IRI hiện cũng đang cung cấp các chức năng tìm kiếm mờ, cả trong cơ sở dữ liệu miễn phí và các công cụ lập hồ sơ tệp phẳng, cũng như các thư viện chức năng trường có sẵn trong IRI CoSort, FieldShield và Voracity để tăng cường chất lượng dữ liệu, bảo mật và khả năng MDM. Đây là bài viết đầu tiên trong loạt bài viết về các giải pháp tìm kiếm mờ IRI đề cập đến ứng dụng của chúng để cải thiện chất lượng dữ liệu.
Giới thiệu
Tính xác thực hoặc độ tin cậy của dữ liệu của một trong những từ ‘V’ lớn (cùng với khối lượng, sự đa dạng, vận tốc và giá trị) mà IRI và các cộng sự nói đến trong bối cảnh quản lý dữ liệu và thông tin doanh nghiệp. Nói chung, IRI định nghĩa dữ liệu bị nghi ngờ là có một hoặc nhiều thuộc tính sau:
- Chất lượng thấp vì không nhất quán, không chính xác hoặc không đầy đủ
- Không rõ ràng (nghĩ MDM), không chính xác (không có cấu trúc) hoặc lừa đảo (mạng xã hội)
- Thành kiến (câu hỏi khảo sát), ồn ào (thừa hoặc ô nhiễm) hoặc bất thường (ngoại lệ)
- Không hợp lệ vì bất kỳ lý do nào khác (dữ liệu có đúng và chính xác cho mục đích sử dụng không?)
- Không an toàn - nó có chứa PII hoặc bí mật không và nó có được che đậy thích hợp, có thể đảo ngược, v.v. không?
Bài viết này chỉ tập trung vào các giải pháp tìm kiếm mờ mới cho vấn đề đầu tiên, chất lượng dữ liệu. Các bài viết khác trong blog này thảo luận về cách phần mềm IRI giải quyết bốn vấn đề về tính xác thực khác; yêu cầu trợ giúp tìm chúng nếu bạn không thể.
Giới thiệu về Tìm kiếm mờ
Tìm kiếm mờ tìm các từ hoặc cụm từ (giá trị) tương tự, nhưng không nhất thiết phải giống hệt với các từ hoặc cụm từ (giá trị) khác. Loại tìm kiếm này có nhiều cách sử dụng, chẳng hạn như tìm lỗi trình tự, lỗi chính tả, ký tự được hoán vị và những thứ khác mà chúng tôi sẽ đề cập sau.
Thực hiện tìm kiếm mờ các từ hoặc cụm từ gần đúng có thể giúp tìm dữ liệu có thể là bản sao của dữ liệu đã lưu trữ trước đó. Tuy nhiên, thông tin người dùng nhập hoặc tự động sửa có thể đã thay đổi dữ liệu theo một cách nào đó để làm cho các bản ghi có vẻ độc lập.
Phần còn lại của bài viết sẽ đề cập đến bốn hàm tìm kiếm mờ mà IRI hiện hỗ trợ, cách sử dụng chúng để tìm kiếm dữ liệu của bạn và trả về các bản ghi đó gần đúng với giá trị tìm kiếm.
1. Levenshtein
Thuật toán Levenshtein hoạt động bằng cách lấy hai từ hoặc cụm từ và đếm số bước chỉnh sửa sẽ thực hiện để biến từ hoặc cụm từ này thành từ khác. Càng ít bước thì từ hoặc cụm từ càng trùng khớp. Các bước mà hàm Levenshtein có thể thực hiện là:
- Chèn một ký tự vào từ hoặc cụm từ
- Xóa một ký tự khỏi từ hoặc cụm từ
- Thay thế một ký tự trong một từ hoặc cụm từ bằng một ký tự khác
Sau đây là chương trình CoSort SortCL (tập lệnh công việc) trình bày cách sử dụng hàm tìm kiếm mờ Levenshtein:
/INFILE=LevenshteinSample.dat /PROCESS=RECORD /FIELD=(ID, TYPE=ASCII, POSITION=1, SEPARATOR="\t") /FIELD=(NAME, TYPE=ASCII, POSITION=2, SEPARATOR="\t") /REPORT /OUTFILE=LevenshteinOutput.csv /PROCESS=CSV /FIELD=(ID, TYPE=ASCII, POSITION=1, SEPARATOR=",") /FIELD=(NAME, TYPE=ASCII, POSITION=2, SEPARATOR=",") /FIELD=(FS_RESULT=fs_levenshtein(NAME, "Barney Oakley"), POSITION=3, SEPARATOR=",") /INCLUDE WHERE FS_RESULT GT 50
Có hai phần phải được sử dụng để tạo ra đầu ra mong muốn.
FS_Result=fs_levenshtein(NAME, "Barney Oakley")
Dòng này gọi hàm fs_levenshtein và lưu trữ kết quả trong trường FS_RESULT. Hàm nhận hai tham số đầu vào:
- Trường để chạy tìm kiếm mờ (NAME trong ví dụ của chúng tôi)
- Chuỗi mà trường nhập sẽ được so sánh với (“Barney Oakley” trong ví dụ của chúng tôi).
/INCLUDE WHERE FS_RESULT GT 50
Dòng này so sánh trường FS_RESULT và kiểm tra xem trường có lớn hơn 50 hay không, sau đó chỉ các bản ghi có FS_RESULT trên 50 mới được xuất. Sau đây là kết quả từ ví dụ của chúng tôi.

Khi kết quả hiển thị, loại tìm kiếm này rất hữu ích cho việc tìm kiếm:
- Các tên được kết hợp
- Tiếng ồn
- Lỗi chính tả
- Các ký tự được hoán chuyển
- Lỗi phiên âm
- Lỗi đánh máy
Do đó, hàm Levenshtein cũng rất hữu ích để xác định các lỗi nhập dữ liệu phổ biến. Tuy nhiên, thuật toán mất nhiều thời gian nhất để thực hiện trong số bốn thuật toán, vì nó so sánh mọi ký tự trong một chuỗi với mọi ký tự trong chuỗi kia.
2. Hệ số xúc xắc
Hệ số xúc xắc, hay thuật toán xúc xắc, chia nhỏ các từ hoặc cụm từ thành các cặp ký tự, so sánh các cặp đó và đếm các trận đấu. Các từ càng trùng khớp thì bản thân từ đó càng có nhiều khả năng là khớp.
Tập lệnh SortCL sau trình bày hàm tìm kiếm mờ hệ số xúc xắc.
/INFILE=DiceSample.dat /PROCESS=RECORD /FIELD=(ID, TYPE=ASCII, POSITION=1, SEPARATOR="\t") /FIELD=(NAME, TYPE=ASCII, POSITION=2, SEPARATOR="\t") /REPORT /OUTFILE=DiceOutput.csv /PROCESS=CSV /FIELD=(ID, TYPE=ASCII, POSITION=1, SEPARATOR=",") /FIELD=(NAME, TYPE=ASCII, POSITION=2, SEPARATOR=",") /FIELD=(FS_RESULT=fs_dice(NAME, "Robert Thomas Smith"), POSITION=3, SEPARATOR=",") /INCLUDE WHERE FS_RESULT GT 50
Có hai phần phải được sử dụng để cung cấp cho chúng tôi đầu ra mong muốn.
FS_Result=fs_dice(NAME, "Robert Thomas Smith")
Dòng này gọi hàm fs_dice và lưu trữ kết quả trong trường FS_RESULT. Hàm nhận hai tham số đầu vào:
- Trường để chạy tìm kiếm mờ (trong ví dụ của chúng tôi là NAME).
- Chuỗi mà trường đầu vào sẽ được so sánh với (“Robert Thomas Smith” trong ví dụ của chúng tôi).
/INCLUDE WHERE FS_RESULT GT 50
Dòng này so sánh trường FS_RESULT và kiểm tra xem trường có lớn hơn 50 hay không, sau đó chỉ các bản ghi có FS_RESULT trên 50 mới được xuất. Sau đây là kết quả từ ví dụ của chúng tôi.
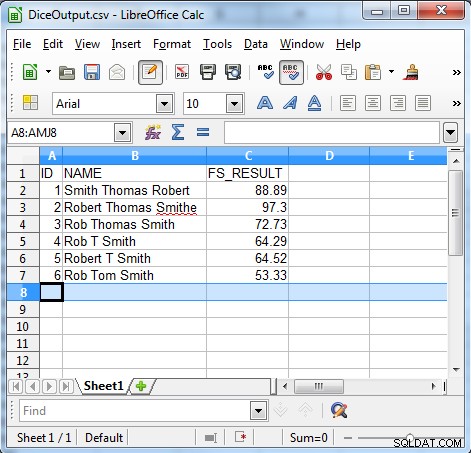
Khi kết quả hiển thị, thuật toán hệ số xúc xắc rất hữu ích để tìm kiếm dữ liệu không nhất quán, chẳng hạn như:
- Lỗi trình tự
- Chỉnh sửa không tự nguyện
- Biệt hiệu
- Tên viết tắt và biệt hiệu
- Cách sử dụng tên viết tắt không thể đoán trước
- Bản địa hoá
Thuật toán xúc xắc nhanh hơn Levenshtein, nhưng có thể trở nên kém chính xác hơn khi có nhiều lỗi đơn giản như lỗi chính tả.
3. Metaphone và 4. Soundex
thuật toán Metaphone và Soundex so sánh các từ hoặc cụm từ dựa trên âm thanh ngữ âm của chúng. Soundex thực hiện điều này bằng cách đọc qua từ hoặc cụm từ và xem xét các ký tự riêng lẻ, trong khi Metaphone xem xét cả các ký tự và nhóm ký tự riêng lẻ. Sau đó, cả hai cung cấp mã dựa trên chính tả và cách phát âm của từ đó.
Tập lệnh SortCL sau thể hiện các chức năng tìm kiếm Soundex và Metasphone:
/INFILE=SoundexSample.dat /PROCESS=RECORD /FIELD=(ID, TYPE=ASCII, POSITION=1, SEPARATOR="\t") /FIELD=(NAME, TYPE=ASCII, POSITION=2, SEPARATOR="\t") /REPORT /OUTFILE=SoundexOutput.csv /PROCESS=CSV /FIELD=(ID, TYPE=ASCII, POSITION=1, SEPARATOR=",") /FIELD=(NAME, TYPE=ASCII, POSITION=2, SEPARATOR=",") /FIELD=(SE_RESULT=fs_soundex(NAME, "John"), POSITION=3, SEPARATOR=",") /FIELD=(MP_RESULT=fs_metaphone(NAME, "John"), POSITION=3, SEPARATOR=",") /INCLUDE WHERE (SE_RESULT GT 0) OR (MP_RESULT GT 0)
Trong mỗi trường hợp, có ba phần phải được sử dụng để cung cấp cho chúng tôi đầu ra mong muốn.
SE_RESULT=fs_soundex(NAME, "John") MP_RESULT=fs_metaphone(NAME, "John")
Dòng này gọi hàm và lưu trữ kết quả trong trường RESULT. Cả hai hàm đều nhận hai tham số đầu vào:
- Trường để chạy tìm kiếm mờ (NAME trong ví dụ của chúng tôi)
- Xtring mà trường đầu vào sẽ được so sánh với ("John" trong ví dụ của chúng tôi)
/INCLUDE WHERE (SE_RESULT GT 0) OR (MP_RESULT GT 0)
Dòng này so sánh các trường SE_RESULT và MP_RESULT, đồng thời kiểm tra và trả về hàng nếu một trong hai trường lớn hơn 0.
Soundex trả về 100 cho một kết quả phù hợp hoặc 0 nếu nó không phải là một kết quả phù hợp. Metaphone có kết quả cụ thể hơn và trả về 100 cho một trận đấu mạnh, 66 cho một trận đấu bình thường và 33 cho một trận đấu nhỏ.
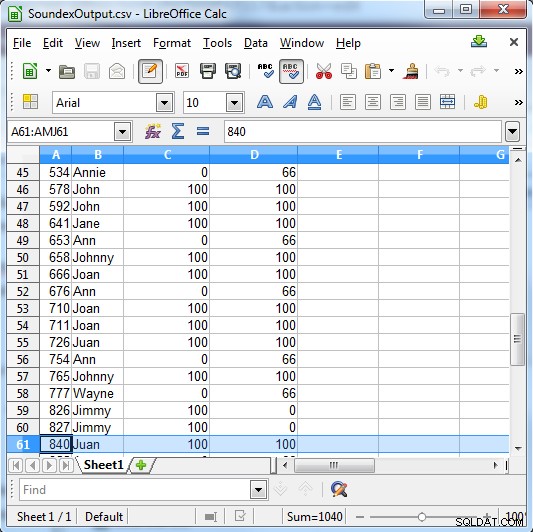
Cột C hiển thị kết quả Soundex. C olumn D hiển thị kết quả Metaphone
Khi kết quả hiển thị, loại tìm kiếm này rất hữu ích cho việc tìm kiếm:
- Lỗi ngữ âm
Vui lòng gửi phản hồi về bài viết này bên dưới, và nếu bạn quan tâm đến việc sử dụng các chức năng này, vui lòng liên hệ với đại diện IRI của bạn. Xem bài viết tiếp theo của chúng tôi về cách sử dụng các thuật toán này trong trình hướng dẫn hợp nhất dữ liệu IRI Workbench (chất lượng).



