Trong bài trước của tôi trong loạt bài này, tôi đã chứng minh rằng không phải tất cả các tình huống truy vấn đều có thể hưởng lợi từ công nghệ OLTP trong bộ nhớ. Trên thực tế, việc sử dụng Hekaton trong một số trường hợp sử dụng thực sự có thể có tác động bất lợi đến hiệu suất (nhấp để phóng to):

Cấu hình giám sát hiệu suất trong quá trình thực thi thủ tục được lưu trữ
Tuy nhiên, tôi có thể đã xếp chồng bộ bài chống lại Hekaton trong trường hợp đó, theo hai cách:
- Loại bảng được tối ưu hóa bộ nhớ mà tôi đã tạo có số lượng nhóm là 256, nhưng tôi đang chuyển tới 2.000 giá trị để so sánh. Trong một bài đăng trên blog gần đây hơn từ nhóm SQL Server, họ đã giải thích rằng định cỡ quá mức cho số lượng nhóm sẽ tốt hơn là định cỡ quá thấp - điều mà tôi biết nói chung, nhưng không nhận ra rằng cũng có ảnh hưởng đáng kể đến các biến bảng:Keep lưu ý rằng đối với một chỉ mục băm, bucket_count phải gấp khoảng 1-2 lần số lượng khóa chỉ mục duy nhất dự kiến. Định cỡ quá mức thường tốt hơn so với định cỡ nhỏ:nếu đôi khi bạn chỉ chèn 2 giá trị vào các biến, nhưng đôi khi chèn tới 1000 giá trị, thì tốt hơn nên chỉ định
BUCKET_COUNT=1000.Họ không thảo luận rõ ràng về lý do thực sự của việc này và tôi chắc chắn rằng có rất nhiều chi tiết kỹ thuật mà chúng tôi có thể nghiên cứu kỹ hơn, nhưng hướng dẫn mang tính quy định có vẻ quá kích thước.
- Khóa chính là chỉ mục băm trên hai cột, trong khi tham số có giá trị bảng chỉ cố gắng khớp các giá trị trong một trong các cột đó. Rất đơn giản, điều này có nghĩa là không thể sử dụng chỉ mục băm. Tony Rogerson giải thích điều này chi tiết hơn một chút trong một bài đăng blog gần đây:Hàm băm được tạo trên tất cả các cột có trong chỉ mục, bạn cũng phải chỉ định tất cả các cột trong chỉ mục băm trên biểu thức kiểm tra bình đẳng của bạn nếu không chỉ mục không thể được sử dụng .
Tôi đã không hiển thị nó trước đây, nhưng lưu ý rằng kế hoạch chống lại bảng được tối ưu hóa bộ nhớ với chỉ mục băm hai cột thực sự thực hiện quét bảng chứ không phải tìm kiếm chỉ mục mà bạn có thể mong đợi so với chỉ mục băm không phân cụm (kể từ đầu cột là
SalesOrderID):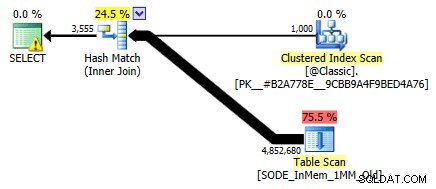
Kế hoạch truy vấn liên quan đến bảng trong bộ nhớ có hai cột chỉ số bămCụ thể hơn, trong một chỉ số băm, cột đứng đầu không có nghĩa là một đồi đậu của riêng nó; hàm băm vẫn được so khớp trên tất cả các cột, vì vậy nó không hoạt động giống như chỉ mục cây B truyền thống (với chỉ mục truyền thống, một vị từ chỉ liên quan đến cột đứng đầu vẫn có thể rất hữu ích trong việc loại bỏ các hàng).
Phải làm gì?
Trước tiên, tôi đã tạo chỉ mục băm phụ chỉ trên SalesOrderID cột. Ví dụ về một bảng như vậy, với một triệu nhóm:
CREATE TABLE [dbo].[SODE_InMem_1MM]
(
[SalesOrderID] [int] NOT NULL,
[SalesOrderDetailID] [int] NOT NULL,
[CarrierTrackingNumber] [nvarchar](25) COLLATE SQL_Latin1_General_CP1_CI_AS NULL,
[OrderQty] [smallint] NOT NULL,
[ProductID] [int] NOT NULL,
[SpecialOfferID] [int] NOT NULL,
[UnitPrice] [money] NOT NULL,
[UnitPriceDiscount] [money] NOT NULL,
[LineTotal] [numeric](38, 6) NOT NULL,
[rowguid] [uniqueidentifier] NOT NULL,
[ModifiedDate] [datetime] NOT NULL
PRIMARY KEY NONCLUSTERED HASH
(
[SalesOrderID],
[SalesOrderDetailID]
) WITH (BUCKET_COUNT = 1048576),
/* I added this secondary non-clustered hash index: */
INDEX x NONCLUSTERED HASH
(
[SalesOrderID]
) WITH (BUCKET_COUNT = 1048576)
/* I used the same bucket count to minimize testing permutations */
) WITH (MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_AND_DATA); Hãy nhớ rằng các loại bảng của chúng tôi được thiết lập theo cách này:
CREATE TYPE dbo.ClassicTVP AS TABLE ( Item INT PRIMARY KEY ); CREATE TYPE dbo.InMemoryTVP AS TABLE ( Item INT NOT NULL PRIMARY KEY NONCLUSTERED HASH WITH (BUCKET_COUNT = 256) ) WITH (MEMORY_OPTIMIZED = ON);
Sau khi tôi điền dữ liệu vào các bảng mới và tạo một quy trình mới được lưu trữ để tham chiếu đến các bảng mới, kế hoạch mà chúng tôi nhận được sẽ hiển thị chính xác một tìm kiếm chỉ mục so với chỉ mục băm một cột:

Gói cải tiến sử dụng chỉ mục băm một cột
Nhưng điều đó thực sự có ý nghĩa gì đối với hiệu suất? Tôi đã chạy lại cùng một tập hợp các bài kiểm tra - các truy vấn dựa trên bảng này với số lượng nhóm là 16K, 131K và 1MM; sử dụng cả TVP cổ điển và TVP trong bộ nhớ với các giá trị 100, 1.000 và 2.000; và trong trường hợp TVP trong bộ nhớ, sử dụng cả quy trình lưu trữ truyền thống và quy trình lưu trữ được biên dịch nguyên bản. Đây là hiệu suất đã diễn ra với 10.000 lần lặp cho mỗi kết hợp:

Hồ sơ hiệu suất cho 10.000 lần lặp so với chỉ mục băm một cột, sử dụng TVP 256 nhóm
Bạn có thể nghĩ, này, hồ sơ hiệu suất trông không tuyệt lắm; trái lại, nó tốt hơn nhiều so với lần kiểm tra trước của tôi vào tháng trước. Nó chỉ chứng minh rằng số lượng nhóm cho bảng có thể có tác động rất lớn đến khả năng sử dụng hiệu quả chỉ mục băm của SQL Server. Trong trường hợp này, sử dụng số lượng nhóm 16K rõ ràng không phải là tối ưu cho bất kỳ trường hợp nào trong số này và nó trở nên tồi tệ hơn theo cấp số nhân khi số lượng giá trị trong TVP tăng lên.
Bây giờ, hãy nhớ rằng, số lượng nhóm của TVP là 256. Vậy điều gì sẽ xảy ra nếu tôi tăng số đó, theo hướng dẫn của Microsoft? Tôi đã tạo loại bảng thứ hai với kích thước nhóm thích hợp hơn. Vì tôi đang thử nghiệm các giá trị 100, 1.000 và 2.000 nên tôi đã sử dụng công suất tiếp theo của 2 cho số nhóm (2.048):
CREATE TYPE dbo.InMemoryTVP AS TABLE ( Item INT NOT NULL PRIMARY KEY NONCLUSTERED HASH WITH (BUCKET_COUNT = 2048) ) WITH (MEMORY_OPTIMIZED = ON);
Tôi đã tạo các quy trình hỗ trợ cho việc này và chạy lại các bài kiểm tra tương tự. Dưới đây là các cấu hình hiệu suất cạnh nhau:

So sánh hồ sơ hiệu suất với TVP 256 và 2.048-bucket
Sự thay đổi về số lượng nhóm cho loại bảng không có tác động mà tôi mong đợi, theo tuyên bố của Microsoft về việc định cỡ. Nó thực sự không có nhiều tác dụng tích cực; trong thực tế, đối với một số trường hợp, nó còn tệ hơn một chút. Nhưng nhìn chung, các cấu hình hiệu suất, đối với tất cả các ý định và mục đích, đều giống nhau.
Tuy nhiên, điều gì đã có tác động rất lớn là tạo chỉ mục băm * right * để hỗ trợ mẫu truy vấn. Tôi rất biết ơn vì tôi đã có thể chứng minh điều đó - mặc dù các bài kiểm tra trước đây của tôi chỉ ra điều khác - bảng trong bộ nhớ và TVP trong bộ nhớ có thể đánh bại cách học cũ để đạt được điều tương tự. Hãy chỉ lấy trường hợp cực đoan nhất từ ví dụ trước của tôi, khi bảng chỉ có chỉ mục băm hai cột:

Hồ sơ hiệu suất cho 10 lần lặp với chỉ mục băm hai cột
Thanh ngoài cùng bên phải hiển thị thời lượng chỉ 10 lần lặp lại của quy trình được lưu trữ gốc so khớp với chỉ mục băm không phù hợp - thời gian truy vấn dao động từ 735 đến 1.601 mili giây. Tuy nhiên, giờ đây, với chỉ mục băm phù hợp, các truy vấn tương tự đang thực thi trong phạm vi nhỏ hơn nhiều - từ 0,076 mili giây đến 51,55 mili giây. Nếu chúng ta loại bỏ trường hợp xấu nhất (số lượng nhóm 16 nghìn), sự khác biệt thậm chí còn rõ ràng hơn. Trong mọi trường hợp, điều này hiệu quả hơn ít nhất hai lần (ít nhất là về thời lượng) so với một trong hai phương pháp, không có thủ tục lưu trữ được biên dịch thuần túy, so với cùng một bảng được tối ưu hóa bộ nhớ; và tốt hơn hàng trăm lần so với bất kỳ cách tiếp cận nào đối với bảng cũ được tối ưu hóa cho bộ nhớ của chúng tôi với chỉ mục băm hai cột duy nhất.
Kết luận
Tôi hy vọng tôi đã chứng minh rằng cần phải hết sức thận trọng khi triển khai các bảng được tối ưu hóa bộ nhớ thuộc bất kỳ loại nào và trong nhiều trường hợp, việc sử dụng TVP được tối ưu hóa bộ nhớ có thể không mang lại hiệu suất lớn nhất. Bạn sẽ muốn xem xét sử dụng các thủ tục được lưu trữ được biên dịch nguyên bản để có được hiệu quả cao nhất cho số tiền của mình và để mở rộng quy mô tốt nhất, bạn sẽ thực sự muốn chú ý đến số lượng nhóm cho các chỉ mục băm trong các bảng được tối ưu hóa bộ nhớ của mình (nhưng có lẽ không rất chú ý đến các loại bảng được tối ưu hóa bộ nhớ của bạn).
Để đọc thêm về công nghệ OLTP trong bộ nhớ nói chung, bạn có thể muốn xem các tài nguyên sau:
- Blog của nhóm SQL Server (Thẻ:Hekaton và Thẻ:OLTP trong bộ nhớ - tên mã không thú vị phải không?)
- Blog của Bob Beauchemin
- Blog của Klaus Aschenbrenner