Spark bắt đầu hoạt động vào năm 2009 với tư cách là một dự án trong AMPLab tại Đại học California, Berkeley. Cụ thể hơn, nó được sinh ra vì sự cần thiết để chứng minh khái niệm về Mesos, khái niệm này cũng được tạo ra trong AMPLab. Spark lần đầu tiên được thảo luận trong sách trắng Mesos có tiêu đề Mesos:Nền tảng chia sẻ tài nguyên hạt mịn trong Trung tâm dữ liệu, được viết bởi Benjamin Hindman và Matei Zaharia.
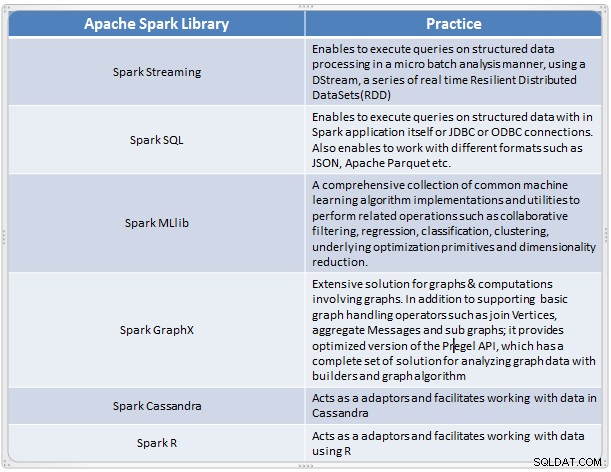
Nó nổi lên như một giải pháp nhanh chóng và tiện lợi để thực hiện các phân tích phức tạp của dữ liệu quy mô lớn. Spark đã phát triển như một khung xử lý mới cho dữ liệu lớn nhằm giải quyết nhiều thiếu sót trong mô hình MapReduce. Nó hỗ trợ Phân tích dữ liệu quy mô lớn và dữ liệu có thể từ các nguồn khác nhau như thời gian thực, xử lý hàng loạt ở các định dạng khác nhau như hình ảnh, văn bản, đồ thị và nhiều hơn nữa. Ngoài lõi Apache Spark, nó cũng cung cấp một số bộ thư viện hữu ích để phân tích dữ liệu lớn.
Tổng quan về các thành phần Spark
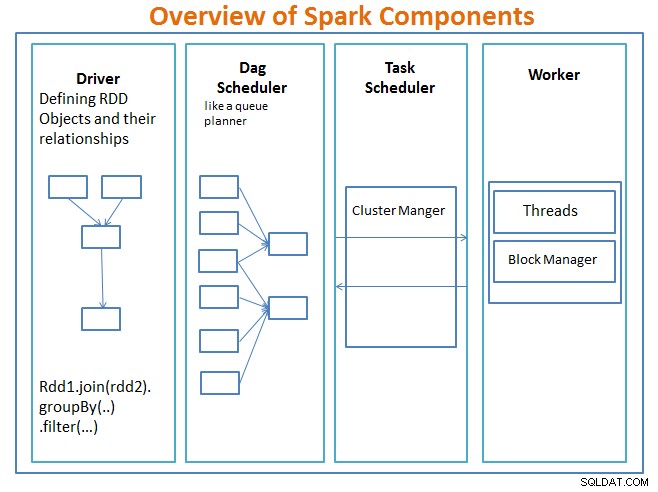
Trình điều khiển là mã bao gồm chức năng chính và xác định các bộ dữ liệu phân tán có khả năng phục hồi (RDD) và các phép biến đổi của chúng. RDD là cấu trúc dữ liệu chính sẽ được sử dụng trong các chương trình Spark của chúng tôi.
Các hoạt động song song trên RDD được gửi đến bộ lập lịch DAG , điều này sẽ tối ưu hóa mã và đến một DAG hiệu quả đại diện cho các bước xử lý dữ liệu trong ứng dụng.
Kết quả DAG được gửi đến người quản lý cụm và người quản lý cụm có thông tin về các công nhân, các luồng được chỉ định và vị trí của các khối dữ liệu và chịu trách nhiệm phân công các nhiệm vụ xử lý cụ thể cho các công nhân. Nó cũng xử lý trở lại nhợt nhạt trong trường hợp nếu công nhân thất bại. Người quản lý cụm có thể là YARN, Mesos, Người quản lý cụm của Spark.
worker nhận các đơn vị công việc và dữ liệu để quản lý và nhân viên thực hiện nhiệm vụ cụ thể của mình mà không cần biết về toàn bộ DAG và kết quả của nó được gửi trở lại các ứng dụng trình điều khiển.
Spark, giống như các công cụ dữ liệu lớn khác, mạnh mẽ, có khả năng và rất thích hợp để giải quyết một loạt các thách thức về dữ liệu. Spark, giống như các công nghệ dữ liệu lớn khác, không nhất thiết phải là sự lựa chọn tốt nhất cho mọi tác vụ xử lý dữ liệu.
Trong Phần 2 - chúng ta sẽ thảo luận về Khái niệm cơ bản về Spark như Tập dữ liệu phân tán có khả năng phục hồi, Biến được chia sẻ, SparkContext, Chuyển đổi, Hành động và Ưu điểm của việc sử dụng Spark cùng với các ví dụ và thời điểm sử dụng Spark.
Tham khảo:
Tìm hiểu Spark trong một ngày bằng Kiến trúc ứng dụng Acodemy &Hadoop.