Thông tin là một trong những tài sản quý giá nhất trong một công ty, và không cần phải nói rằng người ta nên có Kế hoạch khôi phục sau thảm họa (DRP) để ngăn ngừa mất mát dữ liệu trong trường hợp xảy ra tai nạn hoặc lỗi phần cứng. Bản sao lưu là dạng DR đơn giản nhất. Nó có thể không phải lúc nào cũng đủ để đảm bảo Mục tiêu Điểm khôi phục (RPO) được chấp nhận, nhưng là một cách tiếp cận tốt đầu tiên.
Cho dù đó là máy chủ được tải nhiều 24x7 hay môi trường có khối lượng giao dịch thấp, bạn sẽ cần thực hiện sao lưu theo quy trình liền mạch mà không làm gián đoạn hiệu suất của máy chủ trong môi trường sản xuất.
Nếu chúng ta nói về TimescaleDB, có nhiều loại sao lưu khác nhau cho công cụ mới này cho dữ liệu chuỗi thời gian. Loại sao lưu mà chúng ta nên sử dụng phụ thuộc vào nhiều yếu tố, như môi trường, cơ sở hạ tầng, tải, v.v.
Trong blog này, chúng ta sẽ thấy các loại sao lưu khác nhau có sẵn và cách ClusterControl có thể giúp chúng ta tập trung quản lý sao lưu cho TimescaleDB.
Các loại sao lưu
Có nhiều loại sao lưu khác nhau cho cơ sở dữ liệu. Hãy xem xét từng chi tiết trong số chúng.
- Logic:Bản sao lưu được lưu trữ ở định dạng con người có thể đọc được như SQL.
- Vật lý:Bản sao lưu chứa dữ liệu nhị phân.
- Toàn bộ / Gia tăng / Khác biệt:Định nghĩa của ba loại sao lưu này được ngầm hiểu trong tên gọi. Bản sao lưu đầy đủ là bản sao đầy đủ của tất cả dữ liệu của bạn. Sao lưu tăng dần chỉ sao lưu dữ liệu đã thay đổi kể từ lần sao lưu trước và sao lưu phân biệt chỉ chứa dữ liệu đã thay đổi kể từ lần sao lưu đầy đủ cuối cùng được thực thi. Các bản sao lưu gia tăng và khác biệt được giới thiệu như một cách để giảm lượng thời gian và dung lượng ổ đĩa sử dụng để thực hiện sao lưu đầy đủ.
- Tương thích với Point In Time Recovery:PITR Liên quan đến việc khôi phục cơ sở dữ liệu tại bất kỳ thời điểm nào trong quá khứ. Để có thể làm được điều này, chúng tôi sẽ cần khôi phục một bản sao lưu đầy đủ, sau đó áp dụng tất cả các thay đổi đã xảy ra sau khi sao lưu cho đến trước khi xảy ra lỗi.
Tính năng quản lý sao lưu ClusterControl
Hãy xem cách ClusterControl có thể giúp chúng tôi quản lý các loại sao lưu khác nhau.
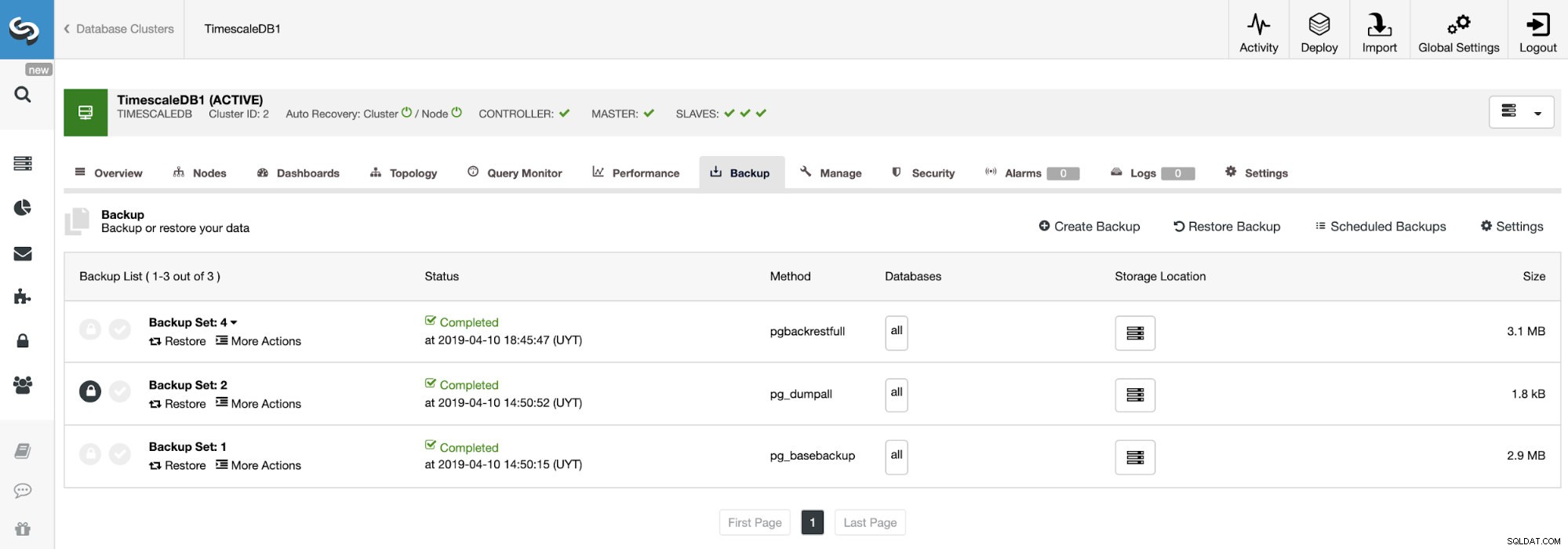
Tạo bản sao lưu
Đối với tác vụ này, hãy đi tới ClusterControl -> Chọn Cụm TimescaleDB -> Sao lưu -> Tạo bản sao lưu .
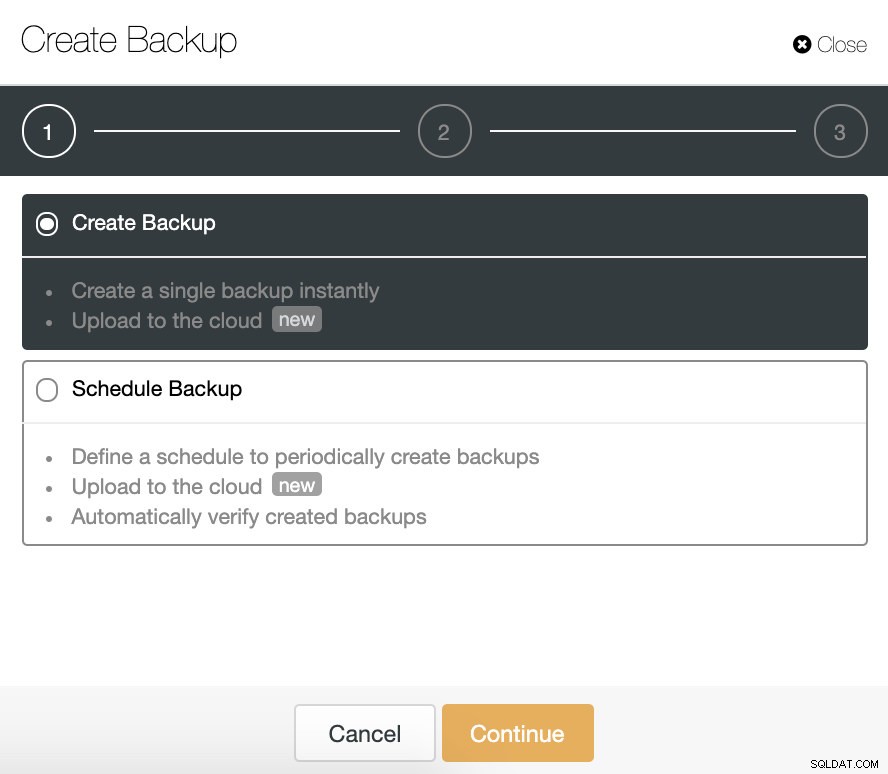
Chúng tôi có thể tạo một bản sao lưu mới hoặc định cấu hình một bản sao lưu đã lên lịch. Đối với ví dụ của chúng tôi, chúng tôi sẽ tạo một bản sao lưu duy nhất ngay lập tức.
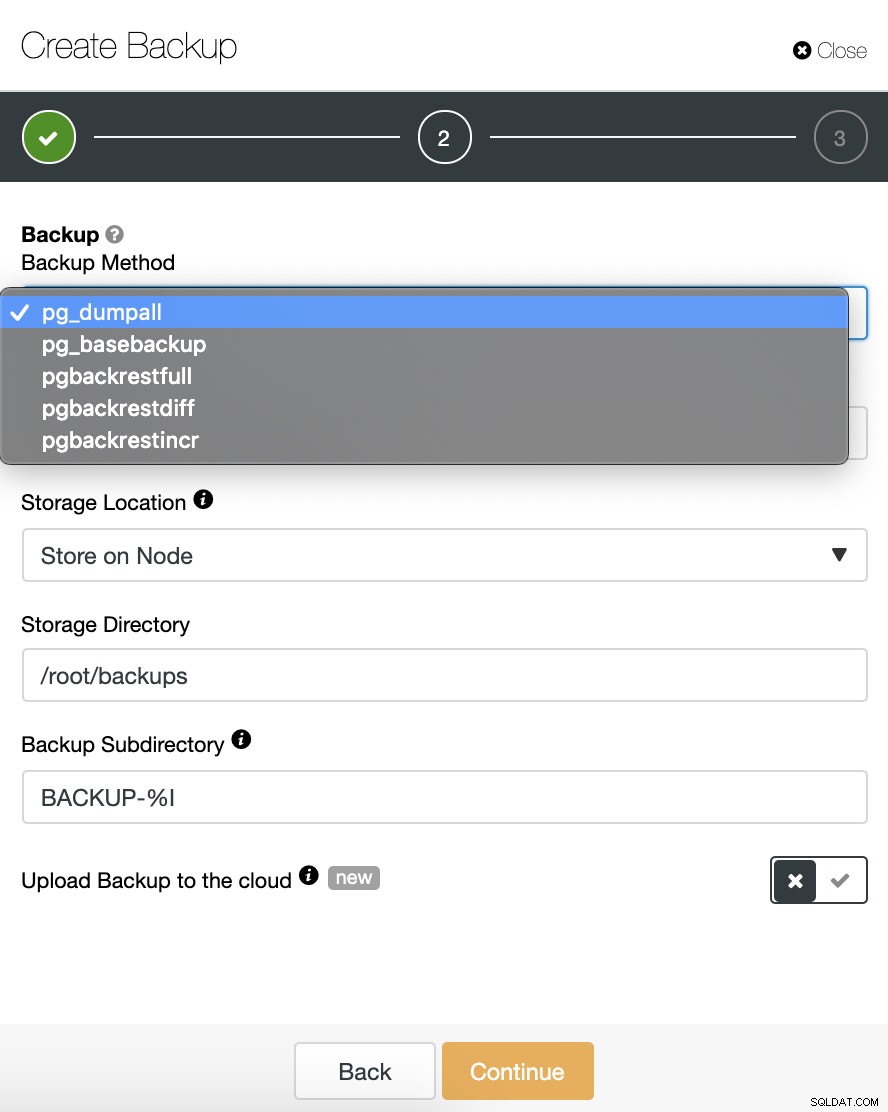
Ở đây chúng tôi có một phương pháp cho mỗi loại sao lưu mà chúng tôi đã đề cập trước đó.
| Loại sao lưu | Công cụ | Định nghĩa |
|---|---|---|
| Logic | pg_dumpall | Đây là một tiện ích để ghi tất cả cơ sở dữ liệu TimescaleDB của một cụm vào một tệp kịch bản. Tệp tập lệnh chứa các lệnh SQL có thể được sử dụng để khôi phục cơ sở dữ liệu. |
| Vật lý | pg_basebackup | Nó được sử dụng để tạo bản sao nhị phân của các tệp cụm cơ sở dữ liệu, đồng thời đảm bảo hệ thống được đưa vào và ra khỏi chế độ sao lưu tự động. Các bản sao lưu luôn được lấy toàn bộ cụm cơ sở dữ liệu của một cụm cơ sở dữ liệu TimescaleDB đang chạy. Chúng được thực hiện mà không ảnh hưởng đến các máy khách khác đến cơ sở dữ liệu. |
| Đầy đủ / Incr / Khác biệt | pgbackrest | Đây là một giải pháp sao lưu và khôi phục đơn giản, đáng tin cậy, có thể tăng quy mô liền mạch lên đến cơ sở dữ liệu và khối lượng công việc lớn nhất bằng cách sử dụng các thuật toán được tối ưu hóa cho các yêu cầu cụ thể của cơ sở dữ liệu. Một trong những tính năng quan trọng nhất là hỗ trợ Sao lưu Toàn bộ, Tăng dần và Khác biệt. |
| PITR | pg_basebackup + WALs | Để tạo bản sao lưu tương thích PITR, ClusterControl sẽ sử dụng pg_basebackup và các tệp WAL, để có thể khôi phục cơ sở dữ liệu tại bất kỳ thời điểm nào trong quá khứ. |
Chúng ta phải chọn một phương pháp, máy chủ mà bản sao lưu sẽ được lấy và nơi chúng ta muốn lưu trữ bản sao lưu. Chúng tôi cũng có thể tải bản sao lưu của mình lên đám mây (AWS, Google hoặc Azure) bằng cách bật nút tương ứng.
Hãy nhớ rằng nếu bạn muốn tạo một bản sao lưu tương thích với PITR, chúng ta phải sử dụng pg_basebackup trong bước này và chúng ta phải lấy bản sao lưu từ nút chính.
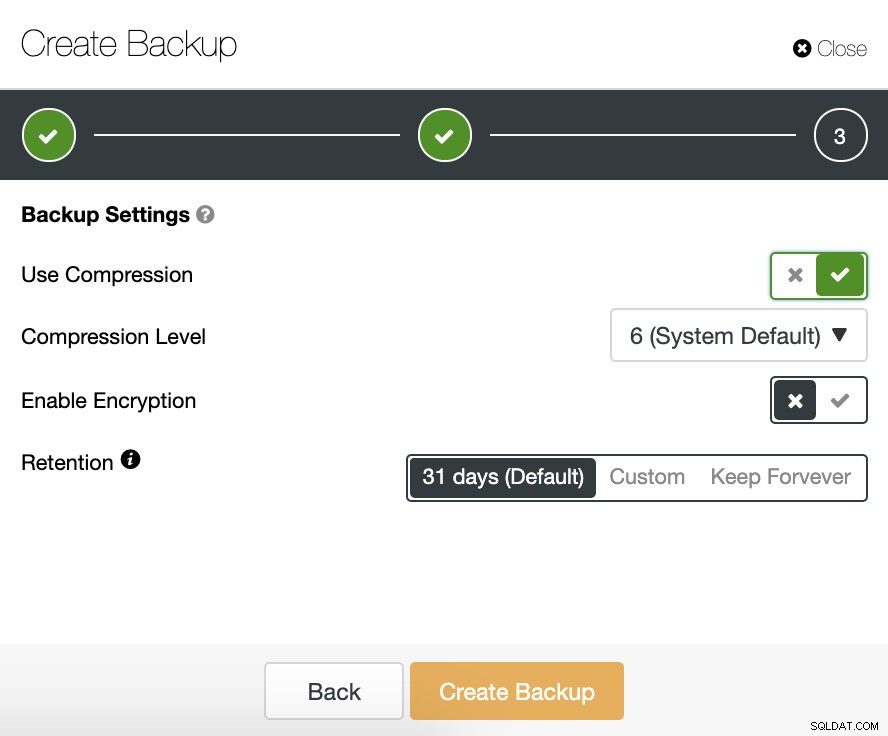
Sau đó, chúng tôi chỉ định việc sử dụng nén, mã hóa và lưu giữ bản sao lưu của chúng tôi.
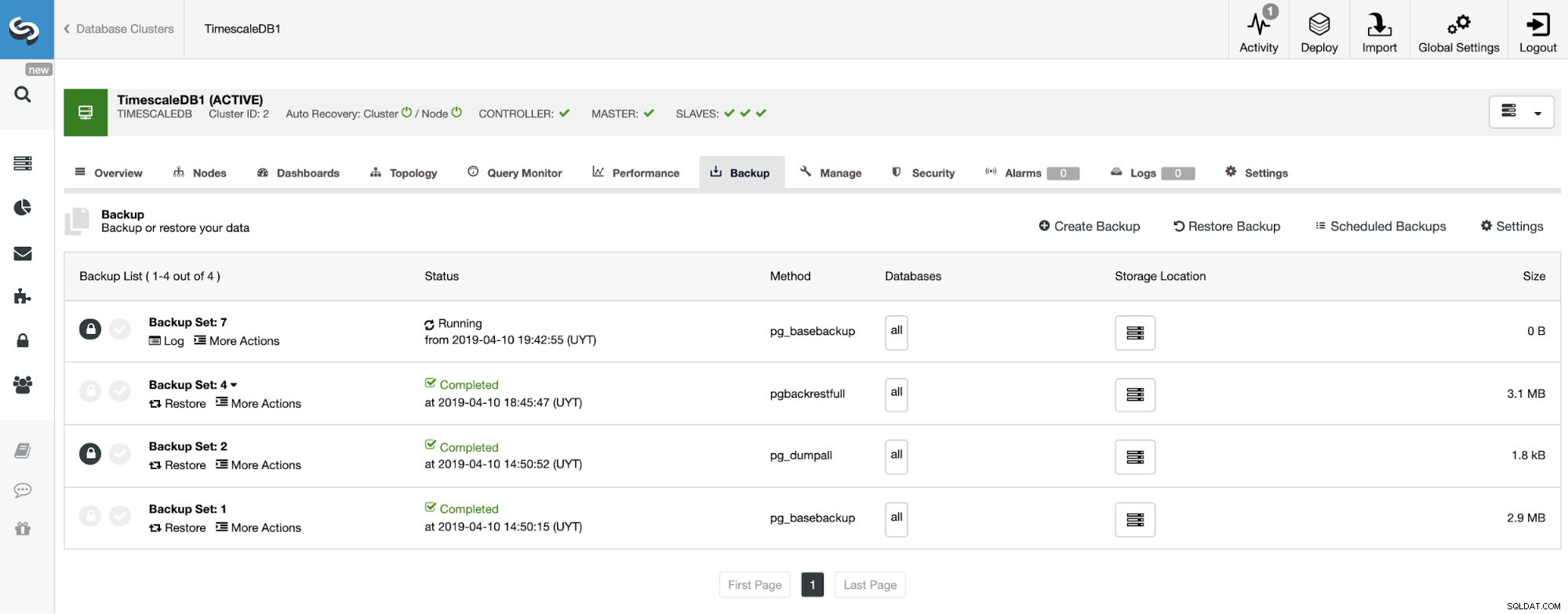
Trên phần sao lưu, chúng ta có thể thấy tiến trình của quá trình sao lưu và thông tin như phương pháp, kích thước, vị trí và hơn thế nữa.
Thời điểm kích hoạt khôi phục
Nếu chúng ta muốn sử dụng tính năng PITR, chúng ta phải bật tính năng Lưu trữ WAL. Đối với điều này, chúng ta có thể đi tới ClusterControl -> Chọn Cụm TimescaleDB -> Hành động nút -> Bật Lưu trữ WAL hoặc chỉ cần đi tới ClusterControl -> Chọn Cụm TimescaleDB -> Sao lưu -> Cài đặt và bật tùy chọn “ Bật khôi phục tại điểm trong thời gian (Lưu trữ WAL) ”Như chúng ta sẽ thấy trong hình ảnh sau đây.
Chúng ta phải ghi nhớ rằng để kích hoạt Lưu trữ WAL, chúng ta phải khởi động lại cơ sở dữ liệu của mình. ClusterControl cũng có thể làm điều này cho chúng tôi.
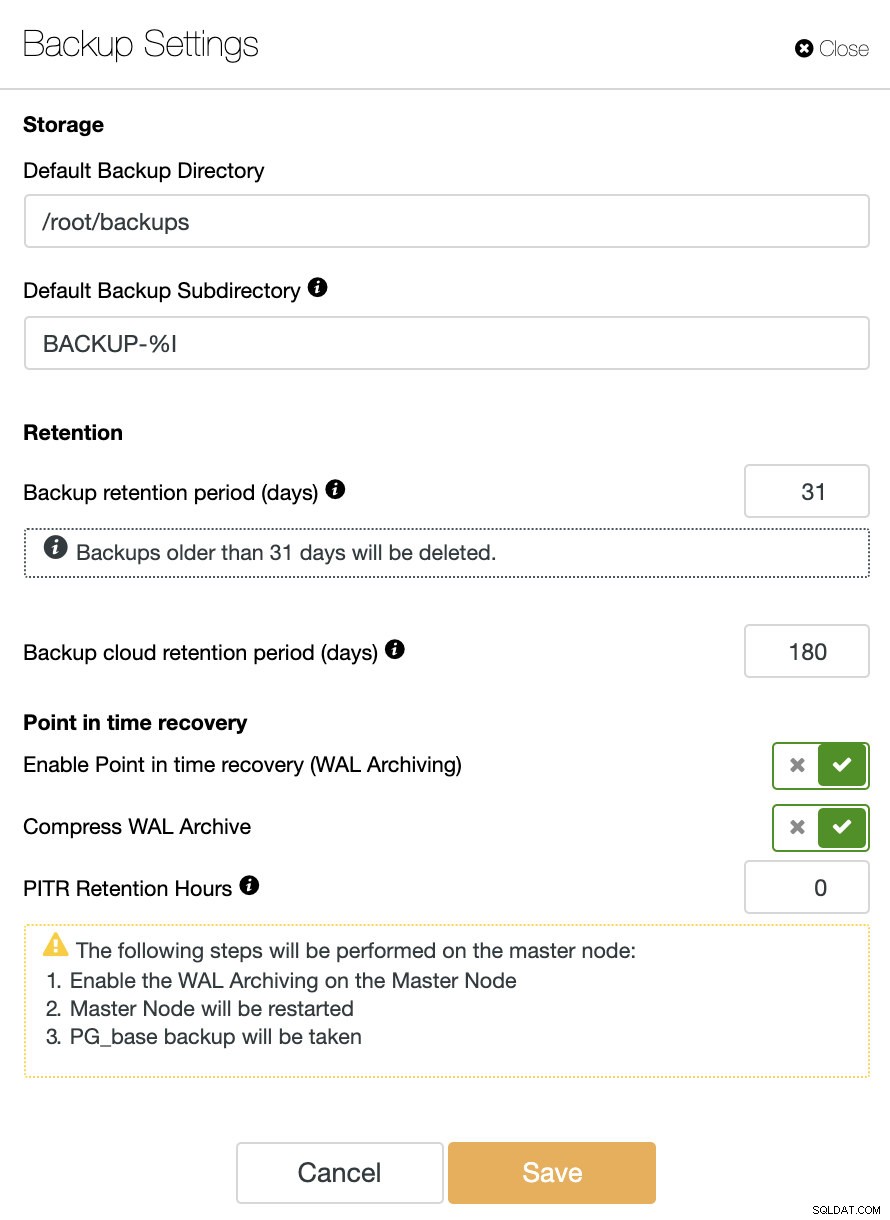
Ngoài các tùy chọn chung cho tất cả các bản sao lưu như “ Thư mục sao lưu ”Và“ Khoảng thời gian lưu giữ dự phòng ”, Ở đây chúng tôi cũng có thể chỉ định Khoảng thời gian lưu giữ WAL. Theo mặc định là 0, có nghĩa là mãi mãi.
Để xác nhận rằng chúng tôi đã bật Lưu trữ WAL, chúng tôi có thể chọn nút Chính của mình trong ClusterControl -> Chọn Cụm TimescaleDB -> Nút và chúng ta sẽ thấy thông báo WAL Archiving Enabled, như chúng ta có thể thấy trong hình ảnh sau.
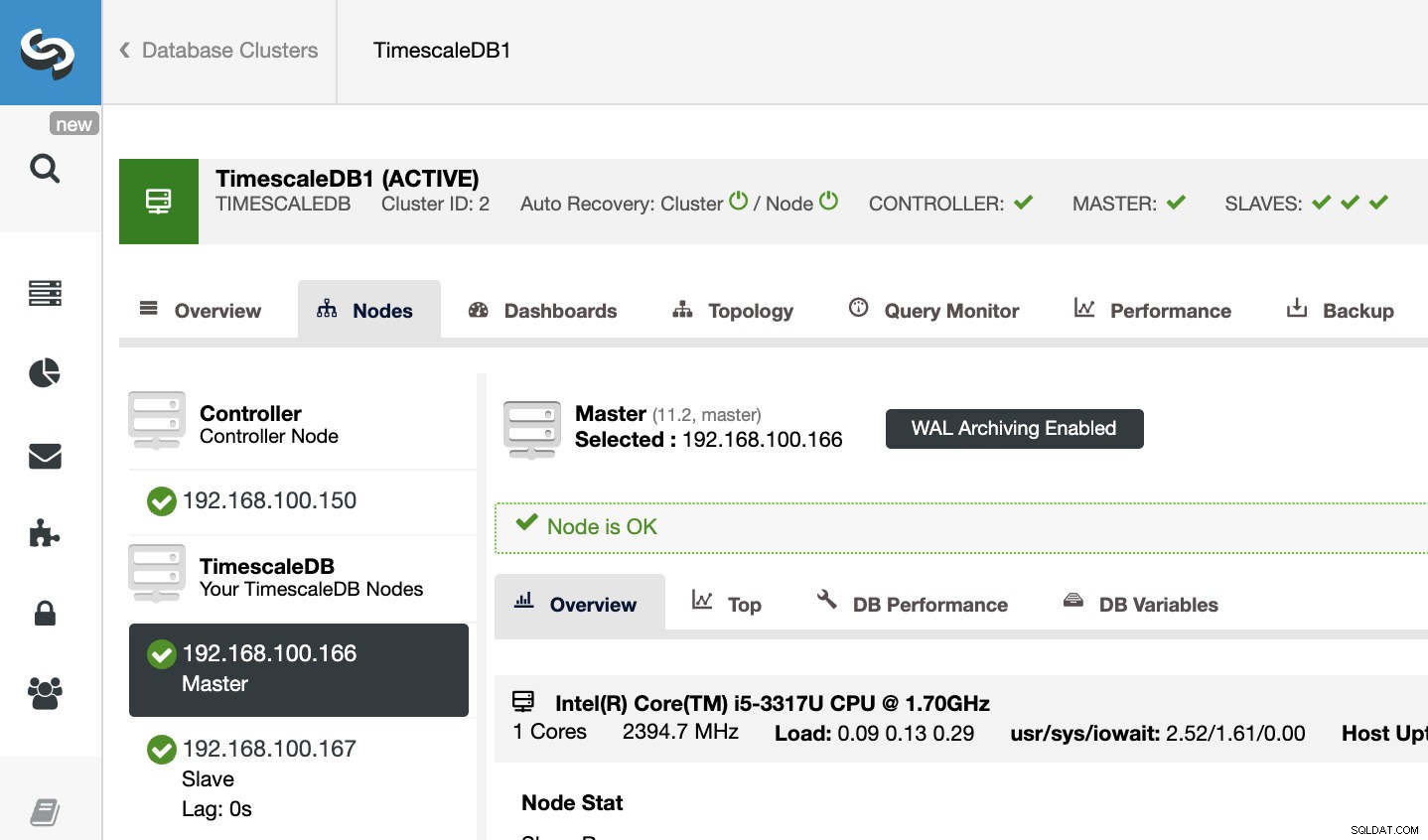
Khôi phục bản sao lưu
Sau khi sao lưu xong, chúng tôi có thể khôi phục nó bằng cách sử dụng ClusterControl. Đối với điều này, trong phần sao lưu của chúng tôi ( ClusterControl -> Chọn Cụm TimescaleDB -> Sao lưu ), chúng tôi có thể chọn "Khôi phục bản sao lưu" hoặc trực tiếp "Khôi phục" trên bản sao lưu mà chúng tôi muốn khôi phục.
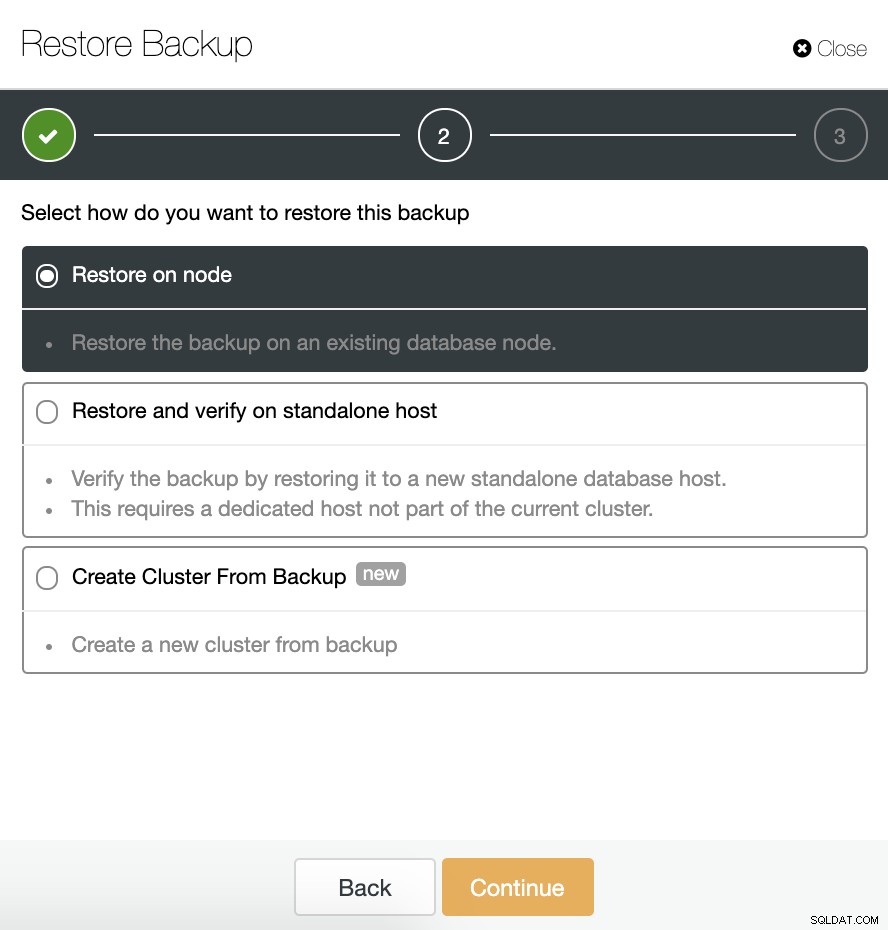
Chúng tôi có ba tùy chọn để khôi phục bản sao lưu. Chúng tôi có thể khôi phục bản sao lưu trong một nút cơ sở dữ liệu hiện có, khôi phục và xác minh bản sao lưu trên một máy chủ độc lập hoặc tạo một cụm mới từ bản sao lưu.
Nếu chúng tôi đang cố gắng khôi phục một bản sao lưu tương thích với PITR, chúng tôi cũng cần chỉ định thời gian.
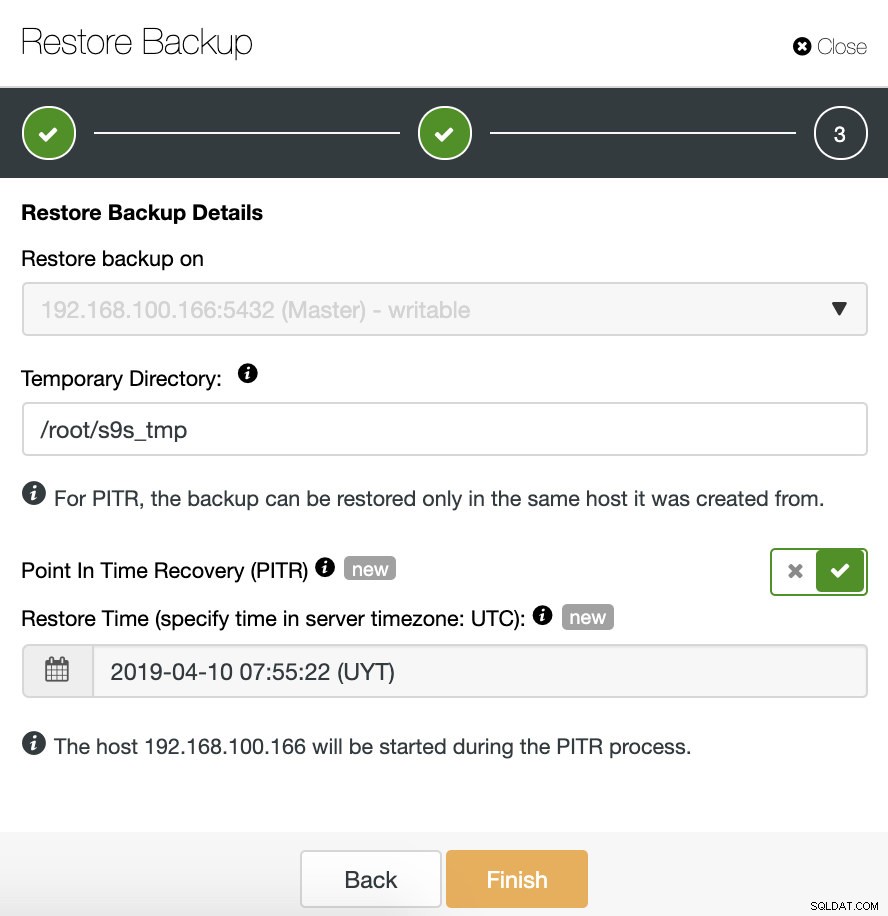
Dữ liệu sẽ được khôi phục lại như cũ tại thời điểm được chỉ định. Hãy lưu ý rằng múi giờ UTC được sử dụng và dịch vụ TimescaleDB của chúng tôi trong bản chính sẽ được khởi động lại.
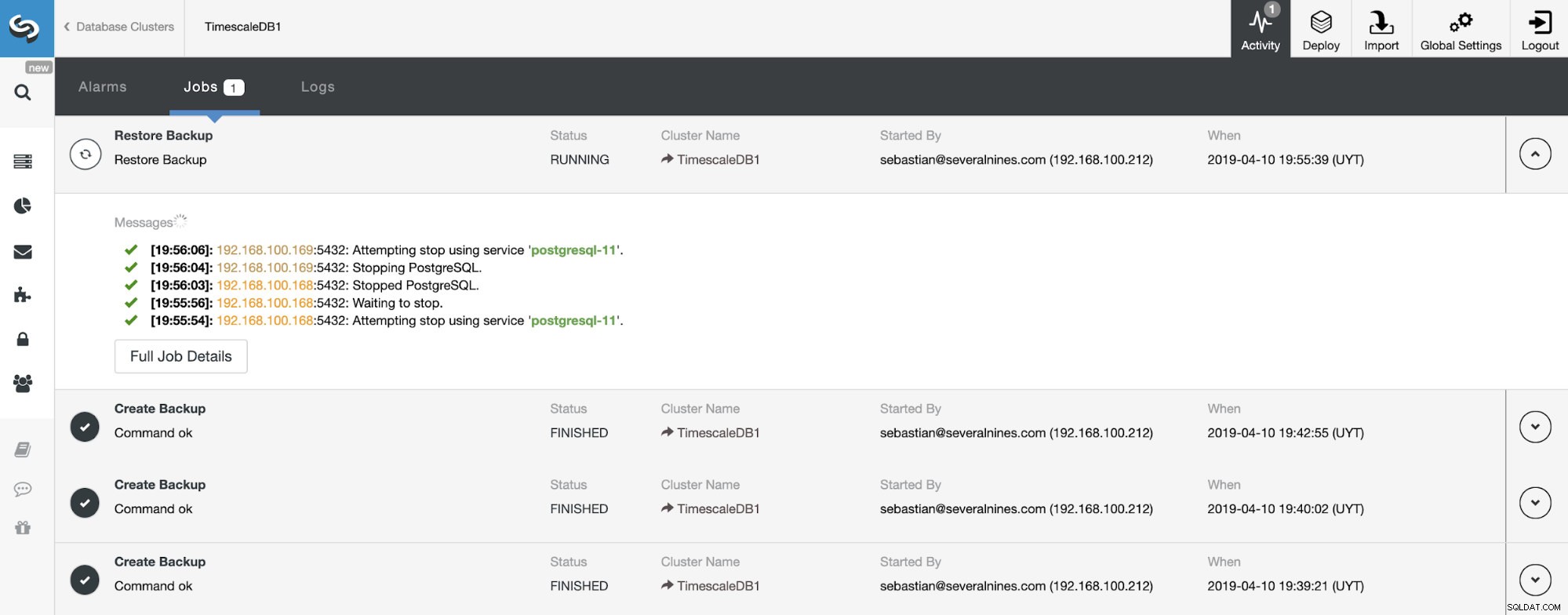
Chúng tôi có thể theo dõi tiến trình khôi phục của mình từ phần Hoạt động trong ClusterControl của chúng tôi.
Xác minh sao lưu tự động
Một bản sao lưu không phải là bản sao lưu nếu nó không khôi phục được. Việc xác minh các bản sao lưu là một việc thường bị nhiều người bỏ qua. Hãy xem cách ClusterControl có thể tự động xác minh các bản sao lưu TimescaleDB và giúp tránh bất kỳ điều gì bất ngờ.
Trong ClusterControl, chọn cụm của bạn và đi tới " Sao lưu ", sau đó, chọn“ Tạo bản sao lưu ”.
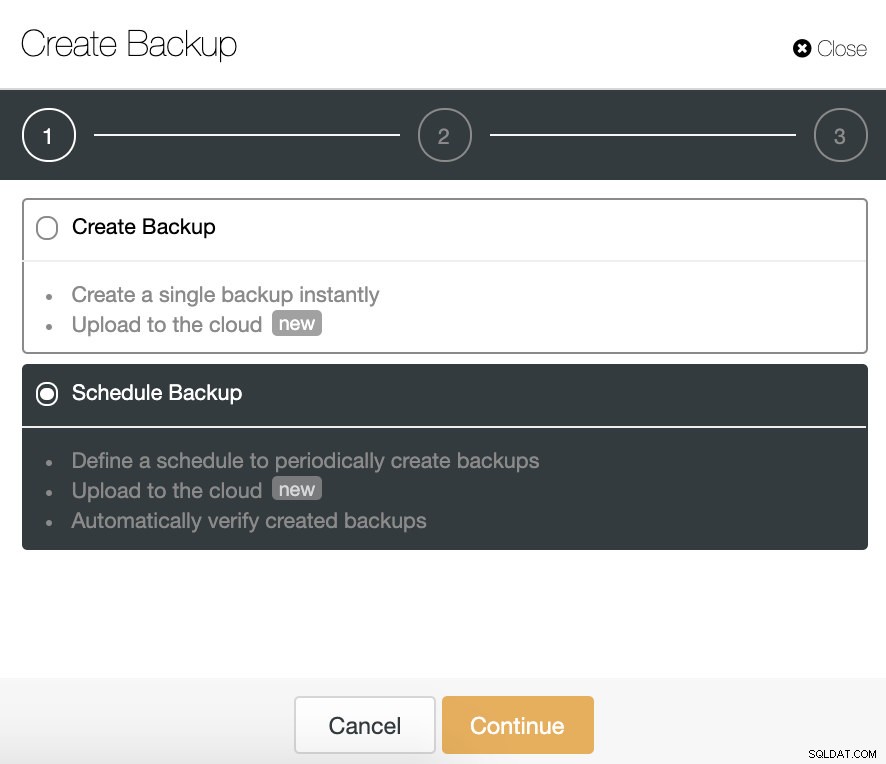
Tính năng sao lưu tự động xác minh khả dụng cho các bản sao lưu theo lịch trình. Vì vậy, hãy chọn “ Lập lịch sao lưu ”Tùy chọn.
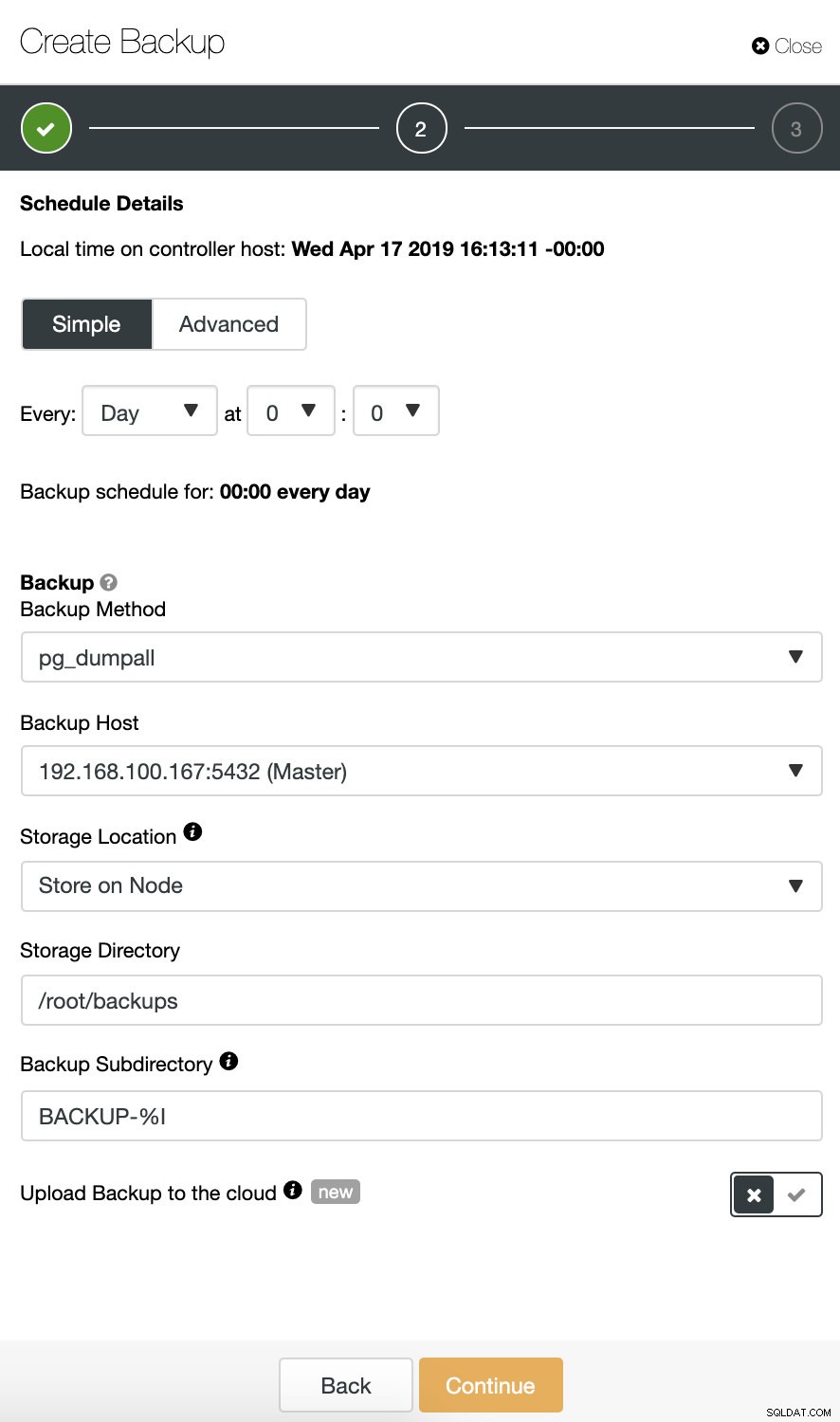
Khi lập lịch sao lưu, ngoài việc chọn các tùy chọn phổ biến như phương pháp hoặc bộ nhớ, chúng ta cũng cần chỉ định lịch / tần suất.
Trong bước tiếp theo, chúng tôi có thể nén và mã hóa bản sao lưu của mình và chỉ định khoảng thời gian lưu giữ. Tại đây, chúng tôi cũng có “ Xác minh bản sao lưu ”.
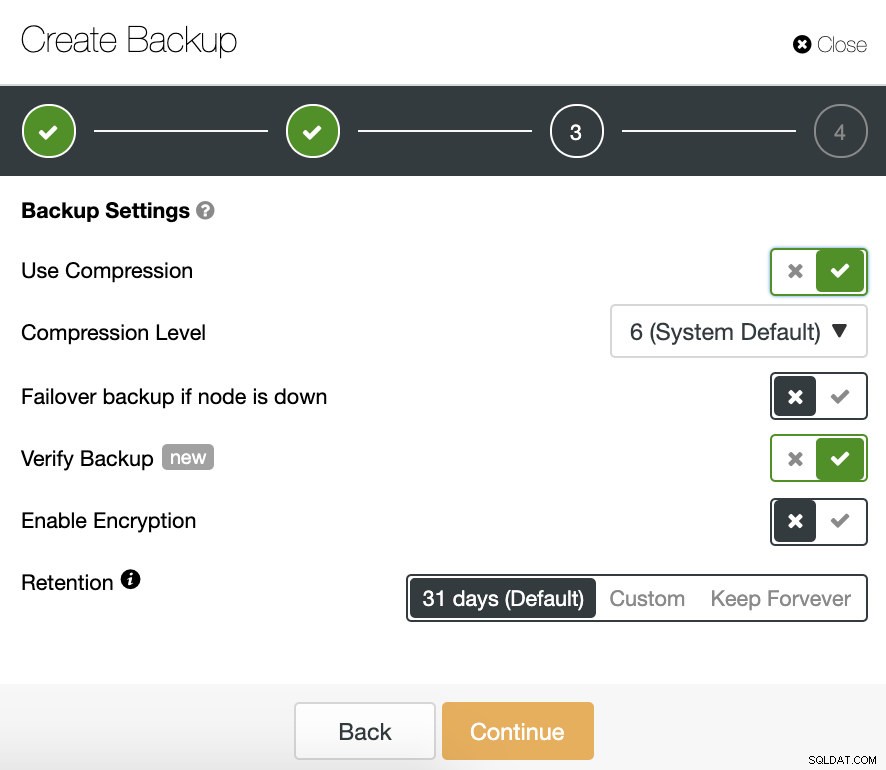
Để sử dụng tính năng này, chúng tôi cần một máy chủ (hoặc máy ảo) chuyên dụng không phải là một phần của cụm.
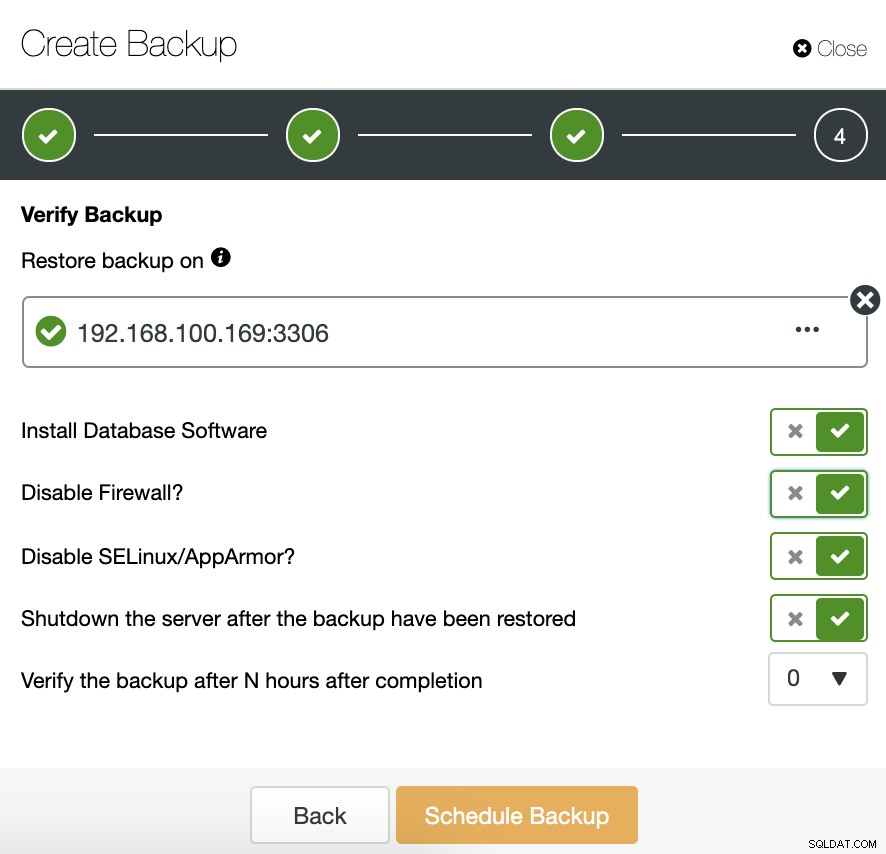
ClusterControl sẽ cài đặt phần mềm và nó sẽ khôi phục bản sao lưu trong máy chủ lưu trữ này. Sau khi khôi phục, chúng ta có thể thấy biểu tượng xác minh trong phần ClusterControl Backup.
Kết luận
Ngày nay, sao lưu là bắt buộc trong bất kỳ môi trường nào. Chúng giúp bạn bảo vệ dữ liệu của mình. Sao lưu tăng dần có thể giúp giảm lượng thời gian và không gian lưu trữ được sử dụng cho quá trình sao lưu. Nhật ký giao dịch rất quan trọng đối với việc phục hồi từng thời điểm. ClusterControl có thể giúp tự động hóa quá trình sao lưu cho cơ sở dữ liệu TimescaleDB của bạn và trong trường hợp không thành công, hãy khôi phục nó bằng một vài cú nhấp chuột. Ngoài ra, bạn có thể giảm thiểu RPO bằng cách sử dụng bản sao lưu tương thích PITR và cải thiện Kế hoạch khôi phục sau thảm họa của mình.