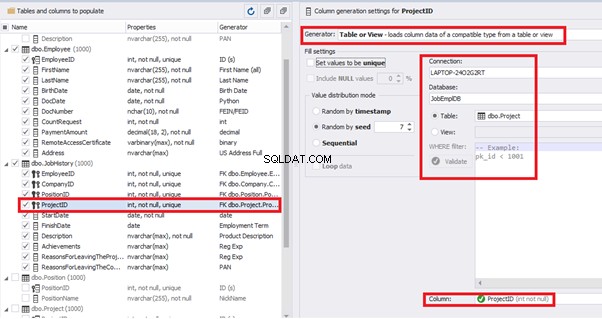
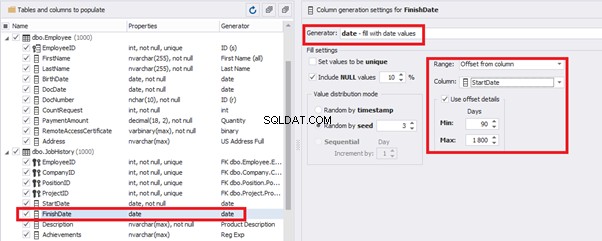
The tool cannot link the columns from different tables and shift them in some way. However, the generator can shift the date within one table – the “date” generator – fill with date values with Range – Offset from the column. Also, it can use data from a different table, but without any transformation (Table or View, SQL query, Foreign key generators).
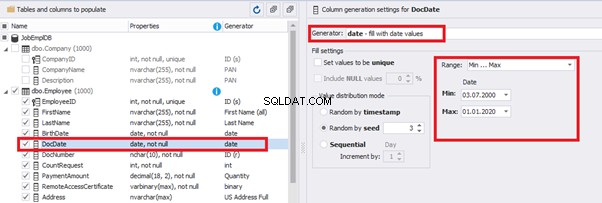
That’s why we resolve the dates’ problem (BirthDate
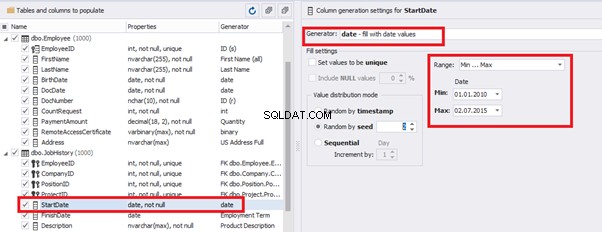
E.g., we limit the BirthDate with the 40-50 years’ interval. Then, we restrict the DocDate with 20-40 years’ interval. The StartDate is, respectively, limited with 25-35 years’ interval, and we set up the FinishDate with the offset from StartDate.
We set up the date of birth:
Set up the date of the document’s issue
Then, the StartDate will match the age from 35 to 45:
The simple offset generator sets FinishDate:
The result is, a person has worked for three months till the current date.
Also, to configure the date of the working end, we can use a small Python script:
This way, we receive the below configuration for the dates of work end [FinishDate] data generation:
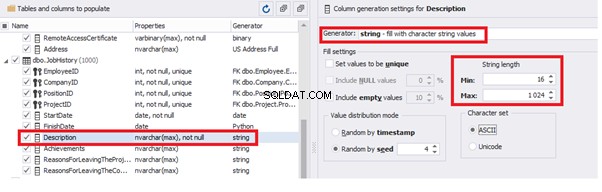
Similarly, we fill in the rest of fields. We set the generator type – string, and set the range for generated lines’ lengths:
Also, you can save the data generation project as dgen-file consisting of:
We can save all these settings:it is enough to keep the project’s file and work with the database further, using that file:
There is also the possibility to both save the new generators from scratch and save the custom settings in a new generator:
Thus, we’ve configured the synthetic data generation settings used for the jobs’ history table [dbo].[JobHistory].
We have examined two approaches to filling the data in the database for testing and development:
We’ve defied the objects for each approach and each script implementation. These objects are here. We’ve also provided scripts for changing the data from the production database and synthetic data generation. An example is the database of recruitment services. In the end, we’ve examined popular data generation tools and explored one of these tools in detail.
SQL SERVER – How to Disable and Enable All Constraint for Table and Database 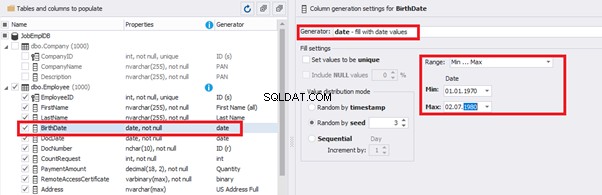
import random
from System import DateTime
bd = DateTime.Parse(str(StartDate))
releaseDate = bd.AddDays(random.randint(1, 30))
releaseDate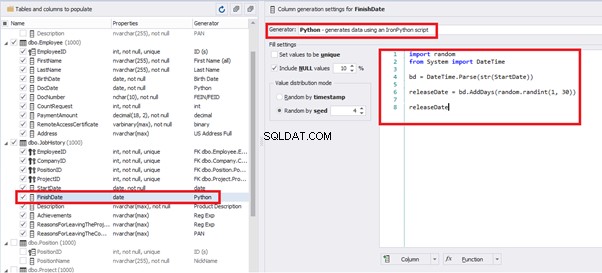
Kết luận
Tài liệu tham khảo
Microsoft TechNet Wiki
Top 10 Best Test Data Generation Tools In 2020
SQL Server Documentation